上一篇:
深度学习环境配置(deepin20.6)
深度学习环境配置(win11版)
1.clone代码+切换环境+安装依赖
git clone https://github.com/ultralytics/yolov5
cd yolov5
conda activate yolov5_env
修改一下requirements.txt,保存:

安装第三方库:
pip install -r requirements.txt
单独安装torch+torchvision
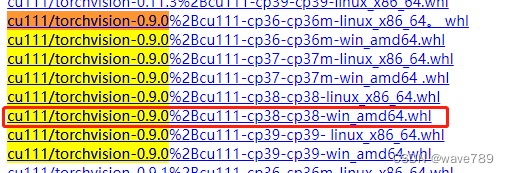
下载地址两者对应关系一般是torch1.7.0-torchvision0.8.0、torch1.8.0-torchvision0.9.0、torch1.9.0-torchvision0.10.0
例如(cu111表示cuda-11.1,cp38表示python3.8):
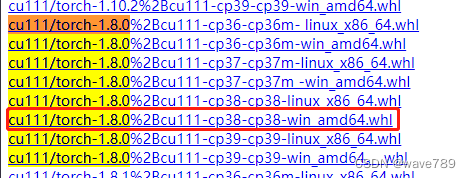
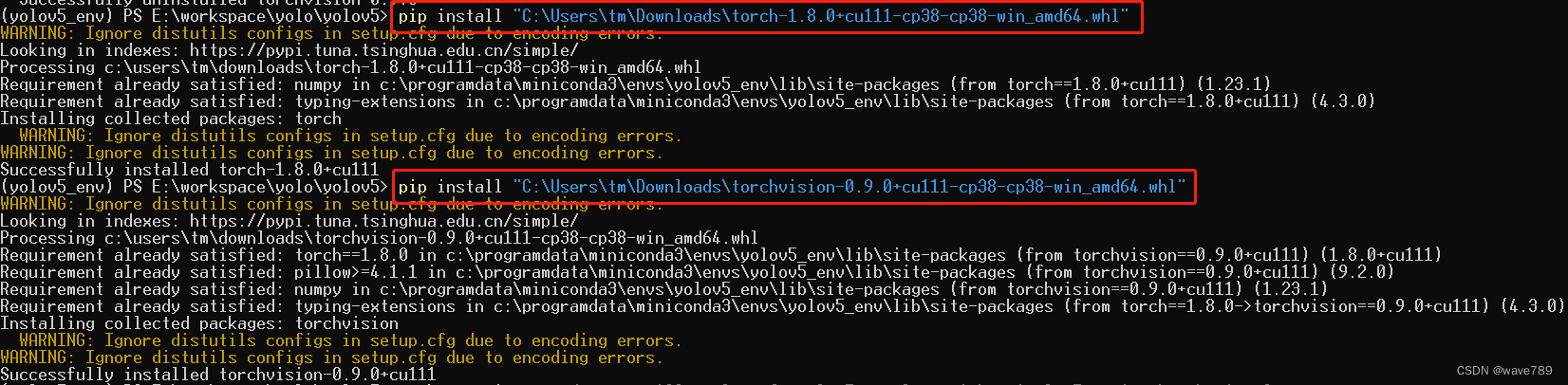
pip install torch的下载路径
pip install torchvision的下载路径
例如:
2.跑官方示例:
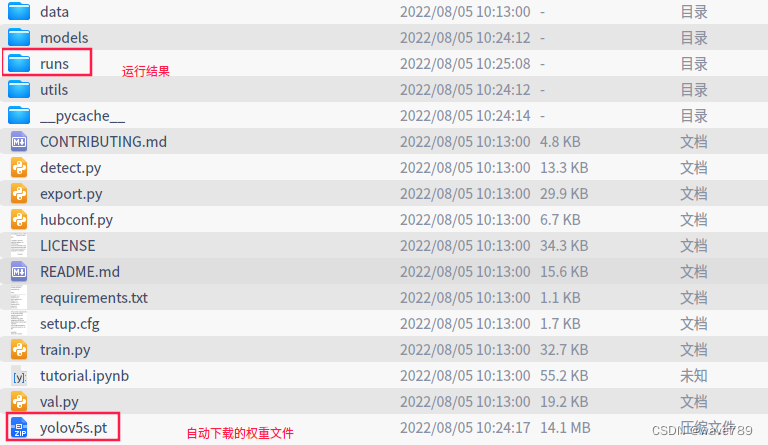
python detect.py --source ./data/images/bus.jpg
3.训练:
python train.py --data=coco128.yaml --cfg=yolov5s.yaml --weights='yolov5s.pt' --batch-size=8
官方提供的coco128数据集,执行会自动下载到项目的同级目录下。

4.标注:
工具labelimg
下载解压后进入目录,
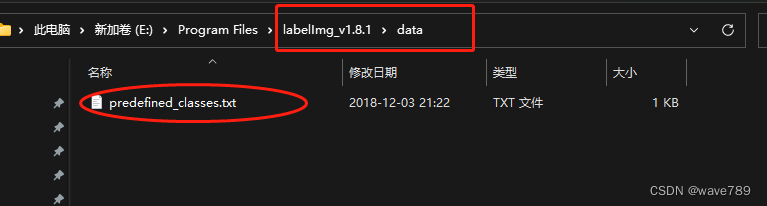
