分类目录:《深入理解强化学习》总目录
文章《深入理解强化学习——马尔可夫决策过程:贝尔曼期望方程-[基础知识]》中提到,不同策略的价值函数是不一样的。这是因为对于同一个马尔可夫决策过程,不同策略会访问到的状态的概率分布是不同的。想象一下,在下图的马尔可夫决策过程中现在有一个策略,它的动作执行会使得智能体尽快到达终止状态 s 5 s_5 s5,于是当智能体处于状态 s 3 s_3 s3时,不会采取“前往 s 4 s_4 s4”的动作,而只会以1的概率采取“前往 s 5 s_5 s5”的动作,所以智能体也不会获得在 s 4 s_4 s4状态下采取“前往 s 5 s_5 s5”可以得到的很大的奖励10。可想而知,根据贝尔曼方程,这个策略在状态的概率会比较小,究其原因是因为它没法到达状态。因此我们需要理解不同策略会使智能体访问到不同概率分布的状态这个事实,这会影响到策略的价值函数。
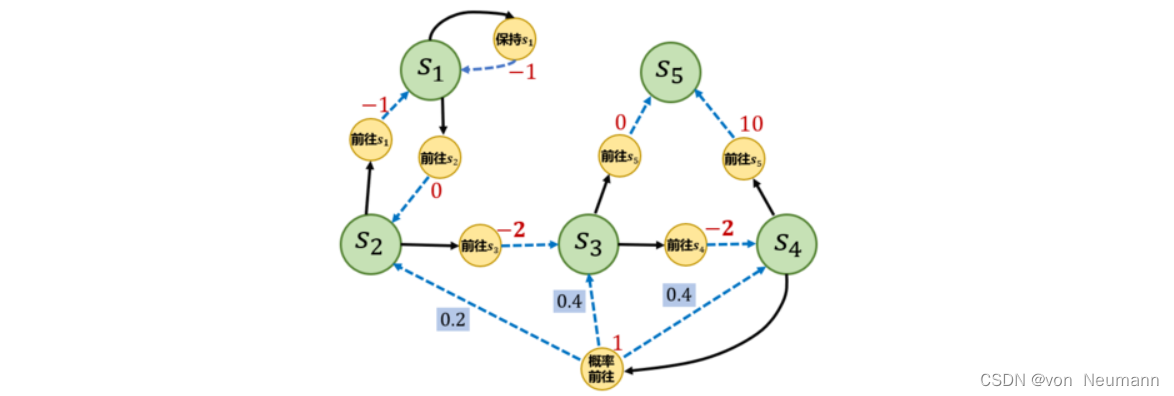
首先我们定义马尔可夫决策过程的初始状态分布为 v 0 ( s ) v_0(s) v0(s),在有些资料中,初始状态分布会被定义进马尔可夫决策过程的组成元素中。我们用 P t π ( s ) P_t^\pi(s) Ptπ(s)表示采取策略 π \pi π使得智能体在时刻 t t t状态为 s s s的概率,所以我们有 P 0 π ( s ) = v 0 ( s ) P_0^\pi(s)=v_0(s) P0π(s)=v0(s),然后就可以定义一个策略的状态访问分布(State Visitation Distribution):
v π ( s ) = ( 1 − γ ) ∑ t = 1 ∞ γ t P t π ( s ) v^\pi(s)=(1-\gamma)\sum_{t=1}^\infty\gamma^tP_t^\pi(s) vπ(s)=(1−γ)t=1∑∞γtPtπ(s)
其中, 1 − γ 1-\gamma 1−γ是用来使得概率加和为1的归一化因子。状态访问概率表示一个策略和马尔可夫决策过程交互会访问到的状态的分布。需要注意的是,理论上在计算该分布时需要交互到无穷步之后,但实际上智能体和马尔可夫决策过程的交互在一个序列中是有限的。不过我们仍然可以用以上公式来表达状态访问概率的思想,状态访问概率有如下性质:
v π ( s ′ ) = ( 1 − γ ) v 0 ( s ′ ) + γ ∫ P ( s ′ ∣ s , a ) π ( a ∣ s ) v π ( s ) d s d a v^\pi(s')=(1-\gamma)v_0(s')+\gamma\int P(s'|s, a)\pi(a|s)v^\pi(s)\text{d}s\text{d}a vπ(s′)=(1−γ)v0(s′)+γ∫P(s′∣s,a)π(a∣s)vπ(s)dsda
此外,我们还可以定义策略的占用度量(Occupancy Measure):
ρ π ( s , a ) = ( 1 − γ ) ∑ t = 1 ∞ γ t P t π ( s ) π ( a ∣ s ) \rho^\pi(s, a)=(1-\gamma)\sum_{t=1}^\infty\gamma^tP_t^\pi(s)\pi(a|s) ρπ(s,a)=(1−γ)t=1∑∞γtPtπ(s)π(a∣s)
它表示动作状态对 ( s , a ) (s, a) (s,a)被访问到的概率。二者之间存在如下关系:
ρ π ( s , a ) = v π ( s ) π ( a ∣ s ) \rho^\pi(s, a)=v^\pi(s)\pi(a|s) ρπ(s,a)=vπ(s)π(a∣s)
进一步我们可以得出如下两个定理:
- 定理 1:智能体分别以策略 π 1 \pi_1 π1和 π 2 \pi_2 π2和同一个马尔可夫决策过程交互得到的占用度量和满足: ρ π 1 = ρ π 2 ⇔ π 1 = π 2 \rho^{\pi_1}=\rho^{\pi_2}\Leftrightarrow\pi_1=\pi_2 ρπ1=ρπ2⇔π1=π2
- 定理 2:给定一合法占用度量 ρ \rho ρ,可生成该占用度量的唯一策略是: π ρ = ρ ( s , a ) ∑ a ′ ρ ( s , a ′ ) \pi_\rho=\frac{\rho(s, a)}{\sum_{a'}\rho(s, a')} πρ=∑a′ρ(s,a′)ρ(s,a)
以上提到的“合法”占用度量是指存在一个策略使智能体与马尔可夫决策过程交互产生的状态动作对被访问到的概率。
参考文献:
[1] 张伟楠, 沈键, 俞勇. 动手学强化学习[M]. 人民邮电出版社, 2022.
[2] Richard S. Sutton, Andrew G. Barto. 强化学习(第2版)[M]. 电子工业出版社, 2019
[3] Maxim Lapan. 深度强化学习实践(原书第2版)[M]. 北京华章图文信息有限公司, 2021
[4] 王琦, 杨毅远, 江季. Easy RL:强化学习教程 [M]. 人民邮电出版社, 2022