-
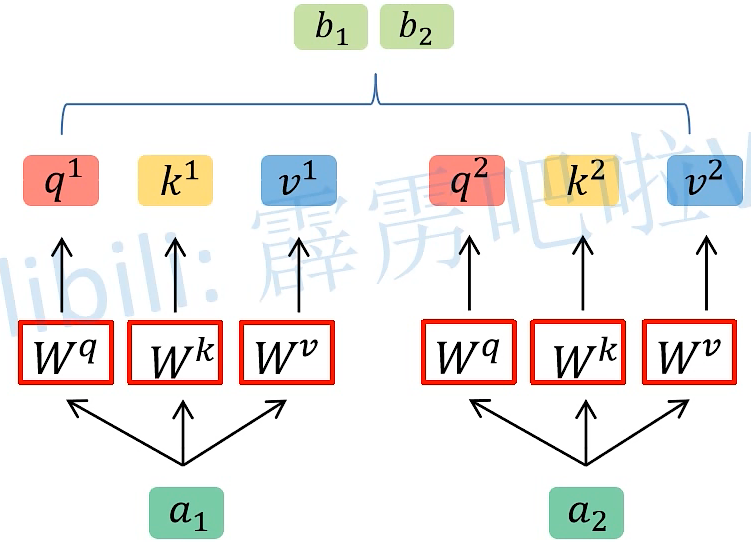
Self-Attention : (三个全连接层参数矩阵 q、k、v)
-
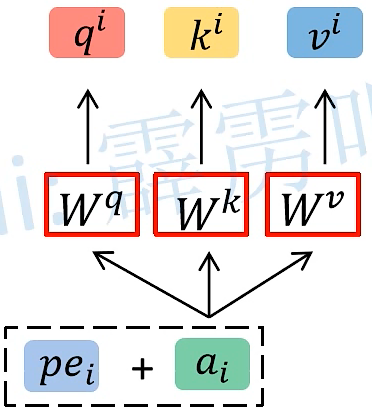
首先将时序数据 Xi 经过 Input Embedding 变成输入的参数 ai
-
然后 ai 依次与这三个参数矩阵相乘 得到 qi、ki、vi
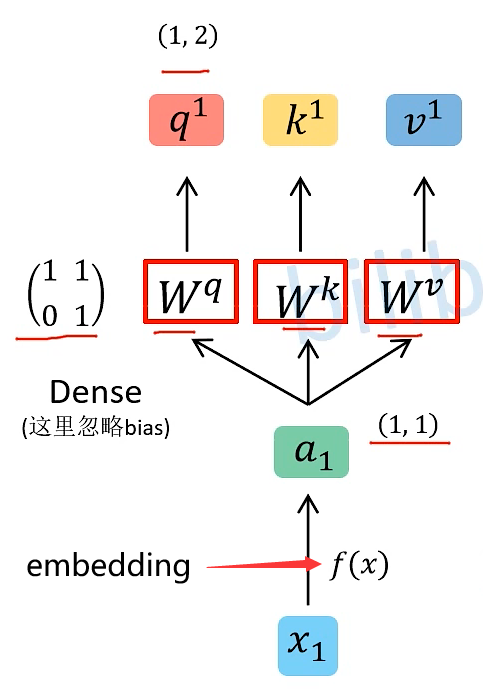
注:
- q参数代表query,会去匹配相应的key
- k参数代表key,会去和query进行匹配
