NeurIPS 对抗攻防论文
BIRD: Generalizable Backdoor Detection and Removal for Deep Reinforcement Learning
https://neurips.cc/virtual/2023/poster/70618
摘要:
后门攻击对深度强化学习(DRL)政策的供应链管理构成了严重威胁。尽管在最近的研究中提出了最初的防御措施,但这些方法的可推广性和可扩展性非常有限。为了解决这个问题,我们提出了BIRD,这是一种在干净的环境中从预先训练的DRL策略中检测和删除后门的技术,而不需要任何关于攻击规范和访问其训练过程的知识。通过分析后门攻击的独特性质和行为,我们将触发恢复公式化为一个优化问题,并设计了一种新的后门策略检测指标。我们还设计了一种微调方法来去除后门,同时在干净的环境中保持代理的性能。我们评估了BIRD在十个不同的单代理或多代理环境中抵御三次后门攻击的能力。我们的结果验证了BIRD的有效性、效率和可推广性,以及它对不同攻击变化和自适应的鲁棒性。
Backdoor attacks pose a severe threat to the supply chain management of deep reinforcement learning (DRL) policies. Despite initial defenses proposed in recent studies, these methods have very limited generalizability and scalability. To address this issue, we propose BIRD, a technique to detect and remove backdoors from a pretrained DRL policy in a clean environment without requiring any knowledge about the attack specifications and accessing its training process. By analyzing the unique properties and behaviors of backdoor attacks, we formulate trigger restoration as an optimization problem and design a novel metric to detect backdoored policies. We also design a finetuning method to remove the backdoor, while maintaining the agent's performance in the clean environment. We evaluate BIRD against three backdoor attacks in ten different single-agent or multi-agent environments. Our results verify the effectiveness, efficiency, and generalizability of BIRD, as well as its robustness to different attack variations and adaptions.
Shared Adversarial Unlearning: Backdoor Mitigation by Unlearning Shared Adversarial Examples
https://neurips.cc/virtual/2023/poster/69874
论文:https://arxiv.org/abs/2307.10562
摘要:
后门攻击是对机器学习模型的严重安全威胁,在这种情况下,对手可以将中毒样本注入训练集中,从而导致后门模型预测具有特定触发器的中毒样本到特定目标类,同时在良性样本上表现正常。在本文中,我们探索了使用小型干净数据集净化后门模型的任务。通过建立后门风险和对抗性风险之间的联系,我们推导了一个新的后门风险上限,该上限主要捕捉后门模型和净化模型之间共享对抗性实例(SAE)的风险。这个上界进一步提出了一个新的双层优化问题,用于使用对抗性训练技术来减轻后门。为了解决这一问题,我们提出了共享对抗性释放(SAU)。具体而言,SAU首先生成SAE,然后忽略生成的SAE,以便它们被纯化模型正确分类和/或被两个模型不同分类,从而后门模型中的后门效应将在纯化模型中得到缓解。在各种基准数据集和网络架构上的实验表明,我们提出的方法在后门防御方面实现了最先进的性能。
Backdoor attacks are serious security threats to machine learning models where an adversary can inject poisoned samples into the training set, causing a backdoored model which predicts poisoned samples with particular triggers to particular target classes, while behaving normally on benign samples. In this paper, we explore the task of purifying a backdoored model using a small clean dataset. By establishing the connection between backdoor risk and adversarial risk, we derive a novel upper bound for backdoor risk, which mainly captures the risk on the shared adversarial examples (SAEs) between the backdoored model and the purified model. This upper bound further suggests a novel bi-level optimization problem for mitigating backdoor using adversarial training techniques. To solve it, we propose Shared Adversarial Unlearning (SAU). Specifically, SAU first generates SAEs, and then, unlearns the generated SAEs such that they are either correctly classified by the purified model and/or differently classified by the two models, such that the backdoor effect in the backdoored model will be mitigated in the purified model. Experiments on various benchmark datasets and network architectures show that our proposed method achieves state-of-the-art performance for backdoor defense.

VillanDiffusion: A Unified Backdoor Attack Framework for Diffusion Models
https://neurips.cc/virtual/2023/poster/70045
论文:https://arxiv.org/abs/2306.06874
摘要:
扩散模型(DM)是最先进的生成模型,它从迭代噪声添加和去噪中学习可逆的破坏过程。它们是许多生成性人工智能应用程序的支柱,如文本到图像的条件生成。然,最近的研究表明,基本的无条件DM(例如DDPM和DDIM)容易受到后门注入的攻击,后门注入是一种由模型输入处恶意嵌入的模式触发的输出操纵攻击。本文提出了一个统一的后门攻击框架(VillanDiffusion),以扩展当前DM后门分析的范围。我们的框架涵盖了主流的无条件和有条件DM(基于去噪和基于分数)以及用于整体评估的各种无训练采样器。实验表明,我们的统一框架有助于对不同DM配置进行后门分析,并为DM上基于字幕的后门攻击提供了新的见解。
Diffusion Models (DMs) are state-of-the-art generative models that learn a reversible corruption process from iterative noise addition and denoising. They are the backbone of many generative AI applications, such as text-to-image conditional generation. However, recent studies have shown that basic unconditional DMs (e.g., DDPM and DDIM) are vulnerable to backdoor injection, a type of output manipulation attack triggered by a maliciously embedded pattern at model input. This paper presents a unified backdoor attack framework (VillanDiffusion) to expand the current scope of backdoor analysis for DMs. Our framework covers mainstream unconditional and conditional DMs (denoising-based and score-based) and various training-free samplers for holistic evaluations. Experiments show that our unified framework facilitates the backdoor analysis of different DM configurations and provides new insights into caption-based backdoor attacks on DMs.



