点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
在CVer微信公众号后台回复:PointGPT,可以下载本论文pdf、代码
3D点云在自动驾驶、机器人和增强现实等各种应用中表现出巨大的潜力。与2D图像中有规律的像素不同,3D点的排列不规则,这阻碍了直接采用经过充分研究的2D网络来处理3D数据。因此,探索适合三维点云数据的先进方法势在必行。然而,目前以三维为中心的方法通常需要从头开始的完全监督训练,这需要劳动密集型的人工注释。在自然语言处理(NLP)和图像分析领域,自监督学习(SSL)已经成为一种获取潜在表示的不依赖注释的方法。在这些方法中,生成式预训练Transformer(GPT)在学习代表性特征方面特别有效,其任务是以自回归的方式预测数据。由于其出色的性能,自然会提出这样一个问题:GPT能否适应点云,并作为一个有效的三维表示学习器?

从点云中进行自动回归生成的预训练
PointGPT
论文解读
摘要
这篇论文介绍了一种名为PointGPT的方法,将GPT的概念扩展到了点云数据中,以解决点云数据的无序性、低信息密度和任务间隔等挑战。论文提出了一种点云自回归生成任务来预训练Transformer模型。该方法将输入的点云分割成多个点块,并根据它们的空间接近性将它们排列成有序序列。然后,基于提取器-生成器的Transformer解码器(使用双重掩码策略)学习了在前序点块条件下的潜在表示,以自回归方式预测下一个点块。这种可扩展的方法可以学习到高容量模型,具有很好的泛化能力,在各种下游任务上实现了最先进的性能。具体来说,该方法在 ModelNet40数据集上实现了94.9%的分类准确率,在ScanObjectNN数据集上实现了93.4%的分类准确率,超过了所有其他Transformer模型。此外,该方法还在四个小样本学习基准测试上获得了新的最先进准确率。

论文链接:https://arxiv.org/pdf/2305.11487.pdf