- v参数代表information to be extracted,表示从ai 中学习到的信息,机器认为他学到的
-
a1、a2、… 、an 共用同一个q、k、v 参数矩阵,可把a1、a2、… 、an 堆叠成一个矩阵,然后乘以参数矩阵,进行并行化处理
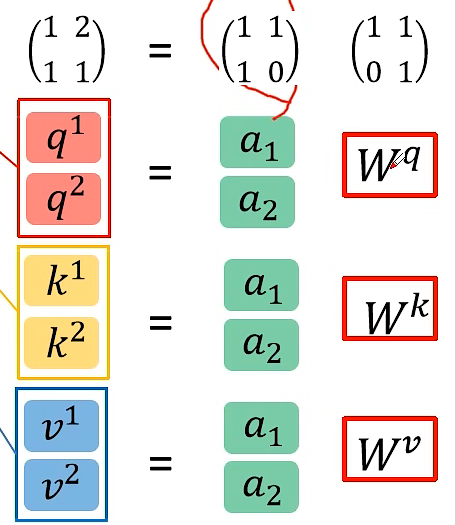
-
我们把经过q、k、v参数矩阵相乘后得到的矩阵值输入到Attention
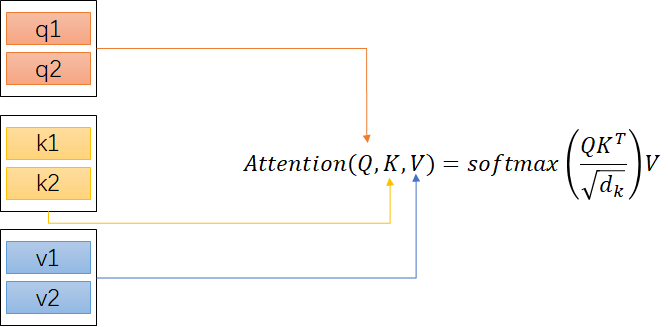
此处详细步骤
-
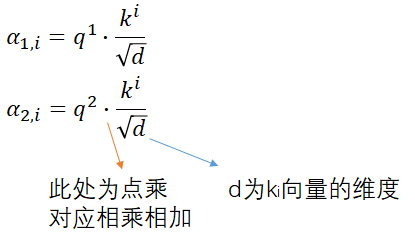
将qi与ki进行match,公式为