Theoretically Modeling Client Data Divergence for Federated Natural Language Backdoor Defense
https://neurips.cc/virtual/2023/poster/70177
摘要:
联合学习算法使神经网络模型能够在多个分散的边缘设备上进行训练,而不会暴露私人数据。然而,它们很容易受到恶意客户端发起的后门攻击。现有的鲁棒联邦聚合算法根据可疑客户端的参数距离启发式地检测和排除可疑客户端,但它们在自然语言处理(NLP)任务中无效。主要原因是,尽管文本后门模式在底层数据集级别是明显的,但它们通常在参数级别是隐藏的,因为在具有离散特征空间的文本中注入后门对模型参数的统计影响较小。为了解决这个问题,我们建议通过显式地建模联邦NLP系统中客户端之间的数据差异来识别后门客户端。通过理论分析,我们推导出了f散度指标,用于估计具有聚合更新和Hessians的客户端数据散度。此外,我们在扩散理论的指导下,设计了一种具有Hessian重新分配机制的数据集合成方法,以解决在计算客户数据Hessian时不可访问数据集的关键挑战。然后,我们提出了一种新的基于联合F-Divergence-Based Aggregation(Fed-FA)算法,该算法利用F-Divergence指标来检测和丢弃可疑客户端。大量的实证结果表明,在各种自然语言后门攻击场景中,Fed-FA在抵御后门攻击方面优于所有基于参数距离的方法。
Federated learning algorithms enable neural network models to be trained across multiple decentralized edge devices without private data exposure. However, they are susceptible to backdoor attacks launched by malicious clients. Existing robust federated aggregation algorithms heuristically detect and exclude suspicious clients based on their parameter distances, but they are ineffective on Natural Language Processing (NLP) tasks. The main reason is that, although text backdoor patterns are obvious at the underlying dataset level, they are usually hidden at the parameter level, since injecting backdoors into texts with discrete feature space has less impact on the statistics of the model parameters. To settle this issue, we propose to identify backdoor clients by explicitly modeling the data divergence among clients in federated NLP systems. Through theoretical analysis, we derive the f-divergence indicator to estimate the client data divergence with aggregation updates and Hessians. Furthermore, we devise a dataset synthesization method with a Hessian reassignment mechanism guided by the diffusion theory to address the key challenge of inaccessible datasets in calculating clients' data Hessians. We then present the novel Federated F-Divergence-Based Aggregation (Fed-FA) algorithm, which leverages the f-divergence indicator to detect and discard suspicious clients. Extensive empirical results show that Fed-FA outperforms all the parameter distance-based methods in defending against backdoor attacks among various natural language backdoor attack scenarios.
BadTrack: A Poison-Only Backdoor Attack on Visual Object Tracking
https://neurips.cc/virtual/2023/poster/71420
摘要:
视觉对象跟踪(VOT)是计算机视觉领域最基本的任务之一。现有技术的VOT跟踪器提取用于引导跟踪器将对象与背景区分开的正示例和负示例。在本文中,我们证明了这一特性可以被用来引入新的威胁,因此提出了一种简单而有效的仅限毒药的后门攻击。具体地说,我们通过将预定义的触发模式附加到每个视频帧的背景区域来毒害训练数据的一小部分,使得触发几乎只出现在提取的负面示例中。据我们所知,这是第一部揭示VOT跟踪器受到仅限毒药后门攻击威胁的作品。我们的实验表明,我们的后门攻击可以显著降低双流Siamese和单流Transformer跟踪器对中毒数据的性能,同时获得与良性跟踪器相当的性能
Visual object tracking (VOT) is one of the most fundamental tasks in computer vision community. State-of-the-art VOT trackers extract positive and negative examples that are used to guide the tracker to distinguish the object from the background. In this paper, we show that this characteristic can be exploited to introduce new threats and hence propose a simple yet effective poison-only backdoor attack. To be specific, we poison a small part of the training data by attaching a predefined trigger pattern to the background region of each video frame, so that the trigger appears almost exclusively in the extracted negative examples. To the best of our knowledge, this is the first work that reveals the threat of poison-only backdoor attack on VOT trackers. We experimentally show that our backdoor attack can significantly degrade the performance of both two-stream Siamese and one-stream Transformer trackers on the poisoned data while gaining comparable performance with the benign trackers on the clean data.
Robust Contrastive Language-Image Pretraining against Data Poisoning and Backdoor Attacks
https://neurips.cc/virtual/2023/poster/71818
论文:https://arxiv.org/abs/2303.06854
摘要:
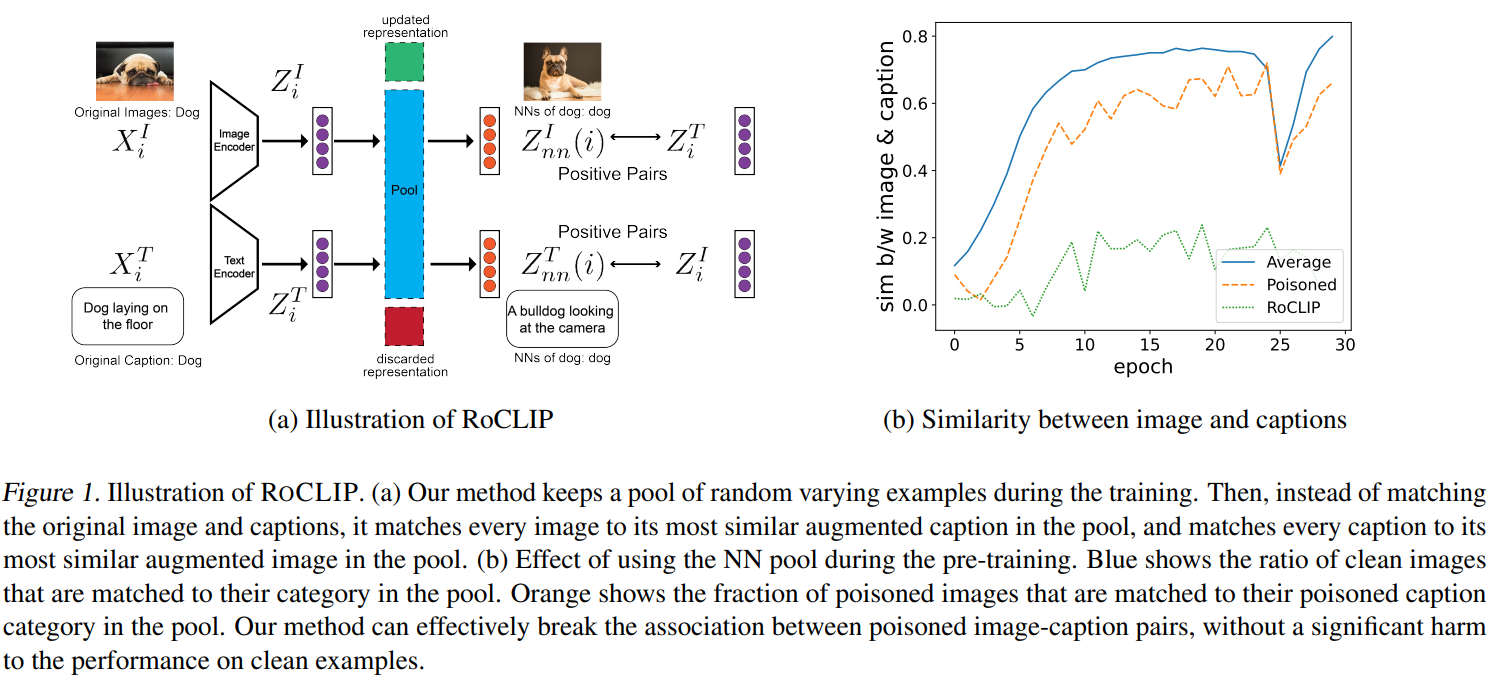
