1.贪心算法
贪心算法是一种常见的算法范式,通常在解决最优化问题中使用。
贪心算法是一种在每一步选择中都采取当前状态下最优决策的算法范式。其核心思想是选择每一步的最佳解决方案,以期望达到最终的全局最优解。这种算法特点在于只考虑局部最优解,而不会回溯或重新考虑已经做出的决策,也不保证能够解决所有问题。尽管贪心算法并非适用于所有问题,但对于某些特定类型的问题,贪心算法的思路简单、高效。
1.区间调度
题目描述:
作业j从sj开始,在fj结束
如果两个作业不重叠,则它们是兼容的。
目标:找到相互兼容作业的最大子集。
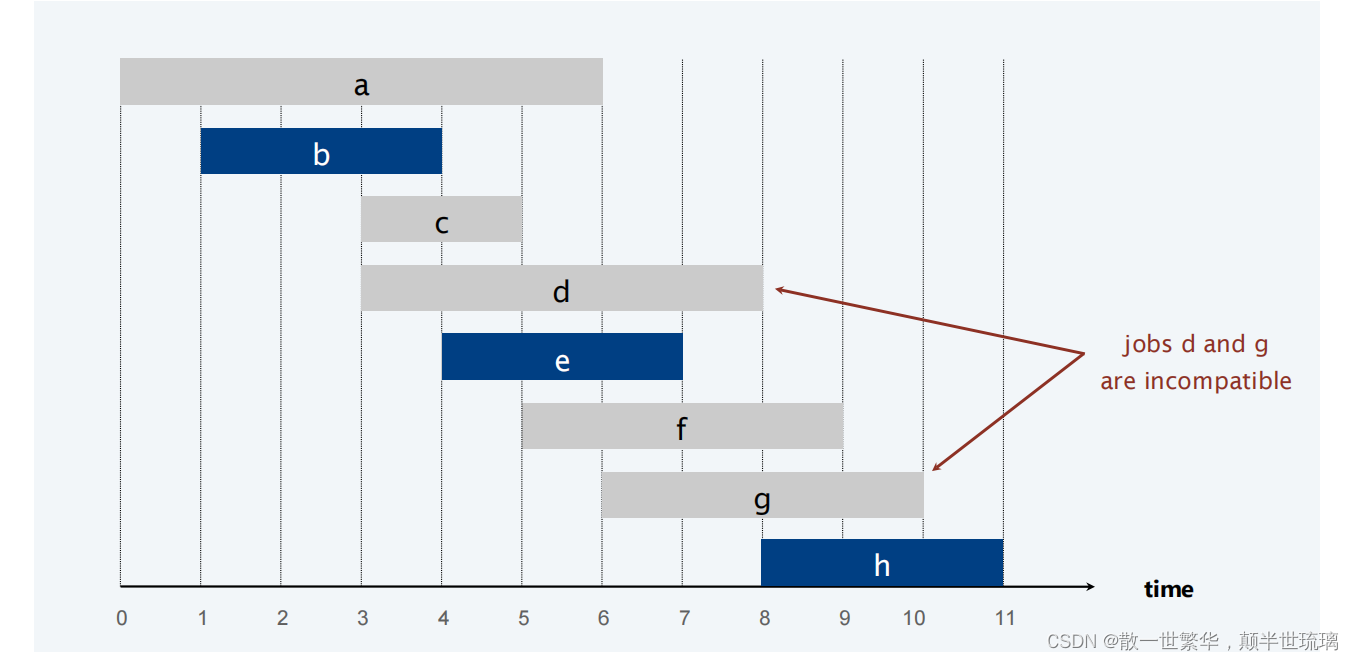
解题思路分析:
要使用贪心算法解决这个问题,我们可以按照以下步骤进行:
- 按照作业的结束时间对作业列表进行排序,确保作业按照结束时间的升序排列。
- 初始化一个空的最大互相兼容作业子集max_jobs_subset。
- 从排序后的作业列表中选择第一个作业,并将其添加到max_jobs_subset中。
- 遍历剩余的作业,对于每个作业:
- 检查该作业的起始时间是否晚于max_jobs_subset中最后一个作业的结束时间。
- 如果是,则将该作业添加到max_jobs_subset中。
- 返回max_jobs_subset作为最大互相兼容作业子集。
python代码:
# 定义一个job类
class Job:
def __init__(self, start_time, finsh_time):
self.start_time = start_time
self.finsh_time = finsh_time
def find_max_compatible_jobs(jobs):
# 使用sort函数对jobs列表进行排序 这里按照结束时间升序排列
jobs.sort(key=lambda x: x.finsh_time)
max_jobs_subset = []
last_time = float('-inf')
for job in jobs:
if job.start_time >=last_time:
max_jobs_subset.append(job)
last_time = job.finsh_time
# 这里直接返回最大公共子集
return max_jobs_subset
# 编写测试函数
# 用户首先输入作业的数量
while True:
try:
job_count = int(input('请输入作业总数:'))
if job_count < 1:
raise ValueError
break
except ValueError:
print('作业总数必须是一个正整数')
# 定义工作列表存储用户输入的工作
jobs = []
# 依次输入每个作业的起始时间和结束时间
for i in range(job_count):
while True:
try:
start_time = int(input('请输入第{}个作业的起始时间:'.format(i + 1)))
finsh_time = int(input('请输入第{}个作业的结束时间:'.format(i + 1)))
if finsh_time < start_time:
raise ValueError
break
except ValueError:
print('结束时间必须晚于开始时间')
job = Job(start_time,finsh_time)
jobs.append(job)
# 调用函数找到最大互相兼容作业子集
max_compatible_jobs = find_max_compatible_jobs(jobs)
print('相互兼容的最大工作子集:')
for job in max_compatible_jobs:
print('作业开始时间:{},作业结束时间:{}'.format(job.start_time,job.finsh_time))
2.区间划分
题目描述:
讲座j 从sj开始,到fj结束;
目标:找到安排所有讲座的最少教室数量
这样就不会在同一个房间里同时发生两次讲座。
解题思路分析:
具体的求解过程如下:
- 将所有的讲座按照结束时间进行排序,可以使用
sorted函数,并将key参数设置为讲座的结束时间。这样可以保证在贪心算法中,我们首先处理最早结束的讲座。 - 创建一个空的教室列表,用于存储已经安排的讲座。
- 遍历排序后的讲座列表。对于每一个讲座,我们需要检查是否存在一个教室可以容纳它。
- 对于每个讲座,我们遍历已经安排的教室,并检查当前讲座是否可以安排在某个教室中。我们可以通过比较当前讲座的开始时间和已安排讲座的结束时间来判断是否可以安排在同一个教室中。
- 如果存在一个教室可以容纳当前讲座,则将该讲座添加到教室的列表中。
- 如果不存在可以容纳当前讲座的教室,则创建一个新的教室,并将当前讲座添加到新的教室中。