 扫描二维码关注公众号,回复: 17173740 查看本文章
扫描二维码关注公众号,回复: 17173740 查看本文章
q1 与k1、k2、k3、…、kn 都要相乘,得到α1,i、α2,i、…、αn,i
-
图解
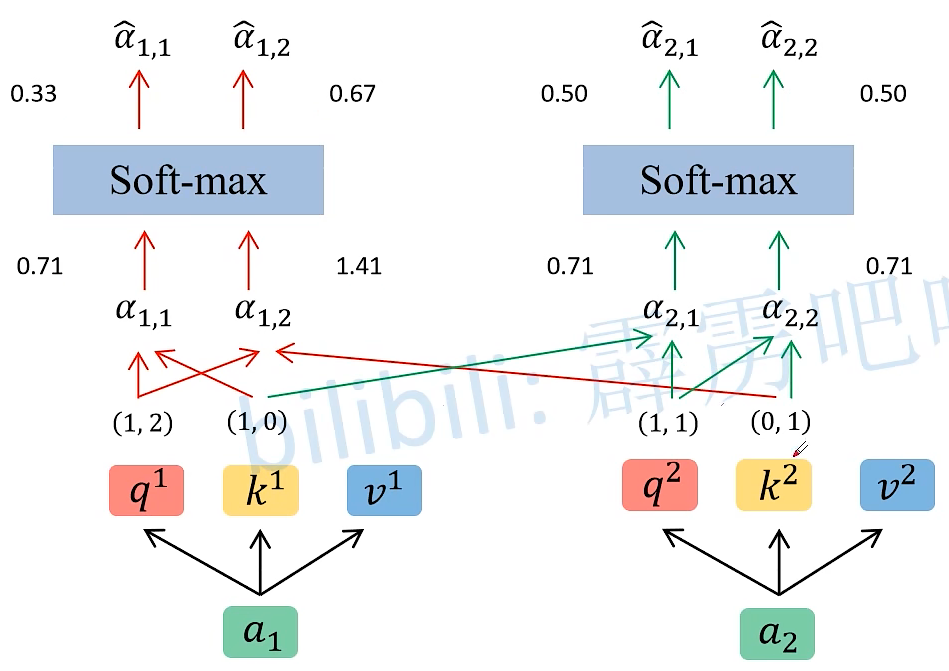
得到的 α ^ \hat{α} α^ 就是V的权重,得到的权重越大,就越关注这个V

-
得到bi
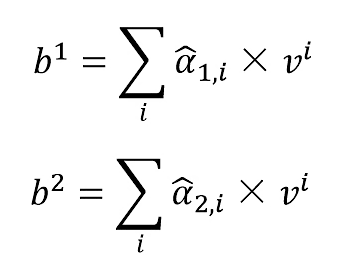
图解:
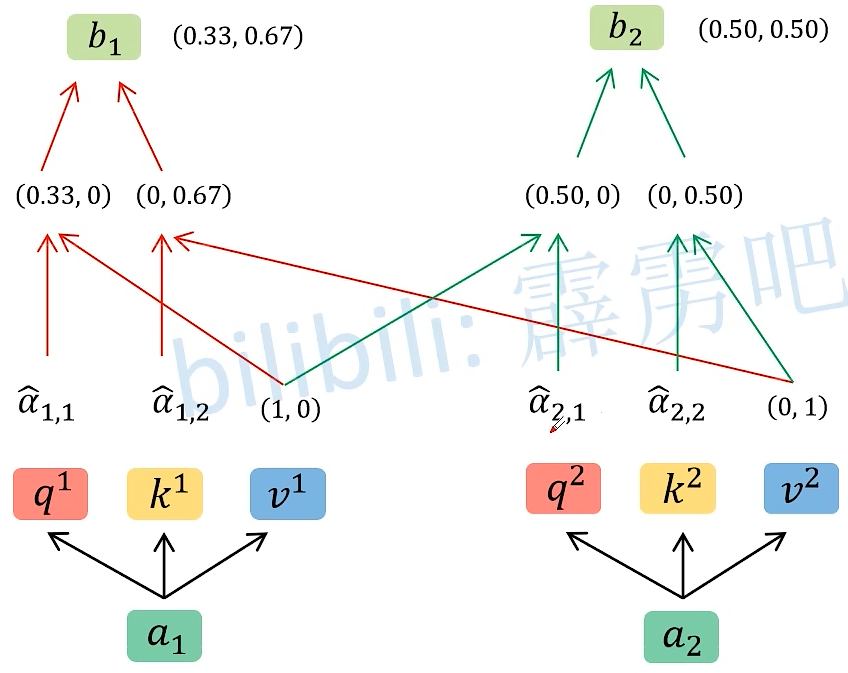
得到
Self-Attention Layer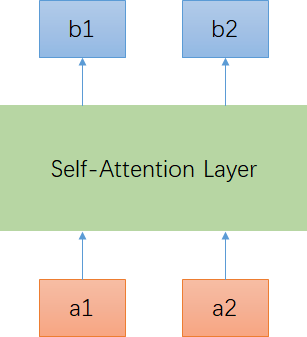
