分类目录:《深入理解强化学习》总目录
《深入理解强化学习——马尔可夫决策过程》系列前面的文章讨论到的马尔可夫过程和马尔可夫奖励过程都是自发改变的随机过程,而如果有一个外界的“刺激”来共同改变这个随机过程,就有了马尔可夫决策过程(Markov Decision Process,MDP)。我们将这个来自外界的刺激称为智能体(Agent)的动作,在马尔可夫奖励过程(MRP)的基础上加入动作,就得到了马尔可夫决策过程(MDP)。马尔可夫决策过程由元组 ( S , A , P , r , γ ) (S, A, P, r, \gamma) (S,A,P,r,γ)构成,其中:
- S S S是状态的集合
- A A A是动作的集合
- P P P是折扣因子
- r ( s , a ) r(s, a) r(s,a)是奖励函数,此时奖励可以同时取决于状态 s s s和动作 a a a,在奖励函数只取决于状态 s s s时,则退化为 r ( s ) r(s) r(s)
- P ( s ′ ∣ s , a ) P(s'|s, a) P(s′∣s,a)是状态转移函数,表示在状态 s s s执行动作 a a a之后到达状态 s ′ s' s′的概率
我们发现马尔可夫决策过程与马尔可夫奖励过程非常相像,主要区别为马尔可夫决策过程中的状态转移函数和奖励函数都比马尔可夫奖励过程多了动作作为自变量。注意,在上面马尔可夫决策过程的定义中,我们不再使用类似马尔可夫奖励过程定义中的状态转移矩阵方式,而是直接表示成了状态转移函数。这样做一是因为此时状态转移与动作也有关,变成了一个三维数组,而不再是一个矩阵(二维数组);二是因为状态转移函数更具有一般意义,例如,如果状态集合不是有限的,就无法用数组表示,但仍然可以用状态转移函数表示。我们在之后的课程学习中会遇到连续状态的马尔可夫决策过程环境,那时状态集合都不是有限的。现在我们主要关注于离散状态的马尔可夫决策过程环境,此时状态集合是有限的。
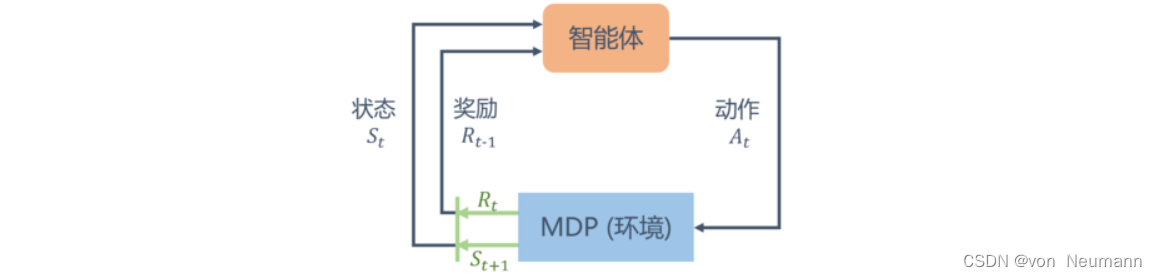
不同于马尔可夫奖励过程,在马尔可夫决策过程中,通常存在一个智能体来执行动作。例如,一艘小船在大海中随着水流自由飘荡的过程就是一个马尔可夫奖励过程,它如果凭借运气漂到了一个目的地,就能获得比较大的奖励;如果有个水手在控制着这条船往哪个方向前进,就可以主动选择前往目的地获得比较大的奖励。马尔可夫决策过程是一个与时间相关的不断进行的过程,在智能体和环境马尔可夫决策过程之间存在一个不断交互的过程。一般而言,它们之间的交互是如下图循环过程:智能体根据当前状态 S t S_t St选择动作 A t A_t At;对于状态 S t S_t St和动作 A t A_t At,马尔可夫决策过程根据奖励函数和状态转移函数得到 S t + 1 S_{t+1} St+1和 R t R_t Rt并反馈给智能体。智能体的目标是最大化得到的累计奖励。智能体根据当前状态从动作的集合 A A A中选择一个动作的函数,被称为策略。
