本文是蒸馏学习综述系列的第三篇文章,《A Comprehensive Survey of Dataset Distillation》的一个翻译。
数据集蒸馏综述
摘要
近年来,深度神经模型在几乎每个领域都取得了成功,甚至解决了最复杂的问题陈述。然而,这些模型规模巨大,有数百万(甚至数十亿)个参数,需要大量计算能力,而且无法部署在边缘设备上。此外,性能提升高度依赖于冗余标记数据。为了实现更快的速度并处理由于缺乏标记数据而引起的问题,已经提出了知识蒸馏(KD)来将从一个模型学习到的信息迁移到另一个模型。KD通常以所谓的“学生-教师”(S-T)学习框架为特征,并在模型压缩和知识迁移中得到了广泛应用。本文是关于近年来积极研究的KD和S-T学习。首先,我们旨在解释KD是什么以及它是如何/为什么工作的。然后,我们对KD方法的最新进展以及通常用于视觉任务的S-T框架进行了全面的综述。总的来说,我们综述了推动这一研究领域的一些基本问题,并全面总结了研究进展和技术细节。此外,我们还系统地分析了KD在视觉应用中的研究现状。最后,我们讨论了现有方法的潜力和挑战,并展望了KD和S-T学习的未来方向。
1. 引言
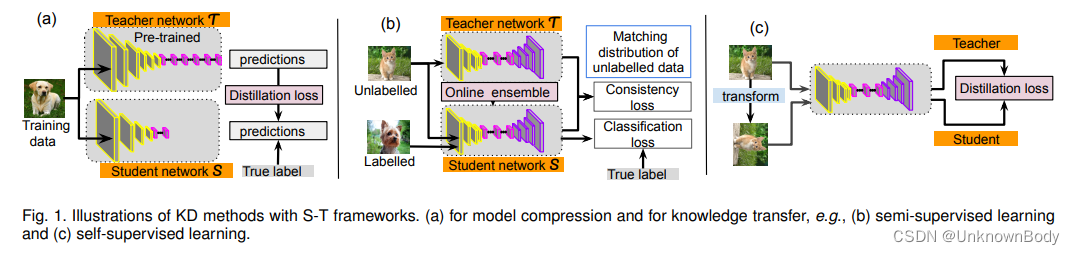
深度神经网络(DNN)的成功通常取决于DNN架构的精心设计。在大规模机器学习中,特别是对于图像和语音识别等任务,大多数基于DNN的模型都被过度参数化,以提取最显著的特征并确保泛化。这种繁琐的模型通常非常深入和广泛,需要大量的计算来进行训练,并且很难实时操作。因此,为了实现更快的速度,许多研究人员一直试图利用经过训练的繁琐模型来获得轻量级DNN模型,该模型可以部署在边缘设备中。也就是说,当繁琐的模型经过训练后,它可以用来学习更适合实时应用或部署的小模型,如图1(a)所示。
另一方面,DNN的性能也严重依赖于训练数据集的非常大和高质量的标签。出于这样的原因,已经做出了许多努力来减少标记的训练数据的量,而不会对DNN的性能造成太大的损害。处理这种数据缺乏的流行方法是从一个源任务迁移知识,以促进对目标任务的学习。一个典型的例子是半监督学习,其中仅使用一小组标记数据和一大组未标记数据来训练模型。由于未标记示例的监督成本是不确定的,因此应用一致性成本或正则化方法来匹配标记数据和未标记数据的预测是至关重要的。在这种情况下,知识在承担教师和学生双重角色的模型中迁移。对于未标记的数据,学生像以前一样学习;然而,教师生成目标,然后由学生用于学习。这种学习指标的共同目标是在没有额外训练的情况下从学生身上形成更好的教师模型,如图1(b)所示。另一个典型的例子是自监督学习,其中使用由输入变换(例如,旋转、翻转、颜色变化、裁剪)构建的人工标签来训练模型。在这种情况下,来自输入转换的知识被迁移以监督模型本身,以提高其性能,如图1(c)所示。
本文是关于知识蒸馏(KD)和学生-教师(S-T)学习的,这是近年来积极研究的一个主题。一般来说,KD被广泛认为是一种主要机制,当只给予具有相同或不同类别的小训练集时,它使人类能够快速学习新的复杂概念。在深度学习中,KD是一种有效的技术,已被广泛用于在进行建设性训练的同时将信息从一个网络转移到另一个网络。KD最早由[4]定义,并由Hinton等人推广。KD已广泛应用于两个不同的领域:模型压缩(参见图1(a))和知识迁移(参见图第1(b)和(c)段)。对于模型压缩,较小的学生模型被训练以模仿预训练的较大模型或模型集合。尽管各种形式的知识是根据目的定义的,但KD的一个共同特征是其S-T框架,其中提供知识的模型被称为教师,学习知识的模型称为学生。
在这项工作中,我们重点分析和分类现有的KD方法以及用于模型压缩和知识迁移的各种类型的S-T结构。我们审查和综述这一迅速发展的领域,特别强调最近的进展。尽管KD已经应用于视觉智能、语音识别、自然语言处理等各个领域,但本文主要关注视觉领域的KD方法,因为大多数演示都是在计算机视觉任务上进行的。使用视觉中的KD原型可以方便地解释NLP和语音识别中使用的KD方法。由于研究最多的KD方法是用于模型压缩,我们系统地讨论了技术细节、挑战和潜力。同时,我们还重点介绍了半监督学习、自监督学习等中知识迁移的KD方法,并重点介绍了将S-T学习作为一种学习度量的技术。
我们探讨了推动这一研究领域发展的一些基本问题。具体来说,KD和S-T学习的理论原理是什么?是什么让一种蒸馏方法比其他方法更好?使用多个老师比使用一个老师好吗?更大的模型总是能造就更好的老师,教出更健壮的学生吗?只有存在教师模式,学生才能学习知识吗?这个学生能自己学习吗?离线KD总是比在线学习好吗?
随着这些问题的讨论,我们结合了现有KD方法的潜力,并与S-T框架一起展望了KD方法的未来方向。我们特别强调了最近开发的技术的重要性,如神经结构搜索(NAS)、图神经网络(GNN)和用于增强KD的门控机制。此外,我们还强调KD方法在解决特定视觉领域(如360)的挑战性问题方面的潜力◦ 愿景和基于事件的愿景。
本文的主要贡献有三个方面:
•我们全面概述了KD和ST学习方法,包括问题定义、理论分析、一系列具有深度学习的KD方法以及视觉应用。
•我们从层次和结构上对KD方法和S-T框架的最新进展进行了系统的概述和分析,并对每一类的潜力和挑战提供了见解和总结。
•我们讨论了问题和悬而未决的问题,并确定了新的趋势和未来方向,以在这一研究领域提供有见地的指导。
本文的组织结构如下。首先,我们在第2节中解释了为什么我们需要关心KD和S-T学习。然后,我们在第3节中对KD进行了理论分析。第3节之后是第4节至第8节,我们对现有方法进行了分类,并分析了它们的挑战和潜力。图2以分层结构的方式显示了本调查将涵盖的具有S-T学习的KD的分类。在第9节中,基于分类法,我们将讨论第1节中提出的问题的答案。第10节将介绍KD和S-T学习的未来潜力,然后在第11节中得出结论。