MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer
Sachin Mehta Apple Mohammad Rastegari Apple
3.2 Multi-scale Sampler for Training Efficiency
Abstract
Light-weight convolutional neural networks (CNNs) are the de-facto for mobile vision tasks. Their spatial inductive biases allow them to learn representations with fewer parameters across different vision tasks. However, these networks are spatially local. To learn global representations, self-attention-based vision transformers (ViTs) have been adopted. Unlike CNNs, ViTs are heavy-weight.
In this paper, we ask the following question: is it possible to combine the strengths of CNNs and ViTs to build a light-weight and low latency network for mobile vision tasks?
Towards this end, we introduce MobileViT, a light-weight and general-purpose vision transformer for mobile devices.
MobileViT presents a different perspective for the global processing of information with transformers, i.e., transformers as convolutions.
Our results show that MobileViT significantly outperforms CNN- and ViT-based networks across different tasks and datasets. On the ImageNet-1k dataset, MobileViT achieves top-1 accuracy of 78.4% with about 6 million parameters, which is 3.2% and 6.2% more accurate than MobileNetv3 (CNN-based) and DeIT (ViT-based) for a similar number of parameters. On the MS-COCO object detection task, MobileViT is 5.7% more accurate than MobileNetv3 for a similar number of parameters.
轻量级卷积神经网络是移动视觉任务的实际应用。其空间归纳偏差允许他们在不同的视觉任务中以较少的参数学习表征。然而,这些网络在空间上是局部的。为了学习全局表征,采用了基于self-attention 的 vision transformer (ViTs)。与 CNN 不同,ViT 是重量级的。
本文提出了以下问题:是否有可能结合 CNN 和 ViT 的优势,构建一个轻量级、低延迟的移动视觉任务网络?
为此,本文提出了 MobileViT,一种轻量级的、通用的移动设备 vision transformer。MobileViT 提出了一个不同的视角,以 transformer 作为卷积处理信息。
结果表明,在不同的任务和数据集上,MobileViT 显著优于基于 CNN 和 ViT 的网络。在 ImageNet-1k 数据集上,MobileViT 在大约 600 万个参数的情况下达到了 78.4% 的 top 1 准确率,对于相同数量的参数,比 MobileNetv3 (基于 CNN)和 DeIT (基于 ViT) 的准确率分别高出 3.2% 和6.2%。在 MS-COCO 目标检测任务中,在参数数量相近的情况下,MobileViT 比 MobileNetv3 的准确率高 5.7%。
1. Intoduction
Self-attention-based models, especially vision transformers (ViTs; Figure 1a; Dosovitskiy et al., 2021), are an alternative to convolutional neural networks (CNNs) to learn visual representations. Briefly, ViT divides an image into a sequence of non-overlapping patches and then learns interpatch representations using multi-headed self-attention in transformers (Vaswani et al., 2017). The general trend is to increase the number of parameters in ViT networks to improve the performance (e.g., Touvron et al., 2021a; Graham et al., 2021; Wu et al., 2021). However, these performance improvements come at the cost of model size (network parameters) and latency. Many real-world applications (e.g., augmented reality and autonomous wheelchairs) require visual recognition tasks (e.g., object detection and semantic segmentation) to run on resource-constrained mobile devices in a timely fashion. To be effective, ViT models for such tasks should be light-weight and fast. Even if the model size of ViT models is reduced to match the resource constraints of mobile devices, their performance is significantly worse than light-weight CNNs. For instance, for a parameter budget of about 5-6 million, DeIT (Touvron et al., 2021a) is 3% less accurate than MobileNetv3 (Howard et al., 2019). Therefore, the need to design light-weight ViT models is imperative.
研究背景和意义:虽然 ViT 很好,但大的网络参数和延迟影响其在现实场景(资源受限)中的应用。因此,轻量级的 ViT 很重要!
基于 Self-attention 的模型,特别是 vision transformers (ViTs; 图 1a) 是卷积神经网络 (CNN) 学习视觉表征的一种替代方法。简单地说,ViT 将图像分成一系列不重叠的 patches,然后在 transformers 中使用多头 Self-attention 学习 patch 间表示。总的趋势是增加 ViT 网络的参数数量以提高性能。然而,这些性能改进是以模型大小 (网络参数) 和延迟为代价的。许多现实世界的应用程序 (如增强现实和自动轮椅) 需要视觉识别任务 (如目标检测和语义分割) 在资源受限的移动设备上及时运行。为了有效,这类任务的 ViT 模型应该是轻量级和快速的。即使减小 ViT 模型的模型尺寸以匹配移动设备的资源约束,其性能也明显低于轻量级 CNN。例如,对于大约 5- 600 万的参数预算,DeIT 的准确性比 MobileNetv3 低 3%。因此,设计轻量化的 ViT 模型势在必行。

Light-weight CNNs have powered many mobile vision tasks. However, ViT-based networks are still far from being used on such devices. Unlike light-weight CNNs that are easy to optimize and integrate with task-specific networks, ViTs are heavy-weight (e.g., ViT-B/16 vs. MobileNetv3: 86 vs. 7.5 million parameters), harder to optimize (Xiao et al., 2021), need extensive data augmentation and L2 regularization to prevent over-fitting (Touvron et al., 2021a; Wang et al., 2021), and require expensive decoders for down-stream tasks, especially for dense prediction tasks. For instance, a ViT-based segmentation network (Ranftl et al., 2021) learns about 345 million parameters and achieves similar performance as the CNN-based network, DeepLabv3 (Chen et al., 2017), with 59 million parameters. The need for more parameters in ViT-based models is likely because they lack image-specific inductive bias, which is inherent in CNNs (Xiao et al., 2021).
