要说视频-文本预训练中使用的预训练任务。首先介绍一些流行的预训练任务。例如,双编码器模型通常通过视频文本对比学习进行优化。对于融合编码器模型,两个流行的预训练任务是掩码语言建模(MLM)和视频文本匹配(VTM)。然后,我们讨论旨在模拟视频输入的独特特征的预训练任务,例如帧顺序建模(FOM)和不同变体的掩码视频建模(MVM)。
1. 视频文本对比学习(VTC)
在VTC中,模型的目标是学习视频和文本之间的对应关系。VTC被广泛采用来训练双编码器模型,其中通过轻量级的内积将视频和文本输入融合在一起。这种简单的点积也用于计算双编码器模型中的视频到文本和文本到视频相似度。具体而言,给定一批N个视频-文本对,VTC旨在从所有个可能的视频-文本对中预测N个匹配对。

视频向量和文本向量在一个训练批次中的规范化表示为: 和
,其中σ是学习到的温度超参数。视频到文本的对比损失为
,文本到视频的对比损失为
。
VTC的简单公式假设在预训练数据中存在正确的视频和文本对齐情况,但这并非总是如此。在现有的视频-文本数据上进行大规模对比预训练的一个巨大挑战是视觉帧与语音转录字幕之间固有的不对齐问题。为了解决视觉不对齐的叙述问题,MIL-NCE提出了将多实例学习和对比学习相结合的方法,以利用叙述视频中弱而嘈杂的训练信号。与Miech等人中的固定长度相比,VideoCLIP构建了时间重叠的视频和文本片段对,以提高预训练语料库的质量和数量。此外,他们不仅对比同一视频中的不同片段,还对比从其他视频检索到的与批次内片段相似的较难负例。
此外,传统的对比学习在聚合视频中的文本和帧中的所有单词后计算损失。在TACo中,作者建议使其成为token-aware的,即仅使用一小部分单词(例如名词和动词)来计算损失,以改进单个单词在视频中的根基。TACo将令牌感知的VTC与应用于双编码器架构的朴素VTC相结合,并进一步添加了通过深度多模态融合增强的第三VTC损失。具体而言,视频和文本输入之间的相似度是Transformer块在双编码器之上操作的结果,该结果对应于融合编码器架构的[CLS]令牌的多模态融合输出。为了减少计算融合编码器VTC损失的复杂性,他们采用了级联采样策略,仅基于令牌感知的VTC和朴素VTC损失对一小部分难负例进行采样。

2. 掩码语言建模(MLM)
MLM是直接采用用于语言模型预训练的模型,除了输入为视频-文本对。形式上,MLM的输入包括:
(i)来自输入句子w的sub-word tokens;
(ii)与w对齐的视觉输入(例如帧块/特征)v;
(iii)掩码索引。N是自然数,M是掩码标记的数量,而m是掩码索引的集合。
在实践中,我们以15%的概率随机掩盖掉输入单词,并用特殊标记[MASK]替换被掩盖的标记wm。遵循BERT的做法,被随机掩盖的15%单词进一步分解成10%的随机单词,10%保持不变和80% [MASK]。目标是根据其周围单词和与句子对齐的视觉输入v来预测这些被掩盖的单词,通过最小化负对数似然来实现:
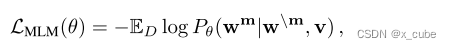
其中θ表示可训练的参数。每对(w,v)都从训练集D中采样。
与图像-文本预训练相似,视频-文本预训练方法也使用语言建模的变体,其中解释逐字生成,如UniVL和Support-Set。特定于视频-文本预训练,语音转录文本通常较为非正式,包含话语或重复提及关键对象。为了避免在无依据的单词上进行掩盖,MERLOT提供了一种简单的启发式解决方案,根据学习的注意权重来掩盖单词,并经验验证了其相对于随机掩盖的优势。
3. 视频文本匹配(VTM)
在VTM中,模型被给予一批正样本视频-文本对和负样本视频-文本对,这些对通过替换正样本视频-文本对中的视频/文本输入来构建。VTM的目标是识别正样本的视频和文本对。VTM通常被表述为一个二分类任务。具体而言,在输入句子的开头插入一个特殊标记(即[CLS]),其学习到的向量表示用作输入视频-文本对的跨模态表示。然后我们以相等的概率将匹配或不匹配的视频-文本对v,w喂给模型,并学习一个分类器来预测二进制标签y,表示采样的视频-文本对是正面还是负面。具体而言,用输出分数sθ(w, v)表示,我们应用二进制交叉熵损失进行优化:

