分类目录:《深入理解强化学习》总目录
策略评估就是给定马尔可夫决策过程和策略,评估我们可以获得多少价值,即对于当前策略,我们可以得到多大的价值。我们可以直接把贝尔曼期望备份(Bellman Expectation Backup) ,变成迭代的过程,反复迭代直到收敛。这个迭代过程可以看作同步备份(Synchronous Backup) 的过程。同步备份是指每一次的迭代都会完全更新所有的状态,这对于程序资源的需求特别大。异步备份(Asynchronous Backup)的思想就是通过某种方式,使得每一次迭代不需要更新所有的状态,因为事实上,很多状态也不需要被更新。
下式是指我们可以把贝尔曼期望备份转换成动态规划的迭代。 当我们得到上一时刻的 V t V_t Vt的时候,就可以通过递推的关系推出下一时刻的值。 反复迭代,最后 V V V的值就是从 V 1 , V 2 V_1, V_2 V1,V2到最后收敛之后的值就是 V t π V_t\pi Vtπ。 V t π V_t\pi Vtπ就是当前给定的策略 π \pi π对应的价值函数。
V t + 1 ( s ) = ∑ a ∈ A π ( a ∣ s ) ( R ( s , a ) + γ ∑ s ′ ∈ S p ( s ′ ∣ s , a ) V t ( s ′ ) ) V_{t+1}(s)=\sum_{a\in A}\pi(a|s)(R(s, a)+\gamma\sum_{s'\in S}p(s'|s, a)V_t(s')) Vt+1(s)=a∈A∑π(a∣s)(R(s,a)+γs′∈S∑p(s′∣s,a)Vt(s′))
策略评估的核心思想就是把如上式所示的贝尔曼期望备份反复迭代,然后得到一个收敛的价值函数的值。因为已经给定了策略函数,所以我们可以直接把它简化成一个马尔可夫奖励过程的表达形式,相当于把 a a a去掉,即:
V t + 1 ( s ) = r π ( s ) + γ P π ( s ′ ∣ s ) V t ( s ′ ) V_{t+1}(s)=r_\pi(s)+\gamma P_\pi(s'|s)V_t(s') Vt+1(s)=rπ(s)+γPπ(s′∣s)Vt(s′)
这样迭代的式子中就只有价值函数与状态转移函数了。通过迭代上式,我们也可以得到每个状态的价值。因为不管是在马尔可夫奖励过程,还是在马尔可夫决策过程中,价值函数 V V V包含的变量都是只与状态有关,其表示智能体进入某一个状态,未来可能得到多大的价值。比如现在的环境是一个小网格世界(Small Gridworld),智能体的目的是从某一个状态开始行走,然后到达终止状态,它的终止状态就是左上角与右下角(如下右图所示的阴影方块)。
