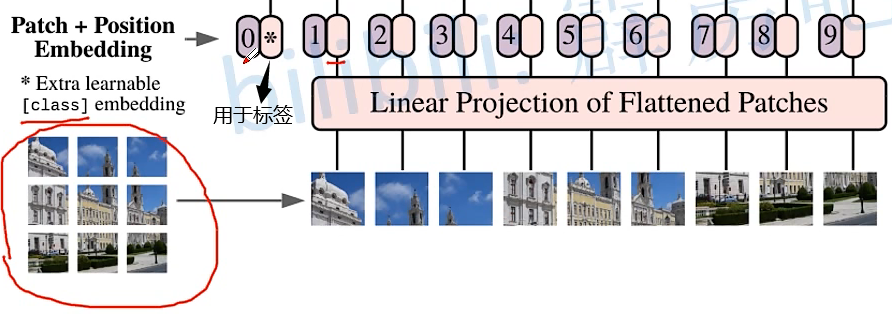
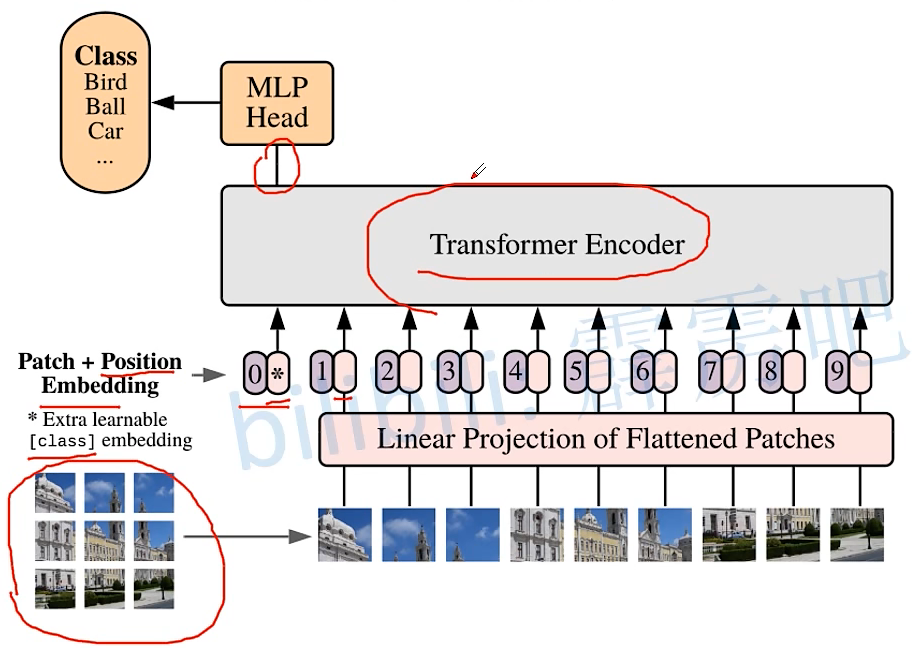
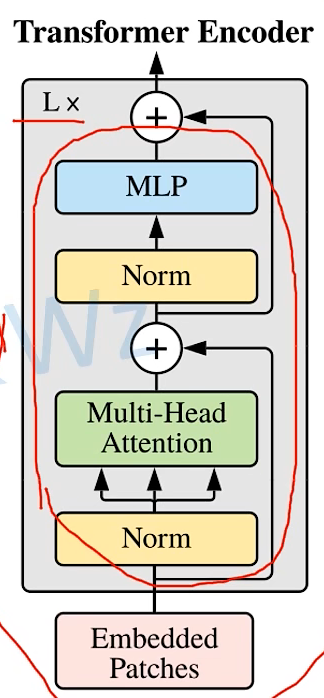
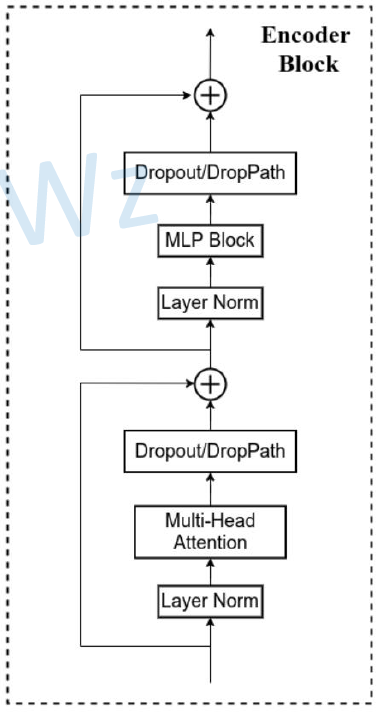
Transformer Vision(二)|| ViT-B/16 网络结构

