大部分为摘录自wiki
树状图是一种数据结构,它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
- 每个节点有零个或多个子节点;
- 没有父节点的节点称为根节点;
- 每一个非根节点有且只有一个父节点;
- 除了根节点外,每个子节点可以分为多个不相交的子树;
术语:
- 节点的度:一个节点含有的子树的个数称为该节点的度;
- 树的度:一棵树中,最大的节点的度称为树的度;
- 叶节点或终端节点:度为零的节点;
- 非终端节点或分支节点:度不为零的节点;
- 父亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
- 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
- 兄弟节点:具有相同父节点的节点互称为兄弟节点;
- 节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
- 树的高度或深度:树中节点的最大层次;
- 堂兄弟节点:父节点在同一层的节点互为堂兄弟;
- 节点的祖先:从根到该节点所经分支上的所有节点;
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
- 森林:由m(m>=0)棵互不相交的树的集合称为森林;
数的种类:
- 无序树:树中任意节点的子节点之间没有顺序关系,这种树称为无序树,也称为自由树;
- 有序树:树中任意节点的子节点之间有顺序关系,这种树称为有序树;
二叉树是每个节点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。
二叉树的每个结点至多只有二棵子树(不存在度大于2的结点),二叉树的子树有左右之分,次序不能颠倒。二叉树的第i层至多有 个结点;深度为k的二叉树至多有
个结点;深度为k的二叉树至多有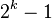 个结点;对任何一棵二叉树T,如果其终端结点数为
个结点;对任何一棵二叉树T,如果其终端结点数为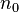 ,度为2的结点数为
,度为2的结点数为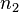 ,则
,则 。
。
一棵深度为k,且有个节点称之为满二叉树;深度为k,有n个节点的二叉树,当且仅当其每一个节点都与深度为k的满二叉树中,序号为1至n的节点对应时,称之为完全二叉树。(简单说,就是每一层都是满的二叉树为满二叉树;只有最后一层不满,并且最后一层的节点都是占据了左边的连续位置的二叉树为完全二叉树)
与树不同,树的结点个数至少为1,而二叉树的结点个数可以为0;树中结点的最大度数没有限制,而二叉树结点的最大度数为2;树的结点无左、右之分,而二叉树的结点有左、右之分。

访问二叉树的方法
前(先)序、中序、后序遍历

二叉查找树(英语:Binary Search Tree),也称二叉搜索树、有序二叉树(英语:ordered binary tree),排序二叉树(英语:sorted binary tree),是指一棵空树或者具有下列性质的二叉树:
- 若任意节点的左子树不空,则左子树上所有结点的值均小于或等于它的根结点的值;
- 任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 任意节点的左、右子树也分别为二叉查找树。
- 没有键值相等的节点(英语:no duplicate nodes)。
二叉查找树相比于其他数据结构的优势在于查找、插入的时间复杂度较低。为O(log n)。二叉查找树是基础性数据结构,用于构建更为抽象的数据结构,如集合、multiset、关联数组等。
二叉查找树的查找过程和次优二叉树类似,通常采取二叉链表作为二叉查找树的存储结构。中序遍历二叉查找树可得到一个关键字的有序序列,一个无序序列可以通过构造一棵二叉查找树变成一个有序序列,构造树的过程即为对无序序列进行查找的过程。每次插入的新的结点都是二叉查找树上新的叶子结点,在进行插入操作时,不必移动其它结点,只需改动某个结点的指针,由空变为非空即可。搜索、插入、删除的复杂度等于树高,期望 ,最坏
,最坏 (数列有序,树退化成线性表)。
(数列有序,树退化成线性表)。
虽然二叉查找树的最坏效率是O(n),但它支持动态查询,且有很多改进版的二叉查找树可以使树高为,如SBT,AVL树,红黑树等.故不失为一种好的动态查找方法.
堆(英语:heap),是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。在队列中,调度程序反复提取队列中第一个作业并运行,因为实际情况中某些时间较短的任务将等待很长时间才能结束,或者某些不短小,但具有重要性的作业,同样应当具有优先权。堆即为解决此类问题设计的一种数据结构。
堆的实现通过构造二叉堆(binary heap),实为二叉树的一种;由于其应用的普遍性,当不加限定时,均指该数据结构的这种实现。这种数据结构具有以下性质。
- 任意节点小于它的所有后裔,最小元在堆的根上(堆序性)。
- 堆总是一棵完全树。
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。
操作:
1.插入节点:从堆尾部插入。然后调整顺序,从堆尾开始逐个和其根元素比较,并调整。
2.删除节点:删除根节点。然后,把堆存储的最后那个节点移到填在根节点处。再从上而下调整父节点与它的子节点:对于最大堆,父节点如果小于具有最大值的子节点,则交换二者。直至当前节点与它的子节点满足堆性质为止。