代码链接:https://github.com/CGuangyan-BIT/PointGPT
论文贡献
1.提出了一种名为PointGPT的新型GPT模型用于点云自监督学习(SSL)。PointGPT利用点云自回归生成任务,同时减轻了位置信息泄漏的问题,在单模态自监督学习方法中表现出色。
2.提出了一种双重掩码策略来创建有效的生成任务,并引入了提取器-生成器Transformer架构来增强学习表示的语义级别。这些设计提高了PointGPT在下游任务中的性能。
3.引入了一个预训练后阶段,并收集了更大的数据集,以促进高容量模型的训练。利用PointGPT,本文的扩展模型在各种下游任务上实现了最先进的性能。
总体框架
PointGPT方法的示意图如图1所示。输入的点云被分割成多个点块,并按照它们的空间接近性排列成一个有序序列。这个序列被输入到 Transformer解码器中,解码器根据之前预测的点块来预测下一个点块。这种自回归的方式使得模型能够逐步生成点块,并且模型可以利用之前生成的点块来预测下一个点块。通过这种方式,PointGPT的方法能够在没有专门指定点块的情况下进行预测,并且避免了位置信息泄漏的问题,从而提高了模型的泛化能力。这种方法的优势在于能够处理点云数据的无序性,并且在各种下游任务上表现出较好的性能。
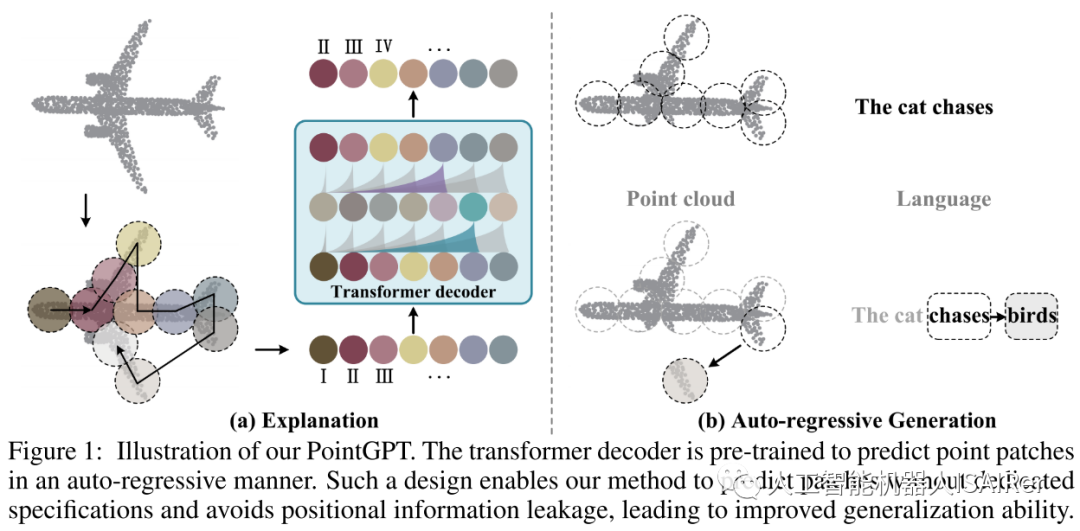
图2展示了PointGPT在预训练阶段的整体流程。
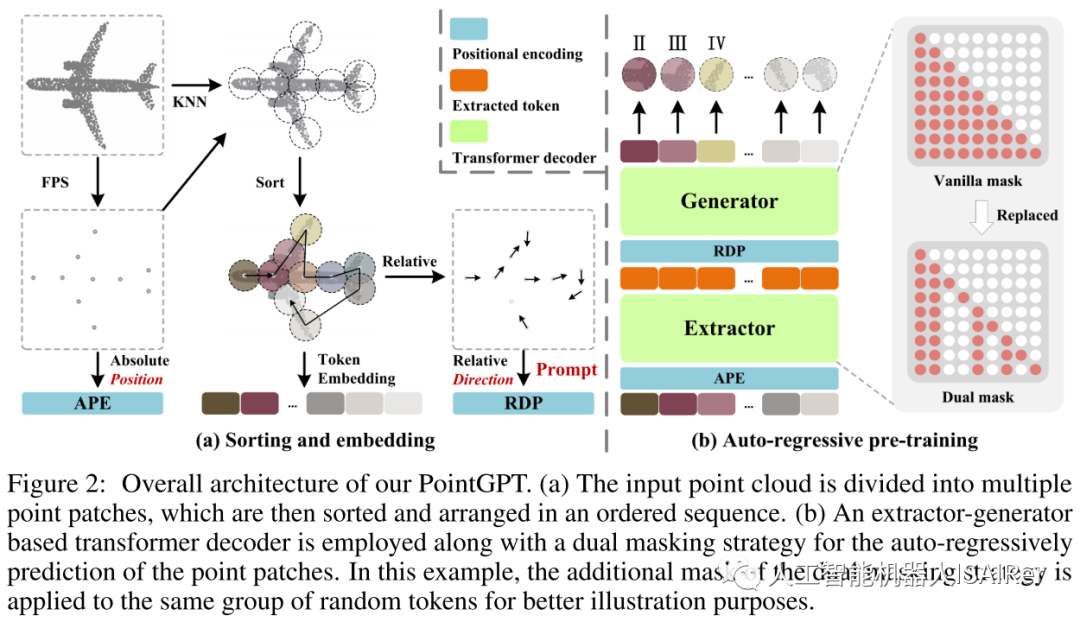
1.点云序列模块
PointGPT的预训练流程包括使用点云序列模块构建有序的点块序列,提取器学习点块的潜在表示,生成器自回归生成点块序列。在预训练后阶段,生成器被舍弃,提取器利用学习到的表示进行下游任务。这个流程旨在通过自回归生成任务来学习点云数据的特征表示,并为后续任务提供更好的表示能力。
