论文: https://arxiv.org/pdf/2207.01772
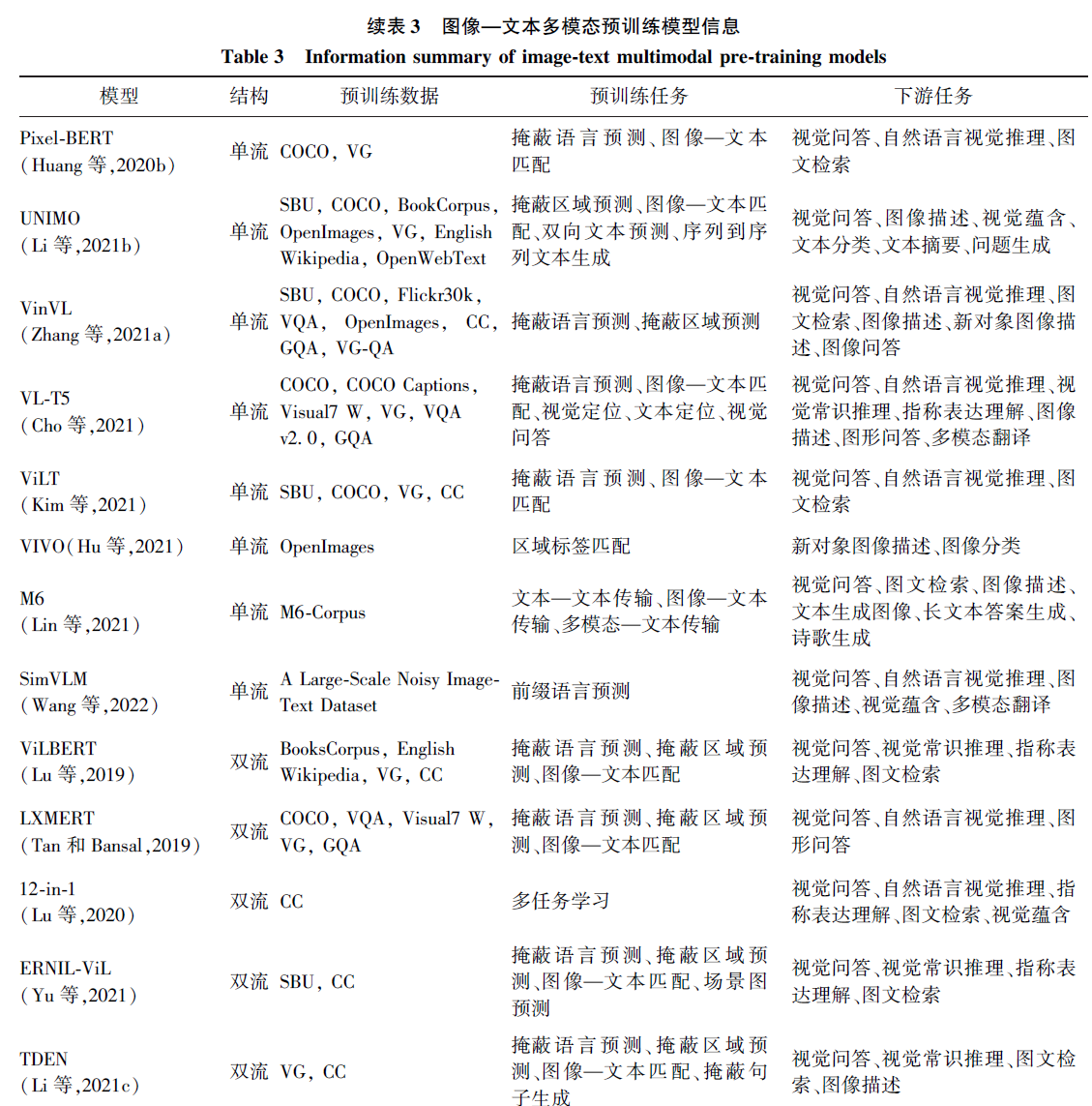
预训练数据集

预训练任务

模型结构
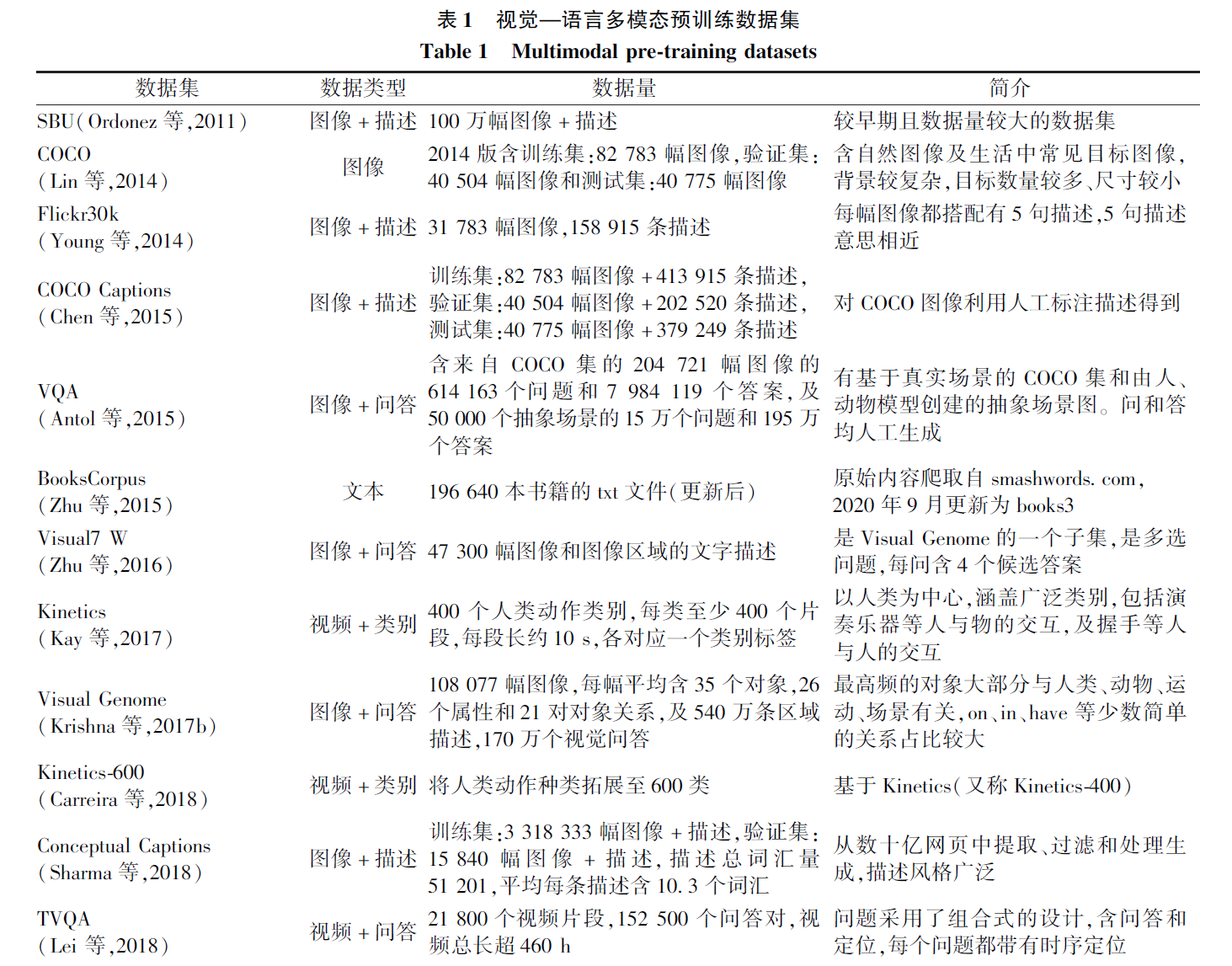
本文根据特征在进行视觉和语言模态融合处理之前是否进行处理,将VLP 模型按结构分为单流式(single-stream) 和双流式( cross-stream)
单流模型将视觉特征和语言特征直接输入融合模块,进行模型训练,其典型方式如图1(a)所示;双
流模型将视觉特征和语言特征分别进行处理,然后进行模态间的融合,典型类型包括但不限于图中
3 类:图1(b)中,模型首先对两路特征分别进行处理,然后进行跨模态融合;图1(c)中,视觉特征经过
视觉处理模块后,与文本特征一同送入多模态融合模块进行交互;图1(d)中,两路特征送入各自处理模块后进行交互式的参数训练。
基础方法
视觉输入特征
Visual Encoder主要包括3种类型。
第一种类型为使用object detection模型(一般为Faster R-CNN)识别图像中的目标区域,并生成每个目标区域的特征表示,输入到后续模型中。例如下图是Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training(AAAI 2020)中的一个例子,对图中的各个目标region识别后生成表示,融入到主模型Bert中。
第二种方式是利用CNN模型提取grid feature作为图像侧输入。
