
论文:ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
代码:https://github.com/dandelin/vilt
出处:ICML 2021 Long Presentation
本文的标题就是使用 transformer 来做多模态的任务,而且没有用卷积监督信号和区域监督信号,这里的卷积监督信号就是指的是预训练的 backbone,区域信号就是用检测头检测出来的那些框所在的区域。
视觉文本的预训练 VLP 方法,为了下游任务上获得好的效果,往往在视觉特征上花费的代价很多,很依赖于视觉特征抽取的效果,看做目标检测的问题或者使用 Resnet 抽取特征,也就是需要额外的视觉网络抽取特征,花费很贵
这样的操作有两个问题:
- 很低效,需要花费大量的时间来进行视觉特征抽取,甚至比后面做的多模态融合花费的时间还多,但可以直观想象如果说多模态任务只是把两个单模态模型效果做的很好的话,那么多模态就没有研究的意义了,所以多模态的研究重点应该在如何让两种模态融合的更好
- 如何使用预训练好的模型来抽特征的话,那么抽到的特征其实很受限的,假设使用预训练好的目标检测器来抽特征,我们都知道目标检测数据集都不大,类别只有几百类,框也只有几十万,规模还不是很大,很难涵盖到边边角角,所以如果模型不是端到端学习的话,那么大概率这个模型不是最优的
ViLT 的贡献:
- 提出了极简化的 VLP 的模型,迄今为止最简单的 VLP 模型,受到 vision transformer 的启发,将图像的预处理做的和文本预处理的方法一样了,都是 Linear embedding,显著减少了计算复杂度和计算时间
- 在降低计算量的情况下,性能也比较能打
- 还使用了更多更适合于图文对儿的数据增强,因为多模态其实不太好做数据增强,因为有可能一不小心就匹配不上了,比如草地上有一只白色兔子,图像做数据增强后可能会改变颜色,兔子就不是白色的了,新的图像文本对就不正确了,所以之前的工作就没有使用很多数据增强的方式,ViLT 却很好的使用了数据增强且提升了效果
训练难度:
- 使用 64 个 32G 的 V100 训练 3 天,代价较大
后面其他大佬的延续工作:
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Masked Unsupervised Self-training for Zero-shot Image Classification
一、背景
本文提出的背景的就是在于多模态领域现在也开始研究先预训练再微调的方式,这种方式在 NLP 和视觉领域都是这样做的,所以就拓展到了多模态领域
所以预训练就很重要,zero-shot 也是很被看重的