- 遍历完所有的讲座后,返回教室列表的长度,即为需要的最小教室数量。
python代码:
class Lecture:
def __init__(self, start_time, end_time):
self.start_time = start_time
self.end_time = end_time
def get_valid_lectures():
lectures = []
while True:
try:
num_lectures = int(input("请输入讲座数量: "))
if num_lectures <= 0:
raise ValueError("讲座数量必须大于0")
for i in range(num_lectures):
start_time = int(input(f"请输入讲座{
i + 1}的开始时间: "))
end_time = int(input(f"请输入讲座{
i + 1}的结束时间: "))
if start_time >= end_time:
raise ValueError(f"讲座{
i + 1}的开始时间必须早于结束时间")
if start_time < 0:
raise ValueError(f'讲座{
i+1}的开始时间必须是正数')
if end_time < 0:
raise ValueError(f'讲座{
i+1}的结束时间必须是正数')
lecture = Lecture(start_time, end_time)
lectures.append(lecture)
break
except ValueError as e:
print("输入错误:", e)
return lectures
def minimum_classrooms(lectures):
sorted_lectures = sorted(lectures, key=lambda x: x.end_time)
classrooms = []
for lecture in sorted_lectures:
found_classroom = False
for classroom in classrooms:
if lecture.start_time >= classroom[-1].end_time:
classroom.append(lecture)
found_classroom = True
break
if not found_classroom:
classrooms.append([lecture])
return len(classrooms)
# 获取有效的讲座数据
valid_lectures = get_valid_lectures()
# 调用函数获取最小教室数量
min_classrooms = minimum_classrooms(valid_lectures)
print("需要的最小教室数量:", min_classrooms)
3.最小延迟时间
题目描述:
・单个资源一次处理一个作业。
・作业j需要tj个处理时间单位,并且在时间dj到期
・如果j在时间sj开始,它在时间fj=sj+tj结束
・潜伏时间:ℓj=最大{0,fj–dj}。
・目标:安排所有作业以最大限度地减少最大延迟L=maxjℓj
解题思路分析:
- 首先,将所有的任务按照截止时间
dj进行排序,以确保优先处理截止时间最早的任务。 - 创建一个空闲时间变量
current_time,并初始化为 0。 - 对每个任务进行迭代,按照排序后的顺序:
- 计算当前任务的完成时间
fj = current_time + tj,其中tj是当前任务的处理时间。 - 计算当前任务的延迟时间
ℓj = max(0, fj - dj)。 - 更新最大延迟
L,如果当前任务的延迟时间ℓj大于L,则将L更新为ℓj。 - 更新当前时间
current_time,将其设置为当前任务的完成时间fj。
- 计算当前任务的完成时间
- 返回最大延迟
L。
Python代码:
class Job:
def __init__(self, processing_time, deadline):
self.processing_time = processing_time
self.deadline = deadline
def minimum_lateness(jobs):
jobs.sort(key=lambda x: x.deadline) # 按照截止时间排序
L = 0 # 最大延迟
current_time = 0 # 当前时间
for job in jobs:
# 验证处理时间和截止时间的格式和数值
if not isinstance(job.processing_time, int) or job.processing_time <= 0:
raise ValueError("Processing time should be a positive integer.")
