文章目录
论文: RegionCLIP: Region-based Language-Image Pretraining
代码:https://github.com/microsoft/RegionCLIP
出处:CVPR2022 Oral | 微软 | 张鹏川
一、背景
近期,视觉-语言模型取得了很大的突破,如 CLIP 和 ALIGN,这些模型使用了极大的图文对儿来学习图像和文本的匹配,并且在很多无手工标签的情况下也取得了很好的效果。
为了探索这种思路能否在 region-caption 的情况下起作用,作者基于预训练好的 CLIP 模型构建了一个 R-CNN 形式的目标检测器。
主要思路:
- 先从输入图像中抠出候选区域
- 然后使用 CLIP 模型将抠出的区域和 text embedding 进行匹配

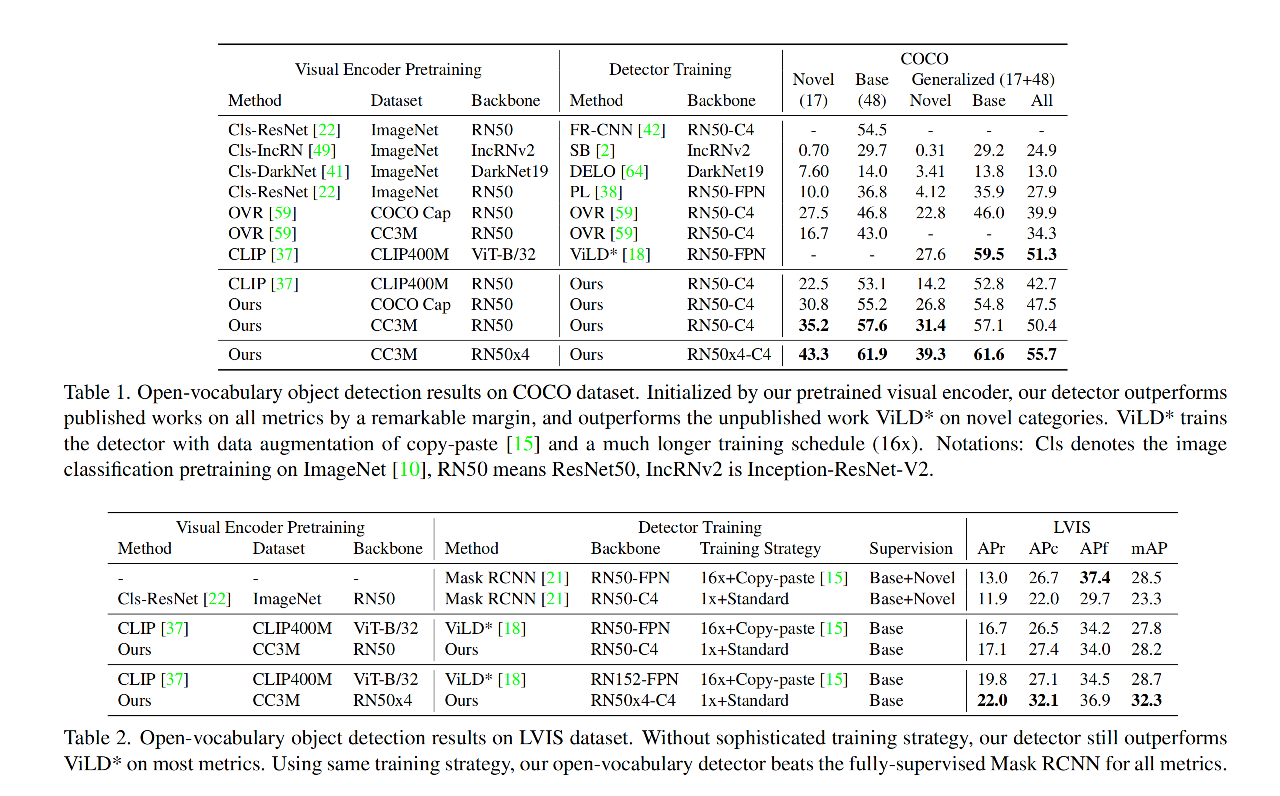
- 图 1 a-b 展示了在 LVIS 上的结果,当使用 proposal 作为输入时,CLIP 的得分无法代码定位的质量,可以看出不准的框得分为 65%,较准的框得分为 55%。
- 图 1b 中对比了使用 gt 框作为输入,CLIP 在 LVIS 框上的分类准确率只有 19%
- 所以,直接将预训练好的 CLIP 拿来用于对 region 的分类不太适合
作者想探索一下这种差别来源于哪里?