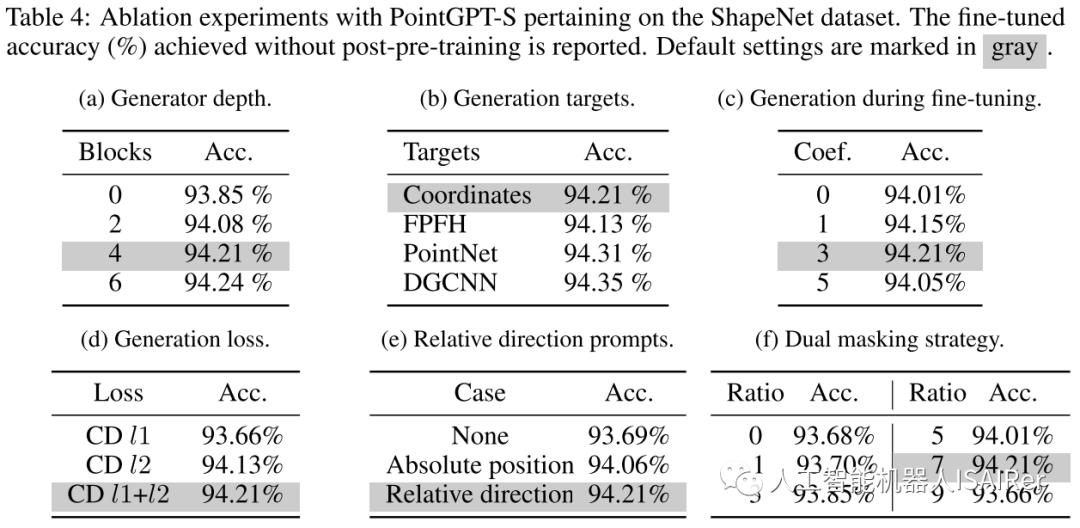
点块分割:该阶段将点云划分为不规则的点块。通过将点云分割成块状的子集,可以将点云的结构分解成更小的部分,以便更好地进行处理。考虑到点云的固有稀疏性和无序性,输入点云通过最远点采样(FPS)和K近邻(KNN)算法处理,以获取中心点和点块。
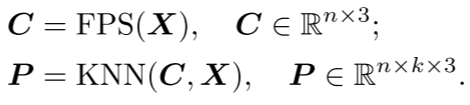
排序:为了解决点云的固有无序性,获得的点块根据它们的中心点被组织成一个连贯的序列。具体而言,使用Morton编码将中心点的坐标编码到一维空间中,然后进行排序以确定这些中心点的顺序 。然后,将点块按照相同的顺序排列。
。然后,将点块按照相同的顺序排列。
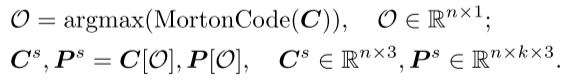
嵌入:在PointGPT中,采用了嵌入(Embedding)步骤来提取每个点块的丰富几何信息。排序后的点块序列被嵌入到模型中,用于后续的预训练和任务学习。嵌入可以将点块的几何信息转化为模型能够理解和处理的向量表示。这里使用了PointNet网络来进行几何信息的提取。
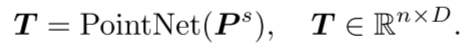
2.提取器-生成器Transformer架构
双重掩码策略:Transformer解码器中的基本掩码策略使得每个token都可以从所有前面的点token中接收信息。为了进一步促进有用表示的学习,提出了双重掩码策略,该策略在预训练期间还会额外屏蔽每个token所参考的一定比例的前置token。所得的双重掩码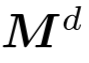 如图2(b),具有双重掩码策略的自我注意过程可以表示为:
如图2(b),具有双重掩码策略的自我注意过程可以表示为:
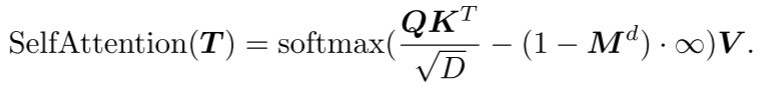