if not isinstance(job.deadline, int) or job.deadline <= 0:
raise ValueError("Deadline should be a positive integer.")
# 计算完成时间和延迟时间
finish_time = current_time + job.processing_time
lateness = max(0, finish_time - job.deadline)
# 更新最大延迟
L = max(L, lateness)
# 更新当前时间
current_time = finish_time
return L
# 用户输入数据
n = None
while not isinstance(n, int) or n <= 0:
try:
n = int(input("Enter the number of jobs: "))
if n <= 0:
print("Number of jobs should be a positive integer.")
except ValueError:
print("Invalid input. Number of jobs should be an integer.")
jobs = []
for i in range(n):
print(f"Enter information for job {
i+1}:")
processing_time = None
while not isinstance(processing_time, int) or processing_time <= 0:
try:
processing_time = int(input("Enter the processing time: "))
if processing_time <= 0:
print("Processing time should be a positive integer.")
except ValueError:
print("Invalid input. Processing time should be an integer.")
deadline = None
while not isinstance(deadline, int) or deadline <= 0:
try:
deadline = int(input("Enter the deadline: "))
if deadline <= 0:
print("Deadline should be a positive integer.")
except ValueError:
print("Invalid input. Deadline should be an integer.")
job = Job(processing_time, deadline)
jobs.append(job)
try:
max_lateness = minimum_lateness(jobs)
print("The maximum lateness is:", max_lateness)
except ValueError as e:
print("Invalid input:", str(e))
2.分治算法
分治算法是一种重要的算法范式,它将一个大问题分解成几个小问题,分别解决这些小问题,然后将其合并以得到原始问题的解。其核心思想是递归地把问题分解成更小的子问题,并将这些子问题独立地解决。
分治算法的设计思路通常分为三个步骤:
- 分解:将原问题分解为若干个子问题。
- 解决:递归地解决这些子问题。
- 合并:将子问题的解合并成原问题的解。
分治算法常用于解决递归性质的问题,例如归并排序、快速排序、二叉树相关问题等。虽然它的效率通常较高,但并非适用于所有问题。
1.最近配对问题
题目描述:
最近配对问题。给定平面上的n个点,找一对点,使得它们之间的欧几里得距离最小。
解题思路分析:
分治法是一种解决问题的方法,将问题划分为更小的子问题,然后将子问题的解合并起来得到原问题的解。下面是使用分治法解决最近配对问题的详细步骤:
- 将所有点按照 x 坐标进行排序。
- 将点集分为左右两部分,分别记为 P_left 和 P_right。
- 递归地在 P_left 和 P_right 中分别找到最近配对的距离,记为 d_left 和 d_right。
- 取 d_left 和 d_right 中的较小值,记为 d。
- 在左右两个点集中,找到横跨中间区域的点集 P_mid,其 x 坐标与中间点的 x 坐标的差值小于等于 d。
- 在 P_mid 中按照 y 坐标进行排序。
- 遍历 P_mid 中的每个点,对于每个点 p,只需计算与其后续的 7 个点的距离(因为在排序后的 P_mid 中,距离任意两点最大为 d)。
- 找到 P_mid 中距离最小的两个点的距离,记为 d_mid。
- 返回 d、d_left 和 d_right 中的最小值作为最终的最近配对距离。
python代码:
import math
# 定义一个坐标类 包括x和y
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
# 求解两个点的欧几里得距离
def distance(p1, p2):
return math.sqrt((p1.x-p2.x)**2+(p1.y-p2.y)**2)
# 使用分治法求解最近配对问题
def closest_pair(points):
n = len(points)
# 这里如果n小于等于3 即直接使用暴力法计算
if n <= 3:
# 默认最小距离为最大值
min_distance = float('inf')
closest_points = None
for i in range(n):
for j in range(i+1, n):
if distance(points[i], points[j]) < min_distance:
min_distance = distance(points[i], points[j])
closest_points = (points[i], points[j])