To build robust and high-performing ViT models, hybrid approaches that combine convolutions and transformers are gaining interest (Xiao et al., 2021; d’Ascoli et al., 2021; Chen et al., 2021b). However, these hybrid models are still heavy-weight and are sensitive to data augmentation. For example, removing CutMix (Zhong et al., 2020) and DeIT-style (Touvron et al., 2021a) data augmentation causes a significant drop in ImageNet accuracy (78.1% to 72.4%) of Heo et al. (2021).
研究现状:ViT 之所以需要巨大参数,可能是因为其没有 CNN 的特异性归纳偏差。于是,有些工作也在想办法结合 CNN 和 ViT,但这种方法依然不够轻量级。
轻量级 CNN 为许多移动视觉任务提供了动力。然而,基于 ViT 的网络距离在这些设备上使用还很遥远。不像轻量 CNN 容易优化并与特定任务网络集成,ViT 是重量的 (例如,ViT-B/16 vs. MobileNetv3: 86 vs. 7.5 million 个参数),更难优化,需要大量的数据增强和 L2 正则化以防止过拟合。对于下游任务,特别是密集预测任务,需要昂贵的解码器。例如,基于 ViT 的分割网络学习了约 3.45 亿个参数,取得了与基于 CNN 的网络 DeepLabv3 的 5900 万个参数相似的性能。基于 ViT 的模型需要更多参数可能是因为它们缺乏 CNN 固有的图像特异性归纳偏差。
为了建立鲁棒的高性能 ViT 模型,结合卷积和 transformer 的混合方法正在引起人们的兴趣。然而,这些混合模型仍然是重量级和依赖于数据增强。例如,去除 CutMix 和 DeIT-style 的数据增强会导致 ImageNet 准确性的显著下降 (78.1%至72.4%)。
It remains an open question to combine the strengths of CNNs and transformers to build ViT models for mobile vision tasks. Mobile vision tasks require light-weight, low latency, and accurate models that satisfy the device’s resource constraints, and are general-purpose so that they can be applied to different tasks (e.g., segmentation and detection).
Note that floating-point operations (FLOPs) are not sufficient for low latency on mobile devices because FLOPs ignore several important inferencerelated factors such as memory access, degree of parallelism, and platform characteristics (Ma et al., 2018). For example, the ViT-based method of Heo et al. (2021), PiT, has 3× fewer FLOPs than DeIT (Touvron et al., 2021a) but has a similar inference speed on a mobile device (DeIT vs. PiT on iPhone-12: 10.99 ms vs. 10.56 ms).
Therefore, instead of optimizing for FLOPs , this paper focuses on designing a light-weight (§3), general-purpose (§4.1 & §4.2), and low latency (§4.3) network for mobile vision tasks. We achieve this goal with MobileViT that combines the benefits of CNNs (e.g., spatial inductive biases and less sensitivity to data augmentation) and ViTs (e.g., input-adaptive weighting and global processing).
Specifically, we introduce the MobileViT block that encodes both local and global information in a tensor effectively (Figure 1b). Unlike ViT and its variants (with and without convolutions), MobileViT presents a different perspective to learn global representations. Standard convolution involves three operations: unfolding, local processing, and folding. MobileViT block replaces local processing in convolutions with global processing using transformers. This allows MobileViT block to have CNN- and ViT-like properties, which helps it learn better representations with fewer parameters and simple training recipes (e.g., basic augmentation).
如何结合 CNN 和 Transformer 的优势来构建移动视觉任务的 ViT 模型,仍然是一个悬而未决的问题。移动视觉任务需要轻量、低延迟和精确的模型,满足设备的资源约束,并且是通用的,以便它们可以应用于不同的任务 (例如,分割和检测)。【满足移动视觉任务的轻量级网络 4 要素:轻量,低延迟,通用,精确】。
注意,浮点操作 (FLOPs) 对于移动设备上的低延迟是不够的,因为 FLOPs 忽略了几个重要的推断相关因素,如内存访问、并行度和平台特性。例如,Heo et al. (2021年) 的基于 ViT 的方法 PiT,其 FLOPs 比 DeIT 少 3 倍,但在移动设备上具有相似的推断速度 (iPhone-12上的 DeIT 与 PiT: 10.99 ms 与 10.56 ms)。
因此,本文并没有针对 FLOPs 进行优化,而是着重于为移动视觉任务设计一个轻量级 (§3)、通用(§4.1 &§4.2) 和低延迟 (§4.3) 的网络。本文通过 MobileViT 实现了这一目标,MobileViT 结合了CNN (例如,空间归纳偏差和对数据增强较不敏感) 和 ViT (例如,输入自适应加权和全局处理) 的优点。
具体来说,引入了 MobileViT block,它可以有效地在一个张量中编码局部和全局信息 (图1b)。与 ViT 及其变体 (有或没有卷积) 不同,MobileViT 为学习全局表示提供了不同的视角。标准卷积包括三种操作:展开、局部处理和折叠。而 MobileViT block 使用 transformer 将卷积中的局部处理替换为全局处理。这允许 MobileViT block 具有 CNN- 和 ViT-like 属性,这有助于它用更少的参数和简单的训练配方 (例如,基本增强) 学习更好的表示。
To the best of our knowledge, this is the first work that shows that light-weight ViTs can achieve light-weight CNN-level performance with simple training recipes across different mobile vision tasks. For a parameter budget of about 5-6 million, MobileViT achieves a top-1 accuracy of 78.4% on the ImageNet-1k dataset (Russakovsky et al., 2015), which is 3.2% more accurate than MobileNetv3 and has a simple training recipe (MobileViT vs. MobileNetv3: 300 vs. 600 epochs; 1024 vs. 4096 batch size). We also observe significant gains in performance when MobileViT is used as a feature backbone in highly optimized mobile vision task-specific architectures. Replacing MNASNet (Tan et al., 2019) with MobileViT as a feature backbone in SSDLite (Sandler et al., 2018) resulted in a better (+1.8% mAP) and smaller (1.8×) detection network (Figure 2).

