本系列文章是笔者以邱锡鹏老师《Pre-trained Models for Natural Language Processing: A Survey》为主要参考材料所做的关于“预训练语言模型综述”的记录,所涉及之素材也包括其他相关综述与未被纳入此综述的工作,分享出来与大家交流讨论。此篇为系列第二篇,记录预训练任务及训练策略。
第一、三篇跳转可阅:
预训练语言模型综述(一)—— 预训练语言模型及其历史
预训练语言模型综述(三)—— 预训练语言模型的实际使用
预训练任务
预训练任务按学习范式可归类成监督学习、无监督学习和自监督学习三类任务。自监督学习略微特殊,它也有输入和输出标签,所以训练方法其实和监督学习一致,但是它的标签是自动生成而非人工标注的,最典型的就是Masked Language Model(MLM)任务了(监督学习这里特指标签由人工标注的情况)。受限于训练语料的丰富程度,目前基于监督学习的预训练任务仅有机器翻译(Machine Translation),其他主流预训练任务都是无监督或自监督的。随着时间的推移,也有可能发展出其他更为细化的、基于监督学习的预训练任务。总的来说,目前预训练任务的具体分类可参考下表:
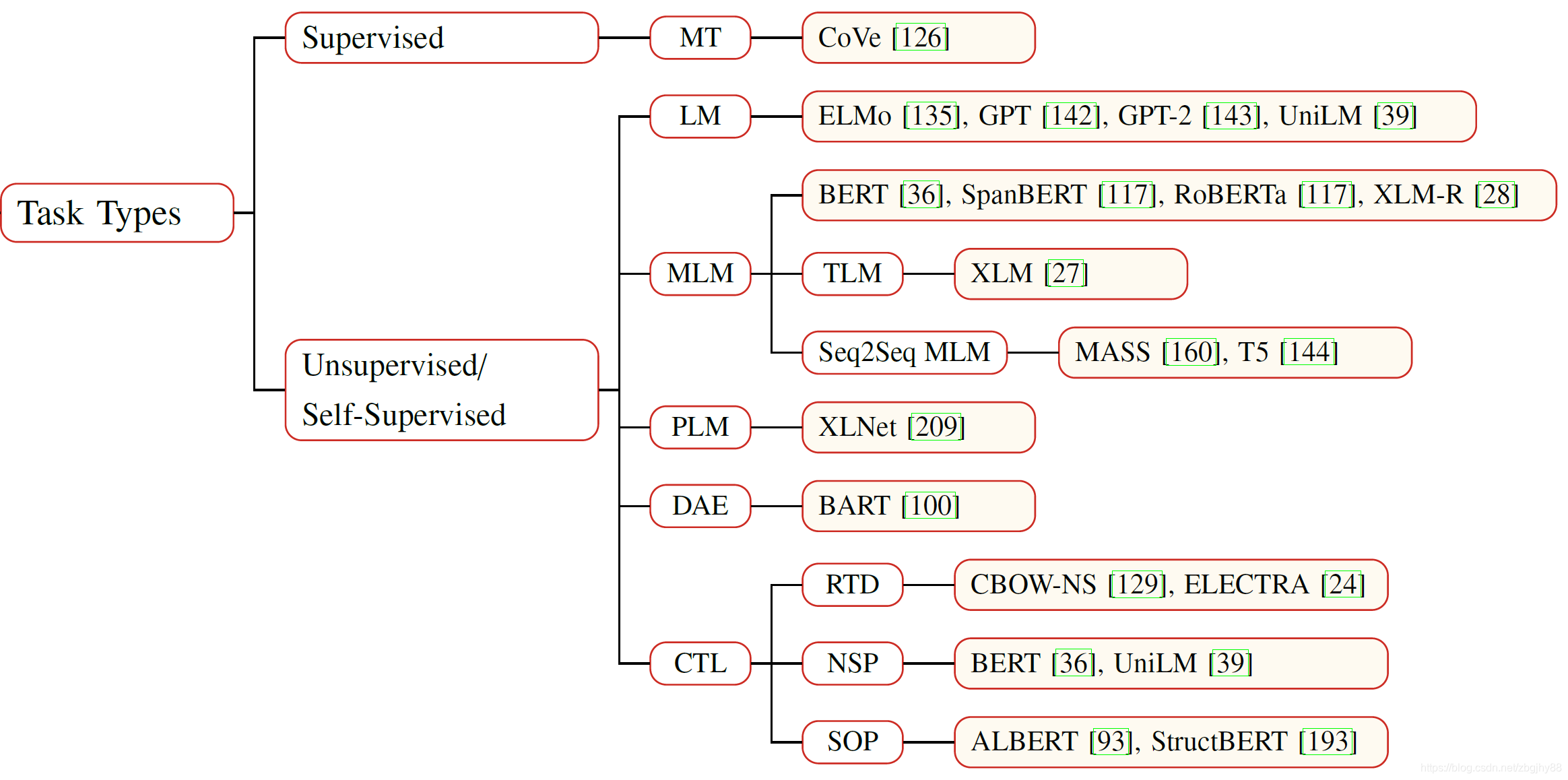
1. Language Modeling
Language Modeling/Probabilistic Language Modeling(LM) 是经典概率密度估计问题,属无监督学习问题,可以通过MLE来估计。
通常特指自回归语言模型或单向语言模型,因此存在只编码了从左到右的上下文信息的缺点;改进版本是BiLM,即同时编码从左到右的上下文信息和从右到左的上下文信息。
2. Masked Language Modeling
掩码语言建模(Masked Language Modeling)归类为自监督学习问题,并通常作为分类问题来处理。
BERT的MLM是遮挡一个词,然后用含遮挡词标记的整个输入序列来预测被遮挡的词;同时由于fine-tuning时并没有mask token,BERT采取的办法是在数据预处理时选择句子15%的词作为目标掩码词(这些词将不再改变,称之为静态masking),并让数据生成器80%的时间内用[Mask]替代目标遮挡词、10%时间用随机词替代目标遮挡词、10%时间用目标遮挡词替代目标遮挡词。
从Mask Token(s)的角度来看,不同于BERT只mask一个词,Seq2Seq MLM用到Seq2Seq模型,被遮挡了多个连续的词的输入序列由Encoder进行编码,再由Decoder解码被遮挡词序列;SpanBERT也是遮挡多个连续词,同时还引入了用边界预测Mask Tokens的损失。
从执行Masking的角度,不同于BERT的静态masking,RoBERTa采用动态masking,它没有在预处理的时候执行 masking,而是在把序列输入模型时动态生成 mask,并且遮挡词不是固定的,有利于模型学习各种掩码策略下语料表现出来的特征。