删除predefined_classes.txt里面原有的类别,并写入自己数据集的类别,一行一类。
手动划分自己数据集(跟官方结构一致,所以在coco128同级目录下)(例如有100张图片,将80张放train里面,20张放val里面):
(也可以直接标100张,然后代码随机划分。)
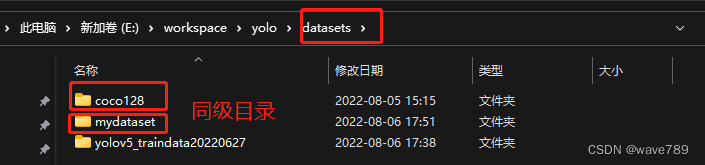
启动labelImg.exe–>file–>Open Dir–>选择train/val。
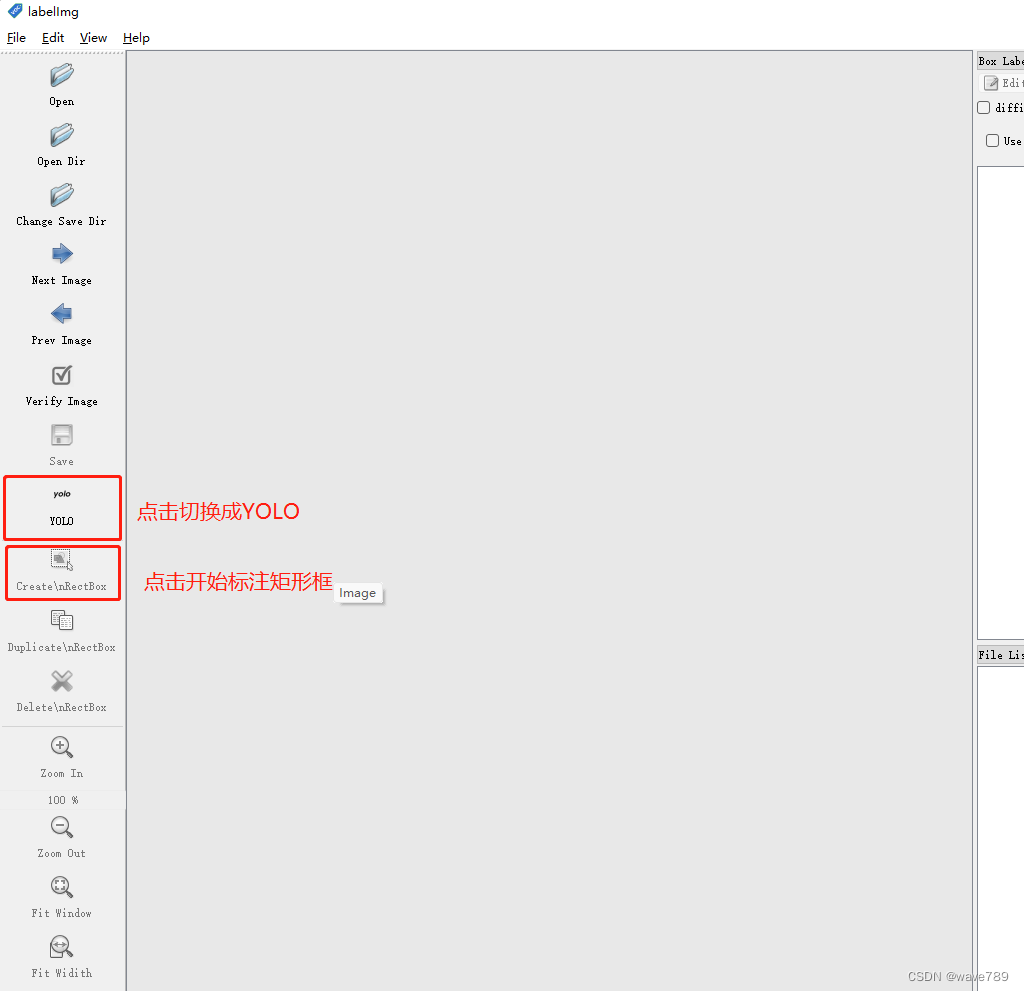
标注好后:
# 标签格式说明:
1.一个图一个txt标注文件(如果图中无所要物体,则无需txt文件);
2.每行一个物体;
3.每行数据格式:类别id、x_center y_center width height;
4.xywh必须归一化(0-1),其中x_center、width除以图片宽度,y_center、height除以画面高度;
5.类别id必须从0开始计数。
展示:
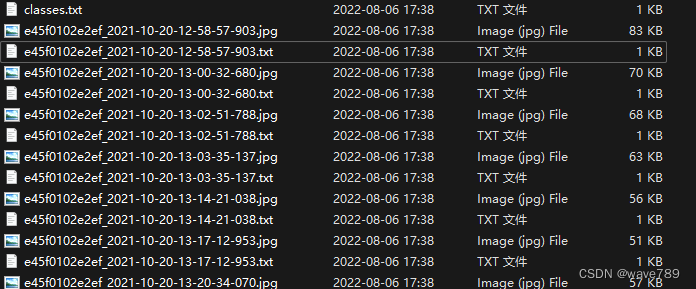

5.训练自己标注的数据集
复制一份coco128.yaml,并重命名为mydataset.yaml,然后修改为自己数据集的路径及类别。
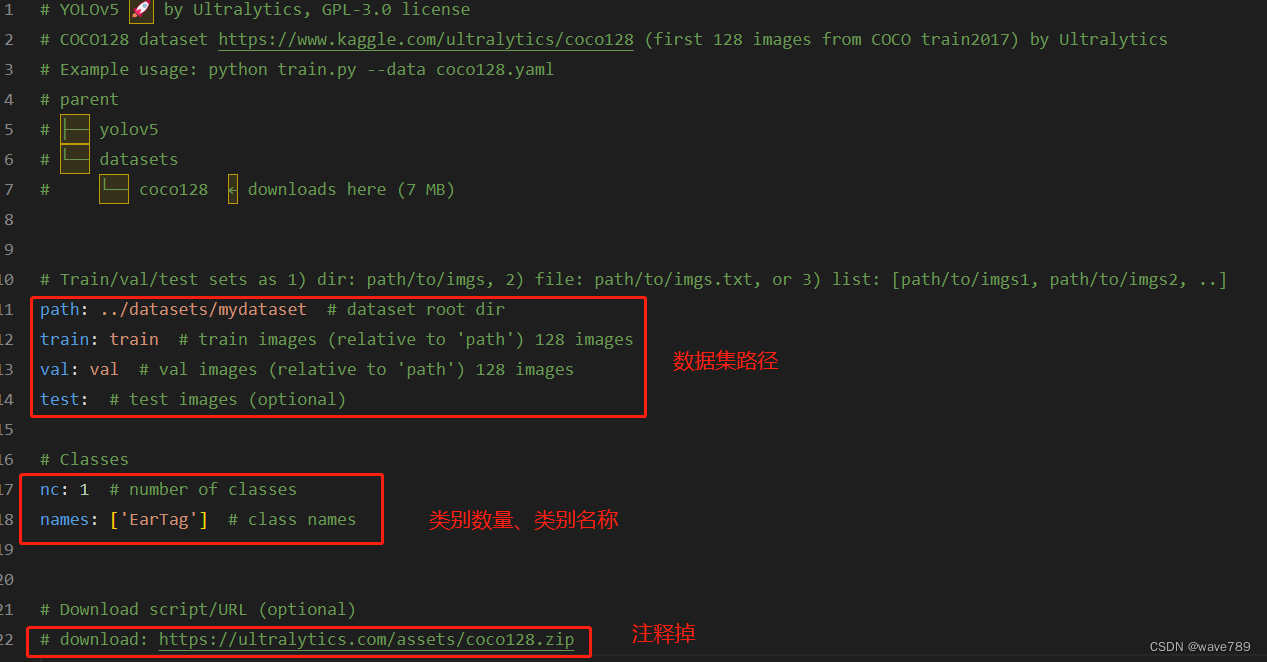
执行:
python train.py --data=mydataset.yaml --cfg=yolov5s.yaml --weights='' --batch-size=8
注意:

6.测试
注意权重的位置。
python detect.py --weights="./runs/train/exp3/weights/best.pt" --source="E:\workspace\yolo\datasets\mydataset\val\e45f0102e2ef_2021-10-20-10-29-34-377.jpg"