这是第一个表明轻量级 ViT 可以通过简单的训练 recipes 在不同的移动视觉任务中实现轻量级 CNN 级性能的工作。【文章中的 simple training recipes 我的理解是在训练设置上采用的一些经验 tricks,比如增加训练 epoch,增加 batch 数量,这些 tricks 和网络、数据特点不相关】。在 5-6 百万的参数预算下,MobileViT 在 ImageNet-1k 数据集上达到了 78.4% 的最高准确率,比 MobileNetv3 的准确率高 3.2%,并且有一个简单的训练 recipes (MobileViT vs. MobileNetv3: 300 vs. 600 epochs;1024 vs. 4096 batch 大小)。
在高度优化的特定于移动视觉任务的架构中,将 MobileViT 用作特性主干时,性能有了显著提高。用 MobileViT 替代 MNASNet 作为 SSDLite 的特征 backbone,可以得到更好的 (+1.8%的mAP) 和更小的 (1.8×) 检测网络 (图2)。
2 Related Work
Light-weight CNNs
The basic building layer in CNNs is a standard convolutional layer. Because this layer is computationally expensive, several factorization-based methods have been proposed to make it light-weight and mobile-friendly (e.g., Jin et al., 2014; Chollet, 2017; Mehta et al., 2020). Of these, separable convolutions of Chollet (2017) have gained interest, and are widely used across state-of-the-art light-weight CNNs for mobile vision tasks, including MobileNets (Howard et al., 2017; Sandler et al., 2018; Howard et al., 2019), ShuffleNetv2 (Ma et al., 2018), ESPNetv2 (Mehta et al., 2019), MixNet (Tan & Le, 2019b), and MNASNet (Tan et al., 2019). These light-weight CNNs are versatile and easy to train. For example, these networks can easily replace the heavy-weight backbones (e.g., ResNet (He et al., 2016)) in existing task-specific models (e.g., DeepLabv3) to reduce the network size and improve latency. Despite these benefits, one major drawback of these methods is that they are spatially local.
This work views transformers as convolutions; allowing to leverage the merits of both convolutions (e.g., versatile and simple training) and transformers (e.g., global processing) to build light-weight (§3) and general-purpose (§4.1 and §4.2) ViTs.
CNN 的基本构建层是标准的卷积层。由于这一层的计算代价昂贵,已经提出了几种基于因子分解的方法,以使其轻量化和移动友好。其中,Chollet (2017) 的可分离卷积引起了人们的兴趣,并被广泛用于最先进的轻量级 CNN 移动视觉任务,包括 MobileNets (Howard et al., 2017;桑德勒等人,2018;Howard et al., 2019), ShuffleNetv2 (Ma et al., 2018), ESPNetv2 (Mehta et al., 2019), MixNet (Tan &Le, 2019b)和 MNASNet (Tan et al., 2019)。这些轻量级 CNN 是多功能的,易于训练。例如,在现有的特定任务模型 (如 DeepLabv3) 中,这些网络可以很容易地替代重量级 backbone (如 ResNet (He et al., 2016)),以减少网络规模,提高延迟。尽管有这些好处,但这些方法的一个主要缺点是它们在空间上是局部的。
本文将 transfomer 视为卷积;允许利用卷积 (例如,多用途和简单训练) 和 transformer (例如,全局处理) 的优点来构建轻量级和通用 ViT。
Vision transformers
Dosovitskiy et al. (2021) apply transformers of Vaswani et al. (2017) for large-scale image recognition and showed that with extremely large-scale datasets (e.g., JFT-300M), ViTs can achieve CNN-level accuracy without image-specific inductive bias. With extensive data augmentation, heavy L2 regularization, and distillation, ViTs can be trained on the ImageNet dataset to achieve CNN-level performance (Touvron et al., 2021a;b; Zhou et al., 2021).
