论文标题:RT-1: Robotics Transformer for Real-World Control at Scale
论文作者:Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Malla, Deeksha Manjunath, Igor Mordatch, Ofir Nachum, Carolina Parada, Jodilyn Peralta, Emily Perez, Karl Pertsch, Jornell Quiambao, Kanishka Rao, Michael Ryoo, Grecia Salazar, Pannag Sanketi, Kevin Sayed, Jaspiar Singh, Sumedh Sontakke, Austin Stone, Clayton Tan, Huong Tran, Vincent Vanhoucke, Steve Vega, Quan Vuong, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Tianhe Yu, Brianna Zitkovich
论文原文:https://roboticsconference.org/program/papers/025/,https://arxiv.org/abs/2212.06817
论文出处:Robotics: Science and Systems 2023
论文被引:149(10/22/2023)
论文代码:
- https://github.com/google-research/robotics_transformer
- https://blog.research.google/2022/12/rt-1-robotics-transformer-for-real.html
- http://robotics-transformer1.github.io/
Summary
机器人领域相关会议和期刊
会议:
- Robotics: Science and Systems(RSS):https://roboticsconference.org/
- Conference on Robot Learning(CoRL):https://www.corl2023.org/
- IEEE International Conference on Robotics and Automation(ICRA):https://www.icra2023.org/
- IEEE/RSJ International Conference on Intelligent Robots and Systems(IROS):https://ieee-iros.org/
其他ML/CV/NLP会议上包含机器人相关工作的会议:JMLR, ICML, CVPR, NIPS, IJCAI
期刊:
- Science Robotics:https://www.science.org/journal/scirobotics
- International Journal of Robotics Research(IJRR):https://journals.sagepub.com/home/ijr
- IEEE Transactions on Robotics(T-RO):https://www.ieee-ras.org/publications/t-ro
- IEEE Robotics and Automation Letters(RA-L):https://www.ieee-ras.org/publications/ra-l
提出背景
当前学习范式从收集、标注任务相关数据集,然后部署模型,解决没有关联性的多个孤立任务,转向在广泛、大型数据集上训练通用模型。其成功的关键在于开放式的任务无关的训练,以及能够吸收大规模数据中所有知识的高容量模型架构。如果模型能够海绵式地吸收经验,学习语言或感知方面的一般模式,那么它就能更有效地将这些模式应用于个别任务。
机器人领域收集数据需要人工,非常消耗人力物力,因此不需要大型特定任务数据集对其非常重要。作者希望在包含各种机器人任务的数据上训练出一个单一、高效、大型的多任务骨干模型,将其应用到新任务,新环境和新目标时具备零样本学习能力。
本文的贡献
-
设计提出了 RT-1 模型
-
收集大量真实世界机器人任务数据集
-
证明了 RT-1 与之前的技术相比,在泛化能力和鲁棒性方面有显著提高
-
评估并消除了模型和训练集组成方面的许多设计选择
-
证明了 RT-1 可以结合模拟数据甚至其他机器人类型的数据,从而保持原有任务的性能,并提高对新场景的泛化能力。
两大挑战
1)收集正确的数据
作者认为良好的泛化需要兼具规模和广度的数据集,涵盖各种任务和环境。同时,数据集中的任务应具有足够的关联性以实现泛化,这样模型才能发现结构相似任务之间的模式,并执行以新颖方式结合这些模式的新任务。
作者使用的数据由 13 台机器人,历时 17 个月收集而成,包含 13 万个事件(episodes)和 700 多个任务。
2)设计合适的模型
一个机器人领域合适的模型需要满足以下特性:
- 多任务学习
- 能够学习以自然语言指令为条件的任务
- 高容量
- 足够高效,实时运行
- 统一知识编码和表示
基于上述几点,作者提出了基于 Transformer 的 RT-1(Robotics Transformer 1)模型,它将高维输入和输出(包括摄像头图像、指令和电机命令)编码为Transformer使用的紧凑标记表征(compact token representations),可以在运行时进行高效推理。
相关工作
基于的工作:
- FiLM: Visual Reasoning with a General Conditioning Layer. 2017.
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. 2018.
- TokenLearner: Adaptive Space-Time Tokenization for Videos. 2021.
- MT-Opt: Continuous Multi-Task Robotic Reinforcement Learning at Scale. 2021.
- Bc-z: Zero-shot task generalization with robotic imitation learning. PMLR, 2021.
- Gato (A Generalist Agent). 2022.
- Do As I Can, Not As I Say: Grounding Language in Robotic Affordances. 2022.
论文工作分配
- Evaluations (ablations, designing procedures, implementations, and running ablations)
- Network Architecture (tokenizer, training, inference)
- Developed Infrastructure (data, training, collect, simulation, evaluations, storage, and operations)
- Leadership (managed or advised on the project)
- Paper (figures, vizualizations, writing)
- Data collection and evaluations
Abstract
通过从大型、多样化、与任务无关的(task-agnostic)数据集中迁移知识,现代机器学习模型能够以较高的性能解决特定的下游任务,无论是零样本(zero-shot)还是小型特定任务(task-specific)数据集。虽然这种能力已在计算机视觉、自然语言处理或语音识别等其他领域得到证明,但在机器人领域仍有待证明,由于真实世界的机器人数据难以收集,因此模型的泛化能力尤为重要。我们认为,此类通用机器人模型成功的关键之一在于开放式的任务无关的训练(open-ended task-agnostic training),以及能够吸收所有不同机器人数据的大容量架构。在本文中,我们提出了一种被称为 Robotics Transformer 的模型类别,该模型具有良好的可扩展模型特性。我们基于对执行真实世界任务的真实机器人的大规模数据收集,对不同的模型类别及其泛化能力进行了研究,从而验证了我们的结论,这些泛化能力是数据大小、模型大小和数据多样性的函数。
1 Introduction
采用模仿(imitation)或强化(reinforcement)的端到端机器人学习,通常涉及在单任务(Kalashnikov et al., 2018; Zhang et al., 2018)或多任务(Kalashnikov et al., 2021b; Jang et al., 2021)设置中收集特定任务数据,这些设置严格针对机器人应执行的任务。这种工作流程反映了计算机视觉和 NLP 等其他领域监督学习的经典方法,在这些领域中,收集,然后标记特定任务的数据集,之后部署模型,以解决单个任务,而任务本身之间几乎没有相互作用(interplay)。近年来,视觉,NLP 和其他领域发生了转变,从孤立的小规模数据集和模型转向在广泛的大型数据集上预先训练的大型通用模型。此类模型成功的关键在于开放式的任务无关的训练,以及能够吸收大规模数据中所有知识的高容量模型架构。如果模型能够海绵式地吸收(sponge up)经验,学习语言或感知方面的一般模式(general pattern),那么它就能更有效地将这些模式应用于个别任务。在监督学习中,不需要大型特定任务数据集一般都很吸引人,但在机器人学中,这一点更为重要,因为在机器人学中,数据集可能需要工程繁重的自主操作或昂贵的人工演示/说明(demonstration)。因此,我们不禁要问:我们能否在包含各种机器人任务的数据上训练出一个单一、高效、大型的多任务骨干模型?这样的模型是否能像在其他领域观察到的那样,对新任务、新环境和新目标表现出零样本泛化的优势?
在机器人学中建立这样的模型并非易事。尽管近年来已有文献提出了几种大型多任务机器人策略(Reed et al., 2022; Jang et al., 2021),但这些模型在现实世界任务中的广度往往有限,如 Gato(Reed et al., 2022),或专注于训练任务而非泛化到新任务,如最近的指令跟随方法(Shridhar et al., 2021; 2022),或在新任务中性能相对较低(Jang et al., 2021)。
两大挑战在于组建正确的数据集和设计正确的模型。数据收集和整理往往是许多大规模机器学习项目中的 “无名英雄”,而在机器人技术领域尤其如此,因为机器人的数据集往往是特定于机器人的,而且是人工收集的。正如我们将在评估中展示的那样,良好的泛化需要兼具规模和广度的数据集,涵盖各种任务和环境。同时,数据集中的任务应具有足够的关联性以实现泛化,这样模型才能发现结构相似任务之间的模式,并执行以新颖方式结合这些模式的新任务。我们使用的数据集由 13 台机器人组成,历时 17 个月收集而成,包含 13 万个事件和 700 多个任务。
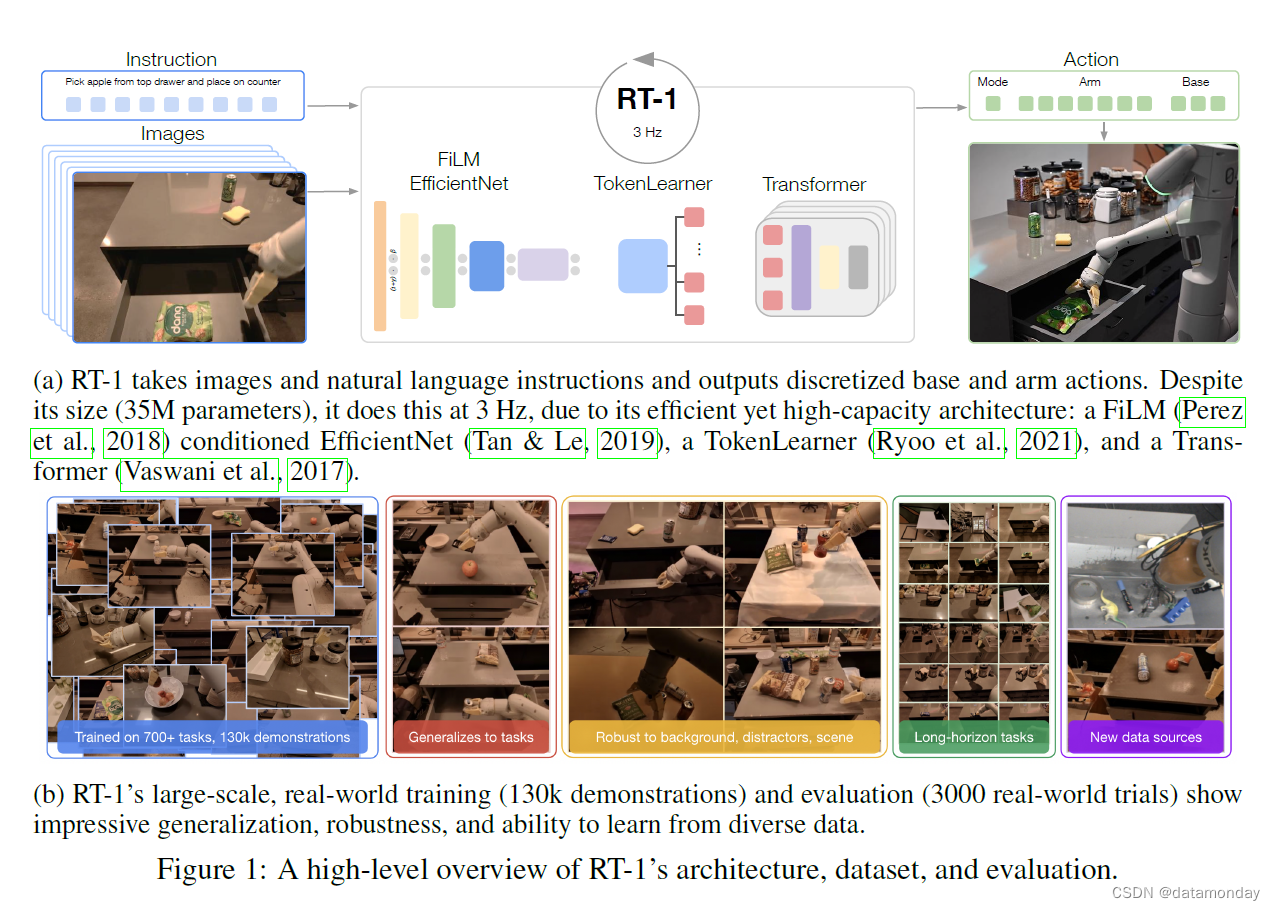