其中,Q、K、V是T用D个通道的不同权重进行编码的。将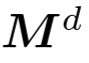 中的经掩码位置设定为0,而将未经掩码位置设定为1。
中的经掩码位置设定为0,而将未经掩码位置设定为1。
提取器:提取器完全由Transformer解码器块组成,并采用双重掩码策略,得到潜在表示 。用正弦位置编码(PE)将排序的中心点的坐标映射到绝对位置编码(APE)。
。用正弦位置编码(PE)将排序的中心点的坐标映射到绝对位置编码(APE)。
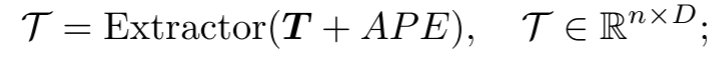
生成器:生成器的架构与提取器类似,但包含较少的Transformer块。它以提取的 作为输入,并生成用于后续预测头的点
作为输入,并生成用于后续预测头的点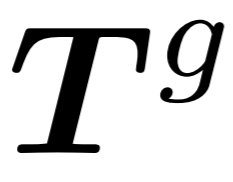 。然而,由于中心点采样过程可能会影响点块的顺序,这在预测后续点块时会引入不确定性。这使得模型难以有效地学习有意义的点云表示。为了解决这个问题,在生成器中加入了中心点之间的相对方向提示(RDP),提供了相对于后续点块的方向信息,作为提示而不暴露被掩码的点块的位置和整体点云对象的形状。
。然而,由于中心点采样过程可能会影响点块的顺序,这在预测后续点块时会引入不确定性。这使得模型难以有效地学习有意义的点云表示。为了解决这个问题,在生成器中加入了中心点之间的相对方向提示(RDP),提供了相对于后续点块的方向信息,作为提示而不暴露被掩码的点块的位置和整体点云对象的形状。
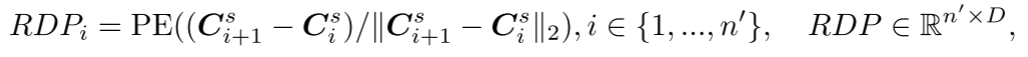
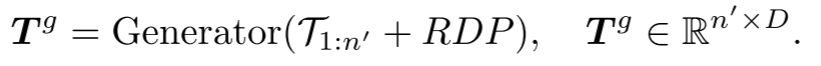
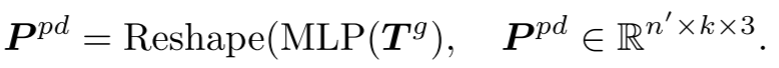