However, unlike CNNs, ViTs show substandard optimizability and are difficult to train. Subsequent works (e.g., Graham et al., 2021; Dai et al., 2021; Liu et al., 2021; Wang et al., 2021; Yuan et al., 2021b; Chen et al., 2021b) shows that this substandard optimizability is due to the lack of spatial inductive biases in ViTs. Incorporating such biases using convolutions in ViTs improves their stability and performance. Different designs have been explored to reap the benefits of convolutions and transformers. For instance, ViT-C of Xiao et al. (2021) adds an early convolutional stem to ViT. CvT (Wu et al., 2021) modifies the multi-head attention in transformers and uses depth-wise separable convolutions instead of linear projections. BoTNet (Srinivas et al., 2021) replaces the standard 3×3 convolution in the bottleneck unit of ResNet with multi-head attention. ConViT (d’Ascoli et al., 2021) incorporates soft convolutional inductive biases using a gated positional self-attention. PiT (Heo et al., 2021) extends ViT with depth-wise convolution-based pooling layer.
Though these models can achieve competitive performance to CNNs with extensive augmentation, the majority of these models are heavy-weight. For instance, PiT and CvT learns 6.1× and 1.7× more parameters than EfficientNet (Tan & Le, 2019a) and achieves similar performance (top-1 accuracy of about 81.6%) on ImageNet-1k dataset, respectively. Also, when these models are scaled down to build light-weight ViT models, their performance is significantly worse than light-weight CNNs. For a parameter budget of about 6 million, ImageNet-1k accuracy of PiT is 2.2% less than MobileNetv3.
Dosovitskiy et al. (2021) 将 Vaswani et al. (2017) 的 transformers 应用于大尺度图像识别,结果表明,在超大尺度数据集 (如JFT-300M)下,ViTs 可以实现 CNN 级的精度,而不存在图像特异性的归纳偏差。通过广泛的数据增强、大量的 L2 正则化和蒸馏,ViT 可以在 ImageNet 数据集上训练以实现 CNN 级别的性能。
然而,与 CNN 不同的是,ViT 的优化性能不佳,而且很难训练。后续工作表明,这种不达标的优化性是由于 ViT 缺乏空间归纳偏差。在 ViT 中使用卷积来合并这种偏差可以提高其稳定性和性能。人们探索了不同的设计来获得卷积和 transformers 的好处。例如,Xiao et al.的 VIT-C 为 ViT 增加了一个早期卷积 stem。CvT 修改了 transformers 中的多头注意,并使用 depth-wise 可分的卷积代替线性投影。BoTNet 在 ResNe t的 bottleneck 单元中用多头注意取代了标准的 3x3 卷积。ConViT 利用门控位置 self-attention 引入了软卷积归纳偏差。PiT 使用基于 depth-wise 卷积的池化层扩展了 ViT。
虽然这些模型可以达到与 CNN 竞争的性能与广泛的增强,大多数这些模型是重型的。例如,PiT 和 CvT 比 EfficientNet 多学习 6.1x 和 1.7x 个参数,并在 ImageNet-1k 数据集上取得了相似的性能 (top one 的准确率约为 81.6%)。此外,当这些模型被缩小以构建轻量级 ViT 模型时,它们的性能明显比轻量级 CNN 差。对于大约 600 万的参数预算,PiT 的 ImageNet-1k 精度比 MobileNetv3 低 2.2%。
Discussion
Combining convolutions and transformers results in robust and high-performing ViTs as compared to vanilla ViTs. However, an open question here is: how to combine the strengths of convolutions and transformers to build light-weight networks for mobile vision tasks? This paper focuses on designing light-weight ViT models that outperform state-of-the-art models with simple training recipes.
Towards this end, we introduce MobileViT that combines the strengths of CNNs and ViTs to build a light-weight, general-purpose, and mobile-friendly network. MobileViT brings several novel observations.
(i) Better performance: For a given parameter budget, MobileViT models achieve better performance as compared to existing light-weight CNNs across different mobile vision tasks (§4.1 and §4.2).
(ii) Generalization capability: Generalization capability refers to the gap between training and evaluation metrics. For two models with similar training metrics, the model with better evaluation metrics is more generalizable because it can predict better on an unseen dataset. Unlike previous ViT variants (with and without convolutions) which show poor generalization capability even with extensive data augmentation as compared to CNNs (Dai et al., 2021), MobileViT shows better generalization capability (Figure 3).
(iii) Robust: A good model should be robust to hyper-parameters (e.g., data augmentation and L2 regularization) because tuning these hyper-parameters is time- and resource-consuming. Unlike most ViT-based models, MobileViT models train with basic augmentation and are less sensitive to L2 regularization (§C).
与普通的 ViT 相比,将卷积和 transformers 相结合可以得到鲁棒的高性能 ViT。然而,一个开放的问题是:如何结合卷积和 transformers 来构建移动视觉任务的轻量级网络?