不同的VTM变体已被提出,以捕获不同粒度级别的时间维度上的对齐。例如,HERO考虑了全局对齐(预测文本是否与输入视频匹配)和局部时间对齐(检索文本应该在视频剪辑中定位的时刻),这已被证明对于下游视频语料库时刻检索是有效的。
4. 其他预训练任务
除了上面讨论的预训练任务外,还有一些尝试利用视频输入的独特特征进行自监督预训练。
4.1 Frame Order Modeling(FOM)
FOM旨在建模视频中发生的事件或动作的时序顺序。在训练期间,我们随机选择一定百分比的输入帧(或帧特征)进行混洗,并训练模型以显式地恢复正确的时间顺序。探索了两种变体,包括像HERO一样重构这些混洗帧的绝对时序顺序,以及像MERLOT一样预测每对帧之间的相对顺序。在这两篇文章中,FOM应用于与具有时序基础的文本(如字幕或ASR输出)配对的视频。
带有绝对时序顺序的FOM
在时间t处,让我们将视频帧输入标记为,将具有时序基础的句子标记为
。FOM的输入是:(i)所有字幕句子
;(ii)视觉帧
;(iii)重新排序索引
,其中R是重新排序帧的数量,而r是重新排序索引的集合。在训练期间,随机选择15%的帧进行混洗,目标是沿着时间维度重建它们的原始顺序,表示为
。FOM被表述为分类问题,其中t是重新排序帧的基准标签。最终目标是最小化负对数似然:
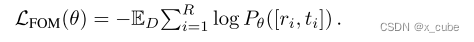
带有相对时序顺序的FOM
在训练期间,40%的时间,首先从[2, T]中随机选择整数n,表示要随机混洗的帧数,给定T个输入帧。然后,随机选择n帧进行随机混洗。混洗后,将帧与文本输入一起输入模型以学习联合视频-语言表示。对于时间步长ti和tj处的每一对帧(混洗后),我们将它们隐藏状态连接起来,并将结果通过两层多层感知机传递,预测ti是否小于tj或ti是否大于tj。类似地,可以使用交叉熵损失来优化带有相对时序顺序的FOM。
4.2 掩蔽视频建模(MVM)
由于连续帧可能包含相似的空间信息,因此引入了MVM来重建一定比例的“掩蔽”视觉输入(即特征或块)的高级别语义或低级别细节,给定来自相邻帧和配对文本描述的完整视频令牌/特征。具体而言,模型训练来重建被掩蔽的块或特征vm,给定剩余可见块或特征v\m和配对文本w。也就是说,

类似的目标已为图像-文本预训练提出,被称为掩蔽图像建模(MIM)。
4.2.1 带有批内负样本的MVM
在HERO中探索了带有批内负样本的MVM,利用噪声构造估计损失来监督模型以识别与被掩蔽帧对应的正确帧特征,并将其与同一批次中的所有负分布进行比较。
4.2.2 带有离散视觉标记的MVM
首先在VideoBERT中引入带有离散视觉标记的MVM。VideoBERT使用分层k-means将输入视频帧中提取的连续S3D特征分割为离散的“视觉标记”。这些视觉标记随后用作模型的视频输入和MVM的预测目标。MVM被表述为分类任务,并以与MLM相同的方式执行。类似地,有15%的输入视觉标记被随机掩蔽,并训练模型以恢复这些被掩蔽的视觉标记。最近,VIOLET从视觉Transformers上的自监督学习方法中获得灵感,利用预训练的DALL-E提取离散视觉标记作为MVM目标。VIOLET随机掩盖原始输入视频帧块,并训练模型以端到端的方式预测这些被掩蔽块的相应视觉标记。
4.2.3 带有其他视觉目标的MVM
除了离散视觉标记外, Fu等人还实际考察了MVM的其他7个重建目标,包括低级别像素值和定向梯度、高级别深度图、光流预测以及来自深度神经网络的各种潜在视觉特征。同样地,原始输入视频帧块被随机掩盖,并以MVM预测与这些被掩蔽块的连续视觉目标之间的l1损失对模型训练进行监督。