Zephyr:Direct Distillation ofLM Alignment
Introduction
dSFT已经被可以提升模型的指令遵循能力的准确性,但是student model 不会超过 teacher model。
作者认为 dSFT虽然可以让模型更好的理解用户意图,但是无法与人类的偏好进行对齐。比如说用dSFT后的模型,对于同一条Instruction回答10次,他可能每次的回答都不一样,能输出真正满足用户偏好(比如说有帮助的、详细的、安全的)回答的概率很低。
在本文中,作者通过对Mistral 7B 在ultraChat dSFT与在ultra Feedback dDPO,可以得到与LLaMA70B-chat类似的性能,如下图。
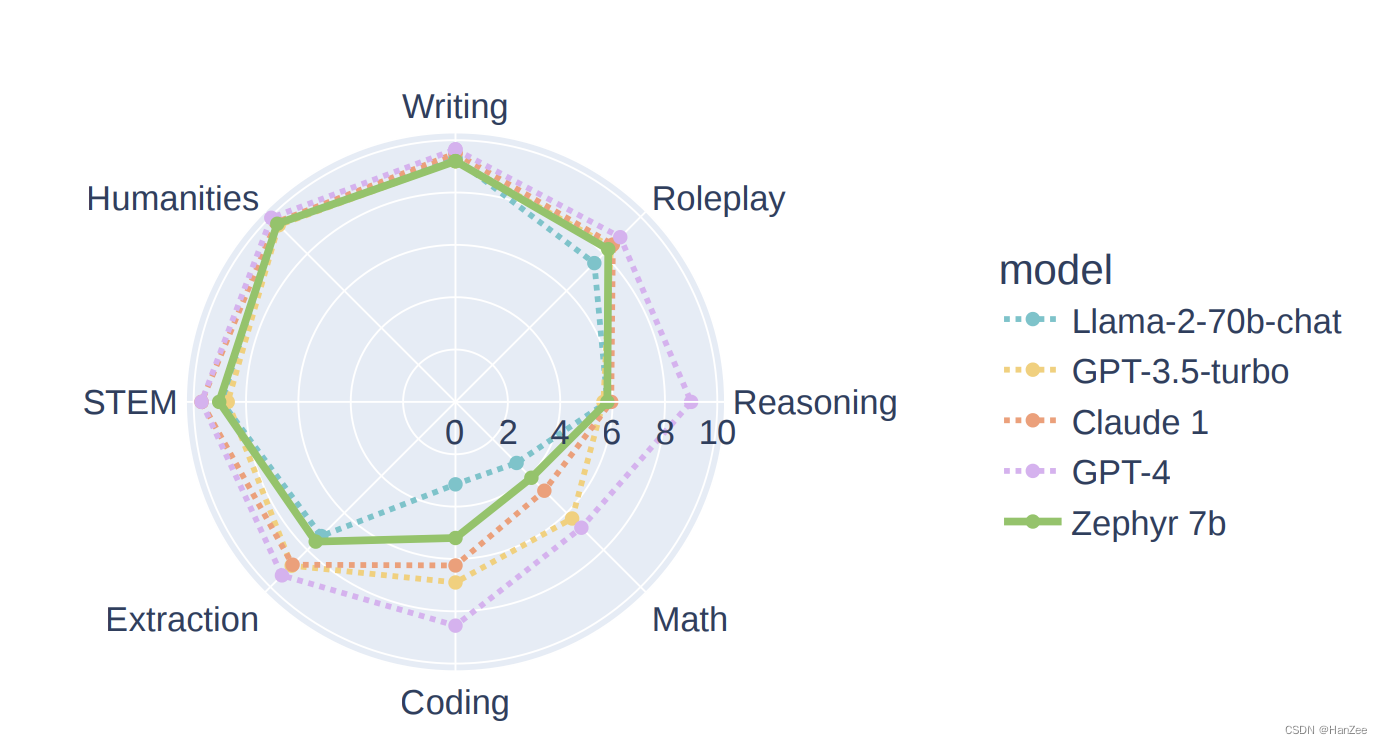
但是作者考虑到不同类别数据混合可能会造成性能下降与冗余,没有对安全性进行对齐。
Method
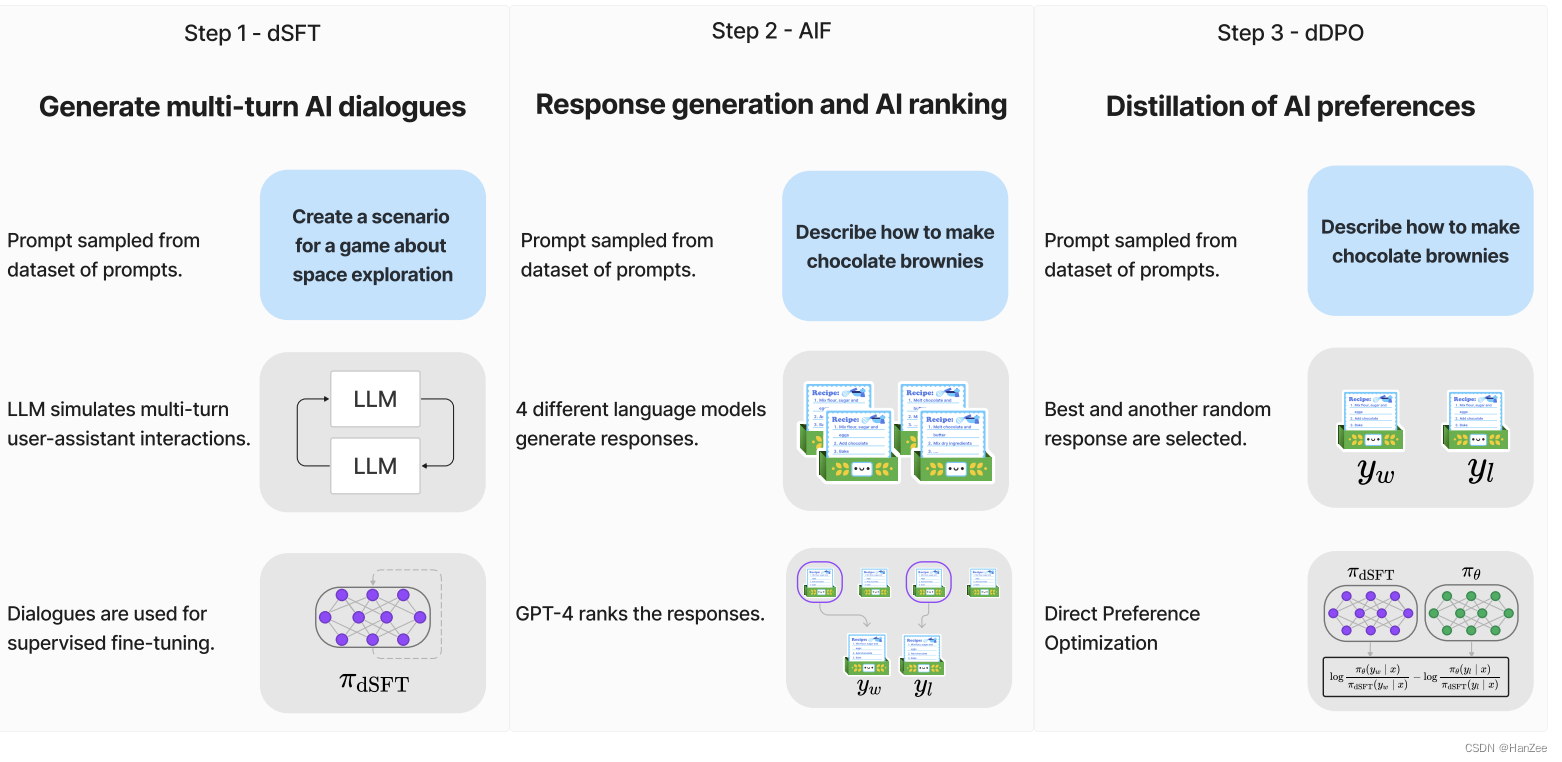
如上图,一共分为三个部分:dSFT、AIF、dDPO。
Distilled Supervised Fine-Tuning(dSFT) : dSFT实际上与之前的SFT要做的事情是一样的,都是通过老师模型去蒸馏学生的模型的训练数据,给学生模型训练,但是SFT的指代范围更宽泛,作者通过dSFT更精确的描述此过程。
