Java集合框架基本接口/类框架层次:
java.util.Collection [I]
+--java.util.List [I]
+--java.util.ArrayList [C]
+--java.util.LinkedList [C]
+--java.util.Vector [C] //线程安全
+--java.util.Stack [C] //线程安全
+--java.util.Set [I]
+--java.util.HashSet [C]
+--java.util.SortedSet [I]
+--java.util.TreeSet [C]
+--Java.util.Queue[I]
+--java.util.Deque[I]
+--java.util.PriorityQueue[C]
java.util.Map [I]
+--java.util.SortedMap [I]
+--java.util.TreeMap [C]
+--java.util.Hashtable [C] //线程安全
+--java.util.HashMap [C]
+--java.util.LinkedHashMap [C]
+--java.util.WeakHashMap [C]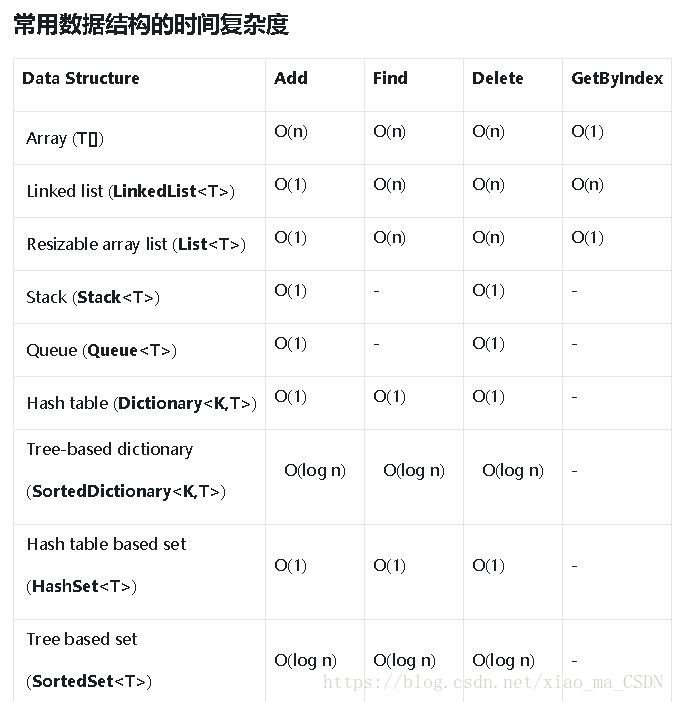
选择数据结构
Array (T[])
当元素的数量是固定的,并且需要使用下标时。
Linked list (LinkedList)
当元素需要能够在列表的两端添加时。否则使用 List。
Resizable array list (List)
当元素的数量不是固定的,并且需要使用下标时。
Stack (Stack)
当需要实现 LIFO(Last In First Out)时。
Queue (Queue)
当需要实现 FIFO(First In First Out)时。
HashMap
当需要使用键值对(Key-Value)来快速添加和查找,允许存在null。
Hash table (Dictionary K,T> )
当需要使用键值对(Key-Value)来快速添加和查找,并且元素没有特定的顺序时。
数组
数组是相同数据类型的元素按一定顺序排列的集合,是一块连续的内存空间。
数组的优点是:get和set操作时间上都是O(1)的;缺点是:add和remove操作时间上都是O(N)的。
Java中,Array就是数组,此外,ArrayList使用了数组Array作为其实现基础,它和一般的Array相比,最大的好处是,我们在添加元素时不必考虑越界,元素超出数组容量时,它会自动扩张保证容量。
Vector和ArrayList相比,主要差别就在于多了一个线程安全性,但是效率比较低下。如今java.util.concurrent包提供了许多线程安全的集合类(比如 LinkedBlockingQueue),所以不必再使用Vector了。
ArrayList 是长度可变的数组,并且它可以存储不同类型的元素。
链表
List 接口的链接列表实现。
在列表中编索引的操作将从开头或结尾遍历列表(从靠近指定索引的一端)。
链表与数组有着同样的线性运行时间 O(n)。
同样,从链表中删除一个节点的渐进时间也是线性的O(n)。因为在删除之前我们仍然需要从 head 开始遍历以找到需要被删除的节点。而删除操作本身则变得简单,即让被删除节点的左节点的 next 指针指向其右节点。
向链表中插入一个新的节点的渐进时间取决于链表是否是有序的。如果链表不需要保持顺序,则插入操作就是常量时间O(1),可以在链表的头部或尾部添加新的节点。而如果需要保持链表的顺序结构,则需要查找到新节点被插入的位置,这使得需要从链表的头部 head 开始逐个遍历,结果就是操作变成了O(n)。
链表与数组的不同之处在于,数组的中的内容在内存中时连续排列的,可以通过下标来访问,而链表中内容的顺序则是由各对象的指针所决定,这就决定了其内容的排列不一定是连续的,所以不能通过下标来访问。如果需要更快速的查找操作,使用数组可能是更好的选择。
使用链表的最主要的优势就是,向链表中插入或删除节点无需调整结构的容量。而相反,对于数组来说容量始终是固定的,如果需要存放更多的数据,则需要调整数组的容量,这就会发生新建数组、数据拷贝等一系列复杂且影响效率的操作。即使是 List 类,虽然其隐藏了容量调整的复杂性,但仍然难逃性能损耗的惩罚。