-
-
-
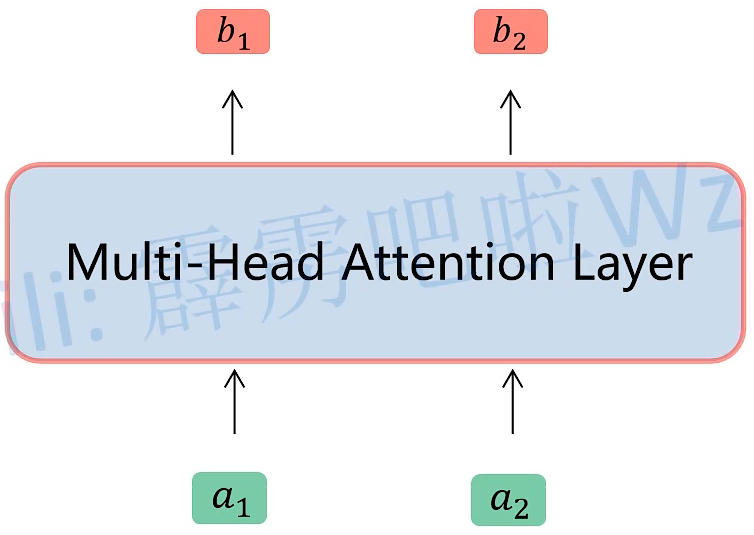
Multi-head Self-Attention
-
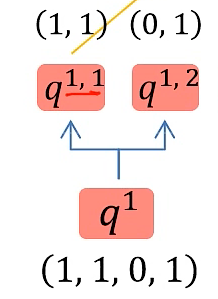
假如 qi 向量是一个n维向量,head数为2,那么就将 qi 向量均分为2个子向量,对于ki 、vi 向量同理
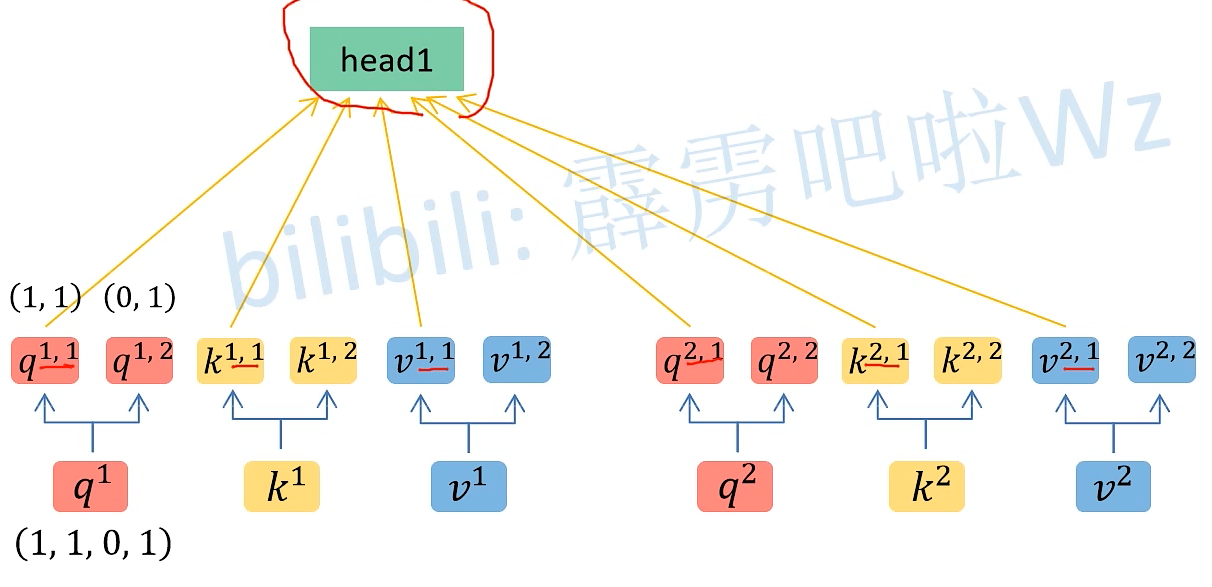
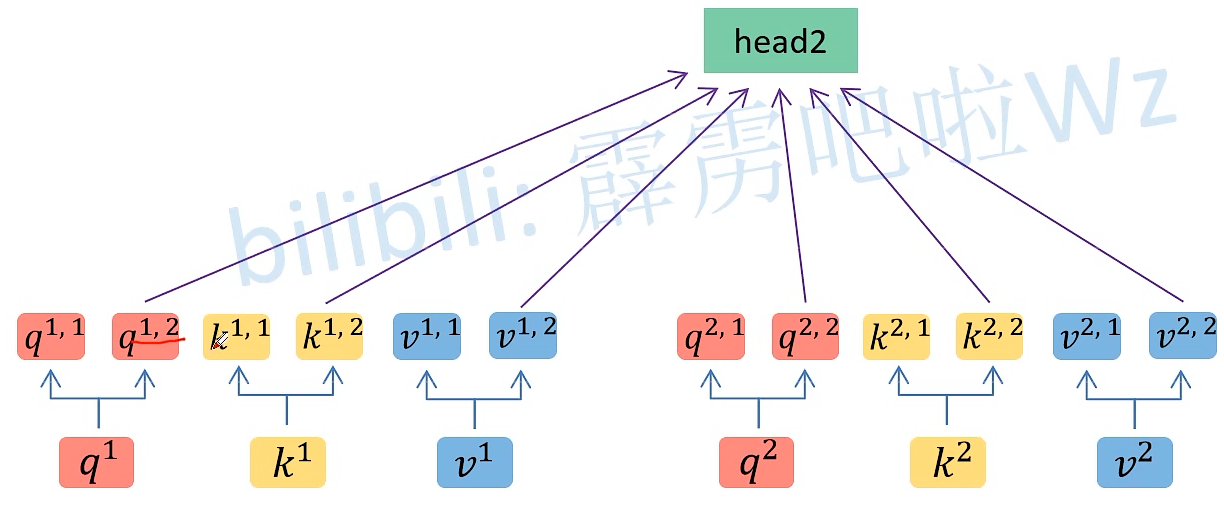
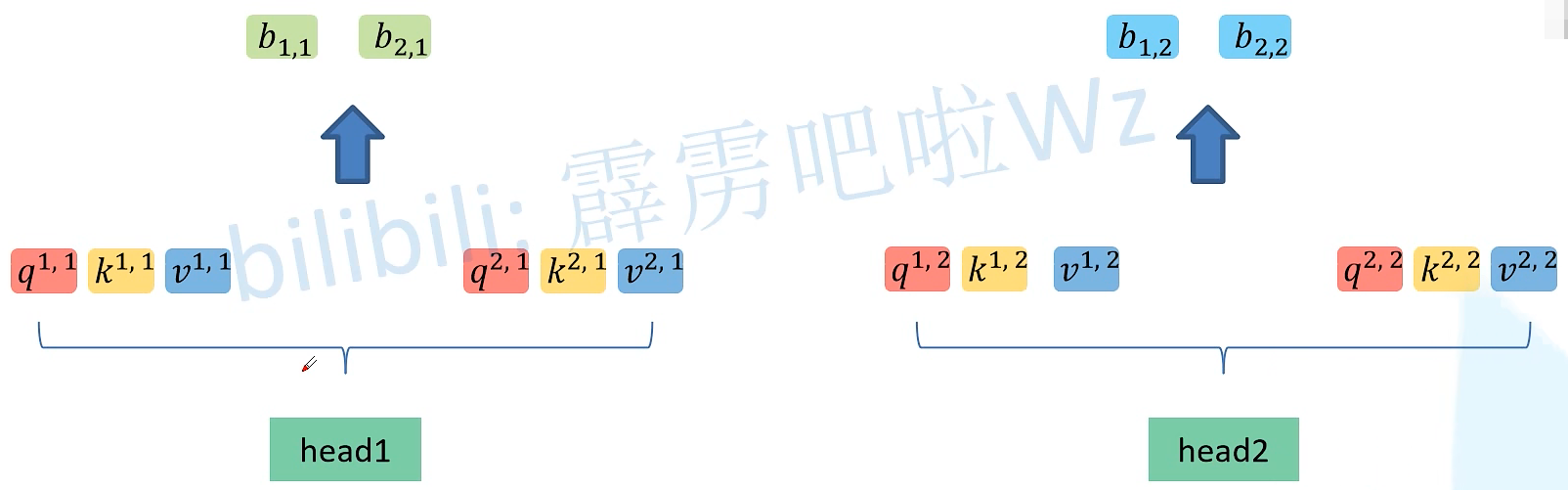