对比视觉-语言表示学习通过从互联网上抓取的数百万对图像-认知对中学习,在零样本分类中取得了最先进的性能。然而,为CLIP等大型多模式模型提供动力的大量数据使它们极易受到有针对性和后门数据中毒攻击。尽管存在这种漏洞,但针对这些攻击的强大对比视觉语言预训练仍然没有得到解决。在这项工作中,我们提出了ROCLIP,这是第一种针对目标数据中毒和后门攻击的鲁棒预训练多模式视觉语言模型的有效方法。ROCLIP通过考虑相对较大且变化的随机字幕池,并将每个图像与池中最相似的文本(而不是其自己的字幕)匹配,有效地打破了中毒图像字幕对之间的关联。我们的大量实验表明,我们的方法使最先进的有针对性的数据中毒和后门攻击在预训练CLIP期间无效。特别是,RoCLIP将毒药攻击成功率从93.75%降低到12.5%,后门攻击成功率降低到0%,并有效地将模型的线性探测性能提高了10%,并保持了与CLIP类似的零发射性能。
Contrastive vision-language representation learning has achieved state-of-the-art performance for zero-shot classification, by learning from millions of image-caption pairs crawled from the internet. However, the massive data that powers large multimodal models such as CLIP, makes them extremely vulnerable to targeted and backdoor data poisoning attacks. Despite this vulnerability, robust contrastive vision-language pretraining against those attacks has remained unaddressed. In this work, we propose ROCLIP, the first effective method for robust pre-training multimodal vision-language models against targeted data poisoning and backdoor attacks. ROCLIP effectively breaks the association between poisoned image-caption pairs by considering a relatively large and varying pool of random captions, and matching every image with the text that is most similar to it in the pool, instead of its own caption. Our extensive experiments show that our method renders state-of-the-art targeted data poisoning and backdoor attacks ineffective during pre-training CLIP. In particular, RoCLIP decreases the poison attack success rate from 93.75% to 12.5% and backdoor attack success rates down to 0% , and effectively improves the model's linear probe performance by 10% and maintains a similar zero shot performance compared to CLIP.

Stable Backdoor Purification with Feature Shift Tuning
https://neurips.cc/virtual/2023/poster/72630
论文:https://arxiv.org/abs/2310.01875v1
代码:https://github.com/AISafety-HKUST/stable_backdoor_purification
摘要:
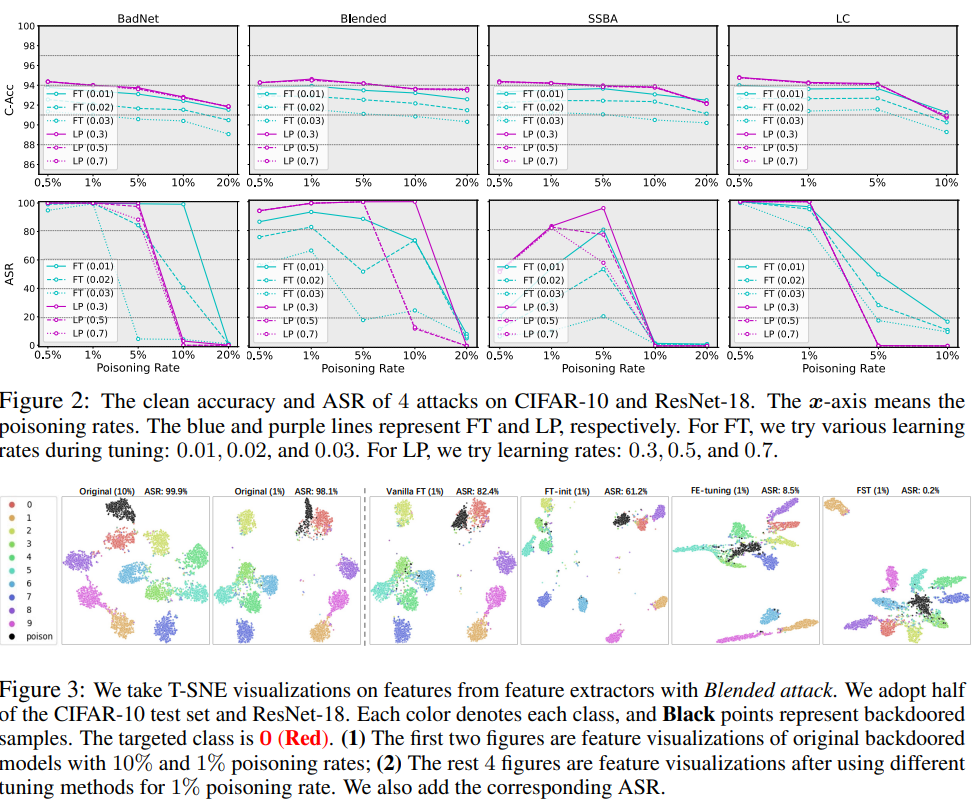
人们已经广泛观察到,深度神经网络(DNN)容易受到后门攻击,攻击者可以通过篡改一小组训练样本来恶意操纵模型行为。尽管提出了一种防线方法来减轻这种威胁,但它们要么需要对训练过程进行复杂的修改,要么严重依赖于特定的模型架构,这使得它们很难部署到现实世界的应用程序中。因此,在本文中,我们转而从微调开始,这是最常见、最容易部署的后门防御之一,通过对不同攻击场景的全面评估。通过初步实验进行的观察表明,与在高中毒率下有希望的防御结果相反,香草调谐方法在低中毒率情况下完全失败。我们假设,在低中毒率的情况下,后门和干净特征之间的纠缠破坏了基于调谐的防御的效果,因此需要在干净特征和后门特征之间解开纠缠来提高后门净化。我们提出了一种基于调整的后门净化方法,称为特征偏移调整(FST),该方法简单且稳定,可以抵御各种后门攻击。具体来说,我们的方法通过主动使分类器头部偏离最初折衷的权重,在干净特征和后门特征之间解开纠缠,来鼓励特征转移。大量实验表明,我们的FST在不同的攻击设置下提供了一致稳定的性能,此外,它还可以方便地部署在真实世界的场景中,大大降低了计算成本。
It has been widely observed that deep neural networks (DNN) are vulnerable to backdoor attacks where attackers could manipulate the model behavior maliciously by tampering with a small set of training samples. Although a line of defense methods is proposed to mitigate this threat, they either require complicated modifications to the training process or heavily rely on the specific model architecture, which makes them hard to be deployed into real-world applications. Therefore, in this paper, we instead start with fine-tuning, one of the most common and easy-to-deploy backdoor defenses, through comprehensive evaluations against diverse attack scenarios. Observations made through initial experiments show that in contrast to the promising defensive results on high poisoning rates, vanilla tuning methods completely fail at low poisoning rate scenarios. We posit that with the low poisoning rate, the entanglement between the backdoor and clean features undermines the effect of tuning-based defenses, and thus disentangling between clean and backdoor features is required to improve the backdoor purification. We propose a tuning-based backdoor purification method called feature shift tuning (FST) which is simple and stable against a wide range of backdoor attacks. Specifically, our method encourages feature shifts by actively deviating the classifier head from the originally compromised weights, disentangling between the clean and backdoor features. Extensive experiments demonstrate that our FST provides consistently stable performance under different attack settings and moreover, it is also convenient to deploy in real-world scenarios with significantly reduced computation costs.


