yolo5模型训练
1.yolov5自己的模型训练
1.1 git下载对应的源码到服务器
- 克隆对应的代码 Python>=3.7.0环境中安装requirements.txt,包括 PyTorch>=1.7
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
1.2 从最新的 YOLOv5版本自动下载模型。
- 自己创建python文件
import torch
# Model
model = torch.hub.load("ultralytics/yolov5", "yolov5s") # or yolov5n - yolov5x6, custom
# Images
img = "https://ultralytics.com/images/zidane.jpg" # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.
1.3 detect.py 推断
- 这里可以传各种参数
python detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
screen # screenshot
path/ # directory
list.txt # list of images
list.streams # list of streams
'path/*.jpg' # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
1.4 train.py进行训练
python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml --batch-size 128
yolov5s 64
yolov5m 40
yolov5l 24
yolov5x 16
1.5 yolo的原理
- 通过输入一个图片-进行卷积-得到输出结果
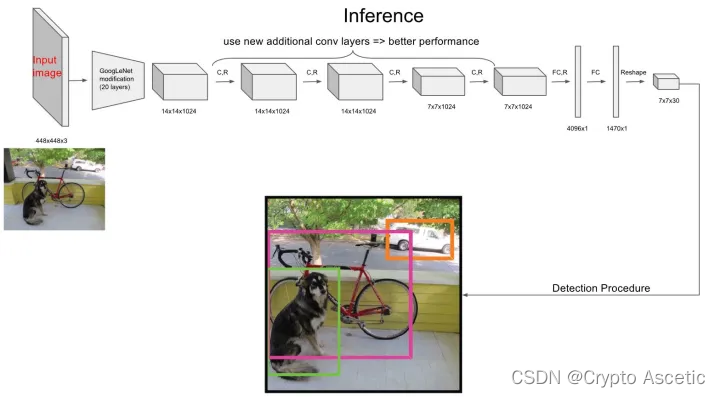
Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,整个系统所示:首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN算法,其是一个统一的框架,其速度更快,而且Yolo的训练过程也是end-to-end的。

在训练之前,先在ImageNet上进行了预训练,其预训练的分类模型采用图8中前20个卷积层,然后添加一个average-pool层和全连接层。预训练之后,在预训练得到的20层卷积层之上加上随机初始化的4个卷积层和2个全连接层。由于检测任务一般需要更高清的图片,所以将网络的输入从224x224增加到了448x448。整个网络的流程如下图所示:
2.训练自己的模型
- 目录结构
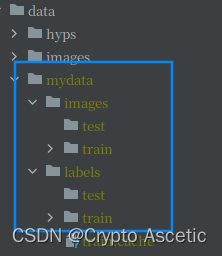
2.1 Data下面新建如图目录Mydata
- mydata
- images
- test
- train(存放原图)
- labels
- test
- train (存放标注的图)
- images
- 存放完图片之后的
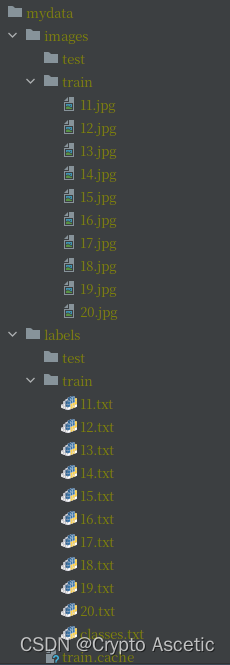
- 如图所示,为积木图