从 2019 年到 2021 年出现了很多篇有影响力的工作,比如 2019 年就出现了 visualBERT、ViLBERT 等以 BERT 命名的方法
一般这些模型都使用图像文本对来训练的,一般都是使用了 image text matching 和 masked language modeling 的目标函数,一旦预训练完成,就可以在下游任务上微调实现
具体怎么处理文本和图像呢:
- 文本:transformer 统一了文本的江湖
- 图像:要做多模态,图像的特征一定要变成语义性强的离散信号的形式,才能使用 transformer 这种结构来进行多模态的训练,但又不能变成像素的离散程度(那样序列就太长了,transformer 处理不了)。比如 ViT 将图像分成 patch 来做,但 ViT 是 2021 年出来的工作,那在 2021 年之前基本上就是使用目标检测器,因为目标检测模型就是将图像转换成了离散的 bbox 的形式,而且还有很明确的语义信息,每个区域呢就可以想象成句子中的单词。也和下游任务有关系,往往都和物体有非常强的关系。如 VQA、visual grounding 等任务,所以选择目标检测模型作为 VLP 的一部分是合理的
当前的 VLP 方法大都是使用预训练好的目标检测器,检测器一般都是在 VG 数据集训练的,有 1600 物体类别,400 个属性类别,类别是相对比较大的,限制性会更小一些。
截止目前的工作还是聚焦在如何提高视觉编码器的效果来提升最后的多模态的效果,因为在学术界中更看重的还是效果,而不是性能。而且在训练的时候,可以提前把目标检测特征抽好,存在本地硬盘,用的时候直接用就好,所以那 800ms 的特征抽取过程是不会耗费训练的时间的,也没人太把这个事情当回事。
但如果说要做现实世界中的应用,对于新数据还是需要抽取特征的,那么那个时候就没法提前抽取好特征了,所以问题还是很严重的。
所以 ViLT 想要构建一个很方便的视觉特征抽取的过程,ViLT 受启发与 ViT,也算是 ViT 在多模态领域的扩展。
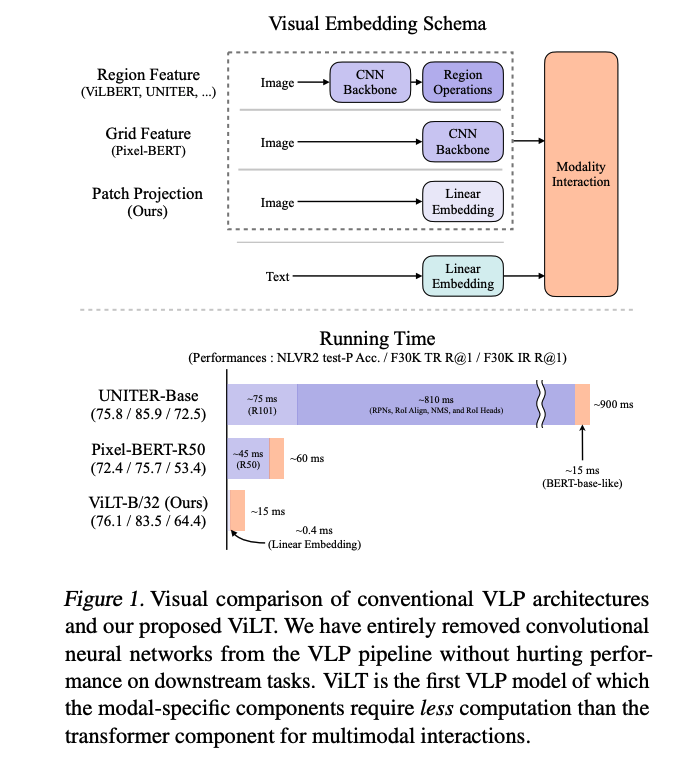
如下图 1 所示,一般利用 region feature 的工作都是先对图像使用 CNN 提取特征,然后使用检测头输出目标检测框,这个过程中,抽取特征耗费约 75ms,RPN/RoI Align/NMS/RoI heads 这些过程耗费约 810ms,所以 Pixel-BERT 就提出将后处理过程去掉,就是把图片进行特征提取,把最后的多通道特征拉直变成序列向量来使用,而不用提取出最后的框信息,能够降低时间到 45ms(R50),但性能下降了十几个点。
ViLT 把 CNN 换成了 Linear embedding 层,图像和文本都是使用 linear embedding 层,非常的快速,图像的只需要 0.4ms。而且效果没有降低很多。
