论文解读:
ViG![]() https://github.com/huawei-noah/Efficient-AI-Backbones/tree/master/vig_pytorch
https://github.com/huawei-noah/Efficient-AI-Backbones/tree/master/vig_pytorch

一、网络结构
ViG可堆叠为各向同性结构(isotropic architecture)(类似于ViT)和金字塔结构(pyramid architecture)(类似于ResNet)。本文主要解析金字塔结构PyramidViG-B为例。涉及的代码是git中的pyramid.py和gcn_lib文件夹在的三个文件。
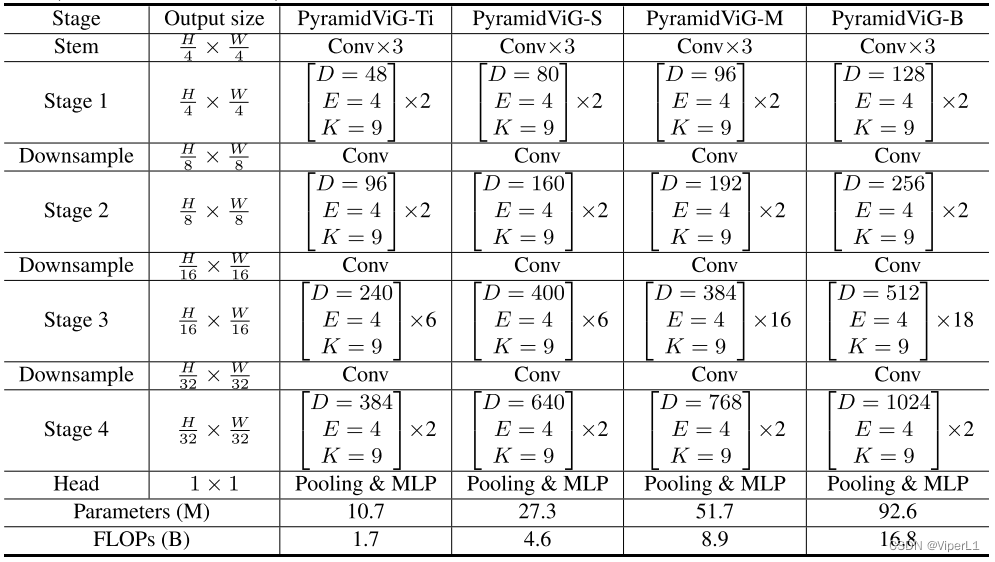
如上图所示,通过不同规格的ViG Block的堆叠,可以构造出具有4个Stage的金字塔行网络。经过移植,可以取代Resnet50在Faster RCNN中担任主干网络(但直接移植效果并不理想)。
网络定义代码:
def pvig_b_224_gelu(num_classes =1000,pretrained=False, **kwargs):
class OptInit:
# 参数列表
def __init__(self, num_classes=1000, drop_path_rate=0.0, **kwargs):
self.k = 9 # 邻居节点数,默认为9
self.conv = 'mr' # 图卷积层类型,可选 {edge, mr}
self.act = 'gelu' # 激活层类型,可选 {relu, prelu, leakyrelu, gelu, hswish}
self.norm = 'batch' # 归一化方式,可选 {batch, instance}
self.bias = True # 卷积层是否使用偏置
self.dropout = 0.0 # dropout率
self.use_dilation = True # 是否使用扩张knn
self.epsilon = 0.2 # gcn的随机采样率
self.use_stochastic = False # gcn的随机性
self.drop_path = drop_path_rate
self.blocks = [2,2,18,2] # 各层的block个数
self.channels = [128, 256, 512, 1024] # 各层的通道数
self.n_classes = num_classes # 分类器输出通道数
self.emb_dims = 1024 # 嵌入尺寸
opt = OptInit(**kwargs)
model = DeepGCN(opt) #构造gcn
model.default_cfg = default_cfgs['vig_b_224_gelu'] #注入参数
return model# 网络参数计算代码
class DeepGCN(torch.nn.Module):
def __init__(self, opt):
super(DeepGCN, self).__init__()