Black-box Backdoor Defense via Zero-shot Image Purification
https://neurips.cc/virtual/2023/poster/71421
论文:https://arxiv.org/abs/2303.12175
摘要:
后门攻击将中毒样本注入到训练数据中,导致在模型部署期间对中毒输入进行错误分类。防范此类攻击具有挑战性,尤其是对于只允许查询访问的真实世界黑匣子模型。在本文中,我们提出了一种新的后门防御框架,通过零样本图像净化(ZIP)来防御后门攻击。我们的框架可以应用于黑盒模型,而不需要有关中毒模型的内部信息或任何清洁/中毒样本的先验知识。我们的防御框架包括两个步骤。首先,我们对中毒图像应用线性变换,旨在破坏后门模式。然后,我们使用预先训练的扩散模型来恢复通过转换去除的缺失语义信息。特别是,我们设计了一种新的逆向过程,使用变换后的图像来指导高保真度纯化图像的生成,该图像在零样本设置中起作用。我们在具有不同类型攻击的多个数据集上评估我们的ZIP框架。实验结果表明,与最先进的后门防御基线相比,我们的ZIP框架具有优势。我们相信,我们的研究结果将为黑匣子模型的未来防御方法提供有价值的见解。
Backdoor attacks inject poisoned samples into the training data, resulting in the misclassification of the poisoned input during a model's deployment. Defending against such attacks is challenging, especially for real-world black-box models where only query access is permitted. In this paper, we propose a novel backdoor defense framework to defend against backdoor attacks through zero-shot image purification (ZIP). Our framework can be applied to black-box models without requiring internal information about the poisoned model or any prior knowledge of the clean/poisoned samples. Our defense framework involves two steps. First, we apply a linear transformation on the poisoned image aiming to destroy the backdoor pattern. Then, we use a pre-trained diffusion model to recover the missing semantic information removed by the transformation. In particular, we design a new reverse process by using the transformed image to guide the generation of high-fidelity purified images, which functions in zero-shot settings. We evaluate our ZIP framework on multiple datasets with different types of attacks. Experimental results demonstrate the superiority of our ZIP framework compared to state-of-the-art backdoor defense baselines. We believe that our results will provide valuable insights for future defense methods for black-box models.



A3FL: Adversarially Adaptive Backdoor Attacks to Federated Learning
https://neurips.cc/virtual/2023/poster/71628
摘要:
联合学习(FL)是一种分布式机器学习范式,允许多个客户端在不共享本地训练数据的情况下协作训练全局模型。由于其分布性,许多研究表明,它很容易受到后门攻击。然而,现有的研究通常使用预先确定的、固定的后门触发器,或者仅基于局部数据和模型对其进行优化,而不考虑全局训练动态。这导致了次优和不太持久的攻击有效性,即当攻击预算有限时,它们的攻击成功率较低,如果攻击者无法再执行攻击,则攻击成功率会迅速降低。为了解决这些限制,我们提出了A3FL,这是一种新的后门攻击,它对抗性地调整后门触发器,使其不太可能被全局训练动态移除。我们的关键直觉是,FL中全局模型和局部模型之间的差异使局部优化触发器在转移到全局模型时的有效性大大降低。我们通过优化触发器来解决这个问题,甚至在最坏的情况下,全局模型被训练为直接忽略触发器。在基准数据集上对12种现有防御进行了广泛的实验,以全面评估我们的A3FL的有效性。
Federated Learning (FL) is a distributed machine learning paradigm that allows multiple clients to train a global model collaboratively without sharing their local training data. Due to its distributed nature, many studies have shown that it is vulnerable to backdoor attacks. However, existing studies usually used a predetermined, fixed backdoor trigger or optimized it based solely on the local data and model without considering the global training dynamics. This leads to sub-optimal and less durable attack effectiveness, i.e., their attack success rate is low when the attack budget is limited and decreases quickly if the attacker can no longer perform attacks anymore. To address these limitations, we propose A3FL, a new backdoor attack which adversarially adapts the backdoor trigger to make it less likely to be removed by the global training dynamics. Our key intuition is that the difference between the global model and the local model in FL makes the local-optimized trigger much less effective when transferred to the global model. We solve this by optimizing the trigger to even survive the worst-case scenario where the global model was trained to directly unlearn the trigger. Extensive experiments on benchmark datasets are conducted for twelve existing defenses to comprehensively evaluate the effectiveness of our A3FL.