第二个挑战在于模型本身的设计。有效的机器人多任务学习需要一个高容量模型,而 Transformer 模型在这方面表现出色,尤其是当需要学习许多以语言指令(instruction)为条件的任务时,就像我们的情况一样。然而,机器人控制器还必须足够高效,能够实时运行,这尤其对 Transformer 提出了重大挑战。我们提出了一种新颖的架构,我们称之为 RT-1(Robotics Transformer 1),通过将高维输入和输出(包括摄像头图像、指令和电机命令)编码为Transformer使用的紧凑标记表征(compact token representations),可以在运行时进行高效推理,从而使实时控制变得可行。
我们的贡献在于 RT-1 模型以及该模型在大量真实世界机器人任务数据集上的实验。我们的实验不仅证明 RT-1 与之前的技术相比,在泛化能力和鲁棒性方面有显著提高,而且还评估并消除了模型和训练集组成方面的许多设计选择。我们的研究结果表明,RT-1 可以执行 700 多条训练指令,成功率高达 97%,对新任务、干扰物和背景的泛化能力分别比次好基线高出 25%、36% 和 18%。这样的性能水平使我们能够在 SayCan 框架中执行多达 50 个阶段的超长视野任务(long-horizon tasks)。我们还进一步证明,RT-1 可以结合模拟数据甚至其他机器人类型的数据,从而保持原有任务的性能,并提高对新场景的泛化能力。图 1b 简要介绍了 RT-1 的能力。
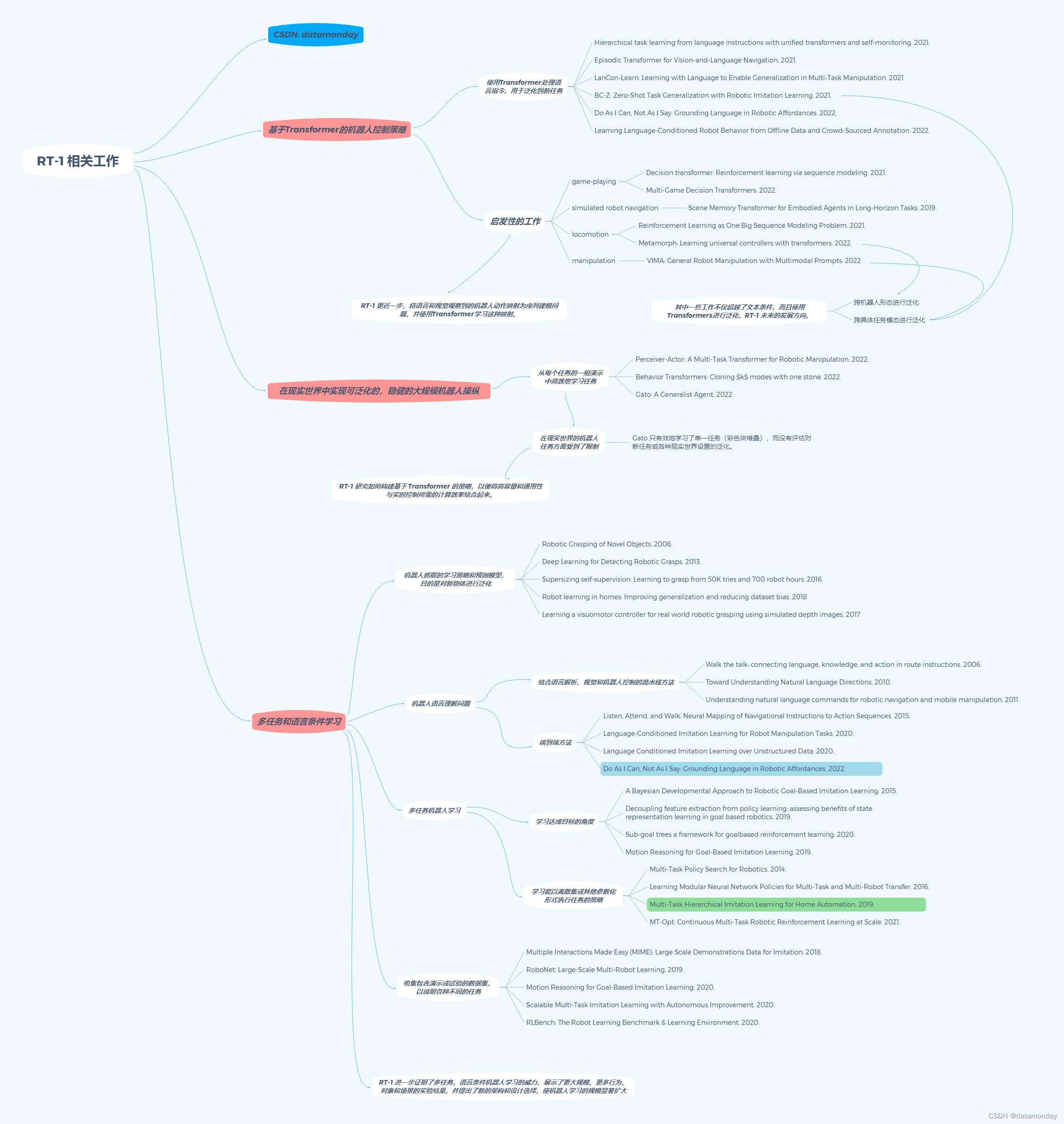
2 Related Work
最近有许多研究提出了基于 Transformer 的机器人控制策略。与 RT-1 一样,有几项研究将使用Transformer处理的语言命令作为一个强大的框架,用于指定和泛化到新任务。我们的工作将Transformer的应用向前推进了一步,将语言和视觉观察到机器人动作的映射视为序列建模问题,使用Transformer来学习这种映射。这一想法直接受到了在游戏以及模拟机器人导航,运动(locomotion)和操纵(manipulation)环境中取得的成功的启发。我们注意到,其中几项工作不仅限于文本调节,还使用Transformer在机器人形态和其他任务规范模态之间进行泛化。这些扩展是 RT-1 未来的发展方向。
除了基于 Transformer 的策略外,我们的工作重点是在现实世界中实现可泛化,稳健的大规模机器人操纵。现实世界中基于 Transformer 的机器人操纵的现有研究侧重于从每个任务的一组演示中高效地学习任务。Behavior Transformer和 Gato 主张在大规模机器人和非机器人数据集上训练单一模型。然而,这些作品在现实世界的机器人任务方面受到了限制;例如,Gato 只有效地学习了单一任务(彩色块堆叠),而没有评估对新任务或各种现实世界设置的泛化。在技术方面,我们的工作是研究如何构建基于 Transformer 的策略,以便将高容量和通用性与实时控制所需的计算效率结合起来。
虽然使用大容量 Transformer 模型来学习机器人控制策略是最近的一项创新,但机器人在多任务和语言条件学习方面有着悠久的历史,RT-1 就是在这些基础上发展起来的。大量研究工作涉及机器人抓取的学习策略和预测模型,目的是对新物体进行泛化。之前的研究试图通过结合语言解析、视觉和机器人控制的流水线方法以及端到端方法来解决机器人语言理解问题。多任务机器人学习还从学习达成目标的角度进行了探讨,以及学习能以离散集或其他参数化形式执行任务的策略。机器人学领域的许多前期工作也侧重于收集包含演示或试验的数据集,以说明各种不同的任务。我们的工作进一步证明了多任务,语言条件机器人学习的威力,展示了更大规模、更多行为、物体和场景的实验结果,并提出了新的架构和设计选择,使机器人学习的规模显著扩大。
3 Preliminaries
Robot learning. 我们的目标是学习机器人策略(robot policies),以便解决视觉中的以语言为条件的任务。从形式上看,我们考虑的是一个序列决策环境。在时间步 t = 0 t = 0 t=0 时,策略 π π π 会收到语言指令 i i i 和初始图像观测值 x 0 x_0 x0。策略会产生一个行动分布 π ( ⋅ ∣ i , x 0 ) π(\cdot |i,x_0) π(⋅∣i,x0),从中抽取一个行动 a 0 a_0 a0 并应用于机器人。这个过程会一直持续下去,策略通过从已学习的分布 π ( ⋅ ∣ i , { x j } j = 0 t ) π(\cdot | i, \{ x_j \}^t_{j=0}) π(⋅∣i,{ xj}j=0t) 中采样,迭代地产生动作,并将这些动作应用到机器人身上。当达到终止条件时,交互(interaction)结束。从起始步骤 t = 0 t = 0 t=0 到终止步骤 T T T 的整个交互过程 i , ( x j , a j ) j = 0 T i, {(x_j, a_j)}^T_{j=0} i,(xj,aj)j=0T 被称为一段经历/一个事件(episode)。在一个事件结束时,智能体(agent)将得到一个二进制奖励 r ∈ { 0 , 1 } r \in \{0, 1\} r∈{ 0,1},表示机器人是否执行了指令 i i i。我们的目标是学习一种策略 π π π,在指令,起始状态 x 0 x_0 x0 和过渡动态(transition dynamics)分布的期望值下,使平均奖励最大化。
Transformers. 一般来说,Transformer 是一种序列模型,它利用自注意层和全连接神经网络的组合,将输入序列 { ξ h } h = 0 H \{\xi_h\}^H_{h=0} { ξh}h=0H 映射到输出序列 { y k } k = 0 K \{y_k\}^K_{k=0} { yk}k=0K。虽然Transformer 最初是为文本序列设计的,其中每个输入 ξ j ξ_j ξj 和输出 y k y_k yk 代表一个文本标记(text token),但它们已被扩展到图像(Image Transformer,2018)以及其他模式(Lee et al., 2022a; Reed et al., 2022)。正如下一节所详述的,我们首先将输入 i i i, { x j } j = 0 t \{x_j\}^t_{j=0} { xj}j=0t 映射到序列 { ξ h } h = 0 H \{\xi_h\}^H_{h=0} { ξh}h=0H,并将动作输出 a t a_t at 映射到序列 { y k } k = 0 K \{y_k\}^K_{k=0} { yk}k=0K,然后使用Transformer学习映射 { ξ h } h = 0 H \{\xi_h\}^H_{h=0} { ξh}h=0H → { y k } k = 0 K \{y_k\}^K_{k=0} { yk}k=0K,从而对 π π π 进行参数化。
Imitation learning. 模仿学习方法在演示(demonstration)数据集 D 上训练策略 π。具体来说,我们假设可以访问一个数据集 D = { ( i ( n ) , { ( x t ( n ) , a t ( n ) ) } t = 0 T ( n ) ) } n = 0 N \mathcal{D} = \{(i^{(n)}, \{(x^{(n)}_t , a^{(n)}_t )\}^{T^{(n)}}_{t=0} )\}^N_{n=0} D={(i(n),{(xt(n),at(n))}t=0T(n))}n=0N 的事件,所有事件都是成功的(即最终奖励为 1)。我们使用行为克隆法(Pomerleau,1988 年)学习 π π π,该方法通过最小化给定图像和语言指令下的行动负对数可能性来优化 π π π。
4 System Overview

这项工作的目标是建立并演示一个能够吸收大量数据并有效泛化的通用机器人学习系统。我们使用的是 Everyday Robots 公司生产的移动机械手,它有一个 7 自由度的机械臂,一个双指抓手和一个移动底座(见图2(d))。为了收集数据和评估我们的方法,我们使用了**三个基于厨房的环境:两个真实的办公室厨房和一个仿照这些真实厨房的训练环境。训练环境如图2(a)所示,由部分计数器组成,用于大规模数据收集。图2(b,c)所示的两个真实环境的台面与训练环境类似,但在照明、背景和整个厨房的几何形状上有所不同**(例如,可能有一个橱柜而不是抽屉,或者水槽可能是可见的)。我们评估了我们的策略在这些不同环境中的表现,衡量了策略的性能和泛化能力。
我们的**训练数据由人类提供的演示(demonstration)组成,我们为每一个事件(episode)注释机器人刚刚执行的指令的文本描述。指令通常包含一个动词和一个或多个描述目标物体的名词**。为了将这些指令组合在一起,我们将其分为若干技能(如 “pick”, “open” or “place upright” 等动词)和目标/物体(如 “coke can”, “apple”, or “drawer” 等名词)。我们将在第 5.2 节中详细介绍大规模数据收集策略。我们最大的数据集包含超过 13 万个单独的演示,这些演示构成了 700 多个不同的任务指令,使用的物体种类繁多(见图2(f))。我们将在第 5.2 节中详细介绍收集到的数据。
我们系统的主要贡献之一是网络架构–Robotics Transformer 1 (RT-1),它是一个高效的模型,可以吸收大量数据,有效地进行泛化,并以实时速率输出动作,用于实际的机器人控制。RT-1 将短序列图像和自然语言指令作为输入,并在每个时间步为机器人输出一个动作。为此,该架构(如图 1a 所示)利用了几个要素:
- 首先通过 ImageNet 预训练卷积网络 EfficientNet (2019) 处理图像和文本,该网络以通过 FiLM (2018) 对指令进行预训练嵌入(pretrained embedding)为条件;
- 然后通过 Token Learner (2021) 计算紧凑的标记集(compact set of tokens);
- 最后通过Transformer (2017) 对这些标记进行处理,并生成离散化的动作标记(action tokens)。
动作包括手臂运动的七个维度(x、y、z、滚动(roll)、俯仰(pitch)、偏航(yaw)、打开夹爪),底座运动的三个维度(x、y、偏航)以及在三种模式之间切换的离散维度:控制手臂、底座或终止事件。RT-1 执行闭环控制,以 3 Hz 的频率发出指令,直到产生 “终止(terminate)” 动作或达到预设的时间步长限制。
5 RT-1: Robotics Transformer
在本节中,我们将介绍如何标记图像、文本和操作,然后讨论 RT-1 模型架构。然后,我们将介绍如何达到实时控制所需的运行速度。最后,我们将介绍数据收集程序以及数据集中的技能和指令。
5.1 MODEL
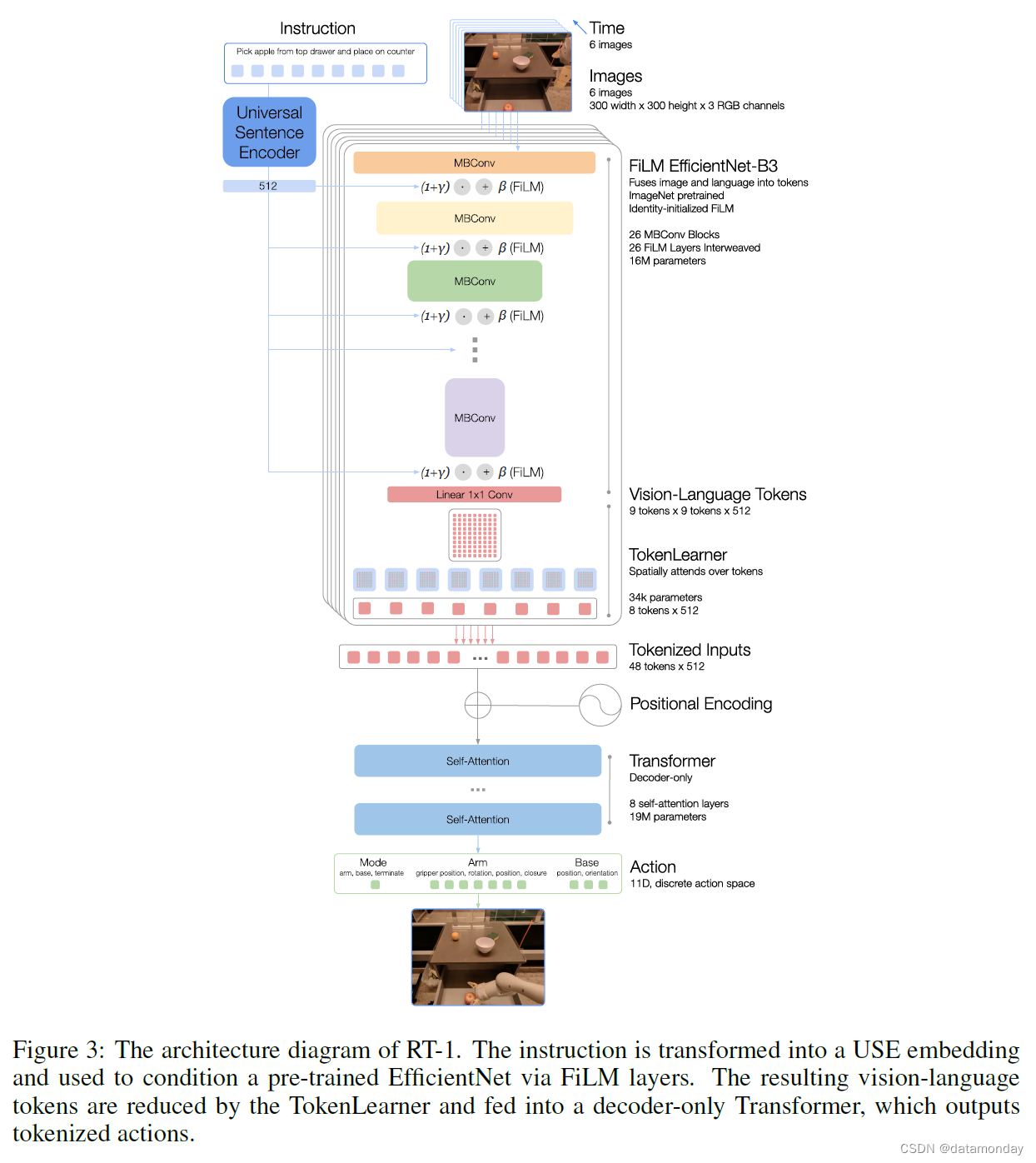
我们的模型建立在 Transformer 架构之上,将历史图像和任务描述作为输入,并直接输出标记化的动作,如图 1a 所示,详细内容见图 3。下面我们将按照图 3 中从上到下的顺序介绍模型的各个组成部分。附录 C.3 提供了更多有关规模模型选择的详细信息。
Instruction and image tokenization. RT-1 架构依赖于数据效率高、结构紧凑的图像标记和语言指令。RT-1 通过 ImageNet 预训练的 EfficientNet-B3 模型对 6 幅图像进行标记化,该模型将分辨率为 300 × 300 的 6 幅图像作为输入,并从最终卷积层输出形状为 9 × 9 × 512 的空间特征图。与 Reed 等人(2022)不同的是,我们在将图像输入 Transformer 骨干之前,并没有将图像补丁化(patchify)为视觉标记(visual tokens)。相反,我们将高效网络的输出特征图扁平化为 81 个视觉标记,并将其传递给网络的后几层。
