java 常见数据结构的解析
1:List对象
类图
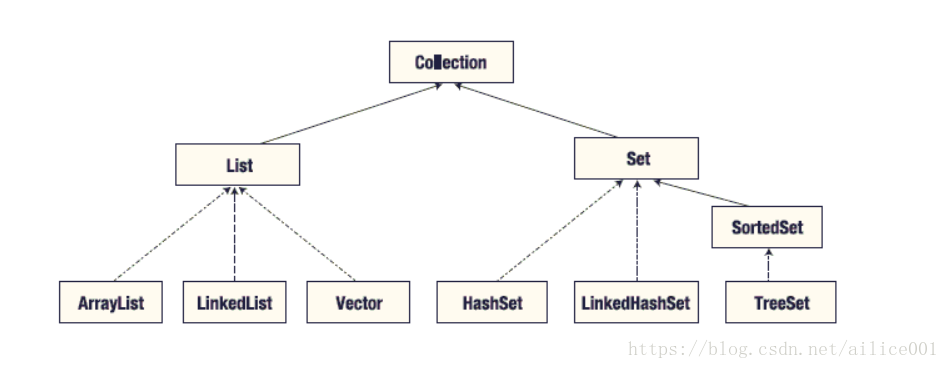
List:
有顺序的,元素可以重复;
遍历:for,迭代;
排序:Comparable Comparator Collections.sort()
ArrayList:
底层用数组实现的List;
特点:查询效率高,增删效率低 轻量级 线程不安全;
为什么查询快?
数组的特性是可以使用索引的方式来快速定位对象的位置,因此对于快速的随机取得对象的需求,使用ArrayList实现执行效率上会比较好;
但是数组再增加超出额外的对象时,是通过复制成新的数组来进行数组扩容,所以性能会有偏差 ;ArrayList默认使用10个
LinkedList : 底层用双向循环链表实现的List;
特点:查询效率低,增删效率高;
为什么增删效率高?
由于链表结构的特性,每个Node都有保存向前或向后的指针
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
在执行删除或者执行插入时会根据具体位置指针会进行相对应的移动
public void add(E e) { checkForComodification(); lastReturned = null; if (next == null) linkLast(e); else linkBefore(e, next); nextIndex++; expectedModCount++; }
public void remove() { checkForComodification(); if (lastReturned == null) throw new IllegalStateException(); Node<E> lastNext = lastReturned.next; unlink(lastReturned); if (next == lastReturned) next = lastNext; else nextIndex--; lastReturned = null; expectedModCount++; }
在执行查询时,
public E get(int index) { checkElementIndex(index); return node(index).item; }
Node<E> node(int index) { // assert isElementIndex(index); if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }
他会遍历所有元素来获取所需要的对象
注意点:
LinkedList还实现了Deque的接口,有队列的特性,还可以用来实现任务队列
Vector:
底层用数组实现List接口的另一个类;
特点:重量级,占据更多的系统开销,线程安全;
2:HashMap
类图
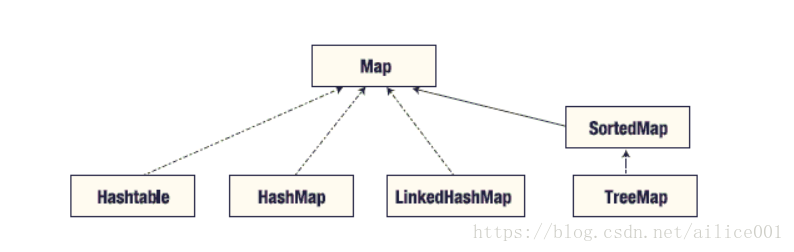
Map
HashMap
底层数据结构是哈希表。线程不安全,效率高
哈希表依赖两个方法:hashCode()和equals()
执行顺序:
首先判断hashCode()值是否相同
是:继续执行equals(),看其返回值
是true:说明元素重复,不添加
是false:就直接添加到集合
否:就直接添加到集合
最终:
自动生成hashCode()和equals()即可
LinkedHashMap
底层数据结构由链表和哈希表组成。
由链表保证元素有序。
由哈希表保证元素唯一。
Hashtable
底层数据结构是哈希表。线程安全,效率低
哈希表依赖两个方法:hashCode()和equals()
执行顺序:
首先判断hashCode()值是否相同
是:继续执行equals(),看其返回值
是true:说明元素重复,不添加
是false:就直接添加到集合
否:就直接添加到集合
最终:
自动生成hashCode()和equals()即可
TreeMap
底层数据结构是红黑树。(是一种自平衡的二叉树)
如何保证元素唯一性呢?
根据比较的返回值是否是0来决定
如何保证元素的排序呢?
两种方式
自然排序(元素具备比较性)
让元素所属的类实现Comparable接口
比较器排序(集合具备比较性)
让集合接收一个Comparator的实现类对象
参考这一篇文章:https://blog.csdn.net/xy2953396112/article/details/54891527
HashMap的对象
key:键的实现就是hash表,每个key都是通过计算hash来算出(hashcode()方法)
value:值的实现是链表的结构,对同一个key多次插入即会覆盖原先的value
Hash算法的实现:
插入时如何对key进行hash计算:
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
在get和put的过程中,计算下标时,先对hashCode进行hash操作,然后再通过hash值进一步计算
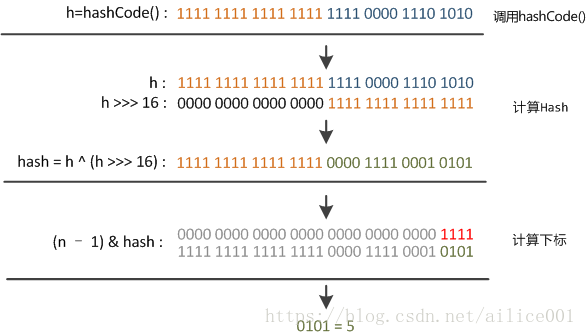
结论:在get和put的过程中,计算下标时,先对hashCode进行hash操作,然后再通过hash值进一步计算,即hash算法会对每个key进行hash计算得倒hash地址,再进行k-v值存储到hash表里;
如put插入的源码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
默认加载因子:0.75,初始容量16,默认阈值: 8
tab为HashMap元素的个数
threshold:阈值,决定了HashMap何时扩容,以及扩容后的大小,一般等于table大小乘以loadFactor
一旦超过了这个边界就会扩容resize,1.8之后扩容有点复杂。。。。
如何获取指定的key对象:
源码:
public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; }
先计算hash地址获取对应的节点再返回节点对象,允许为空;
------引用补充说明
要牢记以下关键点:
- HashMap有一个叫做Entry的内部类,它用来存储key-value对。
- 上面的Entry对象是存储在一个叫做table的Entry数组中。
- table的索引在逻辑上叫做“桶”(bucket),它存储了链表的第一个元素。
- key的hashcode()方法用来找到Entry对象所在的桶。
- 如果两个key有相同的hash值,他们会被放在table数组的同一个桶里面。
- key的equals()方法用来确保key的唯一性。
- value对象的equals()和hashcode()方法根本一点用也没有。
ConcurrentHashMap:
在hashMap的基础上,ConcurrentHashMap将数据分为多个segment,默认16个(concurrency level),然后每次操作对一个segment加锁,避免多线程锁得几率,提高并发效率。3:Queue
即是一种“先进先出”(FIFO—first in first out)的线性表
LinkedBlockingQueue为阻塞队列
线程安全的非阻塞队列 : ConcurrentLinkedQueue