Setting the Trap: Capturing and Defeating Backdoor Threats in PLMs through Honeypots
https://neurips.cc/virtual/2023/poster/72945
摘要:
在自然语言处理领域,流行的方法包括使用局部样本对预训练语言模型(PLM)进行微调。最近的研究暴露了PLM对后门攻击的易感性,其中对手可以通过操纵一些训练样本来嵌入恶意预测行为。在这项研究中,我们的目标是开发一种抗后门调整程序,无论微调数据集是否包含中毒样本,都能产生无后门模型。为此,我们提出并将蜜罐模块集成到原始PLM中,该模块专门用于吸收后门信息。我们的设计是基于这样的观察,即PLM中的较低层表示具有足够的后门特征,同时携带关于原始任务的最少信息。因此,我们可以对蜜罐模块获取的信息进行惩罚,以在茎网络的微调过程中抑制后门的创建。在基准数据集上进行的综合实验证实了我们防御策略的有效性和稳健性。值得注意的是,这些结果表明,与先前最先进的方法相比,攻击成功率大幅降低,从10%到40%不等。
In the field of natural language processing, the prevalent approach involves fine-tuning pretrained language models (PLMs) using local samples. Recent research has exposed the susceptibility of PLMs to backdoor attacks, wherein the adversaries can embed malicious prediction behaviors by manipulating a few training samples. In this study, our objective is to develop a backdoor-resistant tuning procedure that yields a backdoor-free model, no matter whether the fine-tuning dataset contains poisoned samples. To this end, we propose and integrate an \emph{honeypot module} into the original PLM, specifically designed to absorb backdoor information exclusively. Our design is motivated by the observation that lower-layer representations in PLMs carry sufficient backdoor features while carrying minimal information about the original tasks. Consequently, we can impose penalties on the information acquired by the honeypot module to inhibit backdoor creation during the fine-tuning process of the stem network. Comprehensive experiments conducted on benchmark datasets substantiate the effectiveness and robustness of our defensive strategy. Notably, these results indicate a substantial reduction in the attack success rate ranging from 10\% to 40\% when compared to prior state-of-the-art methods.
IBA: Towards Irreversible Backdoor Attacks in Federated Learning
https://neurips.cc/virtual/2023/poster/71079
论文:https://arxiv.org/abs/2303.02213
摘要:
联合学习(FL)是一种分布式学习方法,它使机器学习模型能够在不损害终端设备的个人潜在敏感数据的情况下在去中心化数据上进行训练。然而,分布式的性质和未经调查的数据直观地引入了新的安全漏洞,包括后门攻击。在这种情况下,对手在训练期间将后门功能植入全局模型,该后门功能可以被激活,以对具有特定对抗模式的任何输入造成所需的不当行为。尽管在触发和扭曲模型行为方面取得了显著成功,但FL中先前的后门攻击往往具有不切实际的假设、有限的不可察觉性和持久性。具体来说,对手需要控制足够大的一部分客户端,或者了解其他诚实客户端的数据分布。在许多情况下,插入的触发器通常在视觉上是明显的,如果对手被从训练过程中移除,后门效应会很快被淡化。为了解决这些局限性,我们在FL中提出了一种新的后门攻击框架,该框架联合学习最优的视觉隐形触发器,然后逐渐将后门植入全局模型中。这种方法允许对手执行后门攻击,从而可以逃避人工和机器检查。此外,我们通过选择性地毒害主任务的学习过程最不可能更新的模型参数,并将中毒的模型更新限制在全局模型附近,来提高所提出攻击的效率和持久性。最后,我们在几个基准数据集上评估了所提出的攻击框架,包括MNIST、CIFAR10和Tiny ImageNet,并实现了高成功率,同时绕过了现有的后门防御,与其他后门攻击相比,实现了更持久的后门效果。总的来说,我们的框架为FL中的后门攻击提供了一种更有效、更隐蔽、更持久的方法。
Federated learning (FL) is a distributed learning approach that enables machine learning models to be trained on decentralized data without compromising end devices' personal, potentially sensitive data. However, the distributed nature and uninvestigated data intuitively introduce new security vulnerabilities, including backdoor attacks. In this scenario, an adversary implants backdoor functionality into the global model during training, which can be activated to cause the desired misbehaviors for any input with a specific adversarial pattern.Despite having remarkable success in triggering and distorting model behavior, prior backdoor attacks in FL often hold impractical assumptions, limited imperceptibility, and durability. Specifically, the adversary needs to control a sufficiently large fraction of clients or know the data distribution of other honest clients. In many cases, the trigger inserted is often visually apparent, and the backdoor effect is quickly diluted if the adversary is removed from the training process. To address these limitations, we propose a novel backdoor attack framework in FL that jointly learns the optimal and visually stealthy trigger and then gradually implants the backdoor into a global model. This approach allows the adversary to execute a backdoor attack that can evade both human and machine inspections. Additionally, we enhance the efficiency and durability of the proposed attack by selectively poisoning the model's parameters that are least likely updated by the main task's learning process and constraining the poisoned model update to the vicinity of the global model.Finally, we evaluate the proposed attack framework on several benchmark datasets, including MNIST, CIFAR10, and Tiny-ImageNet, and achieved high success rates while simultaneously bypassing existing backdoor defenses and achieving a more durable backdoor effect compared to other backdoor attacks. Overall, our framework offers a more effective, stealthy, and durable approach to backdoor attacks in FL.