- 首先可以想到,CLIP 模型的训练是使用整个 image 作为输入的,使用的是 image-level 的文本描述来训练的,所以,模型学习到的是整张图的特征
- 所以这种模型无法将文本概念和图像中的区域联系起来
本文如何解决 image 和 region 之间的差距:
- 作者通过使用 vision-language 预训练的模型来探索如何学习 region 的表达
- 主要思想是在预训练过程中,将 image region 和 text token 进行对齐
面临的问题:
- image-text pairs 中不包含 image region 和 text token 的对齐关系
- 整张图的文本描述是不全的,也就是图中的有些目标是没有体现在文本描述中的
二、方法
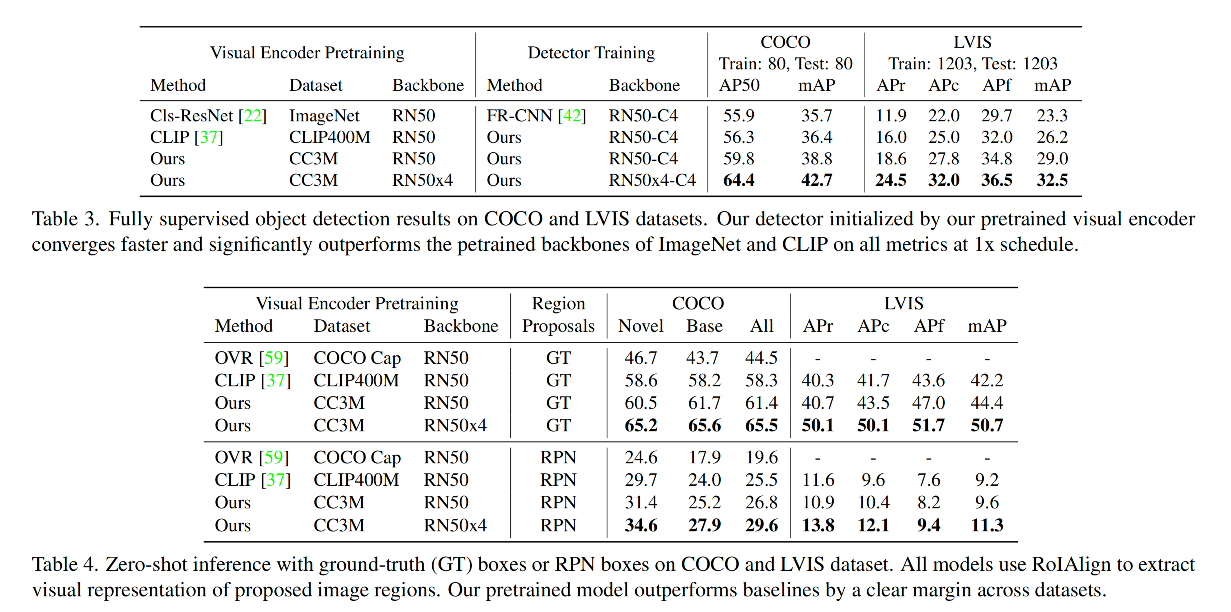
本文的目标是学习一个区域级别的视觉-语义空间,能够覆盖足够丰富的目标词汇且用于开放词汇目标检测
- 假设文本描述 t 能够描述图像 I 中的区域 r
- 在视觉-语义空间,从 r 中抽取到的 visual region representation 能够和 text representation 很好的匹配上
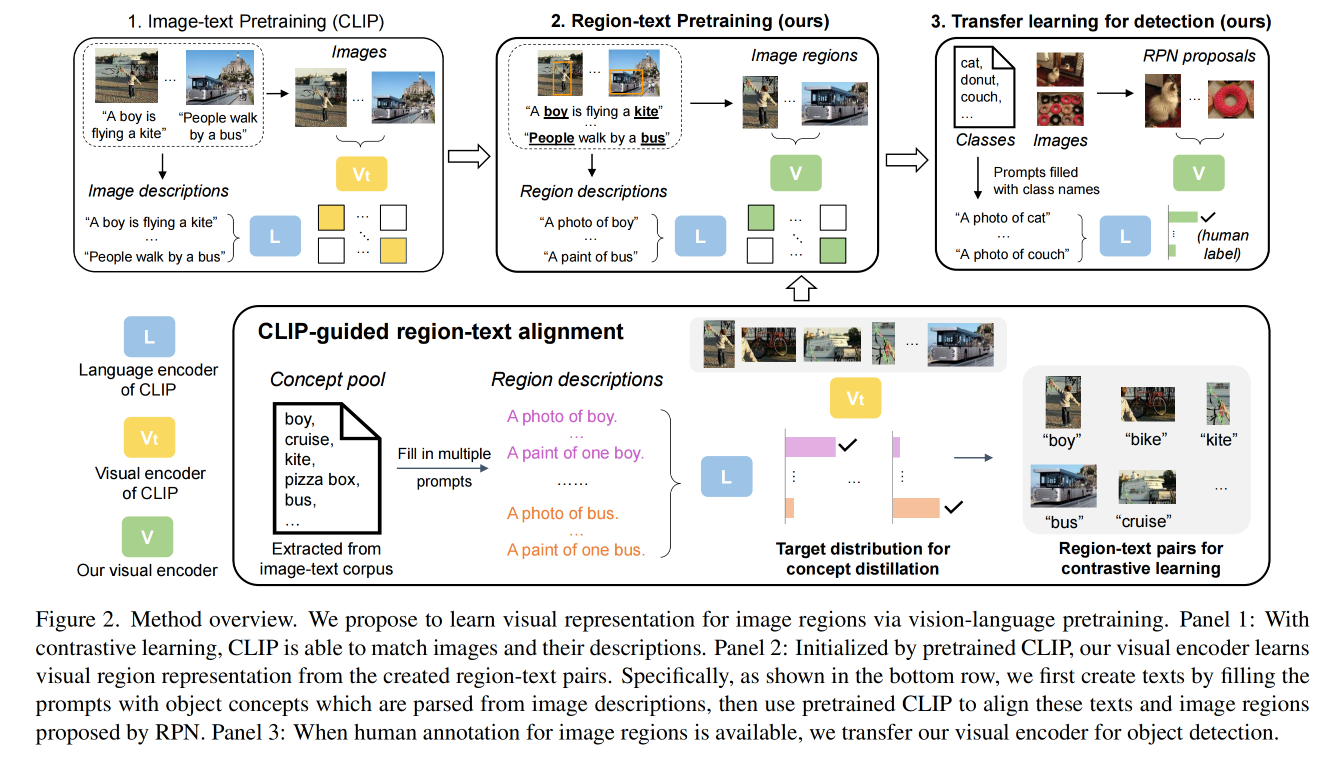
总体框架图如图 2:
- V t V_t Vt :CLIP 的 visual encoder, L L L :CLIP 的 language encoder
- V V V:本文需要训练的 visual encoder,使用 V t V_t Vt 进行初始化,
- 我们的目标是训练一个 visual encoder V V V 类实现对 image region 的编码,并且将这些编码和 language encoder 输出的语言编码对齐
- 为了克服缺少大规模 region 描述的问题,如图 2 底部,作者构建了一个目标词汇池,通过将词汇填入 prompt 来构建 region 的描述,并且借助 teacher encoder V t V_t Vt 来将这些描述和使用图像定位网络得到的图像区域进行对齐
- 通过使用这些创建的 region-text pairs,visual encoder V V V 就需要通过对比学习和词汇整理来学习将这些 pairs 对齐
2.1 Region-based Language-Image Pretraining
1、Visual region representation
可以使用现有的目标定位器(如 RPN)或密集滑动窗口 来进行图像区域的生成
作者使用经过人工标注 bbox 训练过的 RPN 来生成,这里不对 bbox 的类别进行区分
- 对于一个输入 batch,使用 RPN 产生 N 个 image regions
- 使用 visual encoder V V V 进行视觉特征抽取,并使用 RoIAlign 来 pooling,且 V V V 的权重是使用 teacher V t V_t Vt 的来进行初始化的
2、Semantic region representation
一个单个的图像通常会包含丰富的语义信息,多个不同类别的目标,且人工标注这么大规模哦对数据也不太可行
所以,作者首先构建了一个大的词汇池,来尽可能的覆盖所有区域词汇,如图 2 所示,而且建立的词汇池是从文本语料库中解析得来的
有了词汇池后,按照如下的方式来构建每个区域的语义表达:
- 第一步,将 concept 填入 prompt 模版(a photo of a kite)