为了包含语言指令(language instruction),我们以预训练语言嵌入的形式将自然语言指令作为图像标记器(image tokenizer)的条件,这样就能尽早提取与任务相关的图像特征,并提高 RT-1 的性能。指令首先通过 Universal Sentence Encoder (2018) 嵌入。然后将该嵌入作为 identity-initialized FiLM 层 (2018) 的输入,添加到预训练的 EfficientNet 中,以调节图像编码器。通常情况下,将 FiLM 层插入预训练网络的内部会破坏中间激活,从而抵消使用预训练权重的好处。为了克服这一问题,我们将产生 FiLM 仿射变换的全连接层( f c f_c fc 和 h C h_C hC)的权重初始化为零,从而让 FiLM 层在初始时充当恒等变换(identity),并保留预训练权重的功能。我们发现,在不使用 ImageNet 预训练的情况下,使用从头初始化的 EfficientNet 进行训练时,身份初始化的 FiLM 也能产生更好的结果,但并没有超过上述初始化方法。图像标记器的结构如图 3 所示。
RT-1 通过 FiLM EfficientNet-B3 进行的图像和指令标记化(instruction tokenization)总共需要 1600 万个参数,其中有 26 层 MBConv 块和 FiLM 层,可输出 81 个视觉语言标记(vision-language tokens)。
TokenLearner. 为了进一步压缩 RT-1 需要关注的标记数量,从而加快推理速度,RT-1 使用了 TokenLearner (2021)。TokenLearner 是一个 element-wise 的注意力模块,可以学习将大量标记映射到数量更少的标记中。这样,我们就能根据图像标记的信息对其进行软选择,只将重要的标记组合传递给后续的Transformer层。加入 TokenLearner 后,从预训练的 FiLM-EfficientNet 层中产生的 81 个视觉标记将被细分为 8 个最终标记,然后传递给我们的 Transformer 层。
Transformer. 然后,每个图像中的 8 个标记将与历史记录中的其他图像连接(concatenate)起来,形成 48 个标记(增加了位置编码),并输入 RT-1 的 Transformer 骨干。Transformer 是一个仅有解码器的序列模型,具有 8 个自注意层,总计 1900 万个参数,可输出动作标记。
Action tokenization. 为了标记化动作,RT-1 中的每个动作维度都被离散化为 256 个 bins。如前所述,我们所考虑的动作维度包括手臂运动的七个变量(x、y、z、滚动、俯仰、偏航、打开夹爪),底座运动的三个变量(x、y、偏航)以及在三种模式之间切换的离散变量:控制手臂,底座或终止事件。对于每个变量,我们将目标映射到 256 个分区中的一个,分区在每个变量的范围内均匀分布。
Loss. 我们使用标准的分类交叉熵目标和因果掩码(causal masking),这在之前的基于 Transformer 的控制器中得到了应用。
Inference speed. 与自然语言或图像生成等大型模型的许多应用不同,需要在真实机器人上实时运行的模型的一个独特要求是快速而一致的推理速度。考虑到人类执行本研究中的指令的速度(我们测得的速度在 2-4 秒之间),我们希望模型的速度不要明显慢于这一速度。根据我们的实验,这一要求相当于至少 3Hz 的控制频率,并且考虑到系统中的其他延迟,模型的推理时间预算应小于 100 毫秒。
这一要求限制了我们可以使用的模型规模。我们在实验中进一步探讨了模型大小对推理速度的影响。我们采用了两种技术来加快推理速度:
- i) 使用 TokenLearner (2021) 减少由预先训练好的 EfficientNet 模型生成的标记数量;
- ii) 只计算这些标记一次,并在以后推理重叠的窗口中重复使用。
这两种方法使我们的模型推断速度分别提高了 2.4 倍和 1.7 倍。有关模型推理的其他细节见附录 C.1。
5.2 DATA
我们的目标是建立一个表现出高性能、对新任务具有泛化能力、对干扰因素和背景具有鲁棒性的系统。因此,我们的目标是收集一个大型、多样化的机器人轨迹数据集,其中包括多种任务、物体和环境。我们的主要数据集由 13 个机器人组成,历时 17 个月,收集了 13 万次机器人演示。我们在图 2 所示的一系列办公室厨房(我们称之为机器人教室)中进行了大规模数据收集。有关数据收集的更多详情,请参阅附录 C.2。
Skills and instructions. 虽然文献中对任务的定义不尽相同,但在这项工作中,我们计算的是系统能够执行的语言指令数量,其中一个指令对应一个或多个名词包围的动词,例如 “place water bottle upright”、“move the coke can to the green chip bag” 或 “open the drawer”。RT-1 能够在多个真实的办公室厨房环境中执行 700 多条语言指令,我们将在实验中对这些指令进行评估和详细描述。为了对评估进行分组并得出系统性能的结论,我们按照指令中使用的动词(我们称之为技能(skills))对指令进行分组。表 1 列出了更详细的指令列表,并附有示例和每种技能的指令数量。

目前的这套技能包括:
- 挑选(picking)
- 放置(placing)
- 打开和关闭抽屉(opening and closing drawers)
- 将物品放入和取出抽屉(getting items in and out drawers)
- 将拉长的物品放在右上角(placing elongated items up-right)
- 将物品打翻(knocking them over)
- 拉餐巾纸(pulling napkins)
- 打开罐子(opening jars)
选择这些技能的目的是为了用许多物品展示多种行为(如图 2(e) 所示),以测试 RT-1 的各个方面,如对新指令的泛化能力和完成多项任务的能力。然后,我们大大扩展了 “pick” 技能的物体多样性,以确保该技能能够泛化到各种物体上(见图 2(f)中扩展的物体集)。在进行消融的同时,我们还进一步扩展了技能,将表 1 最后一行中添加的指令纳入其中,这些指令将用于第 6.4 和 6.3 节中所述的实验。这些新增技能主要针对办公室厨房中的真实的长视野(long-horizon)指令。添加任务和数据的整个过程见附录 C.4。由于我们在添加新指令时没有对特定技能做出任何假设,因此该系统很容易扩展,我们可以不断提供更多不同的数据来提升其能力。
6 Experiments
我们的实验旨在回答以下问题:
- RT-1 能否学会执行大量指令,以及对新任务、新物体和新环境进行零样本泛化?(第 6.2 节)
- 我们能否通过纳入异构数据源(如模拟数据或来自不同机器人的数据)来进一步推动由此产生的模型? 第 6.3 节)
- 各种方法如何泛化到长视野机器人场景?(第 6.4 节)
- 随着数据量和数据多样性的不同,泛化指标会发生怎样的变化?(第 6.5 节)
- 模型设计中有哪些重要而实用的决定,它们对性能和泛化有何影响?(附录 D.4 节)
在本节中,我们将与两个基准最新架构进行比较,即
- Gato(2022)
- BC-Z(2021)
重要的是,这两个模型都是在第 5.2 节中详细描述的我们的数据(这是我们系统的重要组成部分)上进行训练的,因为这些出版物中的原始模型不会表现出我们的评估任务所需的泛化特性。与 RT-1 类似,Gato 也是基于 Transformer 架构,但在多个方面与 RT-1 有所不同。
- 首先,它在计算图像标记时没有语言的概念,而且每个图像标记嵌入都是针对每个图像补丁单独计算的,这与我们模型中的早期语言融合和全局图像嵌入不同。其次,它不使用预先训练的文本嵌入来编码语言字符串。
- 此外,它也不包括推理时间方面的考虑因素,而这些因素对于第 5.1 节中讨论的真实机器人来说是必要的,例如 TokenLearner 和移除自动回归动作。
- 为了在真实机器人上以足够高的频率运行 Gato,我们还限制了模型的大小,与最初发表的 1.2B 参数(导致机器人推理时间为 1.9s)相比,Gato 的大小与 RT-1 类似(Gato 为 37M 参数,而 RT-1 为 35M)。
BC-Z 基于 ResNet 架构,曾用于 SayCan(2022)。
- BC-Z 与 RT-1 的不同之处在于,它是一个前馈模型,不使用之前的时间步,并且使用连续动作而非离散动作标记。
- 除了原始 BC-Z 模型的大小,我们还将我们的方法与 BC-Z 的更大版本进行了比较,后者的参数数量与 RT-1 类似,我们将其称为 BC-Z XL。
我们将在附录 D.4 和 D.5 部分研究和分析这些设计决策对性能的影响。
我们在实验中评估了成功率,以衡量训练指令的性能、对未见指令的泛化、对背景和干扰因素的鲁棒性,以及在长视野场景中的性能,详见下文。在本节中,我们将通过 3000 多次实际测试来评估我们的方法和基线,这是迄今为止对机器人学习系统进行的规模最大的评估之一。
6.1 EXPERIMENTAL SETUP
如第 4 节所述,我们使用 Everyday Robots 公司的一套移动机械手在三种环境中对 RT-1 进行了评估:两个真实的办公厨房和一个仿照这些真实厨房的训练环境。训练环境如图2(a)所示,由部分台面组成,而两个真实环境如图2(b,c)所示,台面与训练环境类似,但照明、背景和整个厨房的几何形状有所不同(例如,可能会有一个橱柜而不是抽屉,或者可能会看到一个水槽)。对这些策略的评估包括训练任务的性能、对新任务的泛化、对未知环境的鲁棒性,以及在长视野任务中一起使用时的性能,详情如下。
Seen task performance. 为了评估所见指令的性能,我们从训练集中抽样评估指令的性能。但需要注意的是,评估所见指令的性能涉及改变物体的摆放位置和其他设置因素(如一天中的时间、机器人的位置),这就要求技能能够适应环境中的实际变化。在本次评估中,我们总共测试了 200 多项任务: 其中,36 项任务用于拾取物体,35 项任务用于敲击物体,35 项任务用于将物体竖直放置,48 项任务用于移动物体,18 项任务用于打开和关闭各种抽屉,36 项任务用于将物体从抽屉中取出并放入抽屉。
Unseen tasks generalization. 为了评估对未见任务的通用性,我们测试了 21 项新的未见指令。这些指令分布在不同的技能和物体中。这就确保了每个物体和技能至少有一些实例存在于训练集中,但它们会以新颖的方式组合在一起。例如,如果 “捡起苹果” 被排除在外,那么其他训练指令中也会包含苹果。所有未见指令的列表见附录 D.1。
Robustness. 为了评估鲁棒性,我们在真实世界中执行了 30 项干扰鲁棒性任务和 22 项背景鲁棒性任务。
- 背景鲁棒性是通过在新的厨房(具有不同的照明和背景视觉效果)和不同的台面(例如有图案的桌布)进行评估来测试的。
- 鲁棒性评估场景的配置示例如图 4 所示。

Long-horizon scenarios. 我们还评估了对更现实的长视野的泛化能力,每个事件(episode)都需要执行一系列技能。这项**评估的目的是将新任务、新物体、新环境等多个泛化结合起来,在现实环境中测试整体泛化能力。这些评估包括两个真实厨房中的 15 个长视野指令,要求执行由 10 个不同步骤组成的技能序列,每个步骤的范围与训练指令大致相当。这些步骤是通过 SayCan (2022) 从更高层次的指令中自动获取的**,例如 “你会如何扔掉桌子上的所有物品吗?”,详见第 6.4 节和附录 D.3。