CBD: A Certified Backdoor Detector Based on Local Dominant Probability
https://neurips.cc/virtual/2023/poster/72180
摘要:
后门攻击是深度神经网络的常见威胁,在测试过程中,嵌入后门触发器的样本将被后门模型错误地分类为对抗性目标类别。在本文中,我们提出了第一个认证的后门检测器(CBD),它基于一种新的、可调的保角预测方案,使用了一个名为“局部主导概率”的统计量。对于任何要检查的分类器,我们不仅提供了检测推断,而且还导出(对于相同的分类域)保证攻击可检测的条件以及假阳性率的概率上界。我们的理论结果表明,触发器对测试时间噪声更有弹性,扰动幅度较小的攻击更有可能在有保证的情况下被检测到。此外,我们在BadNet、CB和Blend等不同后门类型的四个基准数据集上进行了广泛的实验。从经验上讲,CBD的检测精度与无法提供检测认证的最先进的检测器相当,甚至更高。值得注意的是,对于具有以$\ell_2\leq0.75$为界的随机扰动触发器的后门攻击,其攻击成功率超过90%,CBD在四个基准数据集GTSRB、SVHN、CIFAR-10和TinyImageNet上分别达到98%、84%、98%和40%的认证真阳性率,且假阳性率较低。
Backdoor attack is a common threat to deep neural networks, where samples embedded with a backdoor trigger will be misclassified to an adversarial target class by a backdoored model during testing.In this paper, we present the first certified backdoor detector (CBD), which is based on a novel, adjustable conformal prediction scheme using a proposed statistic named *local dominant probability*.For any classifier to be inspected, we not only provide a detection inference, but also derive (for the same classification domain) the condition under which the attacks are guaranteed to be detectable, as well as a probabilistic upper bound for the false positive rate.Our theoretical results show that attacks with triggers more resilient to test-time noises and smaller in perturbation magnitude are more likely to be detected with guarantees.Moreover, we conduct extensive experiments on four benchmark datasets for various backdoor types, such as BadNet, CB, and Blend.Empirically, CBD achieves comparable or even higher detection accuracy than state-of-the-art detectors, which cannot provide detection certification.Notably, for backdoor attacks with random perturbation triggers bounded by $\ell_2\leq0.75$ that achieves more than 90\% attack success rate, CBD achieves 98\%, 84\%, 98\%, and 40\% certified true positive rates on the four benchmark datasets GTSRB, SVHN, CIFAR-10, and TinyImageNet, respectively, with low false positive rates.
Defending Pre-trained Language Models as Few-shot Learners against Backdoor Attacks
https://neurips.cc/virtual/2023/poster/72193
论文:https://arxiv.org/abs/2309.13256
代码: https://github.com/zhaohan-xi/PLM-prompt-defense
摘要:
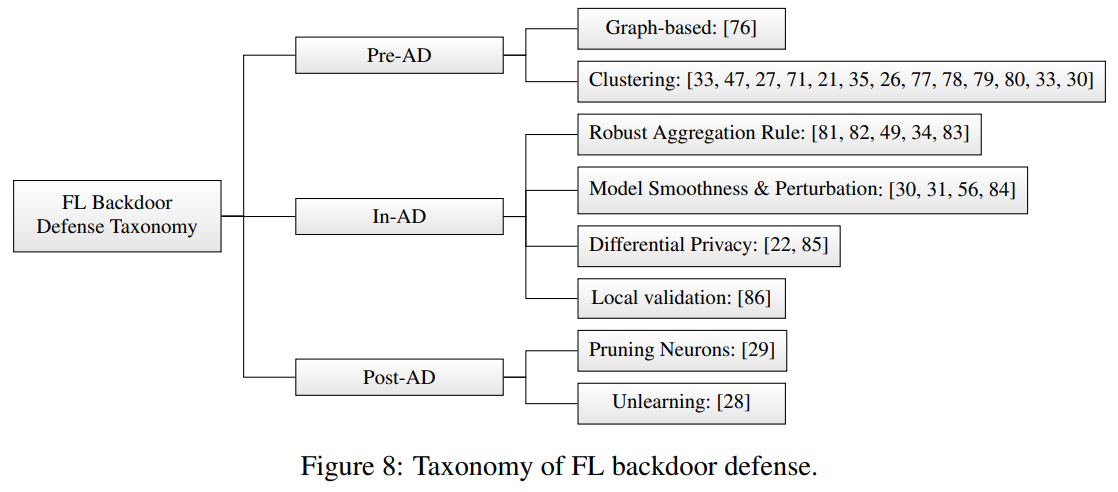
经过预训练的语言模型(PLM)作为少数射击学习者表现出了非凡的表现。然而,在这种情况下,它们的安全风险在很大程度上未被探索。在这项工作中,我们进行了一项试点研究,表明作为少镜头学习者的PLM极易受到后门攻击,而由于少镜头场景的独特挑战,现有的防御能力不足。为了应对这些挑战,我们提倡MDP,这是一种新型的轻量级、可插拔和有效的防御方法,适用于作为少数射击学习者的PLM。具体而言,MDP利用了中毒样本和清洁样本的掩蔽灵敏度之间的差距:参考作为分布锚的有限的少数镜头数据,它比较了不同掩蔽下给定样本的表示,并将中毒样本识别为具有显著变化的样本。我们分析表明,MDP为攻击者在攻击有效性和检测规避性之间做出选择创造了一个有趣的困境。使用基准数据集和代表性攻击的经验评估验证了MDP的有效性。
Pre-trained language models (PLMs) have demonstrated remarkable performance as few-shot learners. However, their security risks under such settings are largely unexplored. In this work, we conduct a pilot study showing that PLMs as few-shot learners are highly vulnerable to backdoor attacks while existing defenses are inadequate due to the unique challenges of few-shot scenarios. To address such challenges, we advocate MDP, a novel lightweight, pluggable, and effective defense for PLMs as few-shot learners. Specifically, MDP leverages the gap between the masking-sensitivity of poisoned and clean samples: with reference to the limited few-shot data as distributional anchors, it compares the representations of given samples under varying masking and identifies poisoned samples as ones with significant variations. We show analytically that MDP creates an interesting dilemma for the attacker to choose between attack effectiveness and detection evasiveness. The empirical evaluation using benchmark datasets and representative attacks validates the efficacy of MDP.