预测头:预测头用于在坐标空间中预测后续的点块。它由一个两层的多层感知机(MLP)组成,包含两个全连接(FC)层和(ReLU)激活函数。预测头将token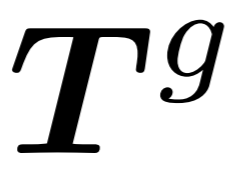 投影到向量空间,其中输出通道的数量等于一个点块中的坐标总数。然后,这些向量被重新组织成预测的点块。
投影到向量空间,其中输出通道的数量等于一个点块中的坐标总数。然后,这些向量被重新组织成预测的点块。
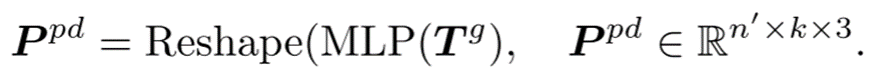
3.中间微调和预训练后阶段
传统的点云自监督学习(SSL)方法直接在目标数据集上微调预训练模型,由于语义监督信息有限,这可能导致潜在的过拟合问题。为了缓解这个问题并便于训练高容量模型,PointGPT采用了中间微调策略,并引入了一个预训练后的阶段。在这个阶段中,使用一个带标签的混合数据集进行训练,该数据集收集和对齐了多个带标签的点云数据集。通过在这个数据集上进行监督训练,可以有效地从多个来源合并语义信息。随后,在目标数据集上进行微调,将学到的通用语义知识转移到任务特定的知识上。这种中间微调和预训练后阶段的策略有助于提高模型的泛化能力,避免潜在的过拟合问题,并利用多样化的语义信息来提升模型的性能。
实验结果
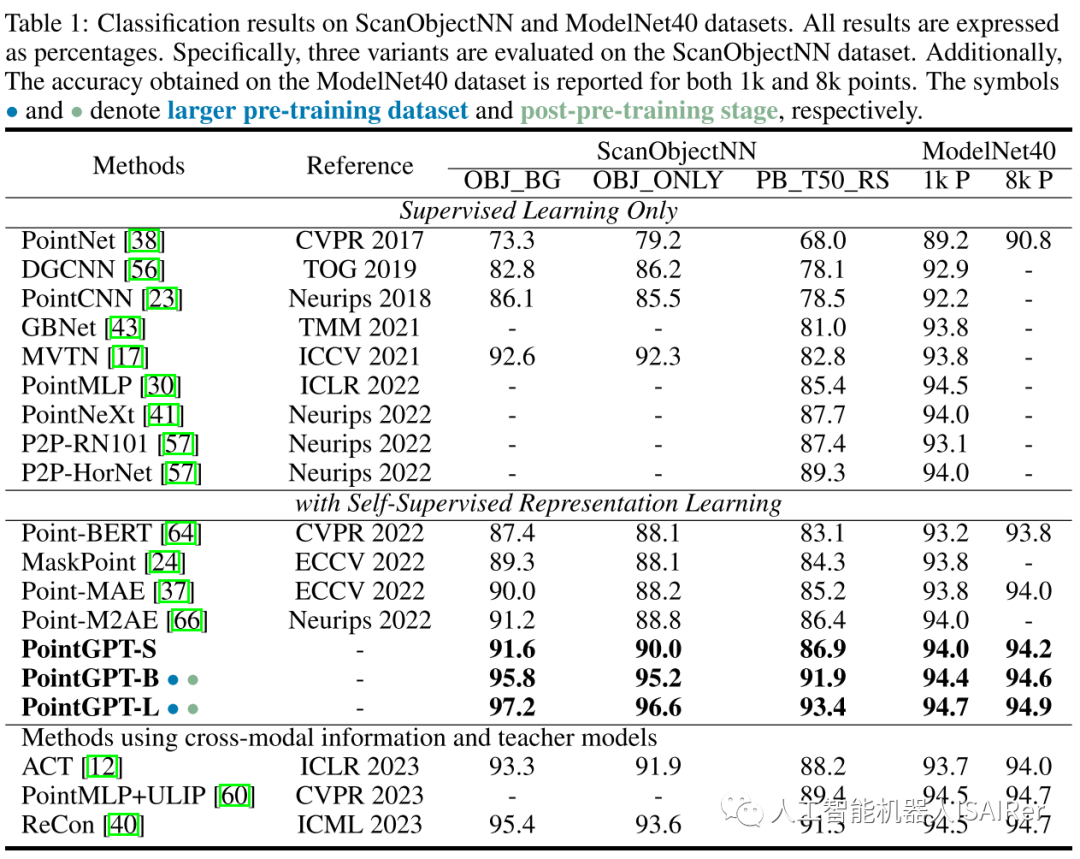
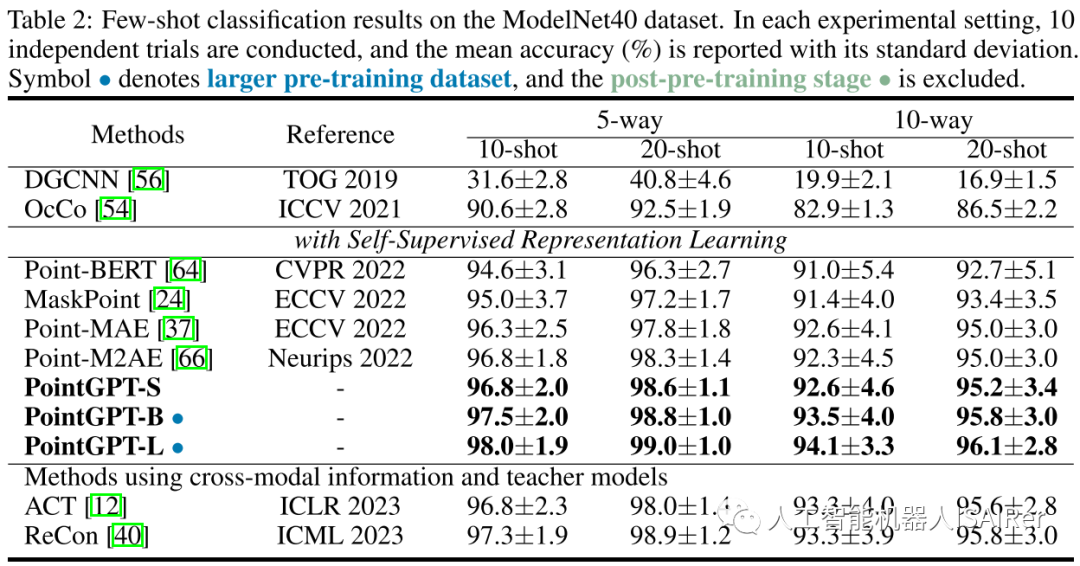
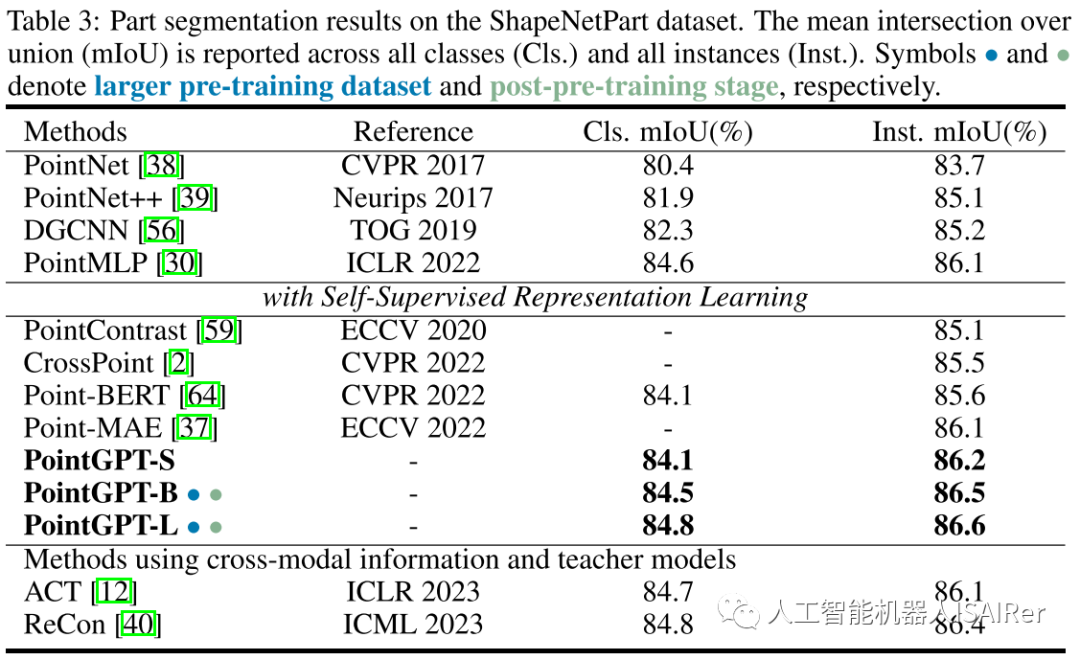
为了展示PointGPT在不同下游任务上的性能,本文进行了一系列实验,包括真实世界和干净对象数据集上的物体分类、少样本学习和部分分割。使用三种不同的模型容量来评估PointGPT的性能:PointGPT-S是指在ShapeNet数据集上进行预训练但不进行预训练后阶段;PointGPT-B和PointGPT-L,在收集的混合数据集上进行预训练和预训练后阶段。