# ...
# 参数赋值省略
# ...
blocks = opt.blocks # 获取各层block个数列表[2,2,18,2]
self.n_blocks = sum(blocks) # 获取block层数总数
channels = opt.channels # 获取输出通道数(用于分类器赋值)
reduce_ratios = [4, 2, 1, 1] # 下采样率
# 获取FFN的随机深度衰减规律
dpr = [x.item() for x in torch.linspace(0, drop_path, self.n_blocks)]
# 获取各层knn的数量
num_knn = [int(x.item()) for x in torch.linspace(k, k, self.n_blocks)]
max_dilation = 49 // max(num_knn) #最大相关数目
HW = 224 // 4 * 224 // 4二、ViG模块
实际网络构造时使用ViG Block进行堆叠,ViG Block由GCN模块和FFN模块个组成,构造使用代码循环堆叠ViG Block
# 构造骨干网络
self.backbone = nn.ModuleList([])
idx = 0
for i in range(len(blocks)):
if i > 0:
# 如果不是第一层需要额外在层间添加下采样
self.backbone.append(Downsample(channels[i-1], channels[i]))
HW = HW // 4
for j in range(blocks[i]):
self.backbone += [
# 构造GCN
Seq(Grapher(channels[i], num_knn[idx], min(idx // 4 + 1, max_dilation), conv, act, norm,
bias, stochastic, epsilon, reduce_ratios[i], n=HW, drop_path=dpr[idx],
relative_pos=True),
# 构造FFN
FFN(channels[i], channels[i] * 4, act=act, drop_path=dpr[idx])
)]
idx += 1
self.backbone = Seq(*self.backbone)
# 构造分类器
self.prediction = Seq(nn.Conv2d(channels[-1], 1024, 1, bias=True),
nn.BatchNorm2d(1024),
act_layer(act),
nn.Dropout(opt.dropout),
nn.Conv2d(1024, opt.n_classes, 1, bias=True))
self.model_init()网络的前向传递函数,可以看到图片在进入图网络之前先进行了stem(就是ViT里的切patch操作)和位置编码(位置对应的矩阵)
def forward(self, inputs):
x = self.stem(inputs) + self.pos_embed #patch分割和位置嵌入
B, C, H, W = x.shape
for i in range(len(self.backbone)):
x = self.backbone[i](x)
x = F.adaptive_avg_pool2d(x, 1)
return self.prediction(x).squeeze(-1).squeeze(-1)stem操作和位置嵌入如下:
self.stem = Stem(out_dim=channels[0], act=act)
#返回整数部分
self.pos_embed = nn.Parameter(torch.zeros(1, channels[0], 224//4, 224//4))1.Grapher模块
首先看Grapher的前向传递函数
def forward(self, x):
_tmp = x
x = self.fc1(x)
B, C, H, W = x.shape
relative_pos = self._get_relative_pos(self.relative_pos, H, W)
x = self.graph_conv(x, relative_pos)
x = self.fc2(x)
x = self.drop_path(x) + _tmp
return x可以看到,对于每个Grapher模块而言,基本的处理流程是:
①全连接层fc1
# 由一个1x1Conv和一个BatchNorm组成
self.fc1 = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 1, stride=1, padding=0),
nn.BatchNorm2d(in_channels),
)②由_get_relative_pos(.)函数更新关联位置
其实从代码来看是用来匹配下采样带来的尺寸变化(调整尺寸)
def _get_relative_pos(self, relative_pos, H, W):
if relative_pos is None or H * W == self.n:
return relative_pos
else:
N = H * W
N_reduced = N // (self.r * self.r)
return F.interpolate(relative_pos.unsqueeze(0), size=(N, N_reduced), mode="bicubic").squeeze(0)在block初始化时,由get_2d_relative_pos_embed(.)函数赋予初值(如不启用的话会直接置None);