第三种方式是ViT采用的将图像分解成patch,每个patch生成embedding输入到模型中。随着Vision-Transformer的发展,第三种方式逐渐成为主流方法,相比前两种方式运行效率更高,不需要依赖object detection模块或前置的CNN特征提取模块。
文本输入特征
Bert, Transformer
包括诸如BERT、RoBERTa、ELECTRA、ALBERT、DeBERTa等经典预训练语言模型结构
多模态融合
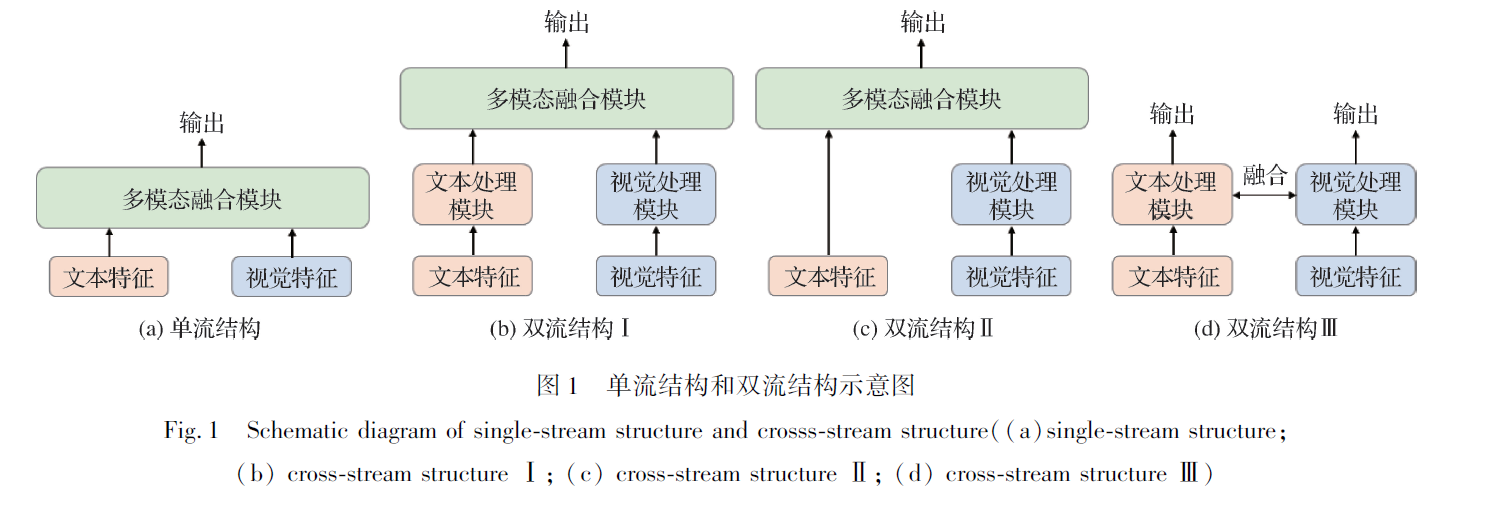
多模态融合常采用Transformer 结构,如图2 所示,其由多层编码器—解码器(encoder-decoder) 结
构组成,N 为层数,编码器中含有两个多头注意力机制模块(multi-head attention, MHA),其由多个自注意力层组成。编解码器均通过残差连接相加并进行正则化,并通过前馈神经网络层(feed forward layer)进行激活。
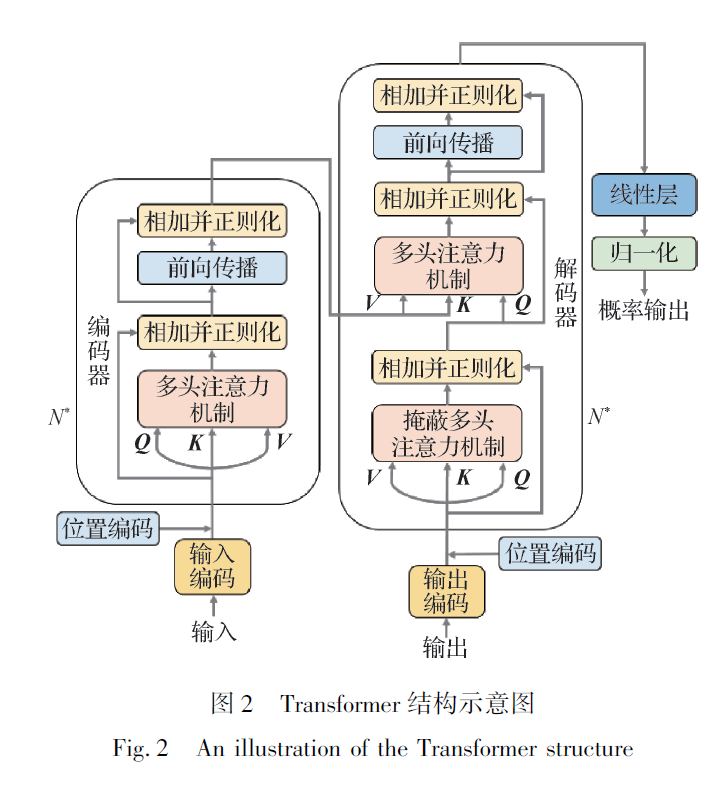
Transformer 的核心是位于MHA 之中的自注意力层(self-attention layer)。自注意力层的输入来自
添加位置编码(position encodin)的文本或视觉特征词向量F = {f0, f1,…, fn } ,将输入线性转换为3 个
不同向量:查询(query): Q ∈ Rn×dQ 、键(key): K ∈ Rn×dK 和值(value): V ∈ Rn×dV ,自注意操作Att()通 过式(11)来学习词与词间的关系
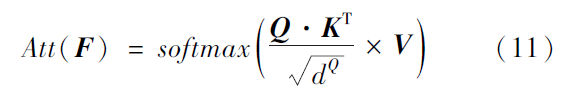
将多个自注意力层的输出进行拼接,然后通过线性层输出即为MHA 的输出,其与输入特征的维
