在语言建模问题中,我们想读取一些语句,从而让神经网络在一定程度上学会生成自然语言
在下图中,我们有一个字符集[h,e,l,o]和一个训练序列样例hello
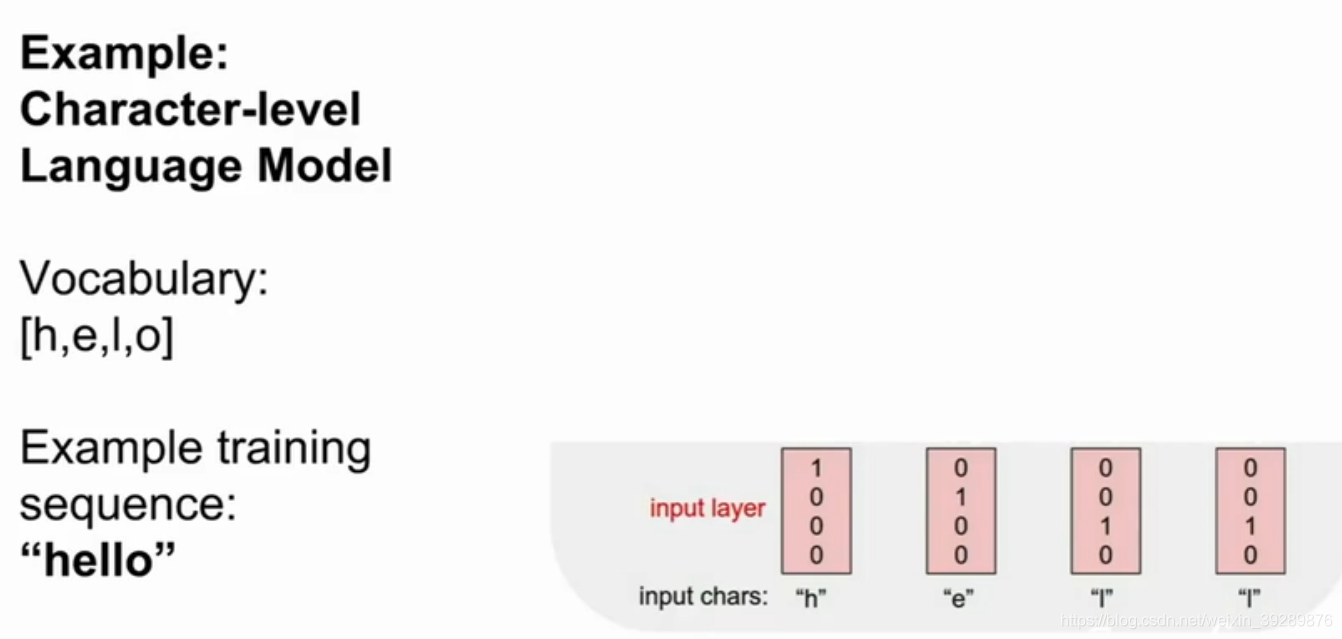
在这里语言模型的训练阶段,我们将这个字符序列作为输入项xt,考虑到是一个字母所以这里我们采用的方法是将其中一个字母所在元素对应index在为位置表为1其他标位0。
随着数字前向传播,神经网络会接收到输入h,该输入会进入RNN单元中,之后输出yt,即网络对组成单词的每个字母做出预测,也就是它觉得最有可能出现的字母,在这个例子中,因为我们训练的字母序列是hello,那么下一个正确的字母应该是e,但有可能它认为o是最有可能的下一个字母,在这种错误的情况下,我们可以用softmax损失函数来度量我们对这些预测结果的不满意程度。
现在我们将e表达为一个向量,利用这个新的输入向量,以及之前计算出的隐层状态,来生成输出一个新的隐层状态,并利用这个隐层状态,再一次对组成单词的其他字母做出预测。你在不断重复这个过程吗,最终它会更具之前出现过的字符来预测接下来会出现的字符。
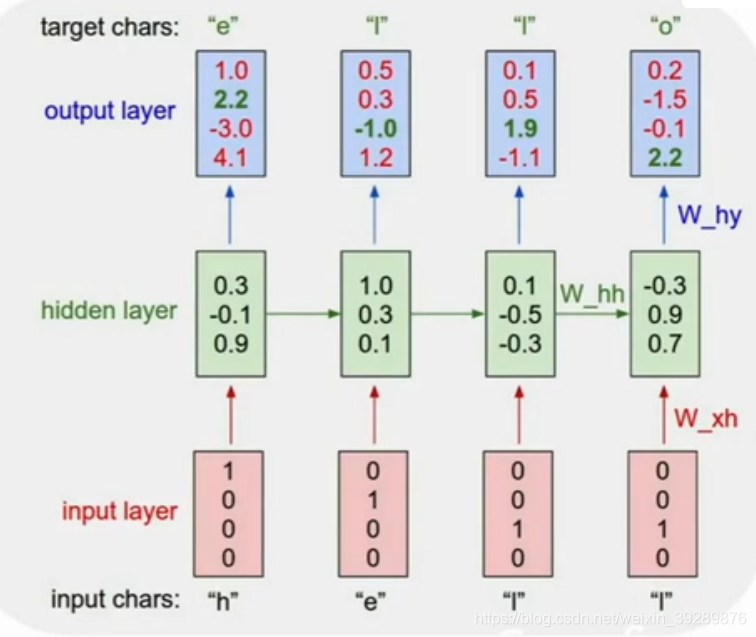
测试输入h会在下一个时间步长内生成一个新的字母