#函数直接返回最短距离点对和最小距离
return closest_points, min_distance
# 如果点集个数大于3 则使用分治法求解
# 首先对点集按照x升序排列
points.sort(key=lambda p: p.x)
# 然后将点集分为两部分
mid = n // 2
left_points = points[:mid]
right_points = points[mid:]
# 分别求解左 右区间的最小距离与最近点集
closest_left, d_left = closest_pair(left_points)
closest_right, d_right = closest_pair(right_points)
if d_left < d_right:
d = d_left
closest_points = closest_left
else:
d = d_right
closest_points = closest_right
mid_x = (points[mid-1].x+points[mid].x)/2
mid_points = [p for p in points if abs(p.x-mid_x) < d]
# 然后把这些点按照y值排序
mid_points.sort(key=lambda p: p.y)
min_distance = d
for i in range(len(mid_points)):
for j in range(i+1, min(i+8, len(mid_points))):# 最多计算后序7个点的距离
if distance(points[i], points[j]) < d:
min_distance = distance(points[i], points[j])
closest_points = (points[i], points[j])
return closest_points, min_distance
# 获取用户输入的点坐标
points = []
while True:
x_input = input("请输入点的 x 坐标(输入 'end' 结束输入): ")
if x_input == 'end':
break
y_input = input("请输入点的 y 坐标(输入 'end' 结束输入): ")
if y_input == 'end':
break
try:
x = float(x_input)
y = float(y_input)
# 进行校验逻辑,例如对 x 和 y 坐标进行合法性检查、范围检查等,根据需求自行定义
# 如果校验通过,则创建 Point 对象并添加到 points 列表中
point = Point(x, y)
points.append(point)
except ValueError:
print("输入的坐标不合法,请重新输入")
# 调用 closest_pair() 函数获取最近配对的结果
closest_points, min_distance = closest_pair(points)
point1, point2 = closest_points
# 输出最近配对的距离和坐标
print("The closest pair distance is:", min_distance)
print("The closest pair coordinates are:", (point1.x, point1.y), (point2.x, point2.y))
2.第k小元素
题目描述:
给定一个完全有序的宇宙中的n个元素,找出第k个最小的元素。
解题思路分析:
- 首先,我们需要选择一个合适的基准元素。可以使用各种方法选择基准元素,例如选择第一个元素、最后一个元素或随机选择一个元素。选择一个好的基准元素可以提高算法的效率。
- 将数组划分为两个子数组,一个包含小于等于基准元素的元素,另一个包含大于基准元素的元素。这可以通过遍历数组,并将小于等于基准元素的元素放在一个子数组中,大于基准元素的元素放在另一个子数组中来实现。这个过程通常被称为分区(partition)。
- 然后,我们需要确定基准元素在整个数组中的位置。这可以通过分区的过程中,记录基准元素的位置来实现。假设基准元素的位置是 pivot_index。
- 现在,我们可以根据 pivot_index 与 k 的关系来决定继续查找的部分:
- 如果 pivot_index == k-1,说明基准元素正好是第 k 小的元素,返回它。
- 如果 pivot_index > k-1,说明第 k 小的元素在基准元素的左边,我们可以递归地在左边的子数组中查找第 k 小的元素。
- 如果 pivot_index < k-1,说明第 k 小的元素在基准元素的右边,我们可以递归地在右边的子数组中查找第 k-pivot_index-1 小的元素。
- 递归地应用上述步骤,直到找到第 k 小的元素。
python代码实现:
def choose_pivot(arr, low, high):
mid = (low + high) // 2
if arr[low] <= arr[mid] <= arr[high] or arr[high] <= arr[mid] <= arr[low]:
return mid
elif arr[mid] <= arr[low] <= arr[high] or arr[high] <= arr[low] <= arr[mid]:
return low
else:
return high
# 分区 分为小于基准元素和大于基准元素两个数组
def partition(arr, low, high):
# 通过三数取中找到基准元素
pivot_index = choose_pivot(arr, low, high)
pivot = arr[pivot_index]
i = low - 1
arr[pivot_index], arr[high] = arr[high], arr[pivot_index]