AI Feedback through Preferences(AIF):这个过程一般指人类提供一个额外的偏好信号(如排名)去align LLM。在本文中作者用GPT4去模拟人类的偏好。
具体来说是作者通过UltraFeedback这个数据集通过的prompt作为输入,让现有的模型来response,如Claude、Falcon、LLaMA等模型,这样的话,一个prompt,就对应了不同模型的多个response,然后通过GPT-4对这些prompt打分,取出每个prompt对应的分数最高的prompt,然后随机sample 一个相对来说低分的prompt。
这样就得到了最终的feedback dataset (x, y_w(高分d回答), yl(低分回答))
Distilled Direct Preference Optimization(dDPO) :
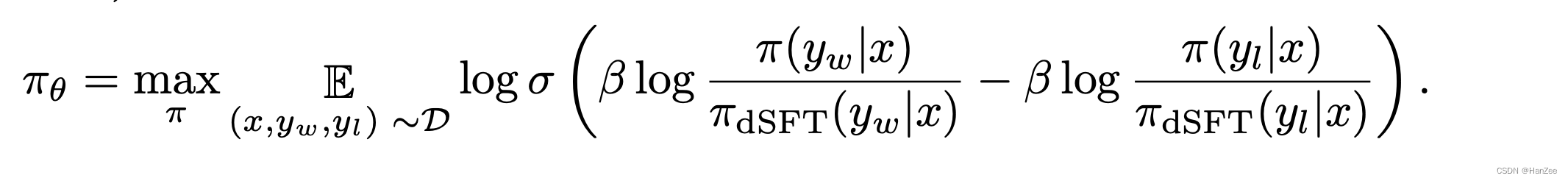
相当于加载了两个模型,一个模型不需要计算梯度,然后做了四次 forward /iter
原文:https://arxiv.org/pdf/2310.16944.pdf