本文的重点是设计轻量的 ViT 模型,通过简单的训练 recipes 超越最先进的模型。为此,引入了 MobileViT,它结合了CNN 和 ViT 的优势,构建了一个轻量级、通用和移动友好的网络。MobileViT 带来了一些新的观察结果。
(i) 更好的性能:在给定的参数预算下,与现有的轻量级 CNN 相比,MobileViT 模型在不同的移动视觉任务中取得了更好的性能 (4.1 和 4.2 节)。
(ii) 泛化能力:泛化能力是指训练与评价指标之间的差距。对于具有相似训练指标的两个模型,具有更好评价指标的模型更具有通用性,因为它可以更好地预测未见数据集。与之前的 ViT 变体 (带卷积和不带卷积) 相比,即使有广泛的数据增强,也表现出较差的泛化能力 (Dai et al., 2021), MobileViT 显示出更好的泛化能力 (图 3)。
(iii) 更鲁棒:一个好的模型应该对超参数具有鲁棒性 (例如,数据增强和 L2 正则化),因为调优这些超参数非常耗时和耗费资源。与大多数基于 ViT 的模型不同,MobileViT 模型使用基本增强训练,对 L2 正则化不太敏感 (附录 C)。

3 MobileViT
首先,总体介绍 MobileViT 诞生的研究动机及其优点
A standard ViT model, shown in Figure 1a, reshapes the input
into a sequence of flattened patches
, projects it into a fixed d-dimensional space
, and then learn inter-patch representations using a stack of L transformer blocks.
The computational cost of self-attention in vision transformers is
. Here,
,
, and
represent the channels, height, and width of the tensor respectively, and
is number of pixels in the patch with height
and width
, and
is the number of patches.
Because these models (ViT-based network) ignore the spatial inductive bias that is inherent in CNNs, they require more parameters to learn visual representations. For instance, DPT (Dosovitskiy et al., 2021), a ViT-based network, learns 6× more parameters as compared to DeepLabv3 (Chen et al., 2017), a CNN-based network, to deliver similar segmentation performance (DPT vs. DeepLabv3: 345 M vs. 59 M).
Also, in comparison to CNNs, these models (ViT-based network) exhibit substandard optimizability. These models are sensitive to L2 regularization and require extensive data augmentation to prevent overfitting (Touvron et al., 2021a; Xiao et al., 2021).
标准 ViT 模型,如图 1a 所示,重塑 输入一系列拉伸的 patches
,再将其映射到一个固定的 d 维空间
,然后通过堆叠 L 个 transformer blocks 学习patch 内部的表示。
Vision transformer 中 self-attention 的计算成本是 。其中,C、H、W 分别表示张量的通道、高度和宽度,P = wh 为高度 H、宽度 W 的 patch 中的像素数,N 为 patch 的数量。由于这些 ViT 模型忽略了 CNN 中固有的空间归纳偏差,它们需要更多的参数来学习视觉表征。例如,基于 ViT 的 DPT 网络,比基于 CNN 的网络 DeepLabv3 多学习 6 倍的参数,才能实现类似的分割性能(DPT vs DeepLabv3: 345 M vs 59 M)。
此外,与 CNN 相比,ViT 模型的优化性能不佳。这些模型对 L2 正则化很敏感,需要大量的数据增强以防止过拟合。

This paper introduces a light-weight ViT model, MobileViT. The core idea is to learn global representations with transformers as convolutions. This allows us to
implicitly incorporate convolution-like properties (e.g., spatial bias) in the network,
learn representations with simple training recipes (e.g., basic augmentation), and
easily integrate MobileViT with downstream architectures (e.g., DeepLabv3 for segmentation).
本文介绍了一种轻量级 ViT 模型 —— MobileViT。其核心思想是学习将 transformer 作为卷积的全局表示。这允许在网络中
隐式地合并类似卷积的属性(例如,空间偏差),
通过简单的训练配方 (例如,基本增强) 学习表示,
易于将 MobileViT 与下游架构集成 (例如,用于分割的 DeepLabv3)。
3.1 MobileViT Architecture
MobileViT block
The MobileViT block, shown in Figure 1b, aims to model the local and global information in an input tensor with fewer parameters. Formally, for a given input tensor
standard convolutional layer followed by a point-wise (or 1×1) convolutional layer to produce
. The
convolutional layer encodes local spatial information while the point-wise convolution projects the tensor to a high-dimensional space (or d-dimensional, where d > C) by learning linear combinations of the input channels.
MobileViT block 如图 1b 所示,其目的是用较少的参数对输入张量中的局部和全局信息进行建模。形式上,对于给定的输入张量,MobileViT 采用一个 标准卷积层,然后是一个 point-wise (或 1×1) 卷积层来生成
。
卷积层编码局部空间信息,而 point-wise 卷积通过学习输入通道的线性组合将张量投影到高维空间 (或 d 维空间,其中 d >c)。

With MobileViT, we want to model long-range non-local dependencies while having an effective receptive field of H × W. One of the widely studied methods to model long-range dependencies is dilated convolutions. However, such approaches require careful selection of dilation rates. Otherwise, weights are applied to padded zeros instead of the valid spatial region (Yu & Koltun, 2016; Chen et al., 2017; Mehta et al., 2018).
Another promising solution is self-attention (Wang et al., 2018; Ramachandran et al., 2019; Bello et al., 2019; Dosovitskiy et al., 2021). Among self-attention methods, vision transformers (ViTs) with multi-head self-attention are shown to be effective for visual recognition tasks. However, ViTs are heavy-weight and exhibit sub-standard optimizability. This is because ViTs lack spatial inductive bias (Xiao et al., 2021; Graham et al., 2021).