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i+1], arr[high] = arr[high], arr[i+1]
return i+1
def kth_smallest(arr, low, high, k):
if low == high:
return arr[low]
pivot_index = partition(arr, low, high)
if pivot_index == k-1:
return arr[pivot_index]
elif pivot_index > k-1:
return kth_smallest(arr, low, pivot_index-1, k)
else:
return kth_smallest(arr, pivot_index+1, high, k)
# 用户输入数据
arr_valid = False
arr = []
while not arr_valid:
arr = input("请输入由空格分隔的整数数组:").split()
if arr:
try:
arr = [int(num) for num in arr]
arr_valid = True
except ValueError:
print("输入无效,请重新输入整数数组。")
else:
print("输入数组不能为空。")
# 校验数据有效性
k_valid = False
k = 0
while not k_valid:
k = input("请输入要查找的第几小的元素的值:")
if k.isdigit():
k = int(k)
if 1 <= k <= len(arr):
k_valid = True
else:
print("输入的值超出了数组范围,请重新输入。")
else:
print("输入无效,请重新输入一个整数。")
kth_smallest_element = kth_smallest(arr, 0, len(arr)-1, k)
print(f"The {
k}th smallest element is: {
kth_smallest_element}")
3.医院医生算法
题目描述:
医院-医生算法是一种解决问题的方法,旨在以最佳方式将医生分配给医院。该算法确保每个医院都有足够数量的医生,并根据特定的标准将每个医生分配到合适的医院。
解题思路分析:
以下是使用稳定婚姻算法解决医院-医生分配问题的步骤:
- 初始化医生和医院的偏好列表,并将所有医生和医院都标记为未匹配状态。
- 对于每个医生,按照其对医院的偏好将医生依次提议给最喜欢的医院。每个医生只能向一个医院提议。
- 对于每个医院收到的提议,根据医院的偏好列表进行选择。如果医院尚未被匹配,将医生分配给该医院。如果医院已经有医生,比较当前医生和已匹配医生对医院的偏好,并选择更受欢迎的医生。
- 如果医生被匹配到医院,医生和医院都将标记为已匹配状态。
- 如果有医生被拒绝或医院已经达到容量上限,则该医生将继续向下一个偏好医院提议。
- 重复步骤2和步骤3,直到所有医生都被匹配到医院为止。
- 最终得到的医生-医院匹配结果即为最优的医院-医生分配方案。
python代码:
def stable_marriage(doctors, hospitals):
doctor_preferences = {
}
hospital_preferences = {
}
doctor_matches = {
}
hospital_matches = {
}
# 初始化医生和医院的偏好列表
for doctor in doctors:
doctor_preferences[doctor] = doctors[doctor]
for hospital in hospitals:
hospital_preferences[hospital] = hospitals[hospital]
# 将所有医生和医院都标记为未匹配状态
for doctor in doctors:
doctor_matches[doctor] = None
for hospital in hospitals:
hospital_matches[hospital] = None
while None in doctor_matches.values():
for doctor in doctors:
if doctor_matches[doctor] is None:
for hospital in doctor_preferences[doctor]:
if hospital_matches[hospital] is None:
doctor_matches[doctor] = hospital
hospital_matches[hospital] = doctor
break
else:
current_match = hospital_matches[hospital]
if hospital_preferences[hospital].index(doctor) < hospital_preferences[hospital].index(current_match):
doctor_matches[doctor] = hospital
doctor_matches[current_match] = None
hospital_matches[hospital] = doctor
break
return doctor_matches
# 用户输入医生和医院的偏好
doctors = {
}
hospitals = {
}
n_doctors = int(input("请输入医生人数:"))
n_hospitals = int(input("请输入医院数量:"))
for i in range(n_doctors):
doctor_name = input(f"请输入第{
i+1}位医生的姓名:")
doctor_preferences = input(f"请输入{
doctor_name}医生对医院的偏好(以空格分隔):").split()
doctors[doctor_name] = doctor_preferences
for i in range(n_hospitals):
