近年来,各种机器学习算法越来越多地被应用于数据挖掘与其相关性分析中,旨在实现通过输入数据(特征)即能准确地预测输出数据(标签),从而辅助我们作判断与决策。
本篇首先学习两种最基本的机器学习算法:线性回归与逻辑回归。在Python中,使用机器学习算法须导入专用的包scikit-learn,导入方式与numpy/pandas类似。
一、线性回归(Linear Regression)
1、描述相关性的参数
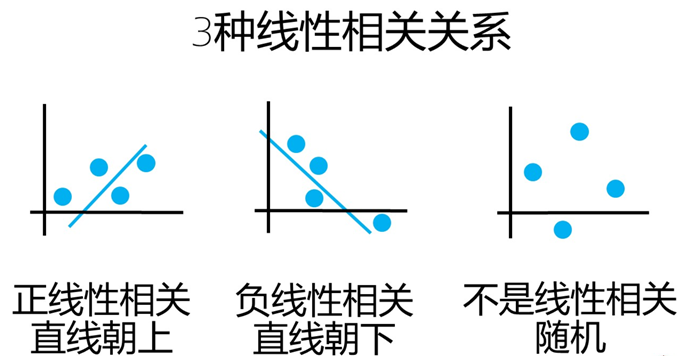
线性相关含3种关系:正相关、负相关与不相关(随机)。因此,描述相关性的参数需具备两个功能:相关方向与相关程度。比如,线性正相关时,该参数>0;线性负相关时,该参数<0。且该参数值越大,线性相关性越强。
协方差 Cov(X,Y)=E[(X−μx)(Y−μy)] 能满足上述要求。如果协方差为正,则说明X,Y同向变化,协方差值越大,说明同向程度越高;反之亦然。
但协方差有个缺点,那就是其值不仅与X,Y的相关程度有关,而且还与X,Y本身的变化幅度有关,为了把变化幅度的影响从协方差中剔除,定义了相关系数 :ρ=Cov(X,Y)σXσY 。即,X,Y的协方差除以X与Y各自的标准差,以剔除变量自身幅度的波动。
这样一来,相关系数就能专注地表征变量间的相关性了。其值范围[-1,1],1表示完全线性正相关,-1表示完全线性负相关,0表示完全不相关(随机)。
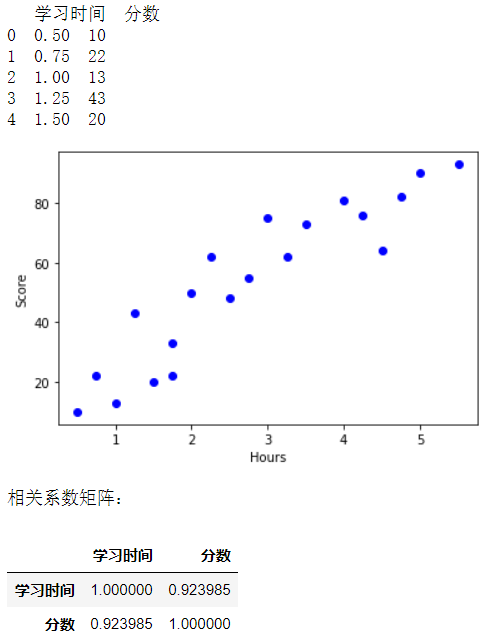
Python中可用corr()函数直接求出两个数据集之间的相关系数。如下代码,首先建立学习时间(特征)与考试分数(标签)两个数据集,然后绘制散点图,并用corr()函数求出两个数据集的相关系数约0.92。即表明,考试分数与学习时间是高度正相关的。
'''建立数据集'''
from collections import OrderedDict #导入有序字典
import pandas as pd #导入Pandas
import matplotlib.pyplot as plt #导入绘图包
#用字典生成两个数据集
examDict={
'学习时间':[0.50,0.75,1.00,1.25,1.50,1.75,1.75,2.00,2.25,
2.50,2.75,3.00,3.25,3.50,4.00,4.25,4.50,4.75,5.00,5.50],
'分数': [10, 22, 13, 43, 20, 22, 33, 50, 62,
48, 55, 75, 62, 73, 81, 76, 64, 82, 90, 93]
}
examOrderDict = OrderedDict(examDict)
examDf = pd.DataFrame(examOrderDict)
print(examDf.head())
#提取特征和标签
exam_X=examDf['学习时间']
exam_Y=examDf['分数']
#绘制特征与标签对应的散点图
plt.scatter(exam_X, exam_Y, color="b", label="exam data")
plt.xlabel("Hours")
plt.ylabel("Score")
plt.show()
#用corr函数提取两个数据集的相关系数:corr返回结果是一个数据框,存放的是相关系数矩阵
rDf=examDf.corr()
print('相关系数矩阵:')
rDf
2、线性回归算法
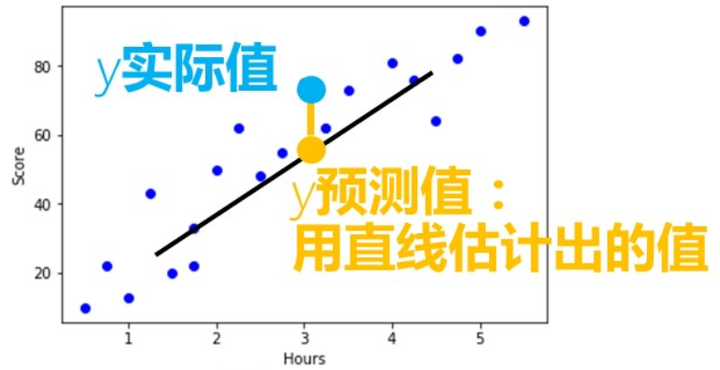
所谓线性回归,就是找一条直线方程(线性回归方程) y=a+b∗x 来模拟两数据集{x}与{y}的相关性,其中a称为截距,b称为回归系数。
线性回归的目标是,找到一条直线(即截距与回归系数),使其能尽可能多地拟合散点图中的数据点,该直线也被称为最佳拟合线。
然而,何谓“最佳拟合”?定义决定系数 R平方来评估拟合优度,决定系数越接近1,拟合越精确。的残差平方和的总平方和的实际值的预测值的实际值的均值R2=1−y的残差平方和SSEy的总平方和SST=1−Σ(y的实际值−y的预测值)2Σ(y的实际值−y的均值)2
如下代码,先从数据集中随机拆分出训练数据集与测试数据集。其中训练数据集占比80%,用于计算出最佳拟合线;余下20%为测试数据集,用于评估拟合优度(决定系数)。
'''线性回归'''
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression #导入线性回归包
#建立训练数据和测试数据
X_train , X_test , Y_train , Y_test = train_test_split(exam_X,exam_Y,train_size=0.8)
#输出数据大小
print('原始数据特征:',exam_X.shape ,
',训练数据特征:', X_train.shape ,
',测试数据特征:',X_test.shape )
print('原始数据标签:',exam_Y.shape ,
'训练数据标签:', Y_train.shape ,
'测试数据标签:' ,Y_test.shape)
#print('训练数据特征:',X_train)
#print('训练数据标签:',Y_train)
#绘制散点图
plt.scatter(X_train, Y_train, color="blue", label="train data")
plt.scatter(X_test, Y_test, color="red", label="test data")
plt.legend(loc=2)
plt.xlabel("Hours")
plt.ylabel("Score")
plt.show()