Lockdown: Backdoor Defense for Federated Learning with Isolated Subspace Training
https://neurips.cc/virtual/2023/poster/71476
代码:https://github.com/LockdownAuthor/Lockdown
摘要:
联邦学习(FL)由于其分布式计算性质,很容易受到后门攻击。现有的防御解决方案通常在训练或测试阶段需要大量的计算,这限制了它们在资源约束场景中的实用性。在集中式后门设置中,提出了一种更实用的防御方法,即基于神经网络修剪的防御。然而,我们的实证研究表明,传统的基于修剪的解决方案在FL中受到\textit{毒耦合}效应的影响,这显著降低了防御性能。本文提出了一种孤立子空间训练方法Lockdown来减轻毒耦合效应。锁定遵循三个关键程序。首先,它通过隔离不同客户端的训练子空间来修改训练协议。其次,它利用随机性初始化孤立的子空间,并执行子空间修剪和子空间恢复来隔离恶意和良性客户端之间的子空间。第三,它引入了quorum共识,通过清除恶意/伪参数来修复全局模型。经验结果表明,与现有的针对后门攻击的代表性方法相比,Lockdown实现了\textit{优越}和\textit{一致}的防御性能。Lockdown的另一个增值特性是通信效率和模型复杂性的降低,这两个特性对于资源约束的FL场景都至关重要。
Federated learning (FL) is vulnerable to backdoor attacks due to its distributed computing nature. Existing defense solution usually requires larger amount of computation in either the training or testing phase, which limits their practicality in the resource-constrain scenarios. A more practical defense, neural network (NN) pruning based defense has been proposed in centralized backdoor setting. However, our empirical study shows that traditional pruning-based solution suffers \textit{poison-coupling} effect in FL, which significantly degrades the defense performance. This paper presents Lockdown, an isolated subspace training method to mitigate the poison-coupling effect. Lockdown follows three key procedures. First, it modifies the training protocol by isolating the training subspaces for different clients. Second, it utilizes randomness in initializing isolated subspacess, and performs subspace pruning and subspace recovery to segregate the subspaces between malicious and benign clients. Third, it introduces quorum consensus to cure the global model by purging malicious/dummy parameters. Empirical results show that Lockdown achieves \textit{superior} and \textit{consistent} defense performance compared to existing representative approaches against backdoor attacks. Another value-added property of Lockdown is the communication-efficiency and model complexity reduction, which are both critical for resource-constrain FL scenario.
FedGame: A Game-Theoretic Defense against Backdoor Attacks in Federated Learning
https://neurips.cc/virtual/2023/poster/70499
摘要:
联合学习(FL)实现了分布式训练模式,多个客户端可以联合训练全局模型,而无需共享其本地数据。然而,最近的研究表明,联合学习为后门攻击提供了额外的表面。例如,攻击者可以危害客户端的子集,从而破坏全局模型,从而将后门触发器作为对抗性目标的输入预测错误。现有的针对后门攻击的联合学习防御通常基于$\textit{static}$攻击者模型检测并排除受损客户端中的损坏信息。然而,这样的防御措施不足以对抗战略性地调整攻击策略的$\textit{dynamic}$攻击者。为了弥补防守中的这一差距,我们将FL中的防守队员和动态进攻队员之间的单阶段或多阶段战略互动建模为一个极大极小游戏。在分析模型的基础上,我们设计了一个交互式防御机制FedGame。我们还证明了在温和的假设下,在后门攻击下用FedGame训练的全局FL模型与没有攻击的训练的FL模型接近。根据经验,我们对基准数据集进行了广泛的评估,并将FedGame与多个最先进的基线进行了比较。我们的实验结果表明,FedGame可以有效地抵御战略攻击者,并实现比基线显著更高的鲁棒性。例如,与Scaling攻击下的六个最先进的防御基线相比,FedGame在CIFAR10上的攻击成功率降低了82%。
Federated learning (FL) enables a distributed training paradigm, where multiple clients can jointly train a global model without needing to share their local data. However, recent studies have shown that federated learning provides an additional surface for backdoor attacks. For instance, an attacker can compromise a subset of clients and thus corrupt the global model to mispredict an input with a backdoor trigger as the adversarial target. Existing defenses for federated learning against backdoor attacks usually detect and exclude the corrupted information from the compromised clients based on a $\textit{static}$ attacker model. Such defenses, however, are not adequate against $\textit{dynamic}$ attackers who strategically adapt their attack strategies. To bridge this gap in defense, we model single or multi-stage strategic interactions between the defender in FL and dynamic attackers as a minimax game. Based on the analysis of our model, we design an interactive defense mechanism FedGame.We also prove that under mild assumptions, the global FL model trained with FedGame under backdoor attacks is close to that trained without attacks. Empirically, we perform extensive evaluations on benchmark datasets and compare FedGame with multiple state-of-the-art baselines. Our experimental results show that FedGame can effectively defend against strategic attackers and achieves significantly higher robustness than baselines. For instance, FedGame reduces attack success rate by 82\% on CIFAR10 compared with six state-of-the-art defense baselines under Scaling attack.