7.评估
python val.py --data="./data/mydataset.yaml" --weights="./runs/train/exp3/weights/best.pt" --batch-size=8
8.建议
数据方面:
- 每类图片:建议>=1500张;
- 每类实例(标注的物体):建议>=10000个;
- 图片采样:真实图片建议在一天中不同时间、不同季节、不同天气、不同光照、不同角度、不同来源(爬虫抓取、手动采集、不同相机源)等场景下采集;
- 标注:
所有图片上所有类别的对应物体都需要标注上,不可以只标注部分; 标注尽量闭合物体,边界框与物体无空隙,所有类别对应物体不能缺少标签; - 背景图:
背景图用于减少假阳性预测(False Positive),建议提供0~10%样本总量的背景图,背景图无需标注;
模型选择:
模型越大一般预测结果越好,但相应的计算量越大,训练和运行起来都会慢一点,建议:
- 在移动端(手机、嵌入式)选择:YOLOv5n/s/m
- 云端(服务器)选择:YOLOv5l/x
训练:
- Epochs:初始设定为300,如果很早就过拟合,减少epoch,如果到300还没过拟合,设置更大的数值,如600, 1200等;
- 图像尺寸:训练时默认为–img=640,如果希望检测出画面中的小目标,可以设为–img=1280(检测时也需要设为–img
=1280才能起到一样的效果) - Batch size:选择你硬件能承受的最大–batch-size;
- 超参数(Hyperparameters):初次训练暂时不要改,具体参见https://github.com/ultralytics/yolov5/issues/607
- 更多:官网建议 查看http://karpathy.github.io/2019/04/25/recipe/