hospital_name = input(f"请输入第{
i+1}家医院的名称:")
hospital_preferences = input(f"请输入{
hospital_name}医院对医生的偏好(以空格分隔):").split()
hospitals[hospital_name] = hospital_preferences
# 调用稳定婚姻算法
matches = stable_marriage(doctors, hospitals)
# 输出医生-医院匹配结果
for doctor, hospital in matches.items():
print(f"{
doctor} 匹配到 {
hospital}")
4.动态规划
动态规划(Dynamic Programming)是一种优化问题求解的算法思想,适用于具有重叠子问题和最优子结构性质的问题。它将问题分解为一系列重叠的子问题,并通过保存子问题的解来避免重复计算,从而实现对整个问题的高效求解。
动态规划算法通常遵循以下步骤:
-
确定状态:将原问题划分为若干个子问题,并定义状态表示问题的解。
-
定义状态转移方程:通过递推关系式来描述子问题之间的关系,即如何通过已知的子问题的解来计算当前问题的解。
-
确定初始条件:确定最简单的子问题的解,作为递推的起点。
-
确定计算顺序:根据子问题之间的依赖关系,确定计算的顺序,通常采用自底向上的方式进行计算。
-
计算最优解:依据状态转移方程,按照确定的计算顺序,通过递推计算出问题的最优解。
-
构造最优解:根据计算得到的最优解和保存的状态信息,构造出原问题的最优解。
动态规划算法的核心思想是利用子问题的解来求解更大规模的问题,通过保存子问题的解,避免了重复计算,从而显著提高了算法的效率。动态规划常用于求解最优化问题,如最短路径问题、背包问题、序列比对等。
经典动态规划算法:接缝雕刻;文本相似和不同比较;样条曲线的赋值等。
以下是一些动态规划常用于解决的经典问题:
- Fibonacci 数列:计算第 n 个 Fibonacci 数的值。
- 背包问题(Knapsack Problem):在给定容量的背包中,选择一些物品放入背包,使得物品的总价值最大化,同时不超过背包的容量。
- 最长公共子序列(Longest Common Subsequence):给定两个字符串,找到它们的最长公共子序列的长度。
- 最长递增子序列(Longest Increasing Subsequence):给定一个序列,找到一个最长的子序列,使得子序列中的元素按顺序递增。
- 矩阵链乘法(Matrix Chain Multiplication):给定一系列矩阵,通过合理地加括号,使得矩阵相乘的次数最少。
- 最短路径问题(Shortest Path Problem):在带有权重的有向图中,找到从起点到终点的最短路径。
- 最大子数组和(Maximum Subarray Sum):给定一个整数数组,找到一个具有最大和的连续子数组。
- 最长回文子串(Longest Palindromic Substring):给定一个字符串,找到一个最长的回文子串。
- 编辑距离(Edit Distance):计算将一个字符串转换为另一个字符串所需的最少编辑操作次数。
- 切割钢条(Cutting Rod):将一根长度为 n 的钢条切割成若干段,使得卖出的总价值最大化。
1.加权区间调度
问题描述:
作业j从 s j s_{j} sj开始,在 f j f_{j} fj结束,且每个作业有个权重 w j w_{j} wj
如果两个作业不重叠,则它们是兼容的。
目标:找到相互兼容作业且权重最大的子集。
解题思路:
当解决加权区间调度问题时,我们希望找到一组相容的区间,使得它们的总权重和最大。
动态规划是一种常用的解决最优化问题的方法。在解决加权区间调度问题时,我们可以利用动态规划的思想来逐步计算出最优解。
首先,我们将所有的区间按照结束时间从小到大进行排序。这是因为结束时间早的区间有更大的潜力可以和后面的区间相容。
接下来,我们定义一个dp数组,dp[i]表示以第i个区间为最后一个区间时的最大权重和。我们需要逐个计算dp数组的值。
对于每个区间i,我们需要考虑两种情况:
- 区间i不被选中:此时dp[i]等于dp[i-1],即前一个区间为最后一个区间时的最大权重和。
- 区间i被选中:此时我们需要找到前面结束时间小于等于区间i开始时间的区间j,使得dp[j]+区间i的权重最大。因此,我们需要遍历前面的区间j,找到这样的区间,并计算dp[j]+区间i的权重。
最后,我们将dp[i]更新为这两种情况中的较大值,即dp[i] = max(dp[i-1], dp[j]+区间i的权重)。
通过这样的状态转移,我们可以逐个计算dp数组的值。最终,dp数组的最后一个元素即为最大权重和。
总结一下动态规划解决加权区间调度的思路:
- 将所有区间按照结束时间从小到大进行排序。
- 定义dp数组,长度为区间个数,初始化为0。
- 遍历每个区间i,计算dp[i]的值:
a. 如果区间i不被选中,dp[i]等于dp[i-1]。
b. 如果区间i被选中,找到前面结束时间小于等于区间i开始时间的区间j,计算dp[j]+区间i的权重。 - 将dp[i]更新为上述两种情况中的较大值。
- 返回dp数组的最后一个元素,即为最大权重和。
希望这样的解题思路能够帮助你更好地理解动态规划解决加权区间调度问题的思路。
python代码实现:
class Job:
def __init__(self, start, end, weight):
self.start = start
self.end = end
self.weight = weight
def weighted_interval_scheduling(jobs):
jobs.sort(key=lambda x: x.end) # 按照结束时间从小到大排序
n = len(jobs)
dp = [0] * n
dp[0] = jobs[0].weight # 初始化第一个作业的dp值为其权重
for i in range(1, n):
dp[i] = jobs[i].weight # 初始化dp[i]为作业i的权重
