论文名称:multimodal machine learning: a survey and taxonomy
论文地址:
TPAMI 版本:Multimodal Machine Learning: A Survey and Taxonomy | IEEE Journals & Magazine | IEEE Xplore
arxiv 版本:https://arxiv.org/abs/1705.09406?context=cs
本文发表与2019年的TPAMI,arxiv 技术报告公开与 2017 年。建议下载TPAMI 版本,arxiv 版本有一些小错误,比如 Figure3 中关于 hybird 的 co-learning 就与non-parallel 重复了。
综述了当时多模机器学习的进展,并进行总结归类了多模学习的五个任务阶段和挑战。本博客摘录部分信息。
一、多模机器学习的应用场景:
1. 语音识别与合成:
a. 利用口型矫正识别
b. 根据口型合成语音
2. 事件检测:
a. 多媒体行为分类
b. 多媒体时间检测
3. 情感、情绪识别与合成:通过表情等进行抑郁和交流评估
4. 媒体描述:
a. 图像描述
b. 视频描述
c. VQA
d. 媒体内容概要
5. 多媒体检索
a. 跨媒体检索
b 跨媒体哈希
二、多模学习任务分类
1. 表示(representation):将不同模态的数据转化为特征,缓解异构(异质heterogeneity)问题
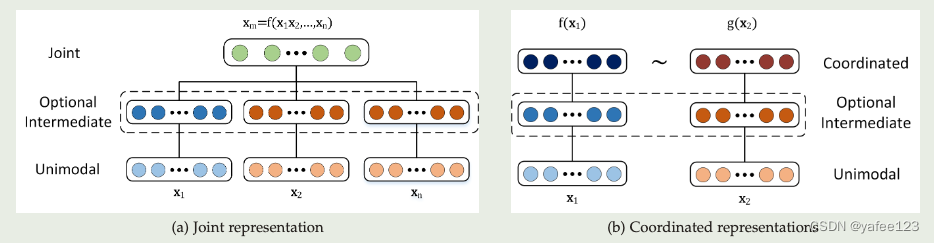
- 联合表示(joint representation)
- 协同表示(coordinated representation)
2. 翻译(translation):给定一种模态的实例,生成另外一种模态中相关的实例。比如image-caption、图像描述、文字生成图像、语音合成等。
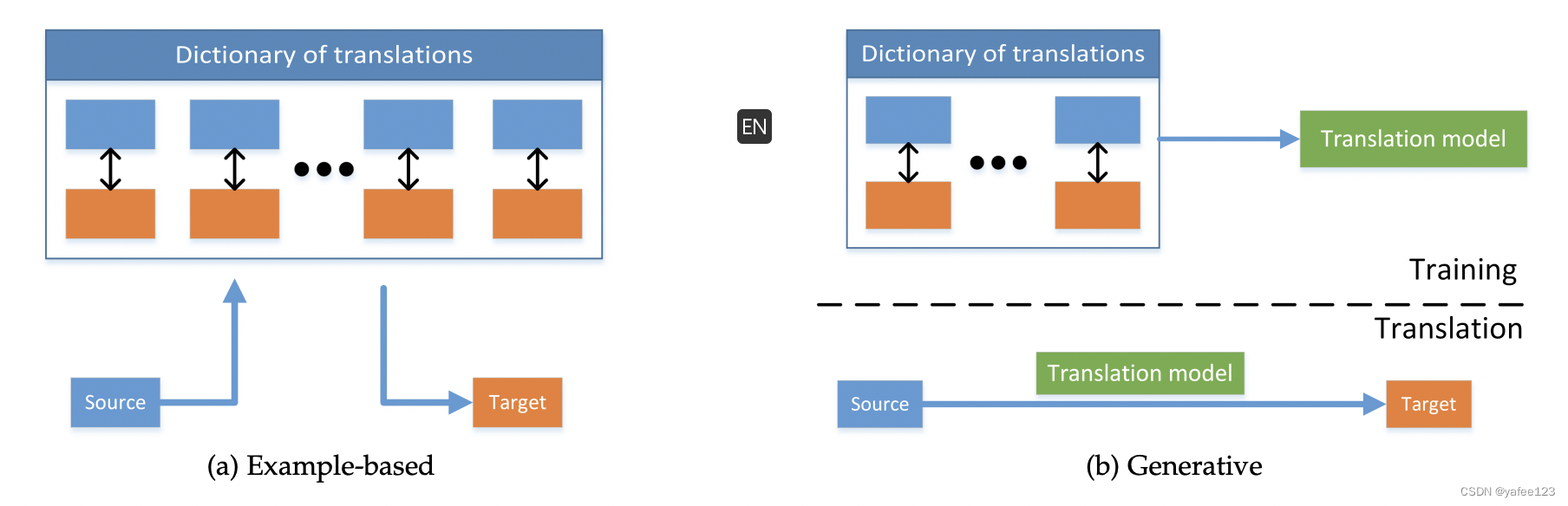
- 基于样例的翻译(example-based):
- 基于生成模型的翻译(generative):
3. 对齐(alignment):在多模态数据中找到具有对应关系的子结构。比如给定一张图片和一个描述,找到描述中的文字与图片中内容的对应关系;给定电影与剧本,找到电影情节与剧本章节的对应关系。
1. 显式对齐:多模态内容中的直接对应关系,比如在烹饪视频中直接找到做菜指引中的步骤。从方法上有无监督和有监督等流派。
2. 隐式对齐:对齐关系是跨模态任务的中间步骤,比如利用文本进行图像检索任务中,单词和图像区域的对齐是其中一个步骤。从方法上有图模型、神经网络等流派。
4. 融合(fusion):多模态信息融合后进行统一的任务(分类、回归),如多模医学影像分析、多模信息情感识别、利用口型与语音信息进行语音识别等。
1. 与模型无关的流派:不依赖与具体模型,可分为 特征融合(前)、决策融合(后)和混合融合
2. 基于模型的流派:利用统一模型进行多模融合,有multiple kernel learning,图模型、神经网络等方案。
5. 联合学习(co-learning):利用一种模态上学习到的能力(数据量多)去辅助另外一种模态的任务(数据量少)。和小样本学习、Zero-shot learning 、迁移学习相关。

1. 并行数据:两种模态的数据直接对应,比如视频中的画面和语音
2. 非并行数据:两种模态数据不能直接对应,但不同模态数据都能对应到一个统一的概念集。比如糖尿病视网膜病变和血糖测试没有直接的对应关系,但是都能进行糖尿病判别,那么就可以通过糖尿病判别这个概念,建立糖网和血糖之间的关系
3. 混合模式:两种非并行数据,可以通过其他一种模态数据或者其他的数据集作为过渡,从而建立联系。比如在多语言 image captioning 任务中,多种语言描述同一张图像,那么可以以图像为桥梁建立不同语言单词之间的对应关系。