还有一类更为综合的MLM,是将知识融入到掩码策略中,典型代表就是百度的ERNIE了。百度的ERNIE在掩码时额外使用了短语级别和实体级别的掩码,藉此向语言模型中引入了知识。
3. Permuted Language Modeling
置换语言建模(Permuted Language Modeling)的开山之作XLNet指出,掩码语言建模中使用的一些特殊符号,尤其是[MASK],在下游任务中时不存在的,因此在预训练过程和微调过程中就存在一定的gap。所以,XLNet的作者就提出使用置换来替代掩码,即使用置换词而不使用掩码[MASK]。
4. Denoising Autoencoder (DAE)
上述MLM、PLM都属于基于Denoising Autoencoder来进行预训练的方式,即对一个输入进行一定干扰,然后让模型来恢复未受干扰的原始输入。此外还有文本填充(多个Token被同时替换,任务的目标是预测被替换Token的数量)、句子置换(置换文本中句子的顺序)等可用于干扰输入的方法。
5. Contrastive Learning (CTL)
不同于上述几种预训练任务(都是自编码形式),对比学习提供了一种全新的无监督预训练方式,将来也很有希望成为NLP中另一种大行其道的训练方式。对比学习的核心是通过对比进行训练。例如,对比合法的句子与不合法的句子之间的相似度,从而调整训练。邱老师的综述中列举了替换词检测(RTD)、下一句预测(NSP)等使用了对比学习的工作。
训练策略
语料的使用
预训练语言模型离不开对大规模语料的使用。我们可以将语料大致可以分为三类:通用语料、特定领域语料、下游任务直接相关的语料。一般预训练中所用是大规模通用语料与特定领域语料。ULMFiT提出了三阶段训练,其中预训练包含两个阶段,第一阶段使用大规模通用语料进行语言模型预训练,使其学习语言的通用规律;第二阶段使用大规模特定领域语料,得到适合于特定领域的预训练模型,最后再在具体任务上进行微调。此外,从语言种类的角度,多语言预训练语言模型的训练中也存在语料使用的问题。multilingual BERT使用共享词汇表来解决多语言语料的使用问题, XLM则是在此基础上进一步引入了翻译语言建模(translation language modeling),以提升多语言预训练语言模型的效果。
预训练任务的选择
我们在上一部分介绍了各种预训练任务,这些预训练任务都有这各自的特点和优势,在选择应当遵循一些基本的原则。从效率角度考虑,与其他任务相比,对比学习具有更小的计算复杂度,在资源受限时可做优先考虑。从效果角度考虑,需要考虑预训练任务对下游任务的影响,毕竟这才是最终目的。例如:NSP可以使预训练语言模型理解两句话之间的关系,因此针对问答、自然语言推理等下游任务,可以考虑NSP作为预训练任务训练预训练语言模型。