度相同。在解码器的第2 个MHA 中,键和值来自本层编码器,查询来自上层解码器。MHA 的输出结合上下文信息,再通过一个前馈网络经过非线性变化,输出综合了上下文特征的各个词的向量表示。
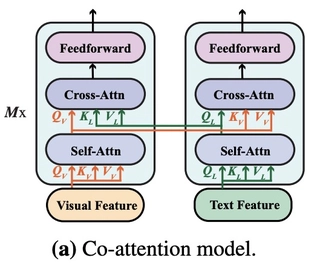
co-attention
图像侧和文本侧分别使用Transformer编码,在每个Transformer模块中间加入图像和文本之间的cross attention。
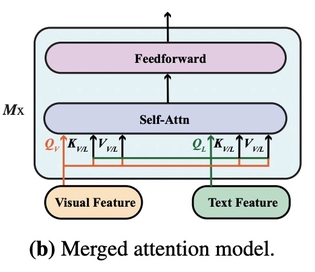
merged attention model
图像侧和文本侧的信息在最开始就被拼接到一起,输入到Transformer模型中。其中,merged attention model方法的参数量相对更少。实验结果表明,co-attention要比merged attention效果更好。
预训练模型
感觉都有点年代久远了,仅供参考


单流
一般将图像与文本两种模态信息置于等同重要位置,对图像和文本编码后共同输入跨模态融合模块进行预训练。对于输入图像是否采用目标检测算法,可对研究进行更细致的分类。
采用目标检测算法
输入的编码处理进行改进
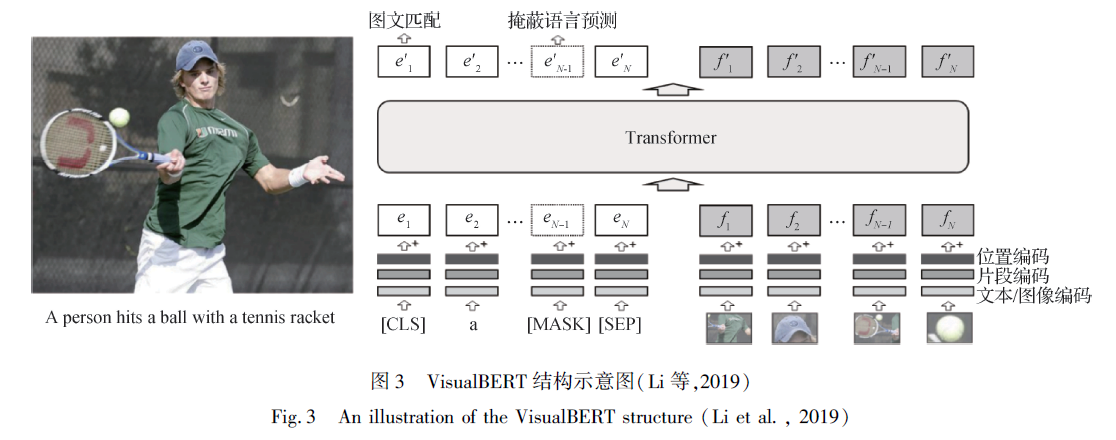
eg1 VisualBERT
文本
采用类似BERT 的方式进行处理,首先将文本分割成一个单词序列,然后使WordPiece对每个单词进行标记,最后采用一个编码矩阵处理得到token embedding序列,其中添加[CLS]作为文本开端,[SEP]作为图文分隔。将原词编码、区分输入不同模态的segment embedding和序列位置编码(sequence position embedding)映射到同一维度组合成文本的最终编码。