作者根据下面两点将当前 VLP 模型分成了四大类,并且总结了不同类别方法的特点:
- 图像和文本的表达力度是不是平衡,如参数量和计算,因为图像和文本都是非常重要的,比重应该差不多,不应该是现在这种视觉比文本贵太多的情况
- 图像和文本两个模态的信息是怎么融合的
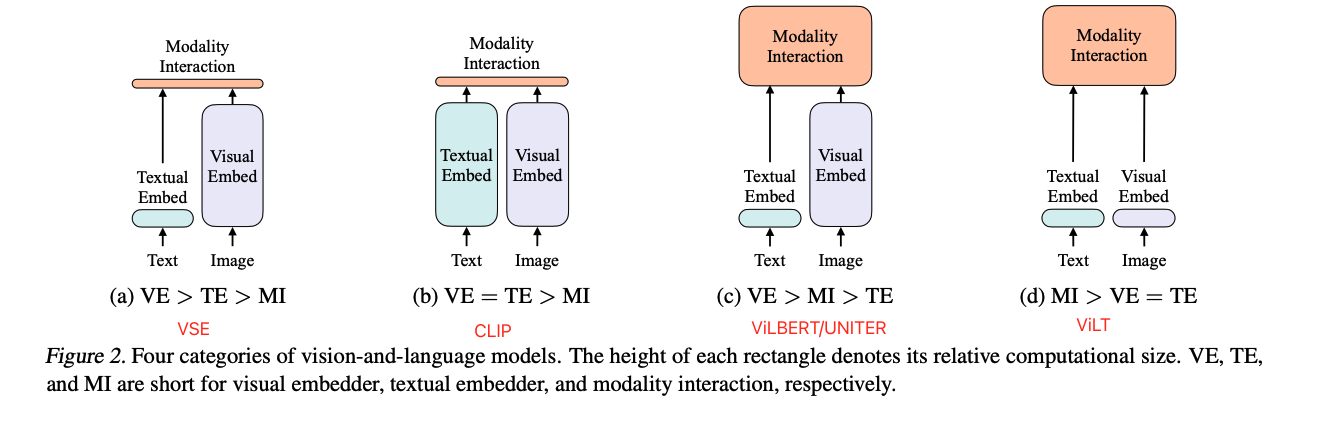
四大类如图 2 所示:
- a:文本端很轻量,视觉端很重,融合部分更轻量
- b:文本和图像的表达力度是一样的,计算量基本是等价的,但模型融合部分很轻量,做模态融合的时候就是点乘就结束了,所以 CLIP 比较适合做抽特征、retrivel 的任务,但做 VQA 或 visual reasoning 任务的效果就不太好了,毕竟只是抽到了特征,没有更深层次的理解
- c:文本端很轻量,视觉端使用目标检测的网络很重,融合部分也很贵,融合部分也是用 transformer 来实现的,性能也不错,所以作者就发现了,好好做模态融合才能主导多模态的效果更好
- d:前面的工作证明了要有好的模型融合模块,多模态效果才能更好,所以 ViLT 就致力于将文本和图像的特征提取部分做的轻量,着重在模态融合模块上来做文章
模态融合很重要,所以要看看当前的模态融合是怎么做的:
- single-stream:把两个序列 concat 成一个序列,然后让 transformer 自己去学习怎么融合
- dual-stream:先各自对各自的输入做处理,挖掘单独模态中包含的信息,然后再融合
- 两种融合方法基本效果差不多,dual-stream 有时候会更好一点,但 dual-stream 引入了更多的参数,ViLT 作者还是使用了 single-stream 更轻量的方法
多模态融合之前,特征怎么提取:
- 文本端:使用预训练好的 BERT
- 视觉端:
- 之前的方法是先将输入图像通过 backbone 来提取特征,然后使用 RPN 网络来抽取一些 ROI,做一次 NMS 降低区域的数量,然后经过 head 得到 bbox,整个过程非常贵
- 还有一些方法使用 Grid Feature,就是直接用抽出的特征,拉平后直接用,但效果不好
- 所以 ViLT 借鉴 ViT 的 patch embedding layer 来抽取特征,又快又好
二、ViLT 方法
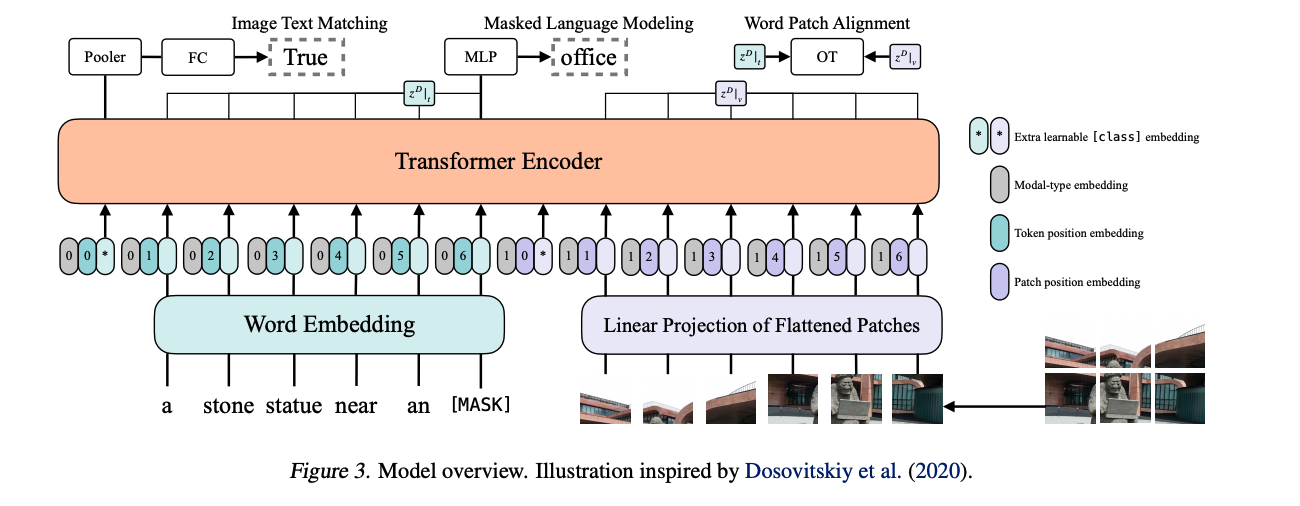
ViLT 是一个 single-stream 的结构,所以只有一个 模型:
- 文本输入:文本先输入 BERT tokenizer,得到 word embedding,假设文本的长度是 L,H 就是 embedding 维度,一般 base 模型就是 768,就是 Lx H 大小