Python中可调用LinearRegression()函数建立线性回归模型,并用fit()函数计算出最佳拟合线。如上所述时间与分数的数据集,其最佳拟合直线为:
score=15.3+14.3∗hours
#创建线性回归模型
model = LinearRegression()
#sklearn要求输入的特征必须是二维数组的类型,但是因为我们目前只有1个特征,所以需要用reshape转行成二维数组的类型
X_train=X_train.values.reshape(-1,1)
X_test=X_test.values.reshape(-1,1)
#训练模型
model.fit(X_train,Y_train)
'''
最佳拟合线:z= + x
截距intercept:a
回归系数:b
'''
#截距
a=model.intercept_
#回归系数
b=model.coef_
print('最佳拟合线:截距a=',a,',回归系数b=',b)
#绘图
#训练数据散点图
plt.scatter(X_train, Y_train, color='blue', label="train data")
plt.scatter(X_test, Y_test, color='red', label="test data")
#训练数据的预测值
Y_train_pred = model.predict(X_train)
#绘制最佳拟合线
plt.plot(X_train, Y_train_pred, color='black', linewidth=3, label="best line")
plt.legend(loc=2)
plt.xlabel("Hours")
plt.ylabel("Score")
plt.show()

Python中可用score()函数直接求出拟合直线的决定系数。

二、逻辑回归(Logistic Regression)
逻辑回归是一种解决二分类问题的机器学习方法,用于估计某种情况发生的可能性。与线性回归不同,逻辑回归的标签是二分类型(0或1),比如:考试通过或未通过、西瓜甜或不甜、这首歌喜欢或不喜欢等等。下面代码以考试通过(1)或未通过(0)为标签,评估其与输入特征(学习时间)之间的相关性。
首先建立特征与标签的数据集(20组),并随机选取其中80%的数据为训练数据,余下的20%的数据为测试数据,用于评估模型预测准确性。
'''建立数据集'''
from collections import OrderedDict
from sklearn.model_selection import train_test_split
import pandas as pd
import matplotlib.pyplot as plt
#建立数据集
examDict={
'学习时间':[0.50,0.75,1.00,1.25,1.50,1.75,1.75,2.00,2.25,2.50,
2.75,3.00,3.25,3.50,4.00,4.25,4.50,4.75,5.00,5.50],
'通过考试':[0,0,0,0,0,0,1,0,1,0,1,0,1,0,1,1,1,1,1,1]
}
examOrderDict=OrderedDict(examDict)
examDf=pd.DataFrame(examOrderDict)
#examDf
#提取特征与标签
exam_X=examDf['学习时间']
exam_Y=examDf['通过考试']
#建立训练数据和测试数据,其中训练数据占比80%
X_train , X_test , Y_train , Y_test = train_test_split(exam_X,exam_Y,train_size=0.8)
#输出数据大小
print('原始数据特征:',exam_X.shape ,
',训练数据特征:', X_train.shape ,
',测试数据特征:',X_test.shape )
print('原始数据标签:',exam_Y.shape ,
'训练数据标签:', Y_train.shape ,
'测试数据标签:' ,Y_test.shape)
#散点图
plt.scatter(X_train, Y_train, color="blue", label="train data")
plt.scatter(X_test, Y_test, color="red", label="test data")
#添加图标标签
plt.legend(loc=2)
plt.xlabel("Hours")
plt.ylabel("Pass")
plt.show()

