本文首先介绍基于n-gram的语言模型,然后引出RNN模型
一、基于n-gram的语言模型
语言模型:计算一个词汇序列出现的概率
(a language model computes a probability for a sequence of words: P(w_1, w_2,…, w_T)
语言模型的作用:
1. word ordering
p(the cat is small) > p(small the is cat)
2. word choice
p(walking home after school) > p( walking house after school)
sequence的概率计算:
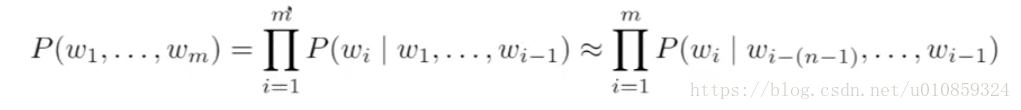
在实际中,会去计算所有的P(wi|w1,w2,w3,…,w(i-1))的概率,并进行结果的保存。而由于序列w1,w2,w3,…,w(i-1)这样的序列个数非常之多,值得计算过程计算量非常巨大。为了简化计算,引入马尔科夫性质,在计算下一个可能出现的词时只考虑之前的n个词,P(wi|w1,w2,w3,…,w(i-1))变为P(wi|w1,w2,w3,…,w(i-(n-1))),此即为n-gram。
n-gram模型的效果于n的大小有关,n越大,模型效果越好,然而模型的计算复杂度也越高。所以一般n取值偏小,实际中也能取得不俗的效果,一般n可取2,3,4这些值。
二、基于RNN的language model
基本的模型数学关系式如下:

在某一时刻t,其neuron示意图如下:
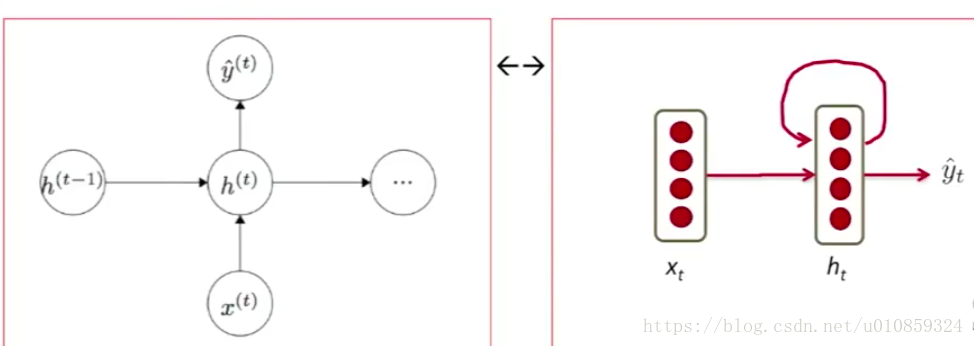
其中,x_t是在timestep t,输入word的word embedding。
h_t = sigma(w(hh) * h_t-1 + w(hx) * x_t),可以理解成在timestep t,把h_t-1和x_t进行concate操作,因为 w(hh) * h_t-1 + w(hx) * x_t = [w(hh) | w(hx)] * [h_t-1 | x_t].T
对应的时间序列示意图如下
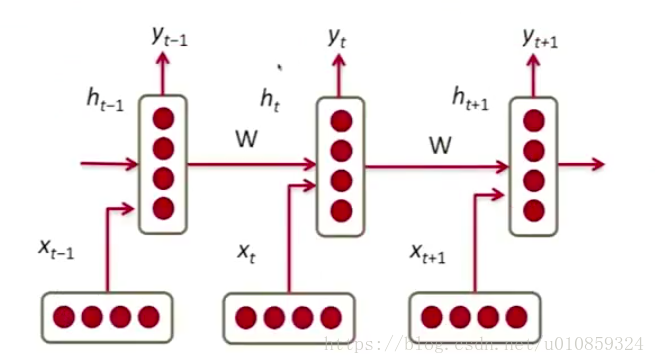
网络怎么预测下一个可能出现的word呢?softmax !