# 获取位置嵌入
relative_pos_tensor = torch.from_numpy(np.float32(
get_2d_relative_pos_embed(in_channels,int(n**0.5)))).unsqueeze(0).unsqueeze(1)
# 进行双线性插值
relative_pos_tensor = F.interpolate(relative_pos_tensor, size=(n, n//(r*r)),
mode='bicubic', align_corners=False)
# 转换为nn参数
self.relative_pos = nn.Parameter(-relative_pos_tensor.squeeze(1), requires_grad=False)get_2d_relative_pos_embed(.)位置嵌入函数,位于gcn_lib/pos_embed.py。作用是构建一个grid,并获取位置嵌入(包含cls_token)
③图卷积(graph_conv )
self.graph_conv = DyGraphConv2d(in_channels, in_channels * 2, kernel_size,
dilation, conv, act, norm, bias, stochastic, epsilon, r)转到graph_conv ,查看其前向传递函数:
def forward(self, x, relative_pos=None):
B, C, H, W = x.shape
y = None
if self.r > 1: # 此参数为下采样率,金字塔池化情况下默认开启(始终大于1)
y = F.avg_pool2d(x, self.r, self.r)
y = y.reshape(B, C, -1, 1).contiguous()
x = x.reshape(B, C, -1, 1).contiguous()
# 获取邻居节点的聚合信息(基于knn)
edge_index = self.dilated_knn_graph(x, y, relative_pos)
# 图卷积
x = super(DyGraphConv2d, self).forward(x, edge_index, y)
# 将tensor变形为四维并输出
return x.reshape(B, -1, H, W).contiguous()其中self.dilated_knn_graph为DenseDilatedKnnGraph,来自gcn_lib/torch_edge.py,和大部分图网络算法一样采用torch.topk(.)来进行邻接矩阵稀疏。同时使用part_pairwise_distance函数从特征中提取x_square_part、x_inner、x_square三个值。
④全连接层fc2
self.fc2 = nn.Sequential(
nn.Conv2d(in_channels * 2, in_channels, 1, stride=1, padding=0),
nn.BatchNorm2d(in_channels),
)这个和前一个全连接层一样,只不过输入通道翻倍了而已。
⑤DropPath随机删除
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()用来防止过拟合,同时该网络中还具备类似残差的结构
x = self.drop_path(x) + _tmp2.FNN模块
FNN模块是一个多层感知机,由两层全连接实现,同样具备残差结构
shortcut = x
x = self.fc1(x)
x = self.act(x)
x = self.fc2(x)
x = self.drop_path(x) + shortcut
return x self.fc1 = nn.Sequential(
nn.Conv2d(in_features, hidden_features, 1, stride=1, padding=0),
nn.BatchNorm2d(hidden_features),
)
self.act = act_layer(act)
self.fc2 = nn.Sequential(
nn.Conv2d(hidden_features, out_features, 1, stride=1, padding=0),
nn.BatchNorm2d(out_features),
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()这里的激活层act默认为relu激活函数。
三、网络的迁移
得益于金字塔结构带来的多尺度特征,ViG可以像Swin Transfomer一样作为骨干网络用来特征提取,这里将其作为骨干网络移植到Faster RCNN中代替原本的ResNet50。卸掉prediction预测头和平均池化adaptive_avg_pool2d后,可以由一个224x224x3的输入得到一个7x7x1024的特征。
def forward(self, inputs):
x = self.stem(inputs) + self.pos_embed
B, C, H, W = x.shape
for i in range(len(self.backbone)):
x = self.backbone[i](x)
# x = F.adaptive_avg_pool2d(x, 1)
return x经过测试,ViG可以在数据集上获得越70%的mAP,但是效果劣于resnet50和mobilenetv3,具体原因不明。