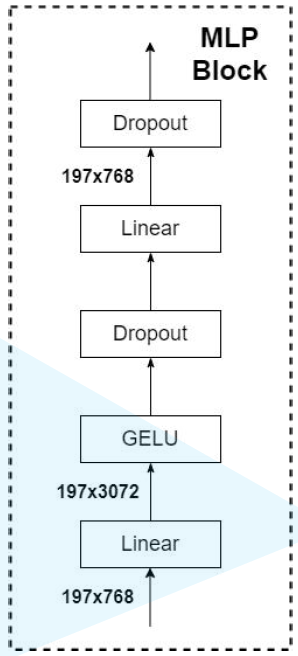
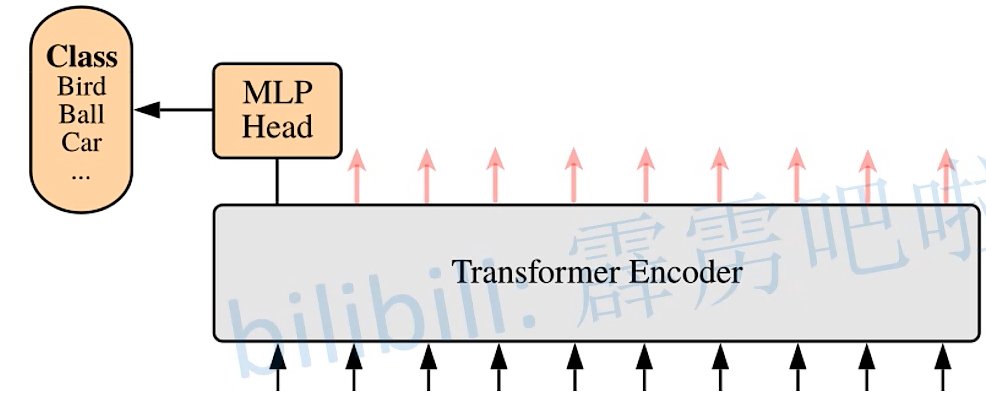
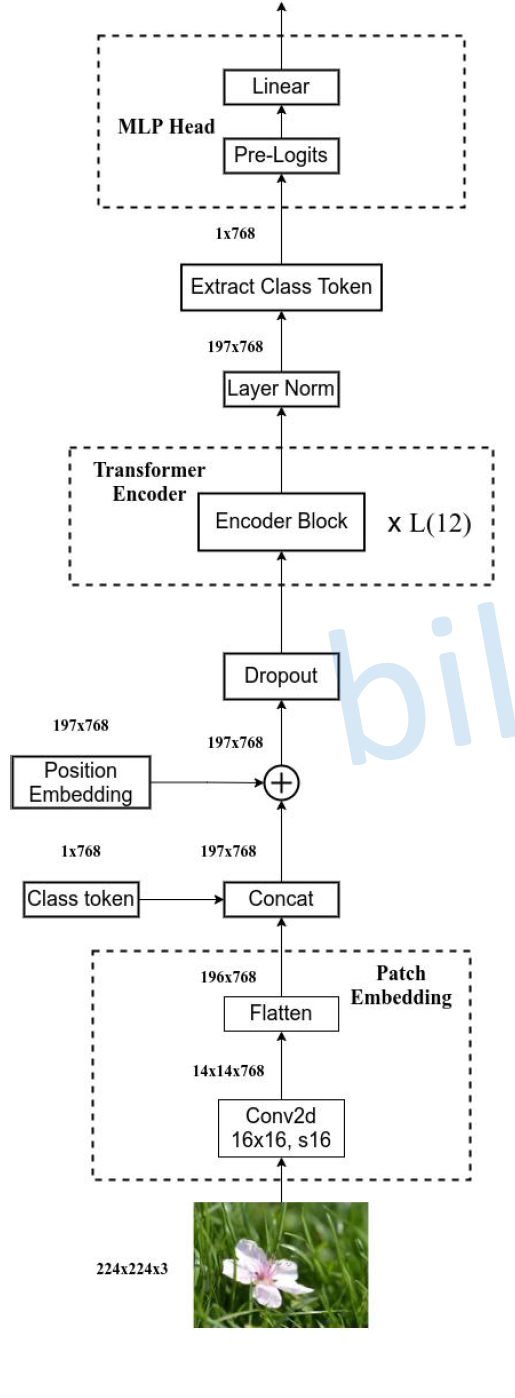

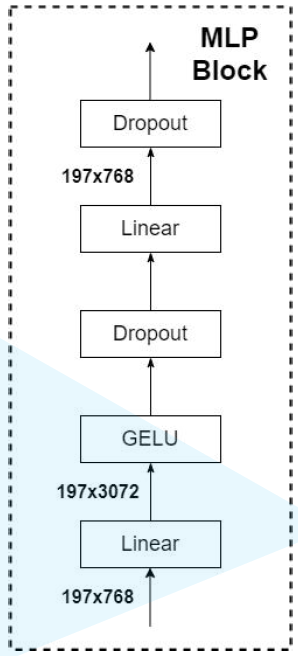
猜你喜欢
转载自blog.csdn.net/qq_56039091/article/details/124785401
今日推荐
周排行