将得到的head 进行拼接
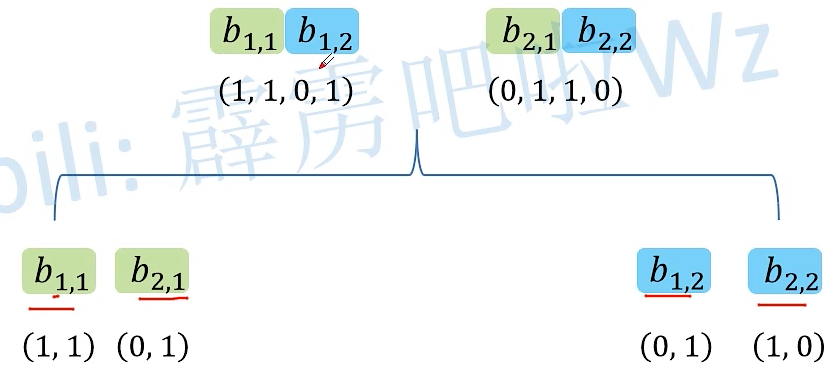
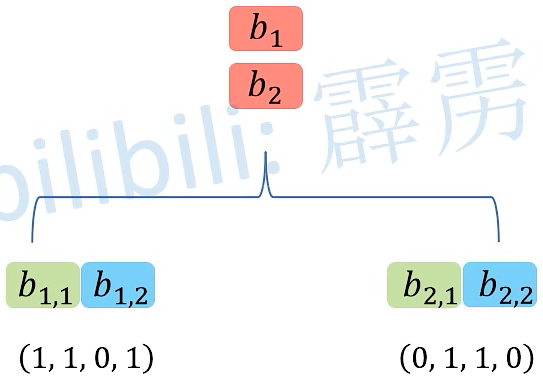
将拼接好的head进一步融合得到
MultiHead(Q,K,V)最终的输出,此处的 Wo 的维度是 d×d 的矩阵
-
-
位置编码
TransformerVision(一)|| Self-Attention和MultiHead Self-Attesntion原理
猜你喜欢
转载自blog.csdn.net/qq_56039091/article/details/124749997
今日推荐
周排行