阅读时间:2023-11-6
1 介绍
年份:2022
作者:王雷,北京信息科技大学自动化学院
期刊: Applied Soft Computing
引用量:12
提出了一种基于伪逆分解的自组织模块化回声状态(PDSM-ESN)网络。该网络通过增长-修剪方法构建,使用误差和条件数来确定储层的结构。作者们还采用了伪逆分解方法来提高网络的学习速度。此外,论文讨论了ESN中的病态问题,并提出了解决方案,例如修剪具有高条件数的模块化子储层。
2 创新点
(1)提出了一种基于伪逆分解的自组织模块化回声状态网络(PDSM-ESN)。这种网络利用生长修剪方法构建,使用误差和条件数来确定储层的结构。同时,采用了伪逆分解方法来提高网络的学习速度。
(2)解决了回声状态网络(ESN)中的不适定问题。文中提出了一些解决方案,例如修剪具有高条件数的模块化子储层。
(3)通过模拟实验结果表明,PDSM-ESN在预测性能和运行时间复杂性方面优于传统的ESN模型。这为改进回声状态网络在时间序列预测方面的设计和性能提供了启示。
3 相关研究
总结了ESN有两个主要缺点:
(1)由于储层的黑盒特性,许多性能属性很难理解。因此,需要进行大量的实验,甚至需要运气。网络性能高度依赖于蓄水池神经元的数量,因此需要一个与特定任务相匹配的适当的蓄水池结构[26,27]。
为了设计一个适当的储层,已经提出了一些模型,包括确定性储层【,Minimum complexity echo state network】【Decoupled echo state networks with lateral inhibition】、生长方法【Growing echo-state network with multiple subreservoirs】、修剪方法【Pruning and regularization in reservoir computing】【 Improved simple deterministically constructed cycle reservoir network with sensitive iterative pruning algorithm】、进化方法【 Echo state networks with orthogonal pigeon-inspired optimization for image restoration】【 PSO-based growing echo state network, 】和混合ESN【2021- Convolutional multitimescale echo state network】【2021-Echo memory-augmented network for time series classification】。
(2)输出权重通过最小二乘误差(LSE)方法学习,因此可能出现病态问题。一旦发生这种情况,就会产生大的输出权重,影响了泛化能力[28,29]。
为了解决病态问题,一些正则化方法,如L1正则化、L2正则化和混合正则化,已经被用于增强泛化能力。L1正则化方法,包括lasso[38]、自适应lasso【2019-Adaptive lasso echo state network based on modified Bayesian information criterion for nonlinear system modeling】和自适应弹性网【Adaptive elastic echo state network for multivariate time series prediction】,可以获得稀疏的预测模型。L2正则化具有平滑的特性,无法获得稀疏的预测模型[32]。混合正则化可以利用不同正则化的优势来训练ESN【2019-Hybrid regularized echo state network for multivariate chaotic time series prediction】。
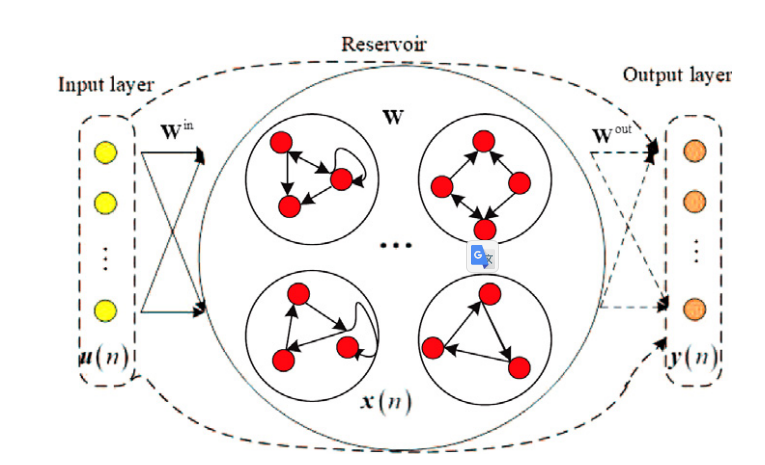
4 算法
PDSM-ESN具有具有误差和条件数的生长-修剪阶段,可以有效解决结构设计和病态问题。同时,采用伪逆分解来改善学习速度,因此输出权重是通过迭代增量方法学习得到的。
(1)Growing phase(增长阶段):在增长阶段,通过使用奇异值分解(SVD)方法构造模块化的子储层,将模块化子储层逐块地添加到网络中,直到满足停止准则。在增长阶段,还采用伪逆分解方法来训练输出权重。增长阶段的目的是优化结构设计以及增强泛化能力。
(2)Pruning phase(修剪阶段):修剪阶段主要包括两个阶段。第一阶段是使用条件数修剪线性相关的模块化子储层。第二阶段是使用迭代矩阵分解方法计算伪逆矩阵,此过程与增长阶段类似。在修剪阶段中,根据条件数,将导致条件数较大的有问题的模块化子储层进行修剪。修剪阶段的目的是修剪冗余的子储层,增强ESN的泛化能力。
5 实验分析
(1)在Mackey-Glass 数据集上测试
- PDSM-ESN在Mackey-Glass时间序列预测上具有较好的性能。与传统的ESN相比,PDSM-ESN具有更好的预测准确度和更小的测试误差。
- PDSM-ESN在不同子储层大小下的表现受到子储层大小的影响。实验结果表明,在子储层大小为5时,PDSM-ESN具有最佳的性能。
- PDSM-ESN在Mackey-Glass时间序列预测中具有较高的鲁棒性。在不同阈值下的实验结果表明,当阈值为0.002左右时,PDSM-ESN的成功设计比率比ESN高两倍左右。
- PDSM-ESN具有紧凑的网络结构,训练时间最短,并且具有较好的预测性能和泛化能力。
(2)在Henon map数据集测试
在50次独立的实验中,当阈值η大于0.003时,PDSM-ESN的成功设计比率高于OESN。当阈值η达到0.007时,PDSM-ESN和OESN的成功设计比率分别为95%和50%,这意味着PDSM-ESN比OESN更具鲁棒性。在PDSM-ESN的自组织过程中(如图14),储层的大小会增加或减小,因此内部状态矩阵的条件数也会发生变化。
(3)水处理厂中氨氮浓度的预测
- NH4-N浓度是评估废水处理厂水质的重要参数,过量排放NH4-N可能导致水体富营养化。由于经济条件或检测技术限制,NH4-N浓度很难通过检测仪器进行检测,因此需要使用软测量方法来进行预测。
- 通过使用提出的DLSBESN方法对NH4-N浓度进行预测,实验结果表明,PDSM-ESN的预测误差明显低于OESN。PDSM-ESN的预测误差范围为[-0.2,0.2],而OESN的预测误差范围为[-0.9,1.4]。
- 效果图显示,PDSM-ESN对废水NH4-N浓度的预测与实际观测值非常接近,决定系数R2为0.9969,说明PDSM-ESN具有较高的预测准确性。
- PDSM-ESN的成功设计比率始终高于OESN,这表明PDSM-ESN更具鲁棒性。
- 在自组织过程中(如图24),内部状态矩阵的条件数先增加后减小。当储层尺寸为115时,条件数达到最大值,而当储层尺寸为40时,条件数相对较小。因此,PDSM-ESN减轻了病态问题。
6 思考
这篇论文给了详细的算法推理过程,证明了生成-剪枝的理论在ESN上可行性。并从三个数据集上,证明了改进的ESN的有效性。生成的过程就是先初始化很多储层子模块,再去删除掉多余的子模块,保留下最佳的储层结构。