6.2 CAN RT-1 LEARN TO PERFORM A LARGE NUMBER OF INSTRUCTIONS, AND TO GENERALIZE TO NEW TASKS, OBJECTS AND ENVIRONMENTS?
为了回答第一个问题,我们分析了 RT-1 与之前提出的模型相比在整体性能、泛化和鲁棒性方面的能力。具体来说,我们与 Gato(2022)和 BC-Z(2021)使用的模型架构以及 BC-Z 的更大版本(我们称之为 BC-Z XL)进行了比较。但请注意,所有模型都是在与 RT-1 相同的数据上训练的,评估只比较模型架构,而不是任务集、数据集或整个机器人系统。RT-1 的能力在很大程度上由数据集和任务集决定,我们认为 RT-1 比之前的作品有了显著提高(例如,BC-Z 使用 100 个任务,而原始 Gato 模型训练的是各种形状的堆叠任务),因此这种比较应被视为对之前的模型相当有利,它们也受益于我们收集的大量不同的数据集和任务集。
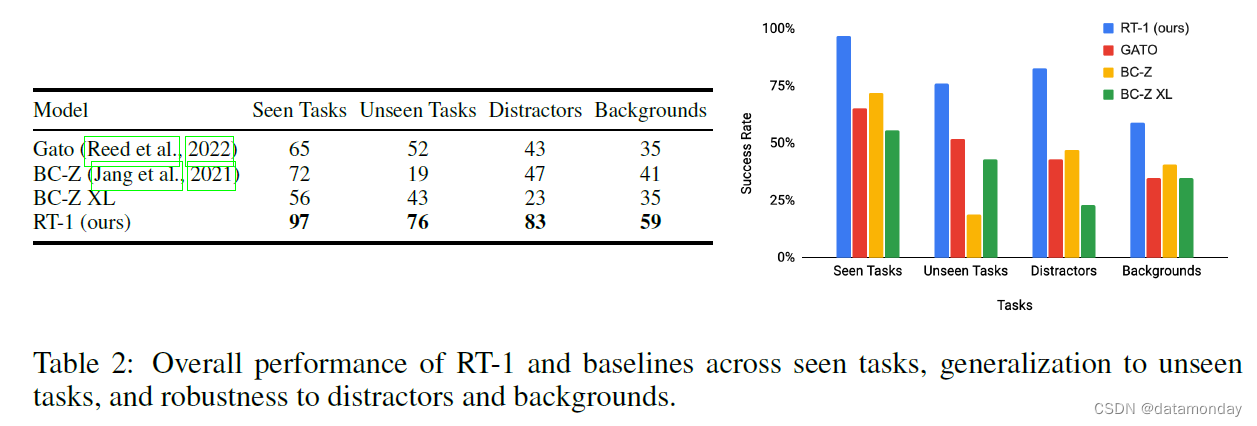
结果如表 2 所示。我们发现,在每个类别中,RT-1 都明显优于先前的模型。在可见任务中,RT-1 能够成功执行 200 多条指令中的 97%,比 BC-Z 多 25%,比 Gato 多 32%。在未见过的任务中,RT-1 显示出对新指令的泛化能力,执行了 76% 的从未见过的指令,比次优基线高出 24%。这种对新指令的泛化能力得益于策略的自然语言调节,因为策略能够理解以前见过的概念的新组合。我们将在下一节中进一步消减 RT-1 的不同组件,以更好地了解我们的方法在哪些方面对这种差异贡献最大。在干扰和背景方面,我们发现 RT-1 的鲁棒性相当高,成功执行了 83% 的干扰鲁棒性任务和 59% 的背景鲁棒性任务(分别比次佳替代方案高出 36% 和 18%)。总之,我们发现 RT-1 具有很高的通用性能,同时表现出令人印象深刻的通用性和鲁棒性。我们在图 5 中展示了 RT-1 代理的轨迹示例,包括涵盖不同技能、环境和物体的指令。我们还在附录中提供了不同泛化测试的其他轨迹示例,其中包括背景(图 10)和干扰(图 12)。

Generalization to realistic instructions. 接下来,我们要测试的是,我们的方法是否能够在我们之前评估过的所有不同轴上实现足够的通用性,以便在实际厨房中使用,因为**实际厨房中会同时出现多种分布变化,如新任务组合、物体干扰以及新环境**。
为了在真实厨房的现实场景中评估我们的算法,我们构建了任务序列来完成一系列现实目标。机器人在抽屉里储存了几个零食,整理被打翻的调味品瓶子,关闭被人类打开的抽屉,用橘子和餐巾纸准备点心,从厨房的几个地方取回丢失的太阳镜和章鱼玩具。附录 D.1 列出了这些场景中使用的详细说明。办公室厨房与培训环境相比发生了巨大变化,我们将这些情景中的任务按不同的通用程度进行了分类:
- L1 泛化到新的台面布局和照明条件;
- L2 泛化到未见的干扰物体;
- L3 泛化到全新的任务设置、新的任务物体或未见位置(如水槽附近)的物体。
图 4 最后一行显示了三个级别,分别对应真实厨房中的补货、准备点心和寻找丢失物品这三个任务。不同级别的轨迹示例见附录图 11。
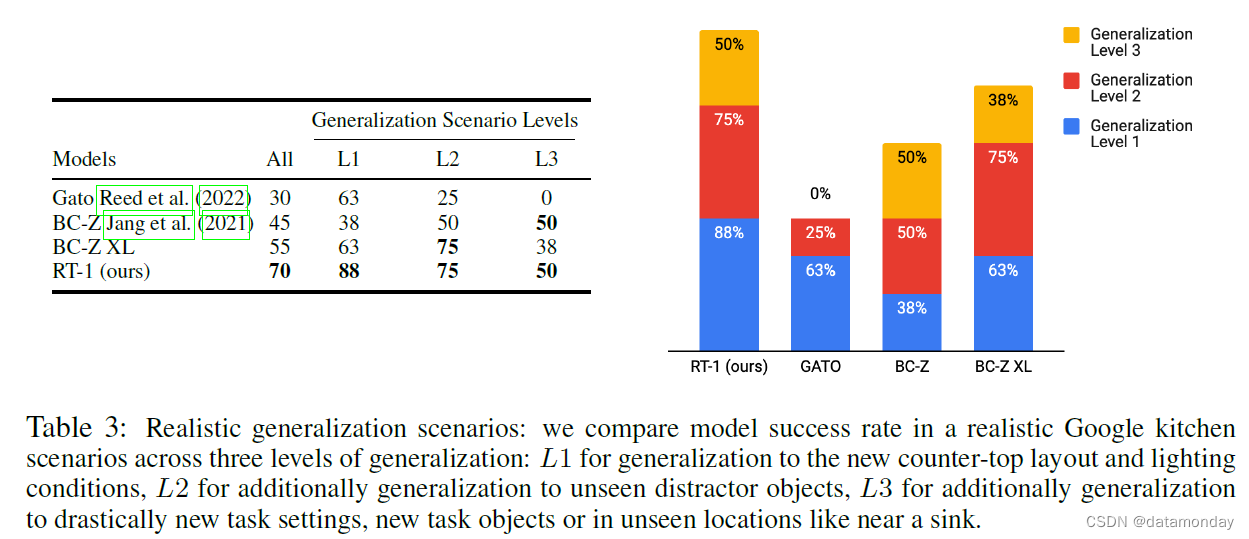
我们在表 3 中报告了在这些现实场景中每个任务的成功率以及不同的泛化级别,结果发现
- RT-1 在所有级别上都是最稳健的。
- Gato 在第一级的泛化效果相当好,但在难度较高的泛化场景中,它的表现明显下降。
- BC-Z 及其 XL 等效软件在 L2 级的表现相当好,在 L3 级的表现优于 Gato,但仍未达到 RT-1 的泛化水平。
6.3 CAN WE PUSH THE RESULTING MODEL FURTHER BY INCORPORATING HETEROGENEOUS DATA SOURCES SUCH AS SIMULATION OR DATA FROM DIFFERENT ROBOTS?