我们希望 MobileViT,在具有 H × W 的有效接受域的同时,对远程非局部依赖进行建模。
膨胀卷积:这种方法需要谨慎选择膨胀率。另外,权重被应用到填充的零而不是有效的空间区域。
self-attention:其中具有 multi-head self-attention 的 ViTs 在视觉识别任务中是有效的。然而,ViT 是重量级的,并表现出低于标准的可优化性。这是因为 ViTs 缺乏空间 inductive bias。
To enable MobileViT to learn global representations with spatial inductive bias, we unfold
into
. Here,
is the number of patches, and
and
are height and width of a patch respectively. For each
, inter-patch relationships are encoded by applying transformers to obtain
as:
(1)
Unlike ViTs that lose the spatial order of pixels, MobileViT neither loses the patch order nor the spatial order of pixels within each patch (Figure 1b). Therefore, we can fold
.
is then projected to low C-dimensional space using a point-wise convolution and combined with
via concatenation operation. Another
convolutional layer is then used to fuse local and global features in the concatenated tensor. Note that because
encodes local information from
encodes global information across
patches for the p-th location, each pixel in
can encode information from all pixels in
.
为了使 MobileViT 学习具有空间归纳偏差的全局表示,将 展开为 N 个不重叠的 flattened patches。其中,P = wh, N = HW, P 为 patch 个数,h ≤ N, w ≤ N 分别为 patch 的高度和宽度。对于每个 p∈{1,···,p},利用 transformer 对 patch 间关系进行编码,得到
,即公式 (1)。
与丢失像素空间顺序的 ViT 不同,MobileViT 既不丢失 patch 顺序,也不丢失每个 patch 内像素的空间顺序 (图1b)。因此,可以将 fold 到
。然后,
通过 point-wise 卷积投影到低的 C 维空间,并通过连接操作与 X 结合。然后使用另一个 n × n 卷积层来融合级联张量中的局部和全局特征。注意,因为
使用卷积对 n × n 区域的局部信息进行编码,而
对 p 个位置的 p 个 patch 的全局信息进行编码,所以
中的每个像素都可以对X 中的所有像素进行编码,如图 4 所示。因此,MobileViT 的整体有效接受域为 H × W。

Relationship to convolutions
Standard convolutions can be viewed as a stack of three sequential operations: (1) unfolding, (2) matrix multiplication (to learn local representations), and (3) folding.
MobileViT block is similar to convolutions in the sense that it also leverages the same building blocks. MobileViT block replaces the local processing (matrix multiplication) in convolutions with deeper global processing (a stack of transformer layers). As a consequence, MobileViT has convolution-like properties (e.g., spatial bias). Hence, the MobileViT block can be viewed as transformers as convolutions. An advantage of our intentionally simple design is that low-level efficient implementations of convolutions and transformers can be used out-of-the-box; allowing us to use MobileViT on different devices without any extra effort.
标准卷积可以看作是三个顺序操作的堆栈 : (1)展开,(2) 矩阵乘法(学习局部表示) 和 (3)折叠。
MobileViT block 与卷积相似,因为它也利用了相同的构建 blocks。MobileViT block 将卷积中的 local处理 (矩阵乘法) 替换为更深层次的全局处理 (堆叠的 transformer 层)。因此,MobileViT 具有类似于卷积的属性 (例如,spatial bias)。因此,MobileViT block 可以看作是 transformer 作为卷积。我们有意设计的简单的一个优势是,卷积和 transformer 的低层次高效实现可以开箱即用 (out-of-the-box);允许我们在不同的设备上使用 MobileViT 而不需要任何额外的努力。
Light-weight
MobileViT block uses standard convolutions and transformers to learn local and global representations respectively. Because previous works (e.g., Howard et al., 2017; Mehta et al., 2021a) have shown that networks designed using these layers are heavy-weight, a natural question arises: Why MobileViT is light-weight?
We believe that the issues lie primarily in learning global representations with transformers. For a given patch, previous works (e.g., Touvron et al., 2021a; Graham et al., 2021) convert the spatial information into latent by learning a linear combination of pixels (Figure 1a). The global information is then encoded by learning inter-patch information using transformers. As a result, these models lose image-specific inductive bias, which is inherent in CNNs. Therefore, they require more capacity to learn visual representations. Hence, they are deep and wide.
Unlike these models, MobileViT uses convolutions and transformers in a way that the resultant MobileViT block has convolution-like properties while simultaneously allowing for global processing. This modeling capability allows us to design shallow and narrow MobileViT models, which in turn are light-weight.
Compared to the ViT-based model DeIT that uses L=12 and d=192, MobileViT model uses L= {2, 4, 3} and d={96, 120, 144} at spatial levels 32 × 32, 16 × 16, and 8 × 8, respectively. The resulting MobileViT network is faster (1.85×), smaller (2×), and better (+1.8%) than DeIT network (Table 3; §4.3).
MobileViT block 使用标准卷积和 transformers 分别学习局部和全局表示。因为之前的工作已经表明,使用这些层设计的网络是重量级的,一个自然的问题出现了:为什么 MobileViT 是轻量级的,而之前的工作 (卷积+transformer) 是重量级的?