图像
采用目标检测算法,如Faster-RCNN 提取区域特征编码,与片段编码和位置编码组合映射到文本编码相同维度得到最终编码。
序列位置编码
语言
一般采取升序来表示文本描述中词的顺序
视觉
当输入提供单词与边界区域间的匹配时,会设置为匹配单词对应的位置编码的总和。
将文本和图像最终编码共同输入Transformer 进行MLM 和ITM 预训练,应用于4 类下游图像文本任务。(?)
eg2 Unicoder-VL(universal encoder for vision and language)
对图像输入使用Faster-RCNN 提取RoI 视觉特征时还生成区域对象标签及区域空间位置特征。
区域对象标签用于MRC训练,空间位置特征含RoI 边界框(bounding box)4 个顶点的值坐标(归一化在0 和1 之间)和区域面积(相对面积,区域面积与图像面积之比,指在0 和1之间)。将RoI 视觉特征和空间位置特征通过FC 投影到同一维度空间,二者相加后送入归一化层(layernormalization, LN)得到最终视觉编码与文本编码一起送入Transformer 进行MLM、MRC 和ITM 训练。
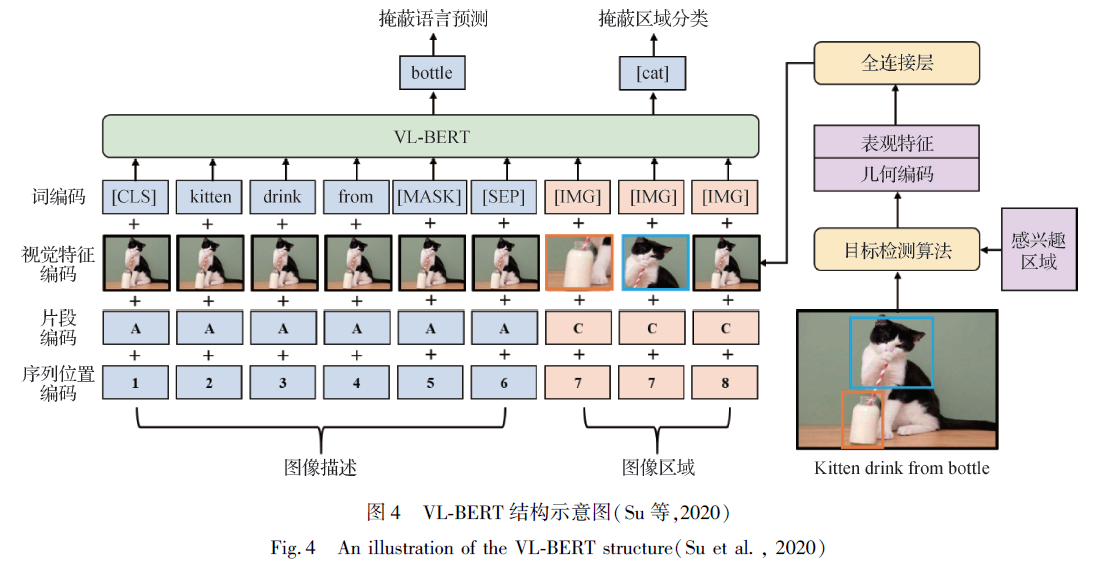
Su 等人(2020)提出的VL-BERT(visual-language BERT)在进行图像编码时,新增了一个视觉特征编码(visualfeature embedding),具体为非视觉输入部分对应整个图像提取的特征,视觉输入部分对应图像经特征提取器所提取的特征,同时在词编码上增加一个特殊符[IMG]对应RoI 图像标记。(?)