接下来,我们将探讨 RT-1 在利用高度异构数据方面的局限性。我们展示了 RT1 如何能从大量不同的数据源中整合和学习,并从这些数据中得到改进,而不影响其在这些数据固有的不同任务中的原始任务性能。为此,我们进行了两项实验:
- 1)RT-1 在真实数据和模拟数据上进行训练和测试;
- 2)RT-1 在不同任务的大型数据集上进行训练,这些数据集最初由不同的机器人收集。附录 D.2 提供了更多相关信息。
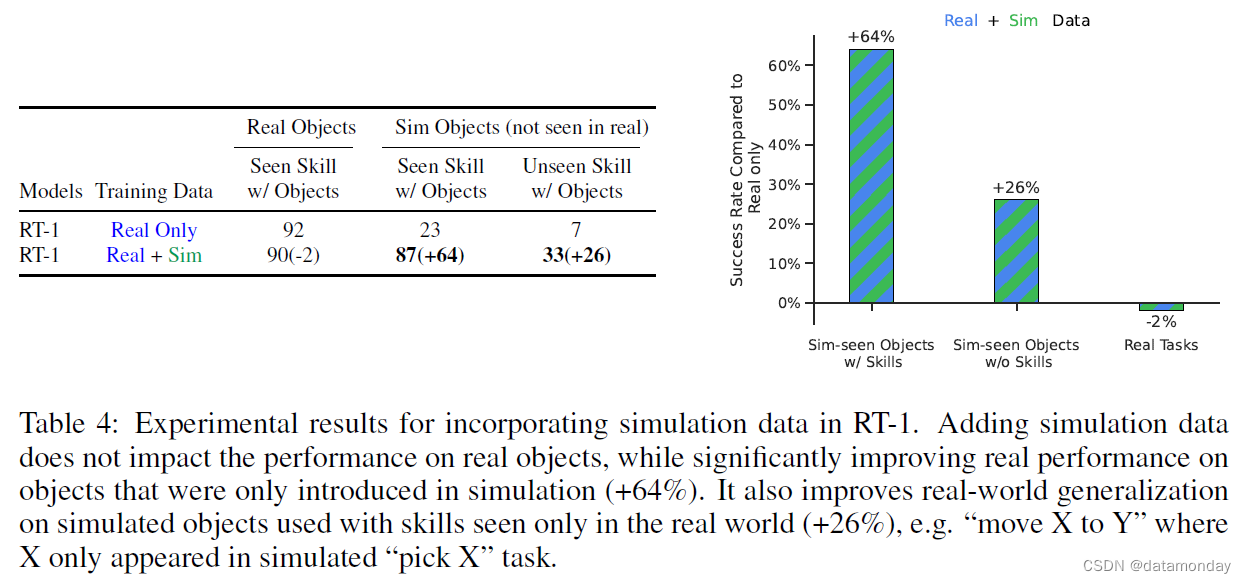
Absorbing simulation data. 表 4 显示了 RT-1 能力,包括能力基线,吸收真实和模拟数据的能力。为了测试这一点,我们使用了所有真实演示数据,但同时也提供了额外的模拟数据,其中包括机器人从未在真实世界中见过的物体。具体来说,我们指定了不同的泛化场景:
- 对于使用真实物体的已见技能(seen skills with real objects),训练数据包含该指令的真实数据(即在已见任务中的表现);
- 对于使用模拟物体的可见技能(seen skills with sim objects),训练数据中包含该指令的模拟数据(例如,“拿起一个模拟物体”,这在模拟中是存在的);
- 对于使用模拟物体的未见技能(unseen skills with sim objects),训练数据中包含该物体的模拟数据,但在模拟或现实中都没有描述使用该物体的技能的指令示例(例如,“将一个模拟物体移到苹果旁边”,尽管机器人只练习了拿起该模拟物体,而没有将它移到其他物体附近)。
所有评估都是在真实世界中进行的,但为了限制评估指令的数量,我们将重点放在拾取和移动到技能上。
我们在表 4 中发现,就 RT-1 而言,与仅真实数据集相比,增加模拟数据并不会降低性能。不过,我们确实看到,
- 在只在模拟中看到的物体和任务上,性能有了显著提高(从 23% 提高到 87%),与真实物体和任务的性能差不多,这表明领域迁移的程度令人印象深刻。
- 在未见过的指令上,RT-1 的表现也从 7% 显著提高到 33%;鉴于从未在真实环境中见过相关物体,也从未见过相关指令,RT-1 的表现给人留下了深刻印象。
总之,我们发现 RT-1 能够高效地吸收新数据,即使是来自截然不同领域的数据。

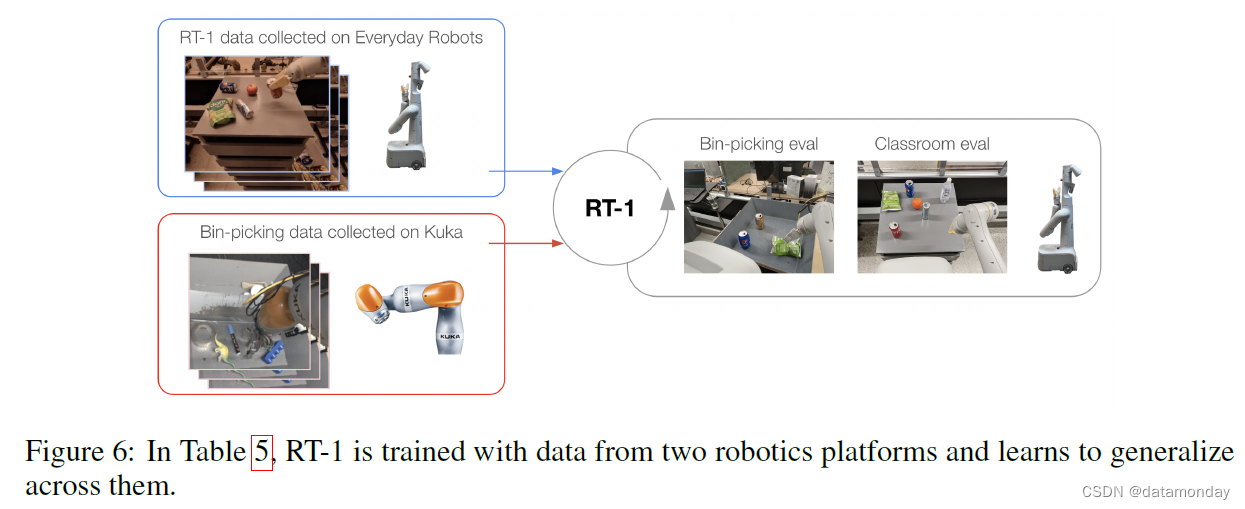
Absorbing data from different robots. 为了突破 RT-1 的数据吸收极限,我们进行了一组额外的实验,将来自不同机器人的两个数据源结合在一起:Kuka IIWA 以及迄今为止实验中使用的 Everyday Robots 公司的移动机械手。Kuka 数据包含 QT-Opt(2018)收集到的所有成功示例,相当于 209k 个事件,其中机器人不加区分地抓取垃圾箱中的物体(见表 5 中 Kuka 事件示例)。为了测试 RT-1 是否能有效吸收这两个截然不同的数据集,我们将其称为标准 “教室评估(Classroom eval)”,以及在新构建的任务上的表现,这些任务反映了 Kuka 数据中存在的垃圾桶抓取设置,我们将其称为 “垃圾桶抓取评估(Bin-picking eval)”(见图 6)。
我们希望通过指出数据集之间的主要差异来强调这一设置的难度。不仅收集数据的机器人在外观和动作空间上不同,而且它们所处的环境也具有不同的外观和动态特性。此外,QT-Opt 数据呈现了完全不同的动作分布–它是由 RL 智能体收集的,而不是我们数据集中的人类演示(human demonstrations)。
结果见表 5。我们注意到,混合使用 RT-1 数据和 Kuka 数据的模型在原始任务(即教室评估)中的表现仅略有下降,即 2%。更重要的是,在 “垃圾桶抓取评估” 中,我们观察到在多机器人数据上训练的模型性能为 39%,而只在 RT-1 数据上训练的模型性能为 22%。这是 17% 的性能差异(几乎是 2 倍)。此外,在 Kuka 垃圾桶拾取数据上训练的 RT-1 在使用 Everyday Robots (EDR) 机器人执行垃圾桶拾取任务时的表现为 0%,这证明很难从另一种机器人形态中迁移行为。不过,将两个机器人的数据混合后,即使面对 Kuka 机器人观察到的状态,RT-1 也能推断出 EDR 机器人的正确行为。这是在 EDR 机器人没有明确演示垃圾箱抓取的情况下,利用 Kuka 机器人过去收集的经验实现的。这些结果表明,RT-1 的吸收特性还包括通过观察其他机器人的经验来获取新技能的能力,这为我们今后的工作提供了一个令人兴奋的途径,即**我们可以结合更多的多机器人数据集来增强机器人的能力**。
6.4 HOW DO VARIOUS METHODS GENERALIZE LONG-HORIZON ROBOTIC SCENARIOS?
在下一组实验中,我们将评估我们的方法是否具有足够的通用性,可用于长视野现实厨房环境。为了回答这个问题,我们在两个不同的真实厨房中执行了 RT-1 和 SayCan(2022)框架中的各种基线。由于 SayCan 结合了许多低级指令来执行高级指令,因此可能的高级指令数量会随着技能的组合而增加,因此 RT-1 的技能广度可以得到充分体现。长视野任务的成功率也会随着任务的长度呈指数递减,因此操作技能的高成功率尤为重要。此外,由于移动操纵任务需要导航和操纵,因此策略对基础位置的稳健性至关重要。更多详情见附录 D.3。
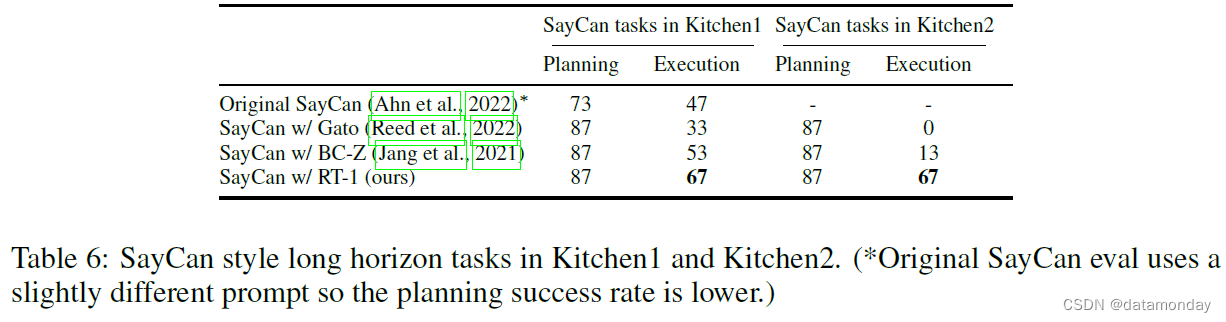
表 6 显示了我们的结果(附录表 12 中的说明)。除原始 SayCan 外,所有方法的规划成功率均为 87%,其中 RT-1 的表现最好,在 Kitchen1 中的执行成功率为 67%。Kitchen2 是一个更具挑战性的通用场景,因为机器人教室的训练场景是以Kitchen1 为模型的(见图 2 中的厨房图片)。由于这种泛化难度,使用 Gato 的 SayCan 无法完成任何长范围任务,而使用 BC-Z 的 SayCan 成功率仅为 13%。最初的 SayCan 论文没有评估新厨房的性能。令人惊讶的是,我们的方法在Kitchen1 到Kitchen2 的操作性能并没有明显下降。在补充视频中,我们展示了在Kitchen2 中操作未见过的抽屉,以及使用 SayCan-RT1 计划和执行多达 50 步的超长时间任务。