作者认为问题主要在于通过 transformers 学习全局表示。对于给定的 patch,以前的工作通过学习像素的线性组合将空间信息转化为潜在信息 (图1a)。然后,通过使用 transformers 学习 patch 间信息对全局信息进行编码。因此,这些模型失去了图像特定的归纳偏差。因此,他们需要更多的能力来学习视觉表征。因此,它们又深又宽。
与这些模型不同的是,MobileViT 使用卷积和 transformers 的方式是,生成的 MobileViT block 具有类似卷积的属性,同时允许全局处理。这种建模能力使我们能够设计浅而窄的 MobileViT 模型,从而使其重量更轻。
与基于 ViT 的 DeIT 模型使用 L=12 和 d=192 相比,MobileViT 模型在 32 × 32、16 × 16 和 8 × 8 的空间层次上分别使用 L={2,4,3} 和 d={96, 120, 144}。由此得到的 MobileViT 网络比DeIT 网络更快 (1.85×),更小 (2×),更好(+1.8%) (表3;§4.3)。
Computational cost
The computational cost of multi-headed self-attention in MobileViT and ViTs (Figure 1a) is
and
MobileViT 和 ViTs 中多头 self-attention 的计算成本分别为 and
。理论上,与 ViTs 相比,MobileViT 效率较低。而实践中,MobileViT 比 ViTs 更有效率 (表3;§4.3)。这是因为轻量化设计的原因 (上面讨论过)。
MobileViT architecture
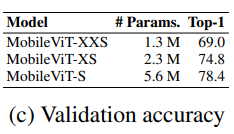
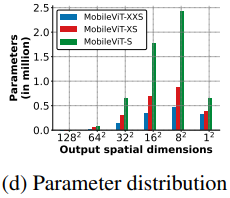
Our networks are inspired by the philosophy of light-weight CNNs. We train MobileViT models at three different network sizes (S: small, XS: extra small, and XXS: extra extra small) that are typically used for mobile vision tasks (Figure 3c). The initial layer in MobileViT is a strided 3 × 3 standard convolution, followed by MobileNetv2 (or MV2) blocks and MobileViT blocks (Figure 1b and §A). We use Swish (Elfwing et al., 2018) as an activation function. Following CNN models, we use n = 3 in the MobileViT block. The spatial dimensions of feature maps are usually multiples of 2 and h, w ≤ n. Therefore, we set h = w = 2 (height and width of patches) at all spatial levels (see §C for more results). The MV2 blocks in MobileViT network are mainly responsible for down-sampling. Therefore, these blocks are shallow and narrow in MobileViT network. Spatial-level-wise parameter distribution of MobileViT in Figure 3d further shows that the contribution of MV2 blocks towards total network parameters is very small across different network configurations.
MobileViT 网络受到轻量级哲学的启发。用三种不同的网络规模 (S:小,XS:特别小,XXS:特别小) 训练 MobileViT 模型,这三种网络规模通常用于移动视觉任务(图3c)。MobileViT 的初始层是一个 strided 的 3 × 3 标准卷积,其次是 MobileNetv2 (或 MV2 ) block 和 MobileViT block (图 1b 和 § A)。使用 Swish 作为激活函数。按照 CNN 模型,在 MobileViT block 中使用 n = 3。feature map 的空间维度通常是 2 和 h, w≤n 的倍数。因此,我们在所有的空间层次上都设 h = w = 2 (更多结果见§C)。MobileViT 网络中的 MV2 block 主要负责降采样。因此,这些 blocks 在 MobileViT 网络中是浅而窄的。图 3d 中 MobileViT 的 spatial-level-wise 参数分布进一步表明,在不同的网络配置中,MV2 block 对总网络参数的贡献非常小。

3.2 Multi-scale Sampler for Training Efficiency
A standard approach in ViT-based models to learn multi-scale representations is fine-tuning. For instance, Touvron et al. (2021a) fine-tunes the DeIT model trained at a spatial resolution of 224 × 224 on varying sizes independently. Such an approach for learning multi-scale representations is preferable for ViTs because positional embeddings need to be interpolated based on the input size, and the network’s performance is subjective to interpolation methods. Similar to CNNs, MobileViT does not require any positional embeddings and it may benefit from multi-scale inputs during training.
在基于 ViT 的模型中,学习多尺度表示的标准方法是微调。例如,Touvron et al. (2021a) 在不同大小的空间分辨率下对训练的 DeIT 模型进行了微调。由于 positional embeddings 需要根据输入大小进行插值,而网络的性能受插值方法的影响,因此这种学习多尺度表示的方法对于 ViT 是更可取的。与 CNN 类似,MobileViT 不需要任何 positional embeddings ,它可以从训练期间的多尺度输入中受益。
Previous CNN-based works (e.g., Redmon & Farhadi, 2017; Mehta et al., 2021b) have shown that multi-scale training is effective. However, most of these works sample a new spatial resolution after a fixed number of iterations. For example, YOLO-v2 (Redmon & Farhadi, 2017) samples a new spatial resolution from a pre-defined set at every 10-th iteration and uses the same resolution across different GPUs during training. This leads to GPU under-utilization and slower training because the same batch size (determined using the maximum spatial resolution in the pre-defined set) is used across all resolutions.
To facilitate MobileViT learn multi-scale representations without fine-tuning and to further improve training efficiency (i.e., fewer optimization updates), we extend the multi-scale training method to variably-sized batch sizes. Given a sorted set of spatial resolutions
and a batch size
for a maximum spatial resolution of
, we randomly sample a spatial resolution
at t-th training iteration on each GPU and compute the batch size for t-th iteration as:
. As a result, larger batch sizes are used for smaller spatial resolutions. This reduces optimizer updates per epoch and helps in faster training.