Java中,LinkedList 使用链表作为其基础实现。
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("one");//add
linkedList.set(0,"oneUpdate");//set,必须先保证 linkedList中已经有第0个元素
String s = linkedList.get(0);//get
linkedList.contains("s");//查找
linkedList.remove("s");//删除队列
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端进行删除操作,而在表的后端进行插入操作,亦即所谓的先进先出(FIFO)。
Java中,LinkedList实现了Deque,可以做为双向队列(自然也可以用作单向队列)。另外PriorityQueue实现了带优先级的队列,亦即队列的每一个元素都有优先级,且元素按照优先级排序。
Deque<Integer> integerDeque = new LinkedList<>();
// 尾部入队,区别在于如果失败了
// add方法会抛出一个IllegalStateException异常,而offer方法返回false
integerDeque.offer(122);
integerDeque.add(122);
// 头部出队,区别在于如果失败了
// remove方法抛出一个NoSuchElementException异常,而poll方法返回false
int head = integerDeque.poll();// 返回第一个元素,并在队列中删除
head = integerDeque.remove();// 返回第一个元素,并在队列中删除
// 头部出队,区别在于如果失败了
// element方法抛出一个NoSuchElementException异常,而peek方法返回null。
head = integerDeque.peek();// 返回第一个元素,不删除
head = integerDeque.element();// 返回第一个元素,不删除栈
栈(stack)又名堆栈,它是一种运算受限的线性表。其限制是仅允许在表的一端进行插入和删除运算。这一端被称为栈顶,相对地,把另一端称为栈底。它体现了后进先出(LIFO)
的特点。
Java中,Stack实现了这种特性,但是Stack也继承了Vector,所以具有线程安全线和效率低下两个特性,最新的JDK8中,推荐用Deque来实现栈,比如:
Deque<Integer> stack = new ArrayDeque<Integer>();
stack.push(12);//尾部入栈
stack.push(16);//尾部入栈
int tail = stack.pop();//尾部出栈,并删除该元素
tail = stack.peek();//尾部出栈,不删除该元素集合
集合是指具有某种特定性质的具体的或抽象的对象汇总成的集体,这些对象称为该集合的元素,其主要特性是元素不可重复。
在Java中,HashSet体现了这种数据结构,而HashSet是在MashMap的基础上构建的。
LinkedHashSet继承了HashSet,使用HashCode确定在集合中的位置,使用链表的方式确定位置,所以有顺序。
TreeSet实现了SortedSet 接口,是排好序的集合(在TreeMap 基础之上构建),因此查找操作比普通的Hashset要快(log(N));插入操作要慢(log(N)),因为要维护有序。
哈希表
散列表也叫哈希表,是根据关键键值(Keyvalue)进行访问的数据结构,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度,这个映射函数叫做散列函数。
Java中HashMap实现了散列表,而Hashtable比它多了一个线程安全性,但是由于使用了全局锁导致其性能较低,所以现在一般用ConcurrentHashMap来实现线程安全的HashMap(类似的,以上的数据结构在最新的java.util.concurrent的包中几乎都有对应的高性能的线程安全的类)。
TreeMap实现SortMap接口,能够把它保存的记录按照键排序。LinkedHashMap保留了元素插入的顺序。