- 图像输入:把图像打成 patch,每个 patch 进行 patch embedding,得到一系列的 token 编码(紫色),假设图像 token 长度为 N 维度也是 H 那么就 NxH 的特征
- *:cls token,绿色的是文本的,紫色的是图像的
- 灰色:表示模态,0 表示文本模态,1 表示图像模态,需要 modal-type embedding 的原因在于,对于 single stream 的方法来说,是会把图像和文本的输入拼接在一起的,如果不告诉模型哪些是文本或哪些是图像的话,是不利于学习的,如果告诉了后,模型就可能互相学习文本和图像之间的关系,更有利于找到潜在的关系
- 输入输出序列长度:每个 token embedding 输入 transformer encoder 之前呢,都是由三部分组成的:灰色+绿色+淡绿色的,是加到一起的,而不是 concat,然后所有相加后的特征会被 concat 起来,送入 transformer encoder,所以输入长度就是 1+L+1+N,整个输入的特征就是(N+L+2)xH,输出的序列也是(N+L+2)xH
预训练的两个 Loss:
- Image-text matching loss:
- 该 loss 是用于衡量文本和图像之间的距离,是人为设计的任务,也就是二分类的任务,判断匹配与否,真正有用的位置是 Pooler 位置,在 Pooler 之前呢,这个位置输出的特征是 1xH,经过 Pooler 相当于权重矩阵,得到 HxH,经过 FC 得到 1xH 的输出,做二分类。
- ViLT 中还使用了 word patch alignment loss,使用最优传输理论来计算分布之间的距离
- Masked language modeling loss:
- 针对文本的目标函数,也就是 NLP 那边常见的完形填空,也就是在输入文本的时候,随机 MASK 掉一个单词,然后在输出的时候重建出来这个 mask
文本模型中使用的小技巧:whole word masking:
- 作者使用将整个单词都 mask 掉的方法,能进一步的加强文本和图像之间的关系的学习
- 当把单词抹掉之后,句子重建就很困难,那就只能从图像中来拿取信息,所以就能迫使模型来建立图像和文本的关系
图像模型中使用的小技巧:
- 前面说过数据增强在图像中很有用,但多模态中不太能用好数据增强
- 本文作者做了改动,也就是不用 color 和 cutout,就能尽可能的保证图像和文本保持原有的匹配关系
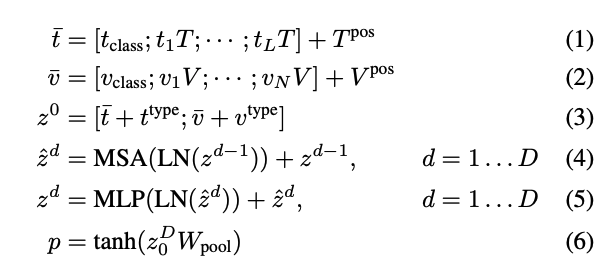
三、效果
ViLT 能做到最好的速度和效果的平衡!!!