- 第二步,使用预训练的 language encoder L 来得到语义特征表达
- 最后,使用语义编码就能表达每个区域词汇的特征表达 { l j } j = 1 , . . . , C \{l_j\}_{j=1,...,C} { lj}j=1,...,C
3、visual-semantic alignment for regions
① 如何对齐 region-text pairs:使用 CLIP 来构建伪标签,即使用 teacher model CLIP 预测的得分最大的 concept 作为该区域的描述
-
作者借用 teacher visual encoder 来建立 region-text 之间的关系,这里的 text 表示语义编码,区域 r i r_i ri 的 visual representation v i t v_i^t vit 是从 teacher visual encoder V t V_t Vt 中抽取的
-
然后,计算 v i t v_i^t vit 和 { l j } \{l_j\} { lj} 的匹配得分,得分最高的就和区域进行关联起来,然后就能得到每个区域的伪标签: { v i , l m } \{v_i, l_m\} { vi,lm}
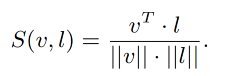
② 如何预训练:
-
同时使用来自网络的 region-text pairs 和 image-text pairs
-
region-text pairs 就是通过 ① 的方法来创建的
-
拿到上述 region-text pairs { v i , l m } \{v_i, l_m\} { vi,lm},使用对比学习 loss 和蒸馏 loss 来训练 visual decoder,总共包含 3 部分
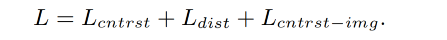
-
region-text 的对比学习 loss 如下, τ \tau τ 是预定义的温度参数, N r i N_{ri} Nri 是 region r i r_i ri 的 negative textual samples,也就是在一个 batch 中和 region r i r_i ri 不匹配但和其他区域匹配的
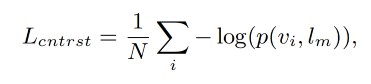
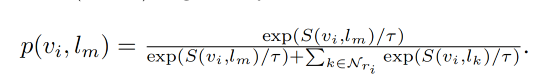
-
除了对比学习 loss 以外,还有考虑每个图像区域的知识蒸馏,蒸馏 loss 如下, q i t q_i^t qit 是从 teacher model 得到的 soft target, q i q_i qi 是 student model 得到的预测
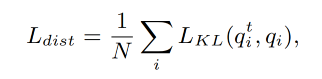
-
image-text 的对比学习 loss L c n t r s t − i m g L_{cntrst-img} Lcntrst−img 可以从 region level 扩展而来,也就是特殊情况,即 ① 一个 box 覆盖了整张图,② 文本描述来源于网络,③ negative samples 是从其他图像而来的文本描述
-
零样本推理
预训练之后,训练得到的 visual encoder 可以直接用于 region reasoning 任务,比如从 RPN 获得区域,从训练的 visual encoder 得到该区域的视觉表达,然后和文本词汇表达进行匹配,得到相似度最高的文本