网络的cost function为croos entropy形式,
在t时刻,
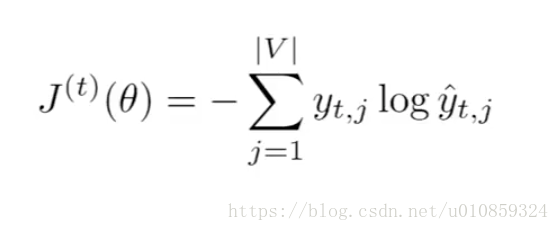
在完整的序列上,
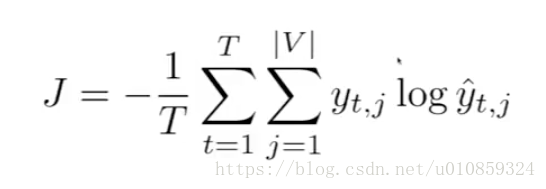
然而RNN的训练存在困难: gradient vanishing or gradient exploding
注意到,网络每个时刻共享一个w
模型的cost E,对W的gradietn,等于每个时刻的损失E_t对W的gradient之和。



对于gradient exploding,采用gradient clipping即可解决;对于gradient vanishing,最重要的策略是采用LSTM/GRU,但在这之前,还可以通过一些trick,在一定程度上解决这些问题。