for j in range(i-1, -1, -1):
if jobs[j].end <= jobs[i].start:
dp[i] = max(dp[i], dp[j] + jobs[i].weight) # 更新dp[i]的值
return max(dp) # 返回最大权重和
# 示例输入
jobs = [
Job(1, 4, 3),
Job(3, 5, 2),
Job(0, 6, 4),
Job(4, 7, 1),
Job(3, 8, 2),
Job(5, 9, 6),
Job(6, 10, 4),
Job(8, 11, 2)
]
# 输出最大权重和
print(weighted_interval_scheduling(jobs))
2.最大子数组问题
问题描述:
最大子数组问题是指在一个数组中,找到一个连续子数组,使得该子数组的和最大。
思路分析:
下面是使用动态规划解决最大子数组问题的一般思路:
- 定义一个dp数组,长度与原数组相同,用于存储以当前位置为结尾的最大子数组和。
- 初始化dp数组的第一个元素为原数组的第一个元素,即dp[0] = nums[0]。
- 从位置1开始遍历原数组,计算以当前位置为结尾的最大子数组和。
- 如果dp[i-1]大于0,说明以前一个位置为结尾的最大子数组和对于当前位置的子数组和是有贡献的,因此dp[i] = dp[i-1] + nums[i]。
- 如果dp[i-1]小于等于0,说明以前一个位置为结尾的最大子数组和对于当前位置的子数组和没有贡献,因此dp[i] = nums[i]。
- 遍历dp数组,找到最大的子数组和,即max_sum = max(dp)。
- 返回max_sum,即为最大子数组和。
python代码实现:
def max_subarray(nums):
n = len(nums)
if n == 0:
return 0
max_sum = nums[0] # 初始化最大子数组和为第一个元素
curr_sum = nums[0] # 当前位置的最大子数组和
for i in range(1, n):
if curr_sum > 0:
curr_sum += nums[i]
else:
curr_sum = nums[i]
max_sum = max(max_sum, curr_sum)
return max_sum
# 用户输入和数据验证
while True:
try:
nums = [int(x) for x in input("请输入一个整数数组,数字之间用空格分隔:").split()]
break
except ValueError:
print("输入无效,请重新输入整数数组!")
# 输出最大子数组和
print(max_subarray(nums))
在这个题的基础上,引申出一个新的题目:
goal:given an n-by-n matrix,find a rectangle whose sum is maxinum
要使用动态规划求解给定的 n × n 矩阵中和最大的矩形,可以按照以下步骤进行:
- 定义一个 dp 数组,其大小为 n × n,用于存储以矩阵中每个位置为右下角的矩形的和。
- 初始化 dp 数组的第一行和第一列为矩阵的第一行和第一列元素。
- 从第二行和第二列开始,遍历矩阵中的每个位置 (i, j):
- 对于每个位置,计算以该位置为右下角的矩形的和,即 d p [ i ] [ j ] = d p [ i − 1 ] [ j ] + d p [ i ] [ j − 1 ] − d p [ i − 1 ] [ j − 1 ] + m a t r i x [ i ] [ j ] dp[i][j] = dp[i-1][j] + dp[i][j-1] - dp[i-1][j-1] + matrix[i][j] dp[i][j]=dp[i−1][j]+dp[i][j−1]−dp[i−1][j−1]+matrix[i][j]。
- 遍历 dp 数组,找到最大的矩形和。
- 返回最大的矩形和。
python代码实现:
def max_rectangle_sum(matrix):
n = len(matrix)
if n == 0:
return 0
dp = [[0] * n for _ in range(n)] # 定义 dp 数组
# 初始化第一行和第一列
dp[0][0] = matrix[0][0]
for i in range(1, n):
dp[i][0] = dp[i-1][0] + matrix[i][0]
dp[0][i] = dp[0][i-1] + matrix[0][i]
# 计算 dp 数组
for i in range(1, n):
for j in range(1, n):
dp[i][j] = dp[i-1][j] + dp[i][j-1] - dp[i-1][j-1] + matrix[i][j]
max_sum = float('-inf') # 初始化最大矩形和为负无穷大
# 遍历 dp 数组,找到最大矩形和
for i in range(n):
for j in range(n):
for k in range(i, n):
for l in range(j, n):
curr_sum = dp[k][l]
if i > 0:
curr_sum -= dp[i-1][l]
if j > 0:
curr_sum -= dp[k][j-1]
if i > 0 and j > 0:
curr_sum += dp[i-1][j-1]
max_sum = max(max_sum, curr_sum)
return max_sum
# 示例输入
matrix = [
[1, 2, -1],
[-3, 0, 6],
[7, 8, -9]
]
# 输出最大矩形和
print(max_rectangle_sum(matrix))
3.背包问题
问题描述:
背包问题是一个经典的组合优化问题,旨在从一组物品中选择适合放入背包以最大化总价值,同时要求背包的容量不超过给定的限制。
实现思路:
- 定义一个一维数组 dp,大小为 (W+1),其中 W 是背包的容量。dp[j] 表示背包容量为 j 时的最大价值。