2.1 lableimg进行数据标注的图形
- 没有安装lableimg的可以进行一下安装

2.2 数据集
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /home/hfg/Soft/Idea_Project/deep/yolov5/data/mydata/images/train # dataset root dir
train: /home/hfg/Soft/Idea_Project/deep/yolov5/data/mydata/images/train # train images (relative to 'path') 128 images
val: /home/hfg/Soft/Idea_Project/deep/yolov5/data/mydata/images/train # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: 积木
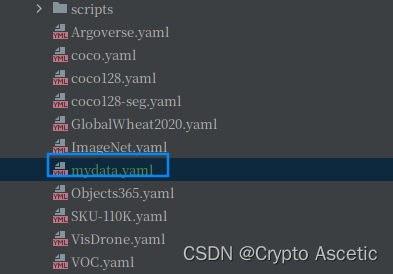
2.3 train.py调整data数据集
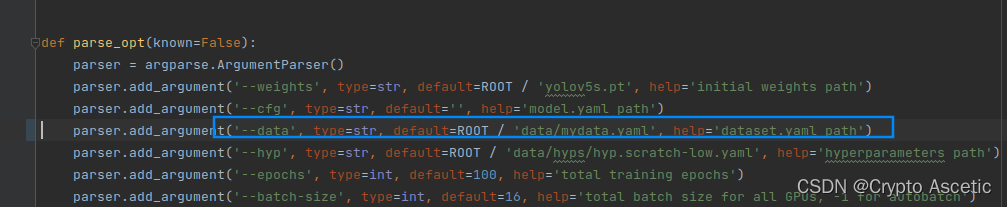
2.4 开始训练
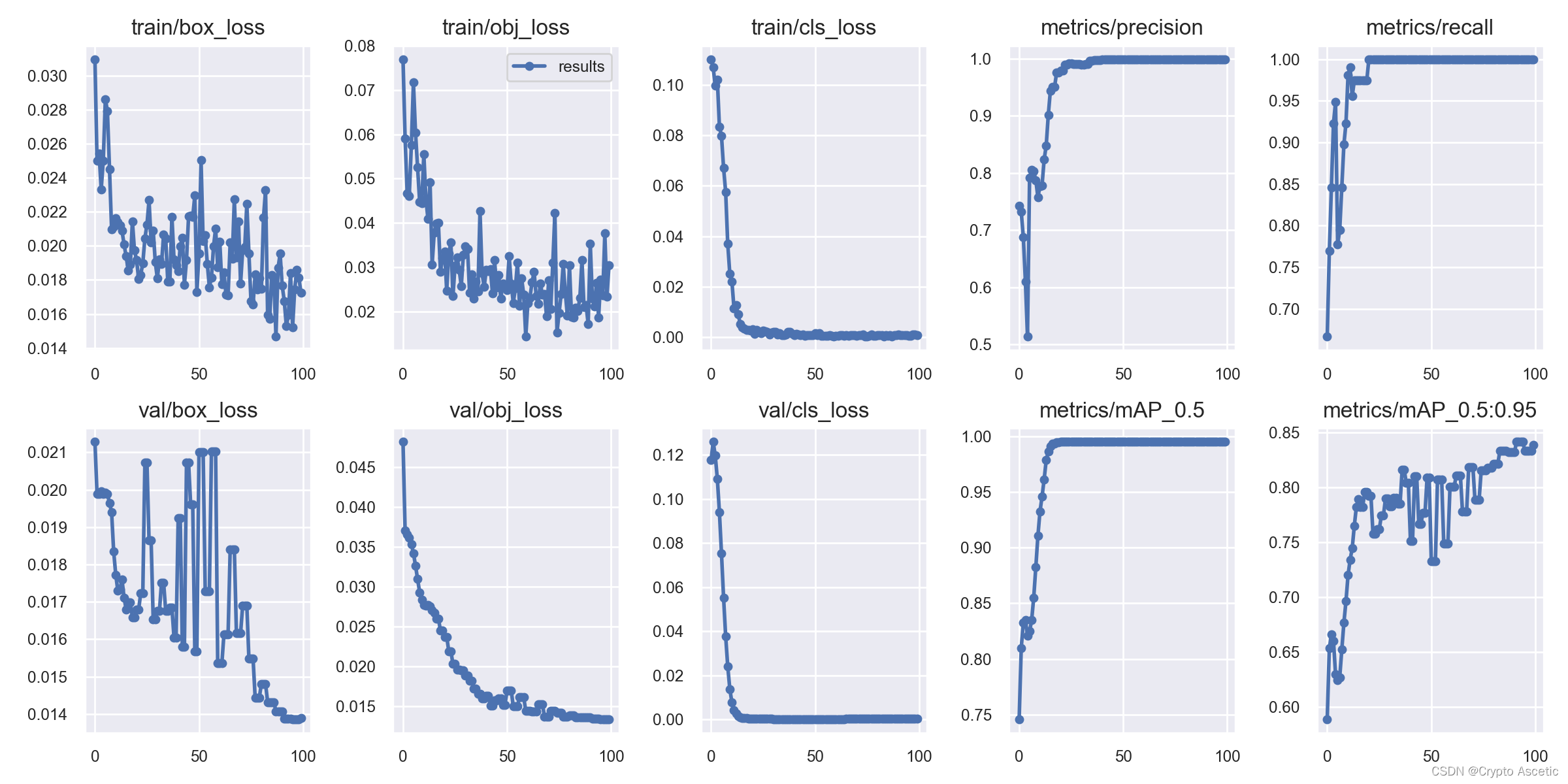
- 如图所示进行训练,本次epochs是100

- 训练的结果集如图所示

- 训练结果