PointGPT-S在ShapeNet数据集上进行预训练,而无需后续的后预训练。这与前面的SSL方法是一致的,以便与前面的方法进行直接比较。另外,为了支持高容量PointGPT模型(PointGPT-B和PointGPT-L)的训练,收集了两个数据集:(1)用于自监督预训练的无标记混合数据集(UHD),从各种数据集中收集点云,例如用于室内场景的ShapeNet、S3DIS和用于室外场景的Semantic3D等。UHD总共包含大约300K点云; (2)用于有监督后预训练的标记混合数据集(LHD),它将不同数据集的标记语义对齐,共有87个类别和大约200k个点云。
结论&讨论
本文介绍了PointGPT,这是一种将GPT概念扩展到点云领域的新方法,解决了点云的无序性、信息密度差异和生成任务与下游任务之间的差距等挑战。与最近提出的自监督遮蔽点建模方法不同,本文的方法避免了整体物体形状泄漏,具有更好的泛化能力。此外,本文还探索了高容量模型的训练过程,并收集了用于预训练和预训练后阶段的混合数据集。本文的方法在各种任务上验证了其有效性和强大的泛化能力,表明PointGPT在模型容量相似的单模态方法中表现优异。此外,本文的大规模模型在各种下游任务上取得了SOTA的性能,无需跨模态信息和教师模型的参与。尽管PointGPT表现出了良好的性能,但其探索的数据和模型规模仍然比NLP和图像处理领域小几个数量级。
在CVer微信公众号后台回复:PointGPT,可以下载本论文pdf、代码
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集
3D点云交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-3D点云 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如3D点云+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看