eg3 Oscar
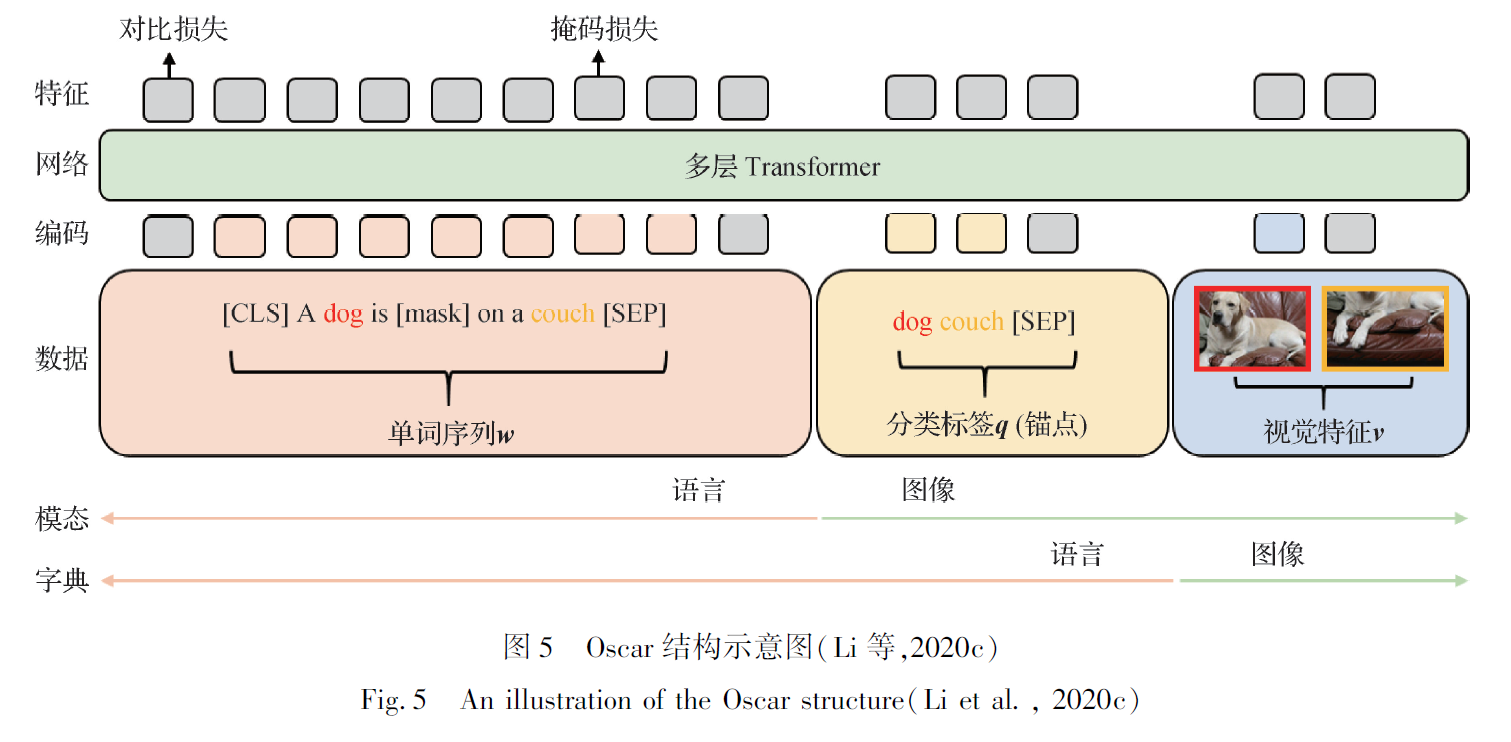
首次引入目标检测中的区域分类标签作为视觉和语言层面上的锚点( anchor point),使图文间的语义对齐任务得以简化
利用特征提取器给每个区域输出的分类标签,将输入图文对表示为单词序列w、分类标签q、区域特征v 三元组, 共享相同的语义特征,从而将预训练优化目标变为最小化视觉损失和文本损失之和。输入三元组可以从两个角度理解,即模态视角和字典视角。因标签序列由特征抽取模型分类得到,所以模态为图像,表示形式为文本,使用文本的字典。分类标签实现了输入层面上的跨模态。
考虑到视觉特征对于VLP 模型的重要性,团队进一步研究对Oscar 的物体检测模型(object detecter,OD)进行了改进,提出了VinVL(Zhang 等,2021a),表明更好的视觉特征可有效改善视觉语言模型的表现。
改进预训练任务
eg1 UNITER(universal image-text representation)
采用条件掩蔽MLM 和MRM 预训练任务,有别于传统设定的双模态随机掩蔽,掩蔽一种模态时保持另一模态不变,这可防止区域与对应描述单词同时被掩蔽造成不对齐问题。此外,设计了文本—区域匹配预训练任务,通过最优传输最小化图像区域和句子中单词间的对齐成本,优化跨模态对齐,激励单词和图像区域间的细粒度匹配。
eg2 Unified-VLP(unified vision-language pre-training)
在传统MLM 任务上新增双向(bidirectional) 和序列到序列(sequence-tosequence)目标以增强编码器和解码器间的联系。
eg3 XGPT(cross-modal generativepre-training)
为提升模型在下游生成任务上的表现,除引入图像描述任务外还设计了3 个新的预训练任务:图像条件掩蔽语言预测(image-conditioned masked language modeling, IMLM)、图像条件降噪自编码(image-conditioned denoising autoencoding, IDA) 和文本条件图像特征生成(text-conditioned image feature generation, TIFG)。
采用有效的预训练策略
eg1 Image-BERT
从互联网搜集了一个大规模视觉和文本信息的数据集(large-scale weak-supervised imagetext, LAIT),基于此设计了多阶段预训练策略,即先在规模最大但质量较低的LAIT 上训练,然后在高质量CC 和SBU 上训练。实验表明预训练中不同质量数据集的使用顺序对性能有很大的影响。
eg2 多模态对比学习(crossmodal contrastive learning, CMCL)
利用丰富的非成对单模态(non-paired single-modal)数据,让文本和视觉知识在统一的语义空间中相互增强,提出UNIMO(unified-modal)能同时有效处理单模态和多模态任务。(?)