6.5 HOW DO GENERALIZATION METRICS CHANGE WITH VARYING AMOUNTS OF DATA QUANTITY AND DATA DIVERSITY?
虽然之前的研究表明,基于Transformer的模型具有随模型参数数量而扩展的能力,但**在许多机器人研究中,模型大小往往不是主要瓶颈,最大模型大小受限于在真实机器人上运行此类模型的延迟要求**。相反,在本研究中,我们专注于消除数据集大小和多样性的影响,因为它们在传统的数据有限的机器人学习领域中发挥着重要作用。由于真实机器人的数据收集成本特别高,因此量化我们的模型需要什么样的数据才能达到一定的性能和泛化效果非常重要。因此,我们最后一个问题的重点是 RT-1 在不同数据属性下的扩展特性。
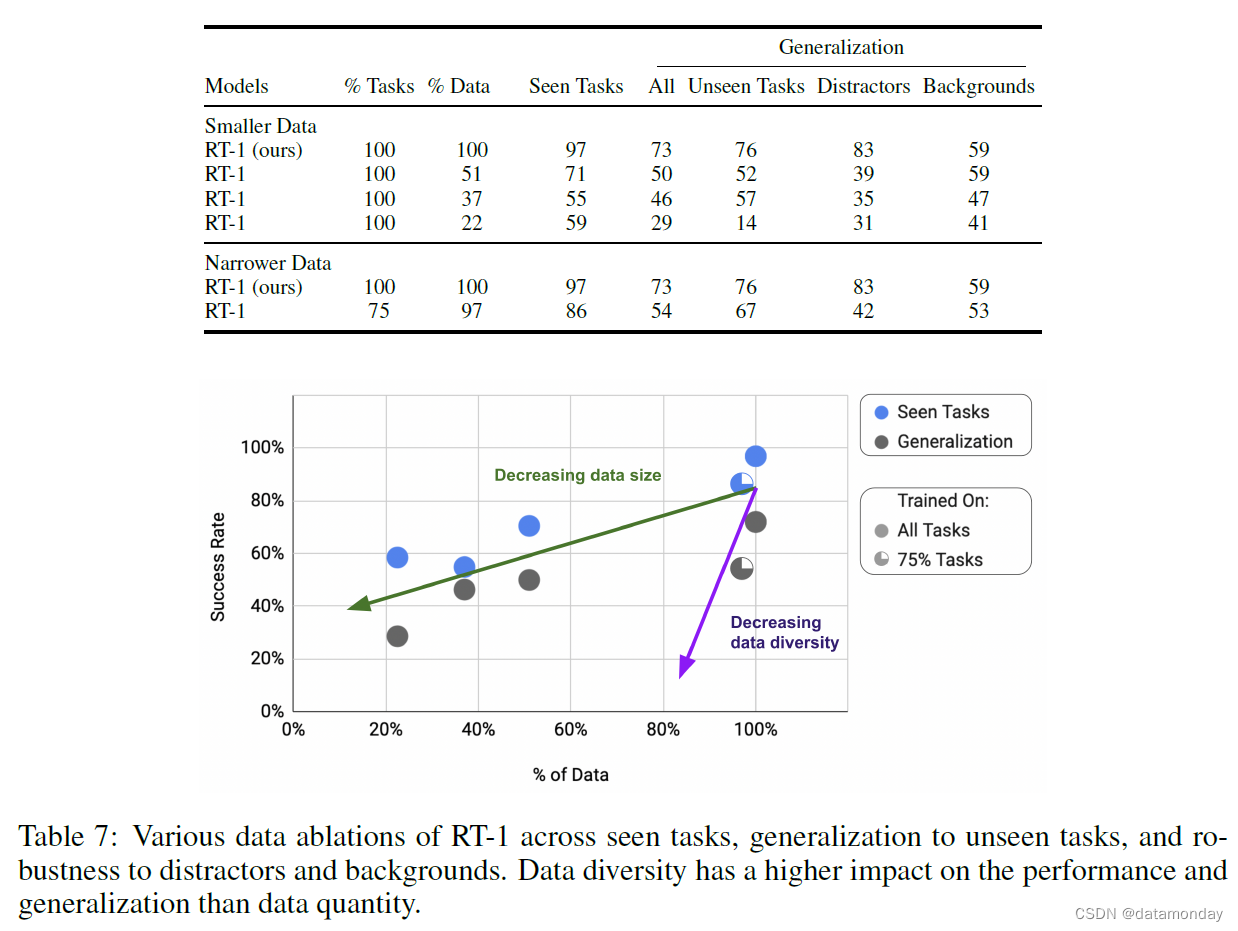
表 7 显示了随着数据集规模(数据百分比)和数据集多样性(任务百分比)的减小,RT-1 的性能、泛化和鲁棒性。为了将数据集大小和多样性这两个轴分开,我们创建了具有相同任务多样性的较小数据集,方法是从数据量最大的任务中移除数据,每个任务的示例数量上限分别为 200 个(占数据量的 51%)、100 个(占数据量的 37%)和 50 个(占数据量的 22.5%)。为了缩小数据集的规模,我们删除了数据最少的任务,因此保留了 97% 的总体数据,但只保留了 75% 的任务。随着数据集规模的缩小,我们发现性能总体呈下降趋势,而泛化程度则呈急剧下降趋势。随着数据集的缩小,我们发现性能下降的幅度更大,尤其是在泛化方面。事实上,在保留 97% 数据的同时移除 25% 的任务所获得的泛化性能相当于将数据集的规模缩小 49%。因此,我们得出的主要结论是,数据多样性比数据数量更重要。
7 CONCLUSIONS, LIMITATIONS AND FUTURE WORK
我们介绍了机器人Transformer 1 RT-1,这是一种能有效吸收大量数据的机器人学习方法,可随着数据数量和多样性的增加而扩展。我们在一个大型演示数据集上对 RT-1 进行了训练,该数据集包含 13 个机器人历时 17 个月收集的超过 13 万个事件。在一系列广泛的实验中,我们证明了我们的方法能够以 97% 的成功率执行 700 多条指令,并能有效地泛化到新的任务、物体和环境中,其效果优于之前发布的基线方法。我们还证明,RT-1 可以成功吸收来自模拟和其他机器人形态的异构数据,而不会牺牲原始任务的性能,同时还能提高对新场景的泛化能力。最后,我们展示了这种性能和泛化水平如何使我们能够在 SayCan (2022) 框架中执行多达 50 步的超长视野任务。
虽然 RT-1 为利用数据吸收模型进行大规模机器人学习迈出了充满希望的一步,但它也存在一些局限性。
- 首先,它是一种模仿学习方法,继承了该类方法所面临的挑战,例如它可能无法超越演示器的性能。
- 其次,对新指令的泛化仅限于以前见过的概念的组合,RT-1 还不能泛化到以前没见过的全新动作。
- 最后,我们的方法是在大量但并不十分灵巧的操作任务集上展示的。我们计划继续扩展 RT-1 支持和泛化的指令集,以应对这一挑战。
在探索这项工作的未来方向时,我们希望通过开发允许非专业人员**通过定向数据收集和模型提示来训练机器人的方法,从而更快地增加机器人技能的数量。虽然当前版本的 RT-1 具有相当强的鲁棒性,尤其是对干扰物体的鲁棒性,但它对背景和环境的鲁棒性还可以通过大大增加环境多样性来进一步提高。我们还希望通过可扩展的注意力和记忆来提高 RT-1 的反应速度和上下文保持(context retention)能力**。
为了让研究界能够在这项工作的基础上更上一层楼,我们已将 RT-1 的代码开源,希望这能为研究人员提供宝贵的资源,用于未来扩大机器人学习规模的研究。
A AUTHOR CONTRIBUTIONS
Evaluations (ablations, designing procedures, implementations, and running ablations): Yevgen Chebotar, Keerthana Gopalakrishnan, Karol Hausman, Julian Ibarz, Brian Ichter, Alex Irpan, Isabel Leal, Kuang-Huei Lee, Yao Lu, Ofir Nachum, Kanishka Rao, Sumedh Sontakke, Austin Stone, Quan Vuong, Fei Xia, Ted Xiao, and Tianhe Yu.
Network Architecture (tokenizer, training, inference): Yevgen Chebotar, Keerthana Gopalakrishnan, Julian Ibarz, Alex Irpan, Kuang-Huei Lee, Yao Lu, Karl Pertsch, Kanishka Rao, Michael Ryoo, Sumedh Sontakke, Austin Stone, and Quan Vuong.
Developed Infrastructure (data, training, collect, simulation, evaluations, storage, and operations): Anthony Brohan, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Yao Lu, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, and Tianhe Yu.
Leadership (managed or advised on the project): Chelsea Finn, Karol Hausman, Julian Ibarz, Sally Jesmonth, Sergey Levine, Yao Lu, Igor Mordatch, Carolina Parada, Kanishka Rao, Pannag Sanketi, Vincent Vanhoucke.
Paper (figures, vizualizations, writing): Keerthana Gopalakrishnan, Karol Hausman, Brian Ichter, Sergey Levine, Ofir Nachum, Karl Pertsch, Kanishka Rao, Austin Stone, Fei Xia, and Ted Xiao.
Data collection and evaluations: Noah Brown, Justice Carbajal, Joseph Dabis, Tomas Jackson, Utsav Malla, Deeksha Manjunath, Jodily Peralta, Emily Perez, Jornell Quiambao, Grecia Salazar, Kevin Sayed, Jaspiar Singh, Clayton Tan, Huong Tran, Steve Vega, and Brianna Zitkovich.
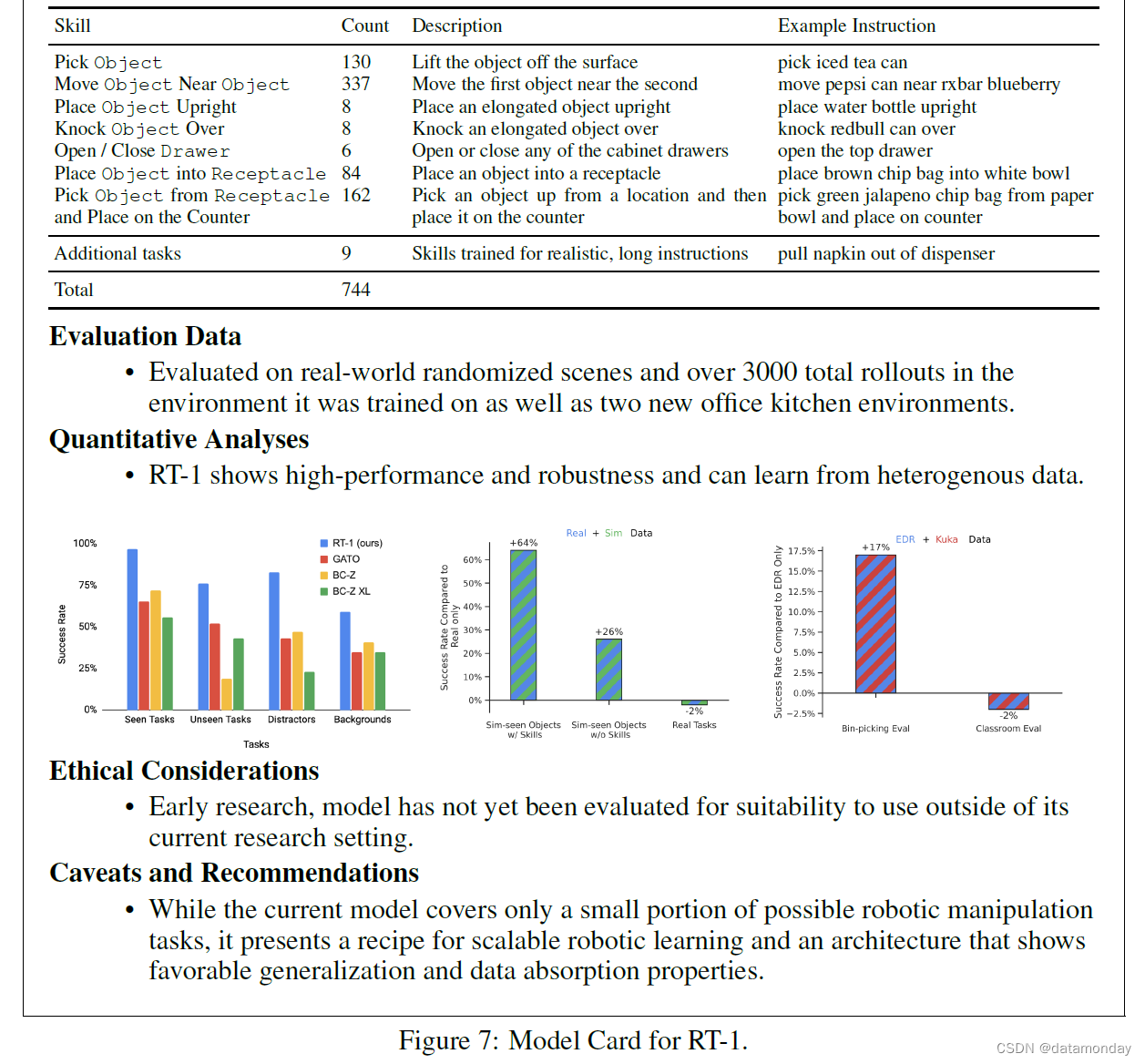
B MODEL CARD

C MODEL AND DATA
C.1 MODEL INFERENCE
除了推理速度要求外,我们还需要确保系统以一致的频率输出动作,避免抖动。为此,我们引入了一种固定时间等待机制,在捕捉到用于计算下一个动作的状态后,但在应用该动作之前,等待一定时间(280 毫秒,所有组件的最大观察延迟),这与 Thinking while moving(2020)描述的程序类似。
Thinking while moving: Deep reinforcement learning with concurrent control. 2020.