先前基于 CNN 的工作已经证明多尺度训练是有效的。然而,这些工作中的大多数都是经过固定次数的迭代后获得新的空间分辨率。例如,YOLO-v2 在每 10 次迭代时从预定义的集合中采样一个新的空间分辨率,并在训练期间在不同的 GPU 上使用相同的分辨率。这导致 GPU 利用率不足和训练速度变慢,因为在所有分辨率中使用相同的 batch size (使用预定义集中的最大空间分辨率确定)。
为了便于 MobileViT 在不进行微调的情况下学习多尺度表示,并进一步提高训练效率 (即更少的优化更新),本文将多尺度训练方法扩展到可变大小的 batch size。给定一组排序的空间分辨率 S = {(H1, W1 ), · · · ,( Hn, Wn)} 和 batch size 为 b 的最大空间分辨率 (Hn, Wn),在每个 GPU 第 t 次训练迭代,随机样本空间分辨率为 (Ht、Wt),并计算第 t 次迭代的 batch size 为 : 。因此,更大的 batch size 用于更小的空间分辨率。这减少了优化器每个 epoch 的更新,有助于更快的训练。
Figure 5 compares standard and multi-scale samplers. Here, we refer to
in PyTorch as the standard sampler. Overall, the multi-scale sampler (i) reduces the training time as it requires fewer optimizer updates with variably-sized batches (Figure 5b), (ii) improves performance by about 0.5% (Figure 10; §B), and (iii) forces the network to learn better multi-scale representations (§B), i.e., the same network when evaluated at different spatial resolutions yields better performance as compared to the one trained with the standard sampler. In §B, we also show that the multi-scale sampler is generic and improves the performance of CNNs (e.g., MobileNetv2).
图 5 比较了标准 samplers 和多尺度 samplers。在这里,将 PyTorch 中的 称为标准 samplers。总体而言,多尺度采样器 (i) 减少了训练时间,因为它需要更少的优化器更新不同大小的 batch size (图5b), (ii) 提高了约 0.5% 的性能 (图10;§B) 和 (iii) 强迫网络学习更好的多尺度表征 (§B),即在不同的空间分辨率下评估相同的网络,与使用标准采样器训练的网络相比,会产生更好的性能。在 §B 中,还证明了多尺度采样器是通用的,并改善了 CNN (如 MobileNetv2) 的性能。

Multi-scale sampler reduces generalization gap
Generalization capability refers to the gap between training and evaluation metrics. For two models with similar training metrics,the model with better evaluation metrics is more generalizable because it can predict better on an unseen dataset. Figure 9a and Figure 9b compares the training and validation error of the MobileViT-S model trained with standard and multi-scale samplers. The training error of MobileViT-S with multi-scale sampler is higher than standard sampler while validation error is lower. Also, the gap between training error and validation error of MobileViT-S with multi-scale sampler is close to zero. This suggests that a multi-scale sampler improves generalization capability. Also, when MobileViT-S trained independently with standard and multi-scale sampler is evaluated at different input resolutions (Figure 9c), we observe that MobileViT-S trained with multi-scale sampler is more robust as compared to the one trained with the standard sampler. We also observe that multi-scale sampler improves the performance of MobileViT models at different model sizes by about 0.5% (Figure 10). These observations in conjunction with impact on training efficiency (Figure 5b) suggests that a multi-scale sampler is effective.
多尺度采样器减少了泛化差距
泛化能力是指训练和评价指标之间的差距。对于具有相似训练指标的两个模型,具有更好评价指标的模型更具有通用性,因为它可以更好地预测未见数据集。图 9a 和图 9b 比较了在标准样本和多尺度样本下训练的 MobileViT-S 模型的训练和验证误差。多尺度采样器对 MobileViT-S 的训练误差高于标准采样器,但验证误差较低。多尺度采样的 MobileViT-S 训练误差与验证误差之间的差距接近于零。这表明多尺度采样器提高了泛化能力。
此外,当使用标准和多尺度采样器独立训练的 MobileViT-S 在不同输入分辨率下进行评估时 (图9c),我们观察到,使用多尺度采样器训练的 MobileViT-S 比使用标准采样器训练的 MobileViT-S 更稳健。我们还观察到,在不同的模型尺寸下,多尺度采样器提高了约 0.5% 的 MobileViT 模型的性能 (图10)。这些观察结果结合对训练效率的影响 (图 5b) 表明多尺度采样器是有效的。


Multi-scale sampler is generic
We train a heavy-weight (ResNet-50) and a light-weight (MobileNetv2-1.0) CNN with the multi-scale sampler to demonstrate its generic nature. Results in Table 5 show that a multi-scale sampler improves the performance as well as training efficiency. For instance, a multi-scale sampler improves the performance of MobileNetv2-1.0 by about 1.4% while decreasing the training time by 14%.
多尺度采样器是通用的
我们使用多尺度采样器对一个 heavy-weight (ResNet-50) 和一个 light-weight (MobileNetv2-1.0) CNN 进行训练,以展示其通用性。表 5 的结果表明,多尺度采样器提高了性能和训练效率。例如,多尺度采样器提高了约 1.4% 的 MobileNetv2-1.0 的性能,同时减少了 14% 的训练时间。