eg3 VILLA(vision-and-language large-scale adversarial)
在预训练和微调过程中对图像和文本编码特征增加扰动以增强模型的泛化性
eg4 VIVO(visual vocabulary)
可以利用数据集中数量远远大于图像—描述对的图像—标签对信息来学习
视觉词汇
eg5
对文本编码添加代表不同任务的前
缀编码,以一个统一的文本生成目标来处理各视觉
语言任务。
不采用目标检测算法
目标检测算法所能提供的RoI 类别限制了特征表示能力,会丢失场景和情感等更广泛语义的视觉信息。此外,RoI 区域为矩形,会包含有噪声的背景,丢失形状和空间关系信息。
eg1 Pixel-BERT
为充分利用原始图像的视觉信息,学习用像素来表示图像
对于输入图像,使用ResNet 对图片进行卷积、池化,最后得到一个特征矩阵,元素为特征向量,对其进行采样后,每个元素与一文本编码相加,作为一种偏置,最后展平,得到最终的像素特征编码输入Transformer 进行训练。
eg2 ViLT
将输入图像切块成一个图像patch 序列,通过线性投影而非卷积操作转化成特征编码,然后和位置编码进行相加,最后和文本编码进行集合得到最终编码输入Transformer,相比基于图像区域特征的方法处理速度大幅度提升。
eg3 SimVLM(simple visual language model)
采用类似的视觉处理方式,利用大规模弱标记数据集(Jia等,2021)只采用一个前缀语言预测预训练任务进行端到端训练,提出了一个极简的模型,在多个下游任务中表现优秀,具有强大的泛化和迁移能力。
eg4 METER(multimodal end-to-end transformer)
Dou 等人(2022)从多个维度研究模型设计对模型性能的影响,对比研究原始ViT 及其拓展的多个视觉编码方法、原始BERT 及其拓展的多个文本编码方法、不同多模态融合模块(合并注意力与协同注意力)、不同架构设计(仅编码器与编码器—解码器)以及预训练目标(MLM, ITM 等)对模型性能的影响,得出在VLP 中ViT 比文本编码器更重要的结论,以及其他一些VLP 模型设计的结论。
eg5 m6
中文多模态预训练数据集M6-Corpus 对1 百万幅电子商务领域图像数据抽样进行对象检测后发现90% 图像所含物体少于5 类,且高度重叠,因此,对图像进行切块并利用ResNet 提取特征,将各patch 特征按位置线性组合成表示序列,与文本特征组合后送入Transformer 进行文本—文本传输(text-to-text transfer)、图像—文本传输(image-to-text transfer)、多模态—文本传输(multimodality-to-text transfer) 预训练任务。M6 使用大规模分布式方法进行训练,大幅度提升了模型的训练速度,适用于广泛任务。
双流模型
由于图像和文本信息在属性上区别较大,将不同模态输入置于相同输入地位可能对模态间匹配造成不良影响。在这一假设下,部分模型根据多模态输入特点设计双流预训练模型,使用不同编码器灵活处理各自模态特征,并通过后期融合对不同模态进行关联。
eg1 ViLBERT

Lu 等人(2019)认为对语言信息需采取较深网络才能获取抽象知识,而图像经Faster-RCNN 处理已经过较深网络,无需再次经历更深编码过程,于是提出典型双流式结构模型ViLBERT(vision and languageBERT),模型结构如图6 所示,上下两路分别独立处理视觉和文本输入,视觉输入采用Faster-RCNN 处理,文本输入采用类BERT 处理,在编码之后经协同注意(co-attention)Transformer 进行特征跨模态融合,然后进行MLM 和ITM 训练。