C.2 DATA COLLECTION AT SCALE
每一个机器人在事件(episode)开始时都会自主靠近自己的工作站,并向操作员传达他们应该向机器人演示的指令。为了确保数据集的平衡和场景的随机化,我们创建了一个软件模块,负责对要演示的指令进行采样,并对背景配置进行随机化。每个机器人都会告诉演示者如何随机化场景以及演示哪条指令。
我们使用 2 个虚拟现实遥控器(remotes),在操作员和机器人之间的直接视线范围内进行收集演示(demonstrations)。我们将遥控器映射到策略动作空间,以保持过渡动力学的一致性。遥控器的三维位置和旋转位移被映射为机器人工具的六维位移。操纵杆的 x,y 位置映射为移动底座的转弯角度和行驶距离。我们根据操纵杆指令计算并跟踪目标姿势的轨迹。
C.3 MODEL SELECTION AT SCALE
随着机器人学习系统的能力越来越强,可处理的指令数量越来越多,对这些模型进行评估变得越来越困难(Kalashnikov et al., 2021a; Jang et al., 2021)。这不仅是在开发过程中评估不同模型类别和数据分布的重要考虑因素,也是为特定训练运行选择性能最好的模型检查点的重要考虑因素。虽然针对这一问题已经提出了很多解决方案(Dud ́ık et al., 2011; Irpan et al., 2019; Hanna et al., 2017),这些方案在离线强化学习文献中大多被称为 “离策略评估(off-policy evaluation)”,但大规模评估多任务机器人学习系统仍然是一个尚未解决的研究难题。
在这项工作中,我们提出利用模拟来实现 “从真实到模拟” 的转移,作为一种可扩展的工具,它能在许多真实任务的训练过程中提供模型性能的近似估计。我们在模拟器中运行根据真实数据训练的策略,以测试全面推广的性能。请注意,我们的所有训练数据都来自真实世界(第 6.3 节中的实验除外),模拟器仅用于模型选择。为此,我们扩展了 Lee et al. (2022b) 提出的模拟环境,以支持第 5.2 节所述的 551 项任务。对于每项任务,我们都定义了一组场景设置随机化、机器人姿势随机化和成功检测标准。为了弥合真实世界与模拟之间的视觉分布偏差,我们训练了一个 RetinaGAN (Ho et al., 2020) 模型,该模型可将模拟图像转换为逼真的图像。然后,我们通过在每个时间步应用 RetinaGAN 视觉转换并测量推出模拟任务的成功率,将在真实数据上训练的策略直接部署到这些模拟环境中。
虽然仅根据真实世界数据训练的模型在真实世界中的表现要好于在模拟中的表现,但我们发现,在真实世界中表现好的策略的模拟成功率要高于在真实世界中表现差的策略的模拟成功率。换句话说,模拟策略成功率的排序对于预测真实世界策略成功率的排序具有参考价值。我们注意到,在这种 “真实到模拟” 的评估设置中,与 “模拟到真实” 的设置相比,我们对模拟准确性的要求并不那么严格;只要模拟成功率与真实成功率在方向上相关,我们就可以接受真实成功率与模拟成功率之间存在中等甚至较高的差距。
我们在图 8 中展示了模拟摄像机图像的示例及其基于 RetinaGAN 的转换。

C.4 DATA COLLECTION PROCESS
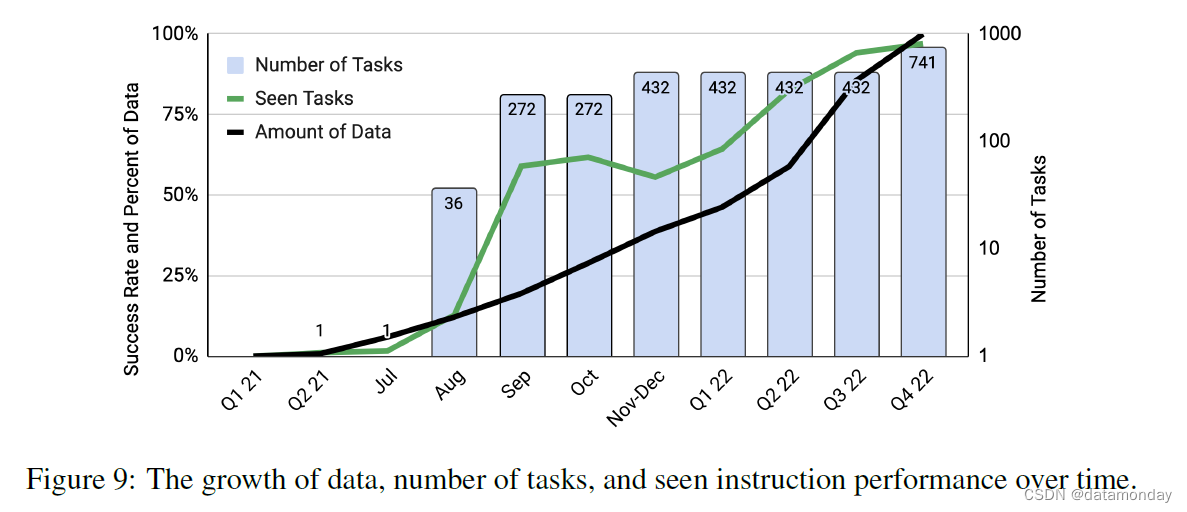
图 9 显示了随着时间推移,数据量、任务数和策略成功率的增长情况。随着时间的推移,收集到的数据越来越多,我们的系统能够处理的任务/指令数量也越来越多。所见任务的性能也是如此。未来工作的一个重要方面是开发技术,使我们能够以更快的速度增加数据以及机器人的性能和综合能力。
D EXPERIMENTS
D.1 EVALUATION DETAILS
在第 6.2 节中,我们将研究 RT-1 对训练数据集中不存在的困难场景的零点泛化能力。为了公平地评估 RT-1 的不同消融方式以及基线策略,我们设计了涵盖一系列递增难度的标准化评估程序。
Seen tasks. 我们对训练数据集中的 744 项任务进行了评估。表 1 显示了 12 种技能之间的细分。对于所有 Seen 评估,我们使用了与第 5.2 节所述数据收集相同的教室环境。对于每种策略,我们都会报告一个具有代表性的指标,该指标是对单个技能评估的技能加权平均值。
Unseen tasks. 我们对 53 个任务的策略性能进行了评估,这些任务在训练过程中被保留了下来。虽然在训练过程中没有看到未见指令的特定技能和物体组合,但训练集中存在相同技能和物体的其他组合。我们在与 Seen 相同的环境和随机化程序中对这些 Unseen 进行评估。表 8 列出了这些未见任务的完整列表。

Distractor robustness. 我们测试了三项任务(“捡起可乐罐”、“将可乐罐竖直放置”、“将可乐罐移至绿色薯片袋附近”),并在场景中逐步增加了干扰物体。
- 简单设置包括 0,2,5 个分散注意力的物体。
- 中等设置包括 9 个分散注意力的物体,但可乐罐从不被遮挡。
- 困难设置包括 9 个干扰物体,但场景更加拥挤,可乐罐被部分遮挡。
中等难度和高难度设置都比训练数据集中的场景更难,后者包含 0 到 4 个干扰物。图 12 显示了这些难度设置和策略评估推出的示例。

Background robustness. 我们测试了六项任务(“拾取可乐罐”、“将蓝色薯片袋靠近橙色薯片袋”、“将红牛罐推倒”、“拾取绿色墨西哥辣椒薯片袋”、“将海绵靠近棕色薯片袋”、“将红牛罐竖直放置”),并逐步增加了背景和计数器纹理的难度。
- 在简单设置中,我们使用与训练数据集相同的背景环境和反纹理。
- 在中等设置中,我们使用相同的背景环境,但增加了一块带图案的桌布来改变计数器纹理。
- 在高难度设置中,我们使用一个全新的厨房环境和一个全新的台面;这会改变台面纹理、抽屉材料和颜色以及背景视觉效果。
图 10 显示了这些难度设置和策略评估展开的示例。

Realistic instructions. 为了研究 RT-1 在更真实的场景中的表现,我们提出了在真实的办公室厨房中进行评估的设置,这与最初的训练时的教室环境有很大不同。我们提出了多种技能,这些技能结合了之前零样本评估的各个方面,包括添加新的干扰物,新的背景以及物体与技能的新组合。我们
- 将最简单的情景称为 L1 概括,它引入了新的台面和照明条件,但技能和物体保持不变。
- 接下来,L2 泛化会增加新的分散注意力的物体,如厨房的罐子容器。
- 最后,L3 泛化会增加新的物体或新的位置,如水槽附近。
虽然第 6.2 节中测试了其中一些分布转移,但这些现实的指令旨在同时测试多个维度。图 11 展示了这些指令的示例。

D.2 HETEROGENEOUS DATA
我们还探索了 RT-1 在利用高度异构数据方面的局限性。我们展示了 RT1 如何能从大量不同的数据源中整合和学习,并从这些数据中得到改进,而不影响其在这些数据固有的不同任务中的原始任务性能。为此,我们进行了两项实验:
- 1)RT-1 在真实数据和模拟数据上进行训练和测试;
- 2)RT-1 在最初由不同机器人收集的不同任务的大型数据集上进行训练。
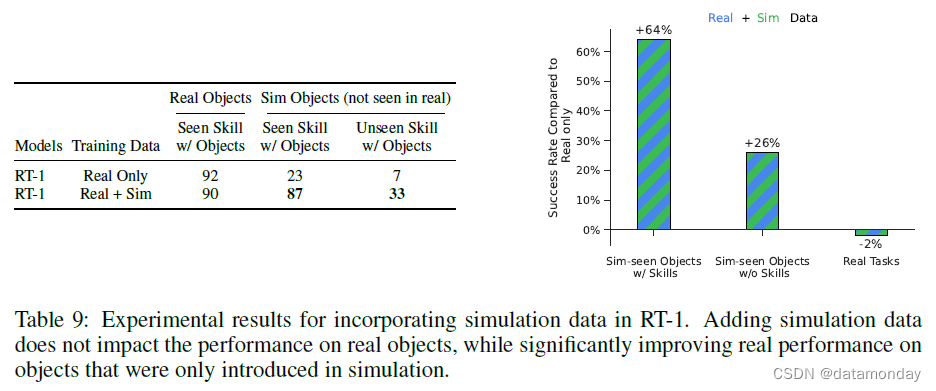
Absorbing simulation data. 表 9 显示了 RT-1 和基线吸收真实数据和模拟数据的能力。为了测试这一点,我们使用了所有真实演示数据,但同时也提供了额外的模拟数据,其中包括机器人从未在真实世界中见过的物体。我们添加了一组模拟物体,并仅在模拟任务(尤其是拾取任务)的子任务集上显示这些物体。为此,我们运行 C.3 节所述的 real2sim 方法,从真实世界的策略中引导出模拟策略,然后使用多任务 RL(MT-OPT,2021a)和模拟中的附加物体对该策略进行训练。在此过程中,我们提取了 518k 条挑选新物体的成功轨迹,并将其与之前实验中使用的真实数据混合。本实验的目的是证明,通过扩大模拟轨迹数据集,我们可以在不牺牲原始训练性能的情况下,提高 RT-1 的泛化能力–这是吸收模型(absorbent model)的理想特性。
为了评估该模型的特性,我们指定了不同的泛化情景:
- 对于使用真实物体的可见技能(seen skills with real objects),训练数据包含该指令的真实数据(即在可见任务中的表现);
- 对于使用模拟物体的可见技能(seen skills with sim objects),训练数据中包含该指令的模拟数据(例如,“拾起一个模拟物体”,这在模拟中是存在的);
- 对于使用模拟物体的未见技能(unseen skills with sim objects),训练数据中包含该物体的模拟数据,但在模拟或真实中都没有描述使用该物体的技能的指令示例(例如,“将一个模拟物体移到苹果旁”,尽管机器人只练习过拾起该模拟物体,而没有将它移到其他物体附近)。
所有评估都是在真实世界中进行的,但为了限制评估指令的数量,我们将重点放在拾取和移动到技能上。
我们在表 9 中发现,对于 RT-1,与仅真实数据集相比,增加模拟数据并不会降低性能。不过,我们确实看到,只在模拟中看到的物体和任务的性能有了显著提高(从 23% 提高到 87%),与真实物体和任务的性能相差无几,这表明领域迁移的程度令人印象深刻。我们还发现,在未见过的指令上,RT-1 的表现也从 7% 显著提高到 33%;鉴于 RT-1 从未在真实环境中见过相关物体,也从未见过相关指令,RT-1 的表现给人留下了深刻印象。总之,我们发现 RT-1 能够有效地 “吸收” 新数据,即使是来自截然不同领域的数据。
为了突破 RT-1 的数据吸收极限,我们进行了一组额外的实验,将来自不同机器人的两个数据源结合在一起:IIWA 以及迄今为止实验中使用的日常机器人移动机械手。Kuka 数据包含 QT-Opt (Kalashnikov 等人,2018 年)中收集的所有成功示例,相当于 209k 个情节,其中机器人不加区分地抓取垃圾箱中的物体(见表 10 中的 Kuka 情节示例)。我们在本实验中的目标是分析在添加额外数据时,RT-1 任务的性能是否会下降,更重要的是,我们是否能观察到由不同机器人形态收集的数据带来的任何转移。
我们希望通过指出数据集之间的主要差异来强调这一设置的难度。不仅收集数据的机器人在外观和动作空间上不同,而且它们所处的环境在外观和动态上也不同。此外,QT-Opt 数据呈现了完全不同的动作分布–它是由 RL 代理收集的,而不是我们数据集中的人类演示。