Neural Polarizer: A Lightweight and Effective Backdoor Defense via Purifying Poisoned Features
https://neurips.cc/virtual/2023/poster/71467
论文:https://arxiv.org/abs/2306.16697
摘要:
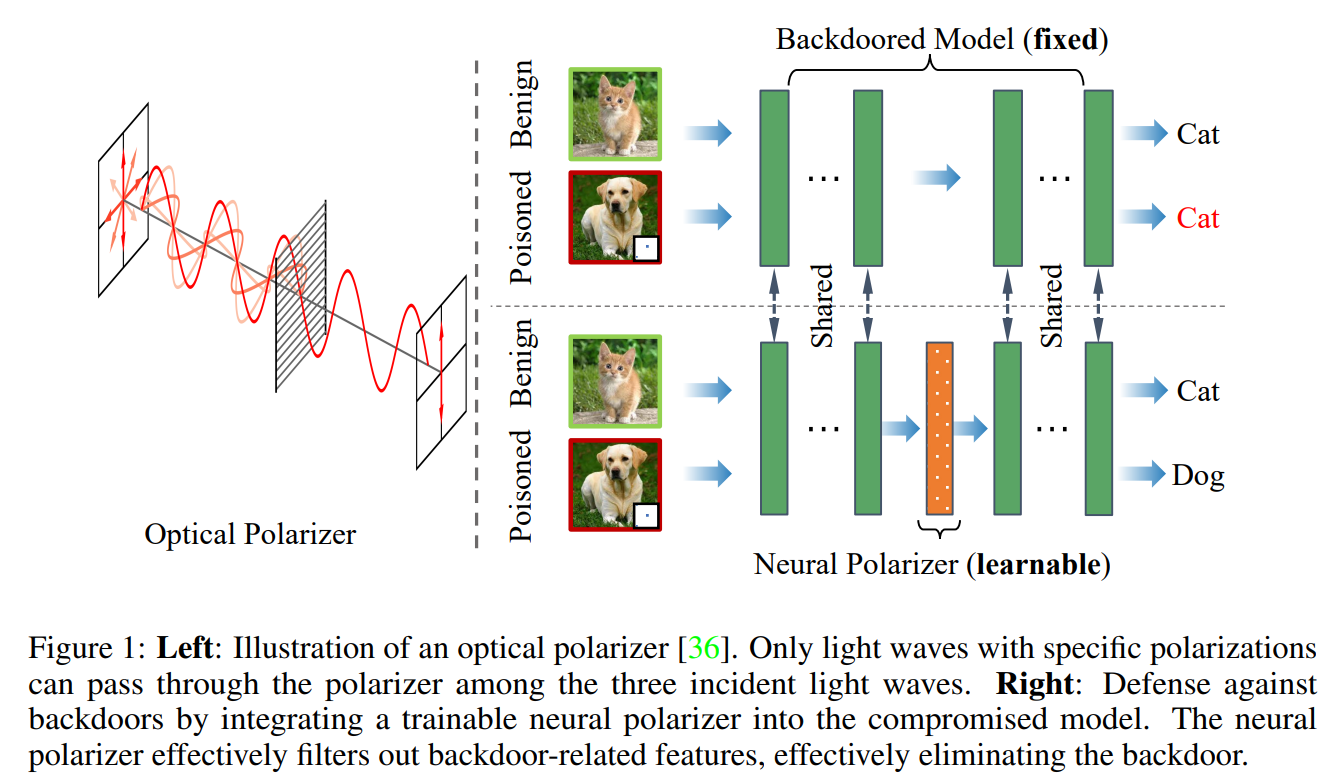
最近的研究已经证明了深度神经网络对后门攻击的易感性。给定一个后门模型,尽管触发信息和良性信息共存,但其对具有触发的中毒样本的预测将由触发信息主导。受光偏振器机制的启发,即偏振器可以通过具有特定偏振的光波,同时过滤具有其他偏振的光波。我们提出了一种新的后门防御方法,通过在后门模型中插入可学习的神经偏振器作为中间层,以便在保持良性信息的同时通过过滤触发信息来纯化中毒样品。神经偏振器被实例化为一个轻量级的线性变换层,该层是通过基于有限的干净数据集解决精心设计的双层优化问题来学习的。与其他经常调整后门模型的所有参数的基于微调的防御方法相比,所提出的方法只需要学习一个额外的层,因此它更高效,并且需要更少的干净数据。大量实验证明了我们的方法在消除各种神经网络架构和数据集的后门方面的有效性和效率,特别是在干净数据非常有限的情况下。
Recent studies have demonstrated the susceptibility of deep neural networks to backdoor attacks. Given a backdoored model, its prediction of a poisoned sample with trigger will be dominated by the trigger information, though trigger information and benign information coexist. Inspired by the mechanism of the optical polarizer that a polarizer could pass light waves with particular polarizations while filtering light waves with other polarizations, we propose a novel backdoor defense method by inserting a learnable neural polarizer into the backdoored model as an intermediate layer, in order to purify the poisoned sample via filtering trigger information while maintaining benign information. The neural polarizer is instantiated as one lightweight linear transformation layer, which is learned through solving a well designed bi-level optimization problem, based on a limited clean dataset. Compared to other fine-tuning-based defense methods which often adjust all parameters of the backdoored model, the proposed method only needs to learn one additional layer, such that it is more efficient and requires less clean data. Extensive experiments demonstrate the effectiveness and efficiency of our method in removing backdoors across various neural network architectures and datasets, especially in the case of very limited clean data.

A Unified Framework for Inference-Stage Backdoor Defenses
https://neurips.cc/virtual/2023/poster/72827
A Unified Framework for Inference-Stage Backdoor Defenses (jding.org)
摘要:
后门攻击涉及在训练过程中插入中毒样本,导致模型包含一个隐藏的后门,该后门可以触发特定行为,而不会影响正常样本的性能。这些攻击很难检测,因为后门模型在被后门触发器激活之前看起来是正常的,这使得它们特别隐蔽。在这项研究中,我们设计了一个统一的推理阶段检测框架来抵御后门攻击。我们首先严格制定了推理阶段后门检测问题,包括各种现有方法,并讨论了一些挑战和局限性。然后,我们提出了一个框架,该框架对假阳性率或错误分类干净样本的概率具有可证明的保证。此外,我们推导了最强大的检测规则,以最大限度地提高检测能力,即在经典学习场景下,在给定假阳性率的情况下,准确识别后门样本的速率。基于理论上的最优检测规则,我们提出了一种实用有效的方法,用于基于后门深度网的潜在表示的现实应用。我们使用计算机视觉(CV)和自然语言处理(NLP)基准数据集,在12种不同的后门攻击上广泛评估了我们的方法。实验结果与我们的理论结果一致。我们显著超过了最先进的方法,例如,与最先进的防御高级自适应后门攻击相比,AUROC评估的检测能力提高了300\%。
Backdoor attacks involve inserting poisoned samples during training, resulting in a model containing a hidden backdoor that can trigger specific behaviors without impacting performance on normal samples. These attacks are challenging to detect, as the backdoored model appears normal until activated by the backdoor trigger, rendering them particularly stealthy. In this study, we devise a unified inference-stage detection framework to defend against backdoor attacks. We first rigorously formulate the inference-stage backdoor detection problem, encompassing various existing methods, and discuss several challenges and limitations. We then propose a framework with provable guarantees on the false positive rate or the probability of misclassifying a clean sample. Further, we derive the most powerful detection rule to maximize the detection power, namely the rate of accurately identifying a backdoor sample, given a false positive rate under classical learning scenarios. Based on the theoretically optimal detection rule, we suggest a practical and effective approach for real-world applications based on the latent representations of backdoored deep nets. We extensively evaluate our method on 12 different backdoor attacks using computer vision (CV) and natural language processing (NLP) benchmark datasets. The experimental findings align with our theoretical results. We significantly surpass the state-of-the-art methods, e.g., up to 300\% improvement on the detection power as evaluated by AUCROC, over the state-of-the-art defense against advanced adaptive backdoor attacks.