WeakHashMap是一种改进的HashMap,它对key实行“弱引用”,如果一个key不再被外部所引用,那么该key可以被GC回收,而不需要我们手动删除。
HashMap 详解
1、hashmap的数据结构
在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的。Hashmap实际上是一个数组和链表的结合体。
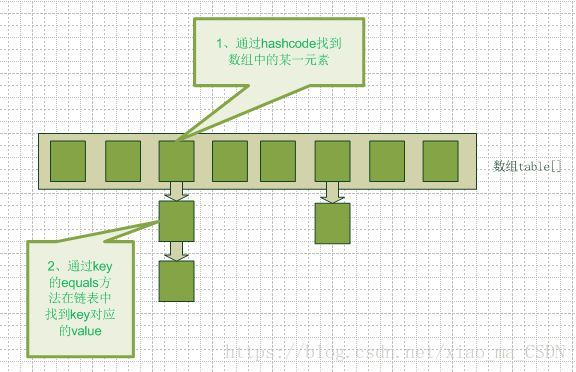
从图中我们可以看到一个hashmap就是一个数组结构,当新建一个hashmap的时候,就会初始化一个数组。我们来看看java代码:
/**
* The table, resized as necessary. Length MUST Always be a power of two.
* 表在必要的时候进行调整。长度必须是2的幂。
*/
transient Entry[] table;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
……
}
上面的Entry就是数组中的元素,它持有一个指向下一个元素的引用,这就构成了链表。
当我们往hashmap中put元素的时候,先根据key的hash值得到这个元素在数组中的位置(即下标),然后就可以把这个元素放到对应的位置中了。如果这个元素所在的位子上已经存放有其他元素了,那么在同一个位子上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。
public V put(K key, V value) {
//当表是空的进行扩张
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。
if (key == null)
return putForNullKey(value);
//根据key的hashcode重新计算hash值
int hash = hash(key);
//根据hash值计算在数组中的下标
int i = indexFor(hash, table.length);
// 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
//新的插入在旧的之前
e.recordAccess(this);
return oldValue;
}
}
// 如果i索引处的Entry为null,表明此处还没有Entry。
// modCount记录HashMap中修改结构的次数
modCount++;
addEntry(hash, key, value, i);
return null;
}从hashmap中get元素时,首先计算key的hashcode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。从这里我们可以想象得到,如果每个位置上的链表只有一个元素,那么hashmap的get效率将是最高的。
//get调用这个方法
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
//先计算出hash值
int hash = (key == null) ? 0 : hash(key);
//查找到hash值所在下标的链表
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}2.hash算法
我们可以看到在hashmap中要找到某个元素,需要根据key的hash值来求得对应数组中的位置。如何计算这个位置就是hash算法。前面说过hashmap的数据结构是数组和链表的结合,所以我们当然希望这个hashmap里面的元素位置尽量的分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,而不用再去遍历链表。
hash(int h)方法根据key的hashCode重新计算一次散列。此算法加入了高位计算,防止低位不变,高位变化时,造成的hash冲突。
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