3.1 数据集
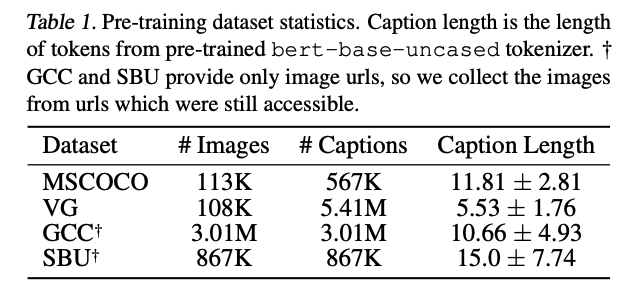
预训练所用的数据集设置:4 个数据集,一般大家把这几个数据集合起来叫做 4Million 数据集(4M),因为数据集中图片个数加起来大概是 400w 多一点
- MSCOCO:每个图片对应 5 个 caption,虽然只有 10w 个图片,但有 50w 个 caption,且标题也较长,能下载完整数据集
- VG:10w 图片,对应 caption 有 500w,caption 长度不长,能下载完整数据集
- GCC:一个图片对应一个 caption,且 caption 长度较长,一些数据链接失效了,不完整
- SBU:一个图片对应一个 caption,且 caption 长度较长,一些数据链接失效了,不完整
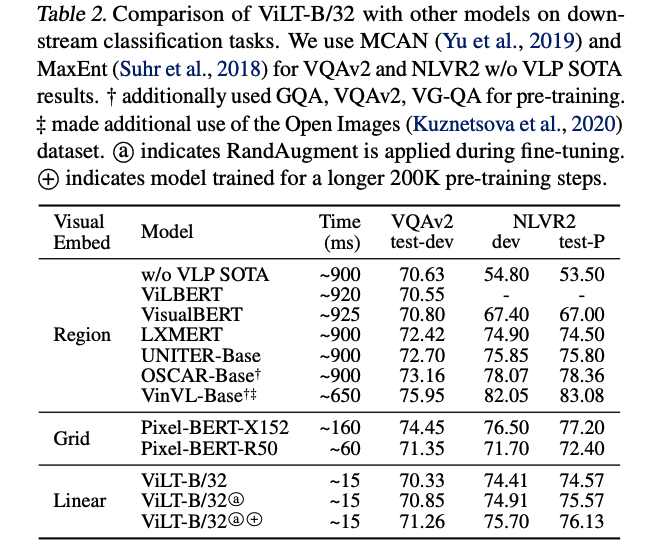
3.2 分类任务 VQA 和 NLVR2
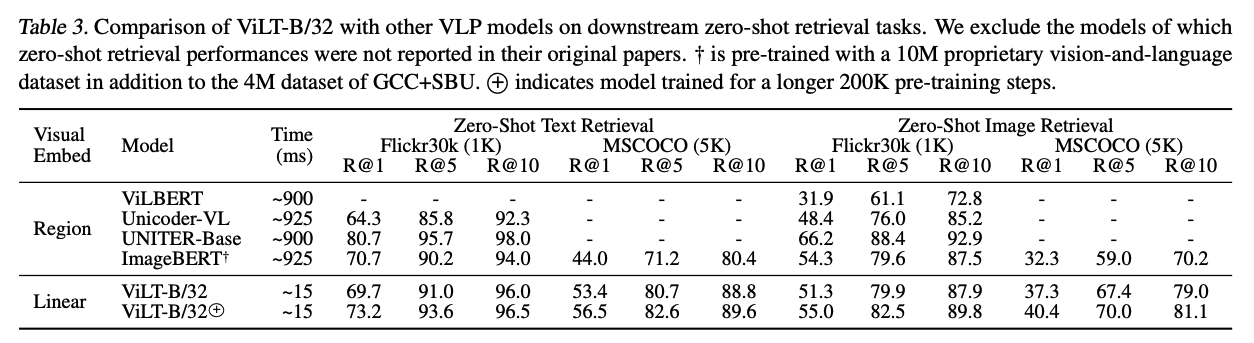
3.3 Image Retrieval
zero-shot:
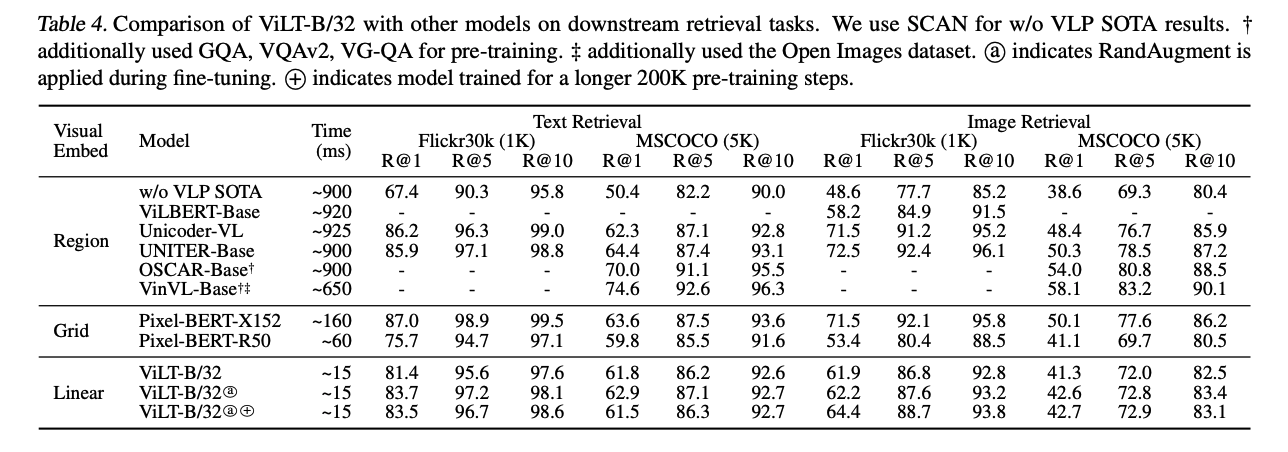
finetune:训练好模型后做 fine-tuning
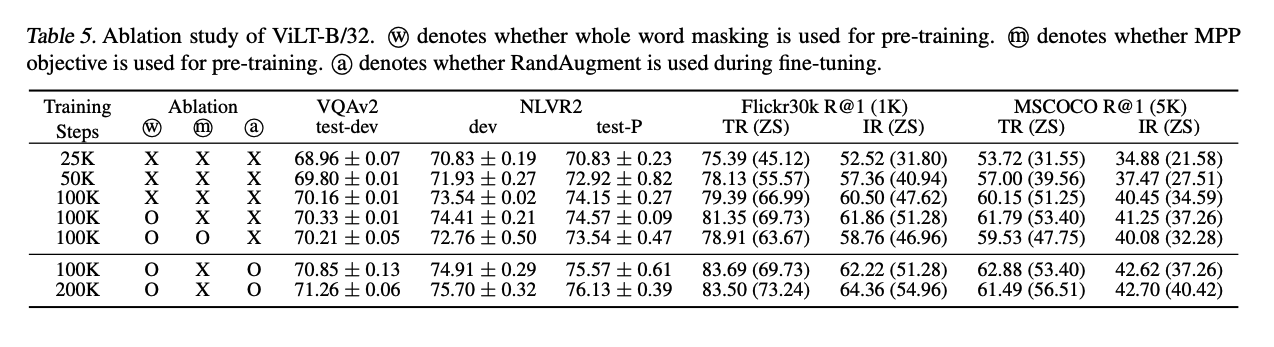
消融实验:
可视化:
