背景
用最少的计算资源,解决了LLM大模型预测问题,训练了一些列的LLaMa模型,在参数量比较少的情况下,达到业界大模型效果。
主要贡献就是提升了LLM模型的训练速度和效率,在小容量的基础上,大大提升了模型的效果。
同时由于模型结构更小更简单,大大提升了推理速度。
数据
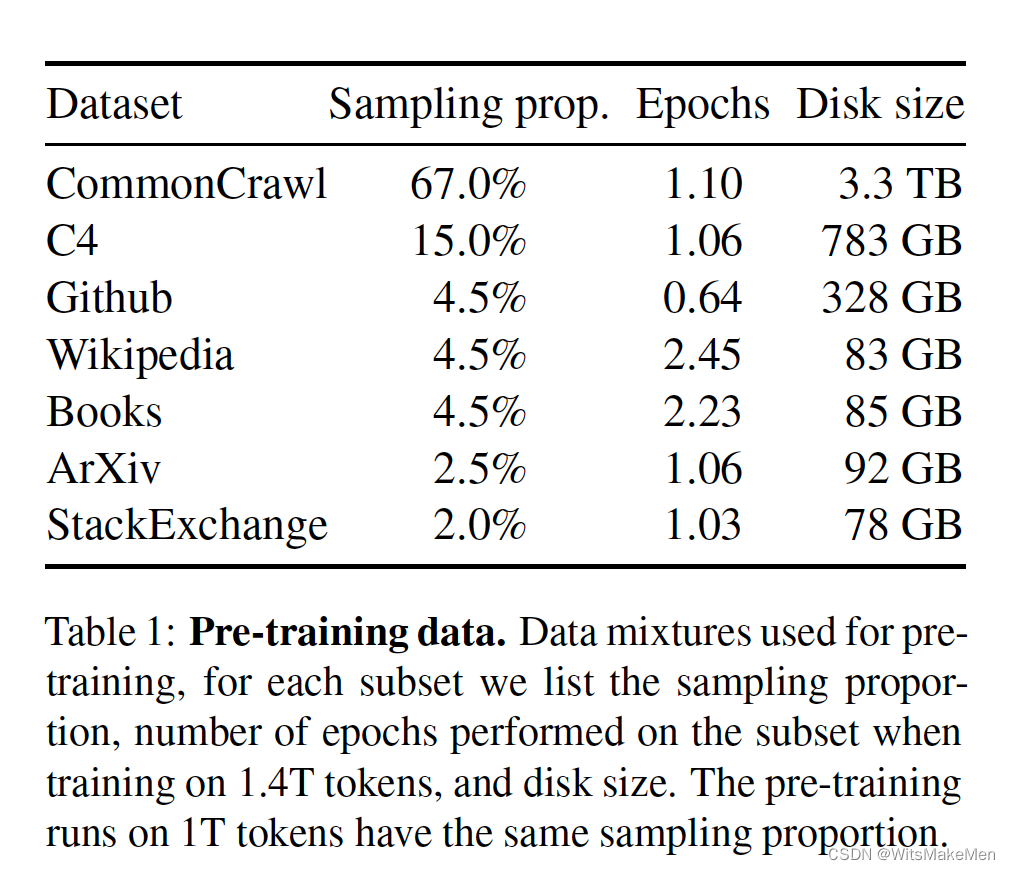
预训练的数据都是业界公开的数据结合,比较透明。
模型结构
主体模型结构还是transformer经典模型结构,但是进行了优化,比如说不是在每一层的output结果上进行norm正则化,而是在input层进行norm正则化。替换了激活函数等。

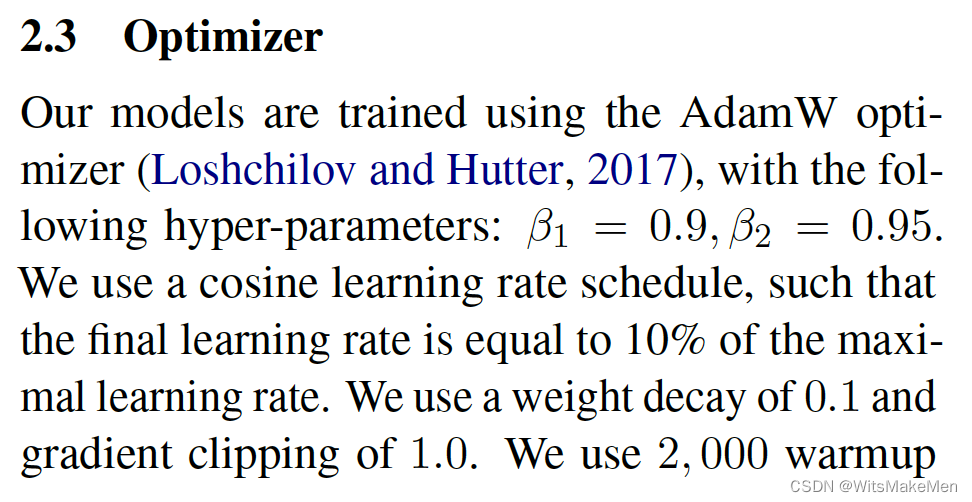
优化器
训练加速优化
使用了《SELF-ATTENTION DOES NOT NEED O(n2) MEMORY》思想,对self-attention进行了内存优化,将内存使用量从O(n2)简化到了O(log(n)),大大降低了模型内存占用量,有效提升了长序列处理的能力。