ViLBERT的核心为跨模态融合模块co-attention Transformer结构,如图7 所示,对于视觉和语言输入,将各自的键K 和值V 输入另一模态,而对查询Q 输入自身模态,使得图像区域作为上下文信息给文本信息进行加权,反之亦然。

在进一步研究中,对ViLBERT 预训练过程中视觉信息泄漏和负样本噪声问题进行优化,并将单个模型用于12 个视觉语言任务提出了12-in-1(Lu 等,2020)。研究提出多任务学习预训练方法,训练时融入动态训练调度器(dynamic stop-and-go trainingscheduler)、基于任务的输入标记(task dependent input tokens)和简单启发式超参(simple hyper-parameterheuristics)。实验结果表明多任务学习是一种有效的预训练任务,可避免因数据集规模造成的训练过度或训练不足的问题。
eg2 LXMERT(learning cross-modality encoder representations from transformers)
Tan 和Bansal(2019)认为视觉概念和语言语义间的关系对推理问题很重要,所以在图像编码时引入对象关系编码器
eg3 ERNIE-ViL(knowledge enhanced vision-language representations)
Yu 等人(2021)在文本编码时,将语言转化为结构化的场景图,使模型能更精准把握图
文间细粒度的对齐信息,提出了知识增强型模型,设计了场景图预测(scene graph prediction,SGP) 预训练任务,含对象、属性和关系预测,通过对场景图中图像和文本信息进行掩蔽,以预测场景图中的节点属性和关系,学习细粒度的跨模态语义对齐信息。
eg4 TDEN (two-stream decoupled encoder-decodernetwork)
Li 等人(2021c)使用独立的解耦编码器和解码器分别处理不同VLP 任务,利用不同模式VLP 任务间相关性来增强下游任务的鲁棒性
eg5 ALIGN(a large-scale image and noisy-text)
COCO 等高质量预训练数据集收集后需进行烦杂的清理过程,针对这一点,Jia 等人(2021)搜集了一个18 亿数据量的含噪数据集,并提出了ALIGN(a large-scale image and noisy-text)方法,使用对比损失对齐图文对的视觉和语言表示。方法在大量下游任务上表现优秀,表明语料库的规模可弥补其噪音,提升模型性能。
eg6 CLIP(contrastive language-imagepre-training)
同一时期,Radford 等人(2021)利用互联网上大规模的图片信息构建了一个4 亿大小的图文对数据集,将自然语言作为监督以提升图像分类效果,使用对比学习方法促进图像和文本的匹配能力,提出了CLIP(contrastive language-imagepre-training)。对于视觉编码分别尝试了ResNet 和ViT,根据具体任务表现进行取舍。与有标签监督学习对比有着较强的泛化能力。
eg7 BriVL(bridging vision and language)