- 初始化 dp 数组为 0,即 dp[j] = 0。
- 从位置 1 开始遍历 dp 数组,并计算每个位置的最大价值。
- 对于每个位置 j,我们需要判断当前物品的重量是否小于等于背包容量 j。如果是,则可以选择将该物品放入背包中,此时的最大价值为 max(dp[j], dp[j-w] + v),其中 w 是当前物品的重量,v 是当前物品的价值。
- 我们将计算得到的最大价值更新到 dp[j] 中。
- 遍历完整个 dp 数组后,dp[W] 即为最大的背包价值。
- 可以通过回溯 dp 数组,找到放入背包的物品。
- 我们从最后一个位置 W 开始,如果 dp[j] != dp[j-w] + v,表示第 j 个物品被放入背包中。
- 然后,我们将 j 减去该物品的重量,继续向前搜索。
- 重复上述步骤,直到搜索到第一个位置 1,即可得到放入背包的物品。
- 返回最大价值和放入背包的物品。
python代码实现:
def knapsack_dp(weight, value, capacity):
n = len(weight)
if n == 0 or capacity == 0:
return 0, []
# 将浮点数转换为整数,乘以一个大的倍数,以保留小数点后的精度
multiplier = 100
weight = [int(w * multiplier) for w in weight]
capacity = int(capacity * multiplier)
dp = [0] * (capacity + 1)
picks = []
for i in range(n):
if weight[i] <= capacity:
for j in range(capacity, weight[i] - 1, -1):
if dp[j] < dp[j - weight[i]] + value[i]:
dp[j] = dp[j - weight[i]] + value[i]
max_value = dp[capacity]
# 回溯找到放入背包的物品
j = capacity
for i in range(n - 1, -1, -1):
if j >= weight[i] and dp[j] == dp[j - weight[i]] + value[i]:
picks.append(i)
j -= weight[i]
picks.reverse()
return max_value, picks
# 输入数据
n = int(input("请输入物品数量:"))
weight = []
value = []
for i in range(n):
w = float(input(f"请输入第 {
i+1} 个物品的重量:"))
v = float(input(f"请输入第 {
i+1} 个物品的价值:"))
weight.append(w)
value.append(v)
capacity = float(input("请输入背包的容量:"))
# 数据合法性验证
if n <= 0 or capacity < 0:
print("输入的物品数量或背包容量不合法,请重新输入!")
else:
max_value, picks = knapsack_dp(weight, value, capacity)
print("最大价值为:", max_value)
print("放入背包的物品索引:", picks)
4.最长公共子序列问题
问题描述:
给定两个字符串,要求找到它们的最长公共子序列的长度。
解题思路:
- 定义问题:
- 输入:两个字符串
s1和s2。 - 输出:最长公共子序列的长度。
- 输入:两个字符串
- 创建一个二维数组
dp,大小为(len(s1)+1) × (len(s2)+1),用来保存最长公共子序列的长度。dp[i][j]表示字符串s1的前i个字符和字符串s2的前j个字符的最长公共子序列的长度。
- 初始化边界条件:
- 当
i=0或j=0时,dp[i][j] = 0,表示一个字符串为空时,最长公共子序列的长度为 0。
- 当
- 动态规划计算最长公共子序列的长度:
- 从
i=1和j=1开始,逐步计算dp[i][j]。 - 如果
s1[i-1]等于s2[j-1],则这两个字符可以加入最长公共子序列中,即dp[i][j] = dp[i-1][j-1] + 1。 - 如果
s1[i-1]不等于s2[j-1],则需要在s1的前i-1个字符和s2的前j个字符中找到最长公共子序列,或者在s1的前i个字符和s2的前j-1个字符中找到最长公共子序列,取两者中的较大值,即dp[i][j] = max(dp[i-1][j], dp[i][j-1])。
- 从
- 返回最长公共子序列的长度:
dp[len(s1)][len(s2)]即为最长公共子序列的长度。
python代码:
def longest_common_subsequence(s1, s2):
m = len(s1)
n = len(s2)
# 创建一个二维数组来保存最长公共子序列的长度
dp = [[0] * (n + 1) for _ in range(m + 1)]
# 动态规划计算最长公共子序列的长度
for i in range(1, m + 1):
for j in range(1, n + 1):
if s1[i - 1] == s2[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
else:
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
# 返回最长公共子序列的长度
return dp[m][n]
# 用户输入和数据验证
s1 = input("请输入第一个字符串:")
s2 = input("请输入第二个字符串:")
if not s1 or not s2:
print("输入字符串不能为空")
else:
lcs_length = longest_common_subsequence(s1, s2)
print("最长公共子序列的长度为:", lcs_length)