实验证明使用 RPN score 能够提升 zero-shot 推理的效果,所以作者也使用了 RPN objectness score + category confidence score 的均值来作为最终的得分,用于匹配。
2.2 目标检测的迁移学习
预训练中,本文的 visual encoder 是从 teacher model 提供的 region-text alignment 中学习的,不需要人为一些操作,所以也会有一个噪声,当引入更强的监督信号(如人为标注 label)时,可以进一步 fine-tuning visual encoder,如图 2
如何将预训练网络迁移到目标检测器呢,作者通过初始化目标检测器的 visual backbone 来实现,先使用现有的 RPN 网络来进行目标区域的定位,然后将区域和文本匹配
开放词汇目标检测:
- 对基础类别,使用类似于 focal loss 的加权权重 ( 1 − p b ) γ (1-p^b) \gamma (1−pb)γ, p b p^b pb 是预测的概率, γ \gamma γ 是超参数,该加权权重能缓解模型对预训练中的知识的遗忘,尤其是当数据集中有很少的基础类时(如 coco),作者猜测如果基础类别很少,模型可能会对基础类别过拟合,对新类的泛化能力会降低
- 对背景类别,作者使用固定的 all-zero 编码方式,并且使用预定义的权重
三、效果
3.1 数据集
预训练时,作者使用:
- 来自于 Conceptual Caption dataset (CC3M) 的 image-text pairs,包括 300 万来自网络的 pairs
- COCO Caption(COCO Cap),包含 118k images,每个 images 约有 5 个人工标注的 captions
- 作者从 COCO/CC3M 中抽取了目标词汇,过滤掉了出现频次小于 100 的词汇,得到了 4764/6790 个词汇
为了开放词汇目标检测的迁移学习,作者使用 COCO 数据集和 LVIS 数据集的基础类来训练。
- COCO:48 个基础类,17 个新类
- LVIS:866 个基础类,337 个新类
作者使用目标检测标准测评:AP 和 AP50
- COCO:使用 AP50 测评新类、基础类、所有类
- LVIS:rare 类也就是 novel 类,即测评新类的 AP (APr)、基础类的 AP (APc/APf)、所有类的 AP (mAP)
3.2 实现细节
1、预训练
- teacher model 和 student model :都是预训练的 CLIP(ResNet50)
- RPN:使用 LVIS 的基础类别训练
- 默认模型:使用 CC3M 数据集,使用从 COCO Cap 解析出来的词汇
- 优化器: SGD、batch = 96、learning rate = 0.002, maximum iteration = 600k、 100 regions per image.
2、目标检测迁移
- 使用 detectron2 基于 Faster RCNN [42] with ResNet50-C4 结构作为检测器
- RPN:使用目标数据集的基础类别来训练
- SGD:batch=16,initial learning = 0.002,1x schedule
- focal scaling: γ = 0.5 \gamma=0.5 γ=0.5
3、目标检测零样本推理
- RPN:使用 LVIS 的基础类别训练得到的 RPN
- NMS:threshold=0.9
- τ = 0.01 \tau=0.01 τ=0.01
3.3 结果