大部分图文预训练模型都假设图像与文本模态间存在强相关关系,Huo 等人(2021)认为这种假设在现实场景中难以存在,因此基于图文对弱相关假设选择隐式建模,提出大型图像—文本预训练模型BriVL(bridging vision and language)。方法使用多模态对比学习框架进行训练,构建队列字典以增加负样本数量。此外还提出一个大型中文多源图像文本数据集RUC-CAS-WenLan,含3 000 万图文对。实验表明在参数量足够大时双流模型较单流模型具有一定优势。
其它
eg1 DeVLBert(deconfounded visio-linguisticBert)
预训练数据集与下游数据集存在域偏移,而现有方法是纯概率角度出发的,这会导致一定程度的虚假关联。Zhang 等人(2020a)提出一个基于因果的去混淆模型DeVLBert(deconfounded visio-linguisticBert),将后门调整方法融入预训练模型。实验证明,DeVLBert 作为整体模型的灵活部分组件,对广泛的单流、双流预训模型具有很好的适用性。
eg2 CPT

预训练任务和下游任务的训练模式也相差较大,针对这一问题,Yao 等人(2022)提出颜色提示优化模型CPT(colorful prompt tuning),利用颜色促进方法作为两种训练模式之间的桥梁,缩小预训练任务与下游任务之间的差异性。模型结构如图8 所示,方法在视觉检测过程中对视觉目标区域添加不同颜色,并通过颜色信息作为图像和文本的共同标记信息,通过对颜色信息进行MLM 任务,将图文关联转换为完形填空问题,加强了图文联系,从而对下游的图像目标定位问题起到了促进作用。
eg3 LayoutLM
生活中存在大量文档图像处理任务,如表格理解、文档图像分类、收据理解和表单理解。为此,Xu等人(2020) 提出LayoutLM(pre-training of text andlayout),重视文档图像的布局和样式信息理解,对扫描的文档利用光学字符识别(optical character recognition,OCR)处理,将识别得到的文字片段和对照的图像进行联合建模,首次将文本和布局结合在一个框架中进行文档级预训练,使用了MLM 和多标签文档分类预训练任务。在进一步研究中,引入ITM 任务,并在传统自注意力机制基础上显式添加空间相对位置信息,帮助模型在1 维文本序列基础上加深对2 维版面信息的理解,提出了LayoutLMv2(Xu 等,2021b)。
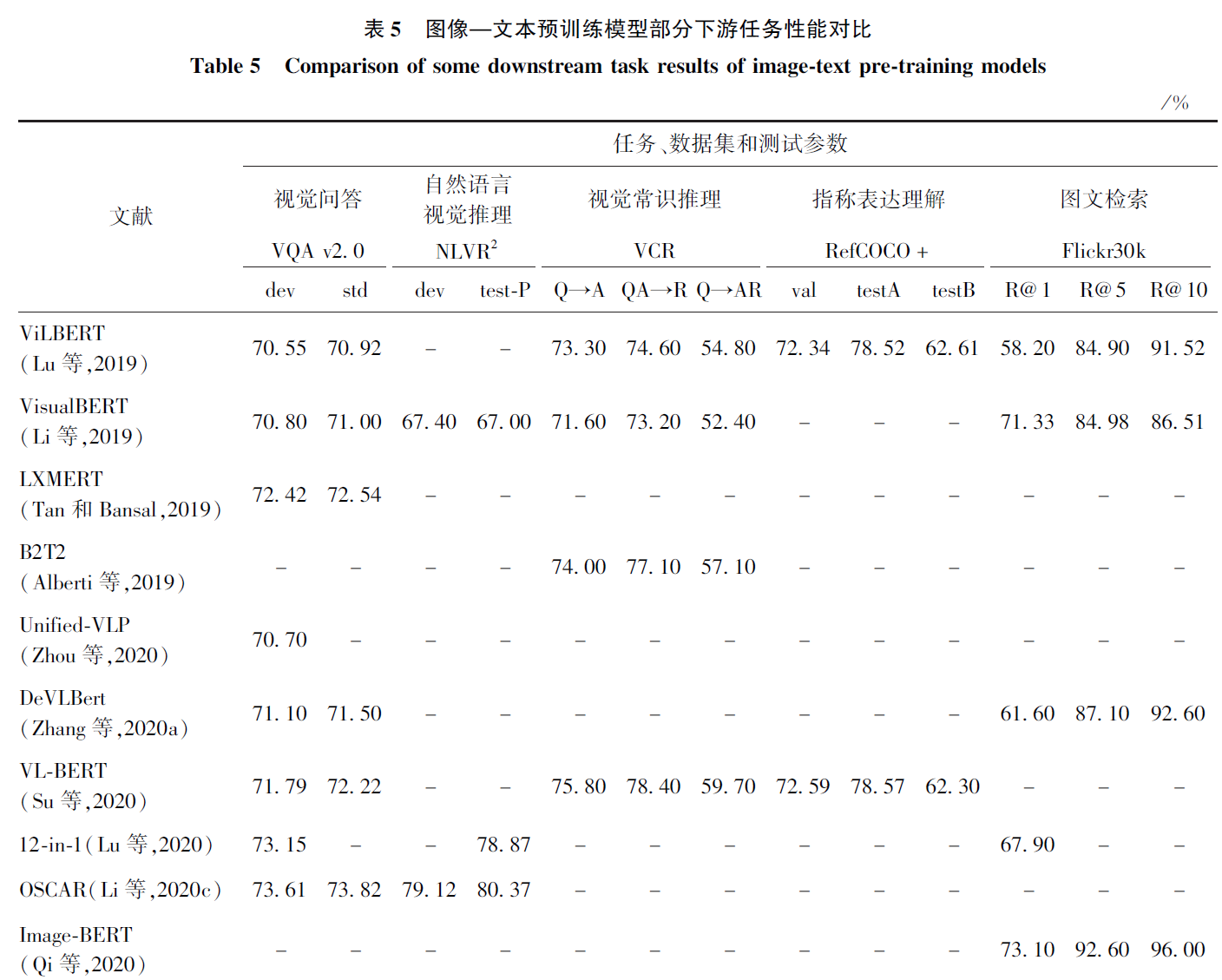
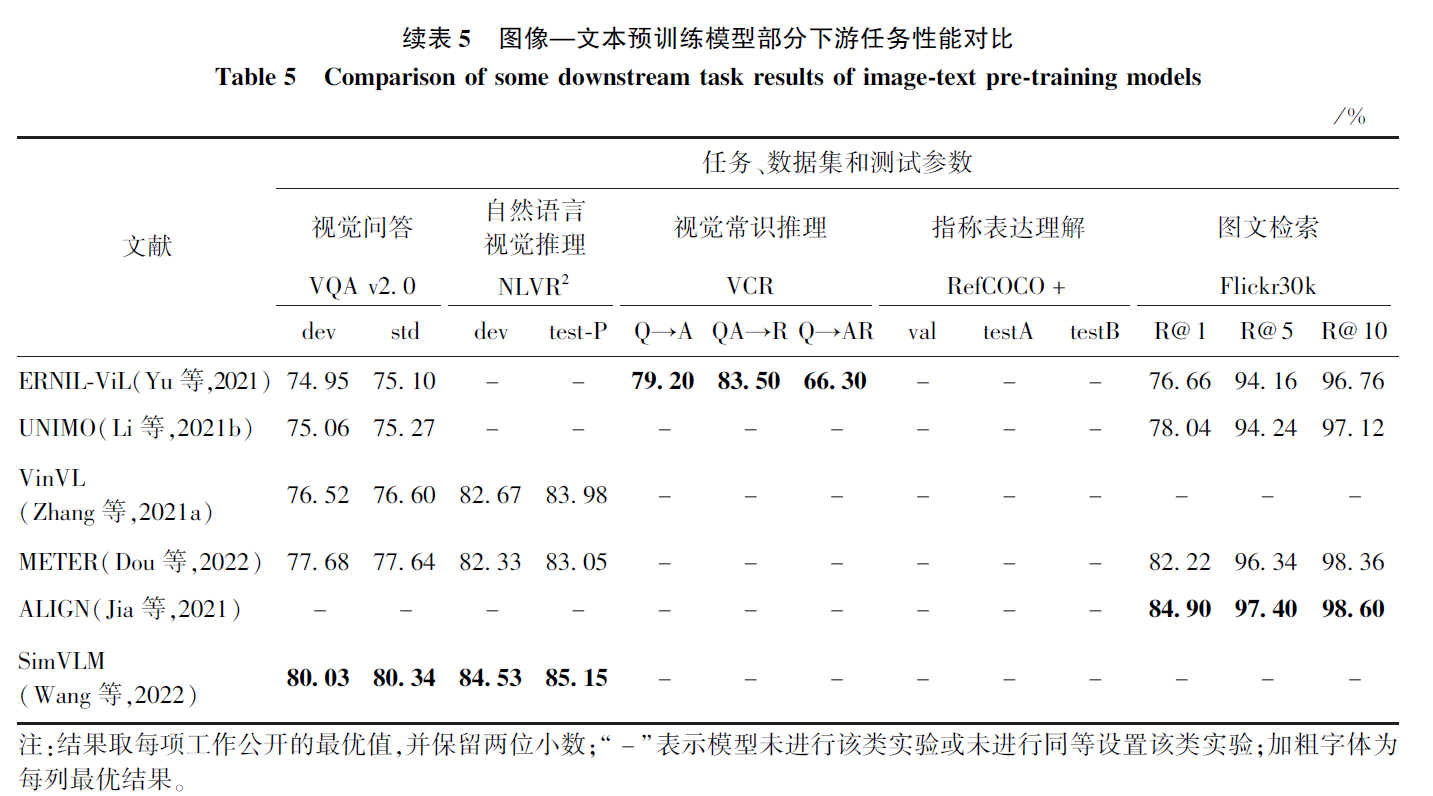
下游任务性能对比

问题与挑战
1)训练数据域的差异
预训练数据集与下游
任务数据集之间存在数据域的差异. MERLOT(Zellers 等,2021)使用较为多样的预训练数据,增大了数据域的分布,在一定程度上提升了模型的性能,但也增加了训练消耗。因此,如何提升预训练数据集的质量和多样性是今后预训练任务的重要课题。
2)知识驱动的预训练模型
对于输入的图文、视频等多模态信息,存在着大量隐含的外部常识信息可以用于更快速地引导模型对于事件内容的挖掘(Chen 等,2021),将知识图谱等结构化知识注入模型,探索轻量化的网络结构,从而增加模型的训练效率和可解释性,是预训练模型的具有前景的方向。
3)预训练模型的评价指标
4)探索多样的数据来源。
包含音频的预训练模型是一个可取的方向。
将模型在不同语言间进行迁移还需要继续研究。
从结构化的多模态数据中进行更细粒度的预训练工作,如从图表中进行目标推理的训练也是可以探索的方向。
5)预训练模型的社会偏见和安全性