综上所述,相对于马尔可夫奖励过程,马尔可夫决策过程多了决策(决策是指动作),其他的定义与马尔可夫奖励过程的是类似的。此外,状态转移也多了一个条件,变成了 p ( s t + 1 = s ′ ∣ s t = s , a t = a ) p(s_{t+1}=s'|s_t=s, a_t=a) p(st+1=s′∣st=s,at=a)。未来的状态不仅依赖于当前的状态,也依赖于在当前状态智能体采取的动作。马尔可夫决策过程满足条件: p ( s t + 1 ∣ s t , a t ) = p ( s t + 1 ∣ h t , a t ) p(s_{t+1}|s_t, a_t)=p(s_{t+1}|h_t, a_t) p(st+1∣st,at)=p(st+1∣ht,at)
对于奖励函数,它也多了一个当前的动作,变成了 R ( s t = s , a t = a ) = E [ r t ∣ s t = s , a t = a ] R(s_t=s, a_t=a)=E[r_t|s_t=s, a_t=a] R(st=s,at=a)=E[rt∣st=s,at=a]。当前的状态以及采取的动作会决定智能体在当前可能得到的奖励多少。
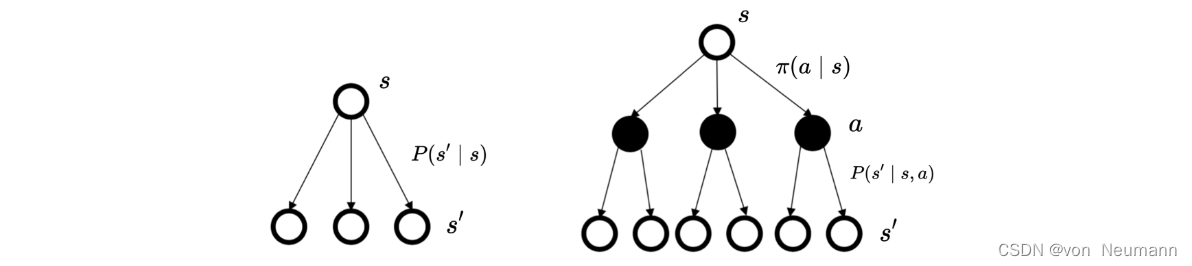
马尔可夫决策过程里面的状态转移与马尔可夫奖励过程以及马尔可夫过程的状态转移的差异如下图所示。马尔可夫过程/马尔可夫奖励过程的状态转移是直接决定的。比如当前状态是 s s s,那么直接通过转移概率决定下一个状态是什么。但对于马尔可夫决策过程,它的中间多了一层动作 a a a,即智能体在当前状态的时候,首先要决定采取某一种动作,这样我们会到达某一个黑色的节点。到达这个黑色的节点后,因为有一定的不确定性,所以当智能体当前状态以及智能体当前采取的动作决定过后,智能体进入未来的状态其实也是一个概率分布。在当前状态与未来状态转移过程中多了一层决策性,这是马尔可夫决策过程与之前的马尔可夫过程/马尔可夫奖励过程很不同的一点。在马尔可夫决策过程中,动作是由智能体决定的,智能体会采取动作来决定未来的状态转移。
参考文献:
[1] 张伟楠, 沈键, 俞勇. 动手学强化学习[M]. 人民邮电出版社, 2022.
[2] Richard S. Sutton, Andrew G. Barto. 强化学习(第2版)[M]. 电子工业出版社, 2019
[3] Maxim Lapan. 深度强化学习实践(原书第2版)[M]. 北京华章图文信息有限公司, 2021
[4] 王琦, 杨毅远, 江季. Easy RL:强化学习教程 [M]. 人民邮电出版社, 2022