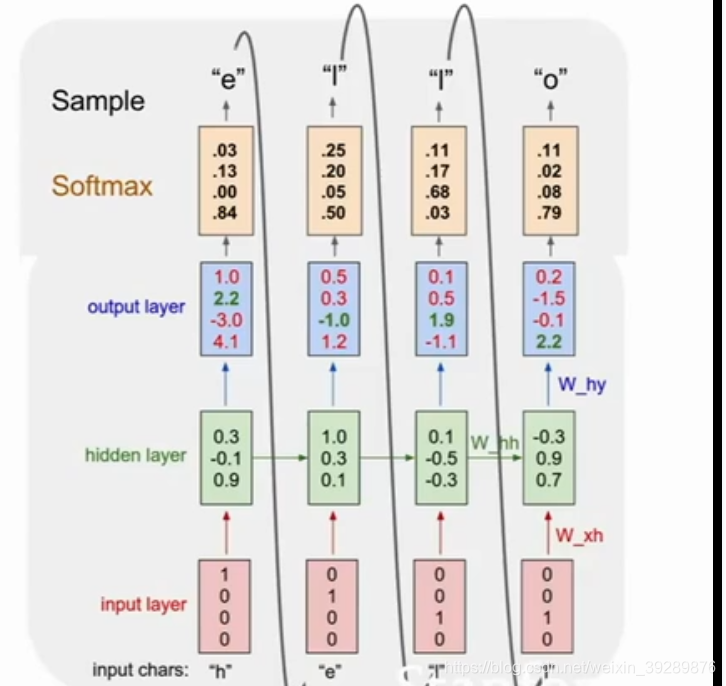
沿时间的反向传播方法
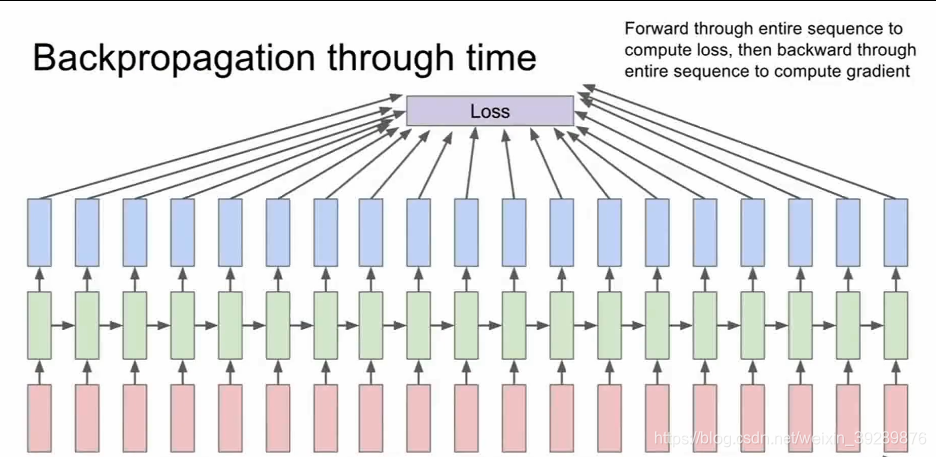
你在沿着时间做前向计算,然后在误差反向传播过程中,你会逆着时间,反向计算所有的梯度,这个误差反向传播过程中实际有些麻烦,如果你想要训练一个很长的序列,比如我们要基于维基百科中的所有文本,这个计算时非常耗时间的,而且我们计算梯度时,都必须所一次前向计算,遍历维基百科中的所有文本 ,反向计算时候又要遍历所有维基百科的所有文本。
这个计算非常耗时,而且很难收敛。
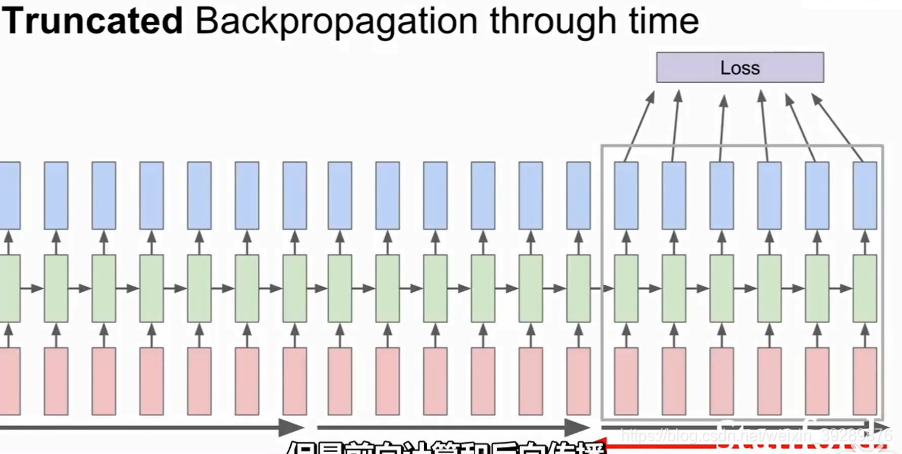
截断反向传播
实际应用中,人们采用了一种近似方法,我们称之为沿时间截断反向传播方法。
即使我们输入的序列很长很长,甚至趋于无限,我们采取的办法是向前计算若干步,比如大概100这样的数目,也就是说我们向前计算100步,计算子序列的损失值,然后沿着这个子序列反向传播误差,并计算梯度更新参数。现在我们重复上述过程。
在这里有一个案例在github上 ,只有112行就可以理解文字,是一个小型的计算样本输出。

对莎士比亚的文集进行训练,可以看出一开始是毫无意义的内容,但随着训练最后可以理解了,最后训练出来的非常有莎士比亚的风格。