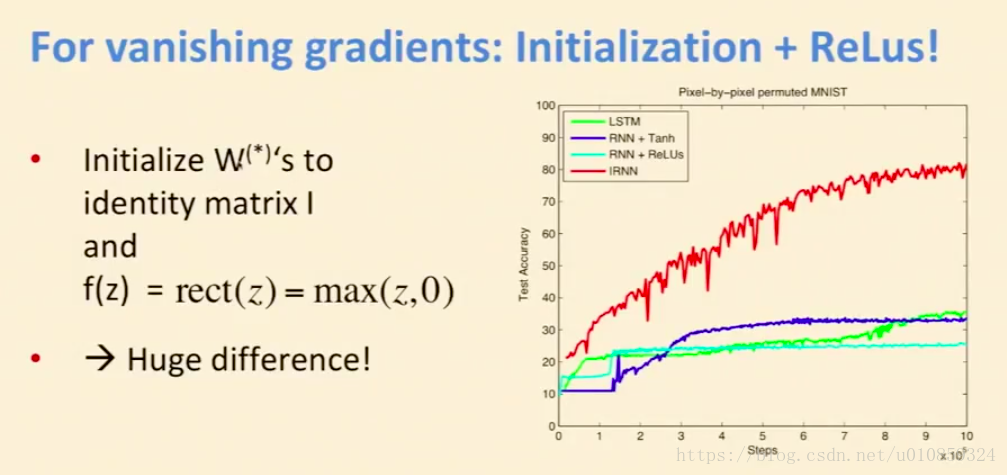
重点在于W矩阵(W(hh)、W(hx))的初始化。
(参考paper: https://arxiv.org/pdf/1504.00941.pdf)
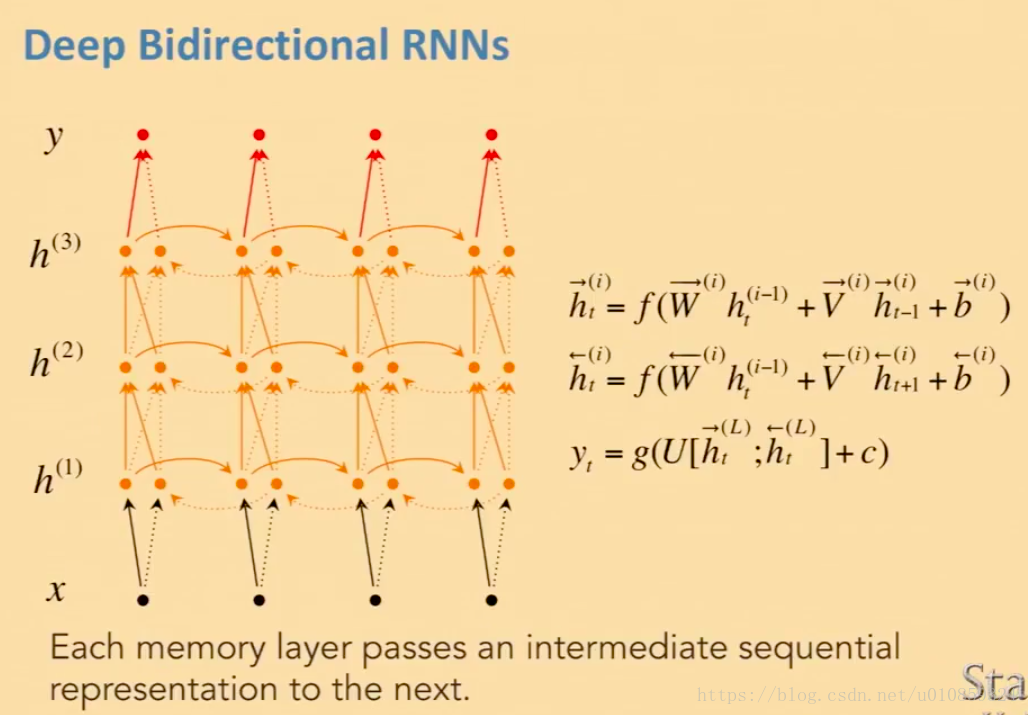
双向RNN

多个隐藏层的双向RNN
RNN的表现
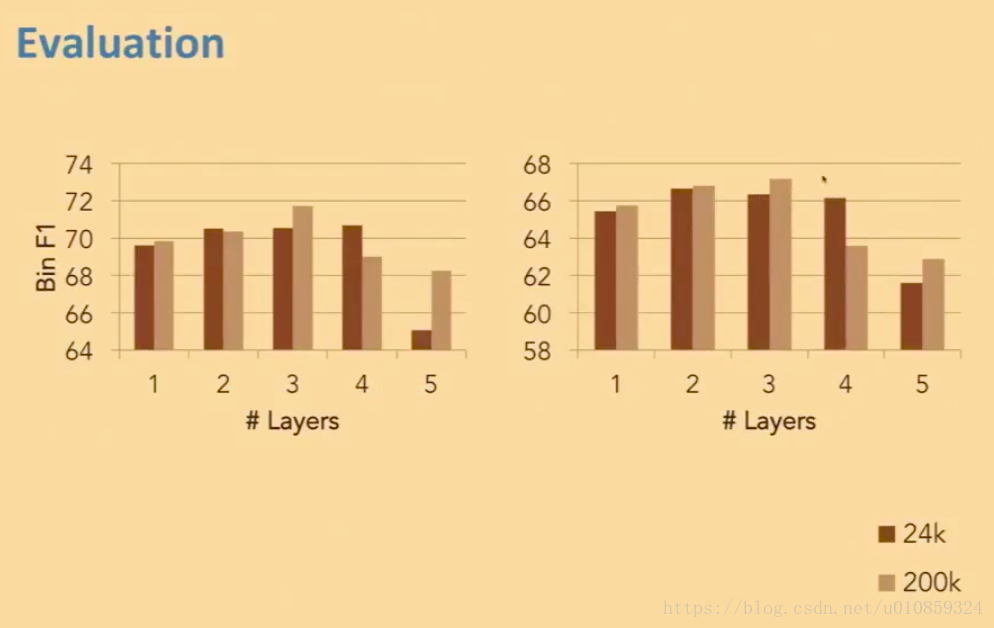
由于很难解决gradient vanishing问题,所以一般情况下RNN不宜太深,2-3层就差不多了,再深效果反而下降。