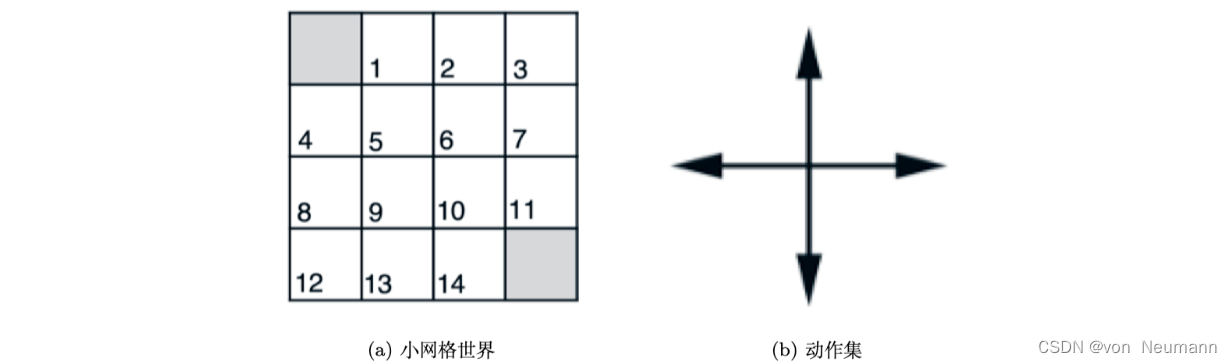
小网格世界总共有14个非终止状态: 1 , 2 , ⋯ , 14 1, 2, \cdots, 14 1,2,⋯,14。我们把它的每个位置用一个状态来表示。如上左图所示,在小网格世界中,智能体的策略函数直接给定了,它在每一个状态都是随机行走,即在每一个状态都是上、下、左、右行走,采取均匀的随机策略(Uniform Random Policy),即 π ( ↑ ∣ ⋅ ) = π ( ↓ ∣ ⋅ ) = π ( ← ∣ ⋅ ) = π ( → ∣ ⋅ ) = 0.25 \pi(\uparrow|\cdot)=\pi(\downarrow|\cdot)=\pi(\leftarrow|\cdot)=\pi(\rightarrow|\cdot)=0.25 π(↑∣⋅)=π(↓∣⋅)=π(←∣⋅)=π(→∣⋅)=0.25。 它在边界状态的时候,比如在第4号状态的时候往左走,依然留在第4号状态。我们对其加了限制,这个限制就是出边界的动作不会改变状态,相应概率设置为1,如 p ( 7 ∣ 7 , → ) = 1 p(7|7, \rightarrow)=1 p(7∣7,→)=1。 我们给出的奖励函数就是智能体每走一步,就会得到 − 1 -1 −1的奖励,也就是到达终止状态之前每走一步获得的奖励都是 − 1 -1 −1,所以智能体需要尽快地到达终止状态。
给定动作之后状态之间的转移(Transition)是确定的,例如 p ( 2 ∣ 6 , ↑ ) = 1 p(2|6, \uparrow)=1 p(2∣6,↑)=1,即从第6号状态往上走,它就会直接到达第2号状态。很多时候有些环境是概率性的(Probabilistic),比如智能体在第6号状态,它选择往上走的时候,地板可能是滑的,然后它可能滑到第3号状态或者第1号状态,这就是有概率的转移。但我们把环境进行了简化,从6号状态往上走,它就到了第2号状态。因为我们已经知道环境中的每一个概率以及概率转移,所以就可以直接使用上式进行迭代,这样就会算出每一个状态的价值。
我们再来看一个动态的例子,推荐斯坦福大学的一个网页,这个网页模拟了上式的单步更新的过程中,所有格子的状态价值的变化过程。
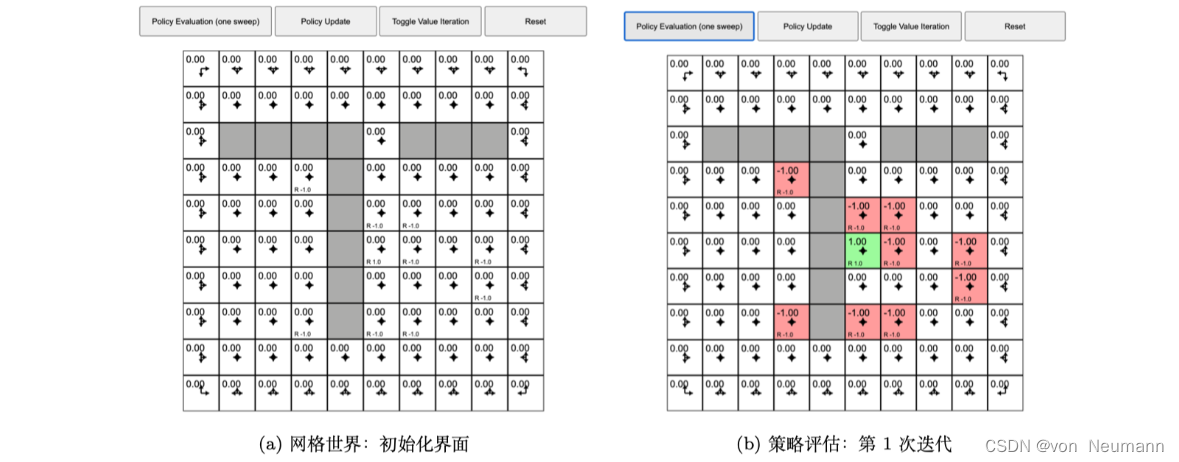