为了将 Kuka 数据与 RT-1 数据混合在一起,我们首先将原始 Kuka 4-DOF 动作空间转换为与 RT-1 相同的动作空间,即设置滚动和俯仰为 0,同时保留原始 Kuka 数据中的偏航值。此外,我们还将二进制抓手闭合指令(gripper-closedness command)转换为 RT-1 数据中的连续抓手闭合指令。我们还需要与所执行任务相对应的文本指令,由于 Kuka 数据中不包含所抓取物体的名称,因此我们将所有数据重新标注为 “任意抓取” 指令。经过这些修改后,我们以 2:1 的比例(RT-1 数据:Kuka 数据)混合两个数据集,并对 RT-1 进行训练,从而获得最终模型。
为了测试 RT-1 是否能有效吸收这两个截然不同的数据集,我们评估了 RT-1 原始任务(在本例中,我们还关注 "拾取 "和 "移动到 "技能)的性能,我们将其称为标准 “教室评估”,以及反映 Kuka 数据中垃圾桶拾取设置的新建任务的性能,我们将其称为 “垃圾桶拾取评估”。为了使 "垃圾桶拣选评估 "接近原始数据集,我们为物体设置了相同外观的垃圾桶,并通过添加额外的导线和将抓手涂成灰色来修改机器人,使其与 Kuka 机械手相似。在所有评估中,我们使用了带有抓取指令的 Everyday Robots 机器人,并根据 72 次抓取试验对其进行评估。
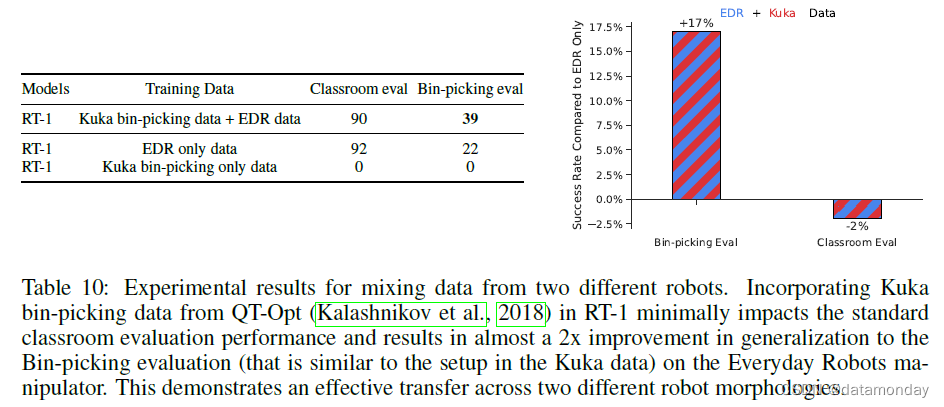
结果见表 10。我们发现,混合使用 RT-1 数据和 Kuka 数据的模型在原始任务(即教室评估)中的表现仅有极小的下降,即 2%。更重要的是,在 “Bin-picking” 评估中,我们观察到在多机器人数据上训练的模型性能为 39%,而只在 RT-1 数据上训练的模型性能为 22%。这是 17% 的性能差异(几乎是 2 倍)。此外,在 Kuka 垃圾桶拾取数据上训练的 RT-1 在使用 Everyday Robots (EDR) 机器人执行垃圾桶拾取任务时的表现为 0%,这证明很难从另一种机器人形态中转移行为。不过,将两个机器人的数据混合后,即使面对 Kuka 机器人观察到的状态,RT-1 也能推断出 EDR 机器人的正确行为。这是在 EDR 机器人没有明确演示垃圾箱拣选的情况下,利用 Kuka 机器人过去收集的经验实现的。这些结果表明,RT-1 的吸收特性还包括通过观察其他机器人的经验来获取新技能的能力,这为我们未来的工作提供了一个令人兴奋的途径,我们将结合更多的多机器人数据集来增强机器人的能力。
D.3 LONG-HORIZON EVALUATION DETAILS
除了前面章节中的短视野单项技能评估外,我们还评估了 RT-1 在长视野现实厨房环境中的表现,该环境包含多种操作和导航技能,以便在 SayCan(2022)内完成自然语言指令。表 12 列出了用于这些评估的长视野指令列表。

长视野任务的成功率随着任务的长度呈指数级下降,因此操纵技能的高成功率尤为重要。此外,由于移动操纵任务需要导航和操纵,因此策略对基础位置的稳健性至关重要。由于 SayCan 结合了许多低级指令来执行高级指令,可能的高级指令数量会随着指令的组合而增加,因此 RT-1 的技能广度可以得到充分体现。
SayCan 的工作原理是将语言模型建立在机器人可承受能力的基础上,并利用少量提示将自然语言表达的长期任务分解为一系列低级技能。例如,“给我拿两杯不同的苏打水”,可行的计划是 “1.找到可乐,2.拿起可乐,3.拿给你,4.放下可乐,5.找到百事可乐,6.拿起百事可乐,7.拿给你,8.放下百事可乐,9.完成”。为了获得承受能力函数,我们使用了通过 MT-OPT(2021a)训练的值函数。
由于本文的重点是获取许多可泛化的技能,因此我们将评估重点放在了 SayCan(2022)提出的一个任务子集上。这是长视野系列任务,涉及 15 个指令,每个指令平均需要 9.6 个步骤才能完成,每个指令平均涉及 2.4 个操作技能。指令的完整列表见表 12。
我们与 3 个基线进行了比较。
- 1)使用 BC-Z 的 SayCan,它使用以 BC-Z 作为操作策略的 SayCan 规划算法;
- 2)使用 Gato 的 SayCan,它使用以 Gato 作为操作策略的 SayCan 规划算法;
- 3)最初报道的 SayCan 结果,它使用以 BC-Z 作为操作策略的 SayCan 规划算法,但由于它使用的提示略有不同,规划成功率较低。
为了进行公平比较,我们在 1) 中重新实施了 3) 算法。
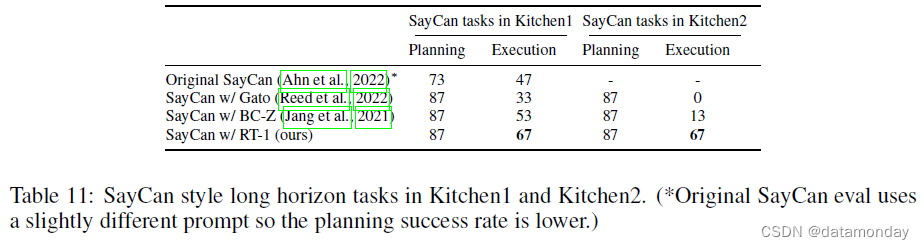
如表 11 所示,除原始 SayCan 外,其他方法的规划成功率均为 87%,其中 RT-1 的表现最好,在 Kitchen1 中的执行成功率为 67%。厨房 2 是一个更具挑战性的泛化场景,因为机器人教室的训练场景是以厨房 1 为模型的(见图 2 中的厨房图片)。由于这种泛化难度,使用 Gato 的 SayCan 无法完成任何长范围任务,而使用 BC-Z 的 SayCan 成功率仅为 13%。最初的 SayCan 论文没有评估新厨房的性能。令人惊讶的是,我们的方法在厨房 1 到厨房 2 的操作性能并没有明显下降。在补充视频中,我们展示了在厨房 2 中操作未见过的抽屉,以及使用 SayCan-RT1 计划和执行多达 50 步的超长时间任务。
D.4 MODEL ABLATIONS
模型设计中的重要和实际决策是什么以及它们如何影响性能和泛化?
为了回答这个问题,我们对 RT-1 中的不同设计决策进行了一系列消减。我们的目标是测试一系列假设,以帮助我们明确我们方法的优势来自何处。关于改进来源的可能假设包括:
- i) 我们模型的容量和表达能力,我们通过消减模型大小、尝试其他架构(例如,通过移除 Transformer 组件)来验证这一点;
- ii) 特定的动作表示法,它可以轻松表示复杂的多模态动作分布,我们通过切换到连续(正态分布)动作以及删除自动回归动作表示法来验证这一点;
- iii) ImageNet 预先训练的组件初始化,我们通过随机初始化模型权重来验证这一点;以及(iv)对简短历史记录的访问,我们通过排除观察历史记录来验证这一点。
更具体地说,我们通过以下方式消减模型:
- 1)减少模型大小(从 3500 万参数减少到 2100 万参数);
- 2)取消 Transformer 架构(使用预训练的 EfficientNet 代替);
- 3)使用连续而非离散的动作空间(使用 MSE 损失和多元正态输出);
- 4)对动作进行自动回归调节;
- 5)取消对 FiLM EfficientNet 的 ImageNet 预训练;
- 6)取消历史记录(将作为输入的六幅图像序列减少为单幅图像)。
对于每种消融情况,我们都会以看到的任务的成绩,未看到的任务的成绩以及推理速度和对干扰项和背景的稳健性为轴进行比较(每个类别的详细说明见第 6.1 节和附录 D.1)。
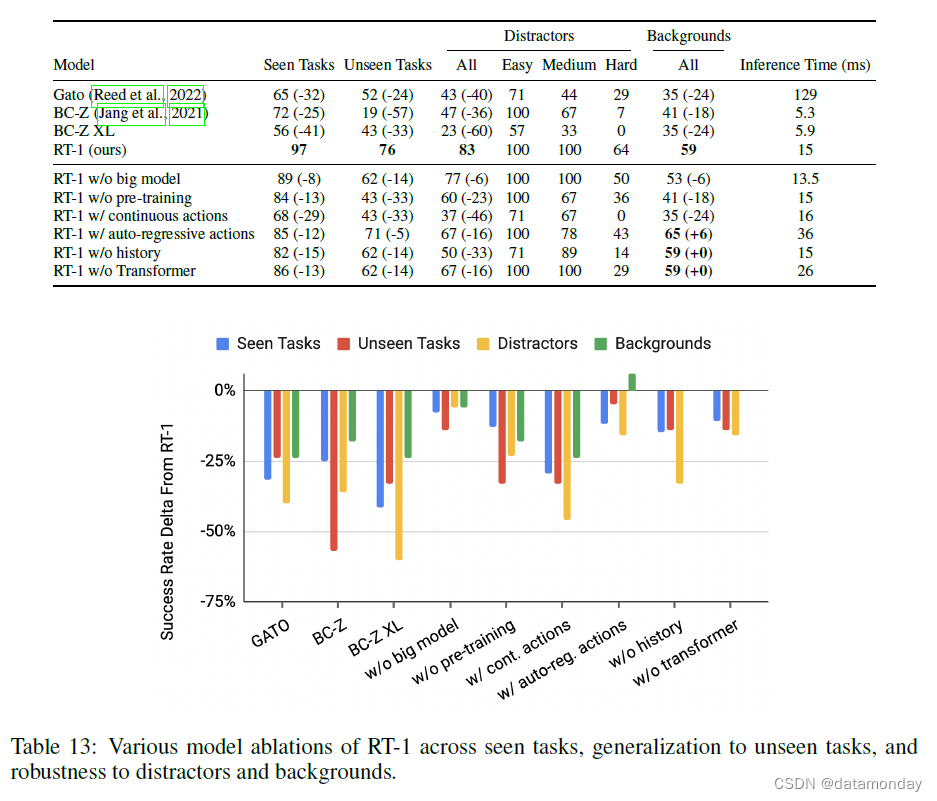
表 13 显示了每次消融的结果以及与完整 RT-1 相比的 delta 性能。RT-1 在任务和新环境中的表现令人印象深刻,尤其是在最具挑战性的鲁棒性问题上,RT-1 的表现优于基线。我们还发现,每个设计决策都很重要,只是程度不同而已。我们首先对一个模型进行了评估,该模型用更标准的连续高斯分布取代了我们模型中按维度离散的动作表示。我们发现这一修改导致性能显著下降。按维度离散化使我们的模型能够表示复杂的多模态分布,而高斯分布只能捕捉单一模态。这些结果表明,对于我们的系统所使用的更为复杂多样的演示数据来说,这种标准和流行的选择非常不理想。ImageNet 预训练对模型的泛化和鲁棒性尤为重要,由于 ImageNet 数据集的视觉效果庞大多样,因此未见任务的表现率降低了 33%。添加历史记录主要影响了干扰项任务的泛化,而移除 Transformer 组件则对已见任务,未见任务和干扰项任务产生了一致但微小的负面影响。为了在保持 ImageNet 预训练的同时缩小模型规模,我们只将参数数量减少了 40%(从 3100 万减少到 2500 万)。结果在训练和泛化任务中的性能都有所下降,但降幅没有其他消减方法那么大。最后,(Reed et al., 2022; Chen et al., 2021; Lee et al., 2022a) 中使用的对动作进行自回归调节的方法并不能提高性能,反而会使推理速度减慢 2 倍以上。
如第 5.1 节所述,为了在真实机器人上运行大型 Transformer 模型,我们需要一个支持快速推理的模型来实现实时操作。请注意,为了实现 3Hz 的目标控制速率(如第 5.1 节所述),我们还需要考虑流水线中的其他延迟来源,例如相机延迟和通信开销。不过,这些因素在所有模型中都是不变的,因此我们只对网络推理时间进行评估。表 13 最后一列显示了所有模型的推理速度。在参数数量相似的情况下,RT-1 比 Gato 快了近一个数量级,但也比基于 ResNet 的 BC-Z 慢很多。就我们模型的不同消减而言,我们观察到最大的减慢是由包含自动回归动作引起的(减慢 2 倍),由于这对性能没有显著影响,RT-1 的最终版本没有自动回归生成动作。
D.5 SUMMARY AND ANALYSIS
在本节中,我们将总结我们的一些发现,并提出 RT-1 的高性能,泛化和鲁棒性的直观原因。
- 首先,ImageNet 预训练(以及通用句子编码器语言嵌入)对未见任务的影响很大。我们观察到,RT-1 继承了这些模型所训练的数据集的通用性和多样性所产生的一些知识。
- 其次,连续动作对性能的各个方面都有很大影响。这在以前也曾被观察到过,可能是由于我们的模型能够表示更复杂的动作分布–每维离散化允许我们的模型表示复杂的多模态分布,而高斯分布只能捕捉单一模态。
- 第三,考虑到这种多任务模型的表现力,数据多样性比数据大小的影响更大。事实上,RT-1 甚至可以利用在模拟环境或不同机器人装置中收集的数据集,为新的数据收集方式开辟道路。
最后,RT-1 通过 FiLM 调节将语言提前融合到图像流水线中,而 Gato 的融合时间较晚。这使得图像标记只关注手头指令的相关特征,而这可能是 Gato 干扰效果不佳的原因。图 13 显示了 RT-1 的滚动过程中的注意力情况。我们可以看到,注意力都集中在相关特征上,尤其是抓手与感兴趣物体之间的互动。这些注意力层的瓶颈导致了一种紧凑的表征,从而有效地忽略了干扰因素和不同的背景。