对于任意给定的对象,只要它的 hashCode() 返回值相同,那么程序调用 hash(int h) 方法所计算得到的 hash 码值总是相同的。我们首先想到的就是把hash值对数组长度取模运算,这样一来,元素的分布相对来说是比较均匀的。但是,“模”运算的消耗还是比较大的,在HashMap中是这样做的:调用 indexFor(int h, int length) 方法来计算该对象应该保存在 table 数组的哪个索引处。indexFor(int h, int length) 方法的代码如下:
static int indexFor(int h, int length) {
return h & (length-1);
} 这个方法非常巧妙,它通过 h & (table.length -1) 来得到该对象的保存位,而HashMap底层数组的长度总是 2 的n 次方,这是HashMap在速度上的优化。
首先算得key得hashcode值,然后跟数组的长度-1做一次“与”运算(&)。
当length总是 2 的n次方时,h& (length-1)运算等价于对length取模,也就是h%length,但是&比%具有更高的效率。
例子来说明:
假设数组长度分别为15和16,优化后的hash码分别为8和9,那么&运算后的结果如下:
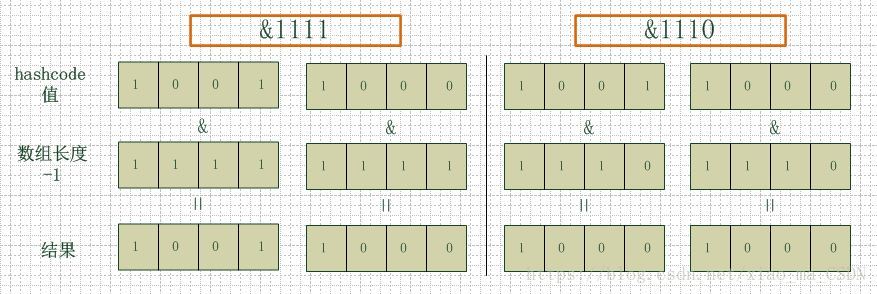
从上面的例子中可以看出:当8、9两个数和(15-1)2=(1110)进行“与运算&”的时候,产生了相同的结果,都为0100,也就是说它们会定位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到数组中的同一个位置上形成链表,那么查询的时候就需要遍历这个链 表,得到8或者9,这样就降低了查询的效率。同时,我们也可以发现,当数组长度为15的时候,hashcode的值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!
所以,在存储大容量数据的时候,最好预先指定hashmap的size为2的整数次幂次方。就算不指定的话,也会以大于且最接近指定值大小的2次幂来初始化的。
3.hashMap的resize
当hashMap的元素越来越多时,碰撞的几率也大大增加,这时就需要进行扩容。扩容之后就出现了最消耗性能的问题,之前数组中的元素要在新的数组中计算出新的的位置,这就是resize。
那么HashMap什么时候进行扩容呢?当HashMap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,这是一个折中的取值。也就是说,默认情况下,数组大小为16,那么当HashMap中元素个数超过16*0.75=12(这个值就是代码中的threshold值,也叫做临界值)的时候,就把数组的大小扩展为 2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
4.HashMap的性能参数:
HashMap 包含如下几个构造器:
HashMap():构建一个初始容量为 16,负载因子为 0.75 的 HashMap。
HashMap(int initialCapacity):构建一个初始容量为 initialCapacity,负载因子为 0.75 的 HashMap。
HashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的负载因子创建一个 HashMap。
HashMap的基础构造器HashMap(int initialCapacity, float loadFactor)带有两个参数,它们是初始容量initialCapacity和加载因子loadFactor。
initialCapacity:HashMap的最大容量,即为底层数组的长度。
loadFactor:负载因子loadFactor定义为:散列表的实际元素数目(n)/ 散列表的容量(m)。
负载因子衡量的是一个散列表的空间的使用程度,负载因子越大表示散列表的装填程度越高,反之愈小。对于使用链表法的散列表来说,查找一个元素的平均时间是O(1+a),因此如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低;如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费。