如下图(a)所示,网格世界里面有很多格子,每个格子都代表一个状态。每个格子里面有一个初始值0。每个格子里还有一个箭头,这个箭头是指智能体在当前状态应该采取什么策略。我们这里采取随机的策略,不管智能体在哪一个状态,它往上、下、左、右的概率都是相同的。比如在某个状态,智能体都有上、下、左、右各0.25的概率采取某一个动作,所以它的动作是完全随机的。在这样的环境里面,我们想计算每一个状态的价值。我们也定义了奖励函数,我们可以看到有些格子里面有一个 R R R的值,比如有些值是负的。我们可以看到有几个格子里面是 − 1 -1 −1的奖励,只有一个 + 1 +1 +1奖励的格子。在网格世界的中间位置,我们可以看到有一个 R R R的值是1。所以每个状态对应一个值,有一些状态没有任何值,它的奖励就为0。
如下图(b)所示,我们开始策略评估,策略评估是一个不停迭代的过程。当我们初始化的时候,所有的 V ( s ) V(s) V(s)都是0。我们现在迭代一次,迭代一次之后,有些状态的值已经产生了变化。比如有些状态的 R R R值为 − 1 -1 −1,迭代一次之后,它就会得到 − 1 -1 −1的奖励。对于中间绿色的格子,因为它的奖励为正,所以它是值为 + 1 +1 +1的状态。当迭代第1次的时候,某些状态已经有些值的变化。
如下图(a)所示,我们再迭代一次,之前有值的状态的周围状态也开始有值。因为周围状态与之前有值的状态是临近的,所以这就相当于把周围的状态转移过来。如图下图(b)所示,我们逐步迭代,值是一直在变换的。
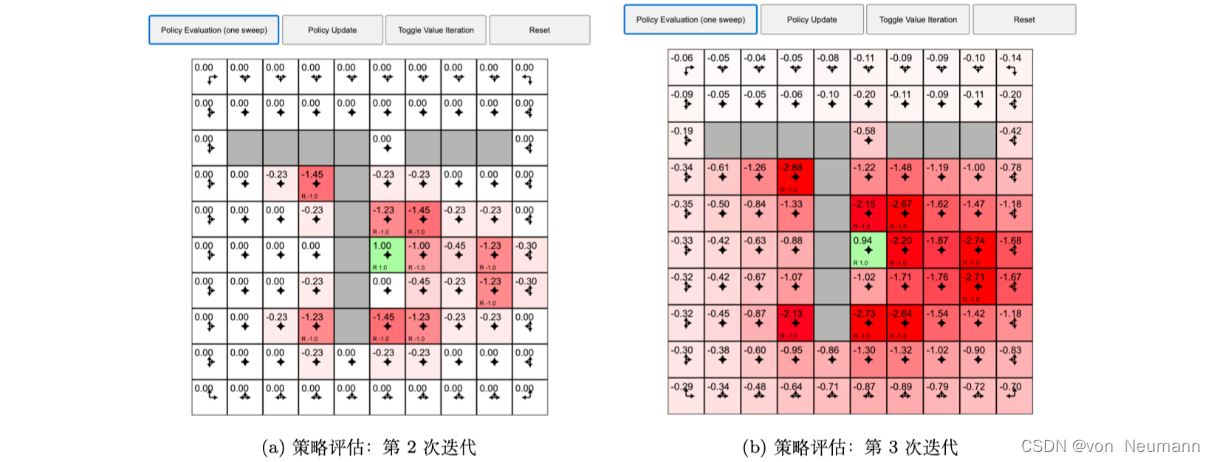
当我们迭代了很多次之后,有些很远的状态的价值函数已经有值了,而且整个过程是一个呈逐渐扩散的过程,这其实也是策略评估的可视化。当我们每一步进行迭代的时候,远的状态就会得到一些值,值从已经有奖励的状态逐渐扩散。当我们执行很多次迭代之后,各个状态的值会逐渐稳定下来,最后值就会确定不变。收敛之后,每个状态的值就是它的状态价值。
参考文献:
[1] 张伟楠, 沈键, 俞勇. 动手学强化学习[M]. 人民邮电出版社, 2022.
[2] Richard S. Sutton, Andrew G. Barto. 强化学习(第2版)[M]. 电子工业出版社, 2019
[3] Maxim Lapan. 深度强化学习实践(原书第2版)[M]. 北京华章图文信息有限公司, 2021
[4] 王琦, 杨毅远, 江季. Easy RL:强化学习教程 [M]. 人民邮电出版社, 2022