在绘制出输入特征数据与标签的散点图后,会发现一个问题:用线性回归的最佳拟合直线方法很难表征出实际的相关性。
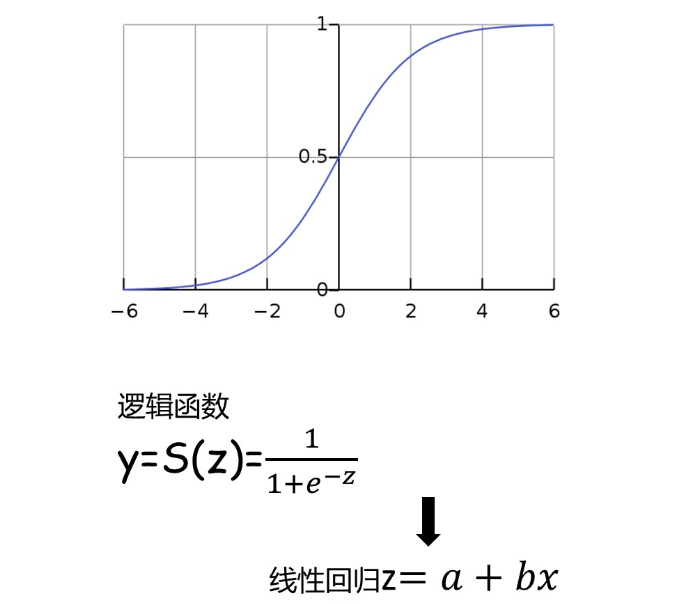
这时,便需要引入一个辅助工具:Sigmoid函数,又称逻辑函数。该函数曲线为S形,它能把一个实数(如线性回归方程)映射到(0,1)的区间,用来表示通过考试(发生1)的概率,从而巧妙地把线性回归方法与二分类问题耦合起来。
方便起见,一般以概率0.5为分类决策面。即,当Sigmoid函数返回值>0.5时,预测考试通过(输出1);反之,当Sigmoid函数返回值<0.5时,预测考试未通过(输出0)。
用Python实现逻辑回归的代码与线性回归相近,其中,可用score函数评估预测结果的正确率(0.75)。也可类似线性回归提取截距与回归系数,再代入特征数据计算相应的预测概率值(如学习时间为2小时,则考试通过的概率仅为约23%,预测考试未通过)
'''逻辑回归'''
from sklearn.linear_model import LogisticRegression #导入逻辑回归包
#数据特征转换为二维数组类型
X_train=X_train.values.reshape(-1,1)
X_test=X_test.values.reshape(-1,1)
# 创建逻辑回归
model = LogisticRegression()
#训练模型
model.fit(X_train,Y_train)
#评估模型:准确率
accuracy = model.score(X_test,Y_test)
print('模型准确率 = ',accuracy)

import numpy as np #导入Numpy包
#回归方程:z= + x,提取截距a与回归系数b
a=model.intercept_
b=model.coef_
x=2
z=a+b*x
#将z值带入逻辑回归函数中,得到概率值
y_pred=1/(1+np.exp(-z))
print('预测的概率值:',y_pred)

三、Kaggle项目实操——泰坦尼克号生存率预测
项目题目:根据数据建立泰坦尼克号上乘客生存情况(标签)的预测模型,已知数据中包含乘客的姓名、性别、年龄、登船港口与船舱号等特征信息。

合并训练数据集与待测数据集,以便统一预处理。由于导入的原始数据中存在不少缺失值,首先应按数据类型进行缺失值处理(补充或删除),生成一个完整的表格数据信息(1309行*12列)。
'''数据导入与预处理'''
#导入处理数据包
import numpy as np
import pandas as pd
###导入数据(训练数据集与测试数据集)
train = pd.read_csv('./train.csv')
test = pd.read_csv("./test.csv")
print ('训练数据集:',train.shape,'待测数据集:',test.shape)
rowNum_train = train.shape[0]
rowNum_test = test.shape[0]
full = train.append( test,ignore_index = True )
###缺失数据处理
##数值类型,用平均值取代缺失值
full['Age']=full['Age'].fillna(full['Age'].mean())
full['Fare'] = full['Fare'].fillna(full['Fare'].mean())
##分类类型,用最常见的类别取代缺失值
full['Embarked'].value_counts() #计算出频数最高的类别为'S'
full['Embarked'] = full['Embarked'].fillna( 'S' )
full['Cabin'] = full['Cabin'].fillna( 'U' ) #缺失数据比较多时,缺失值填充'U',意为Unkown
full.info()
full.head()
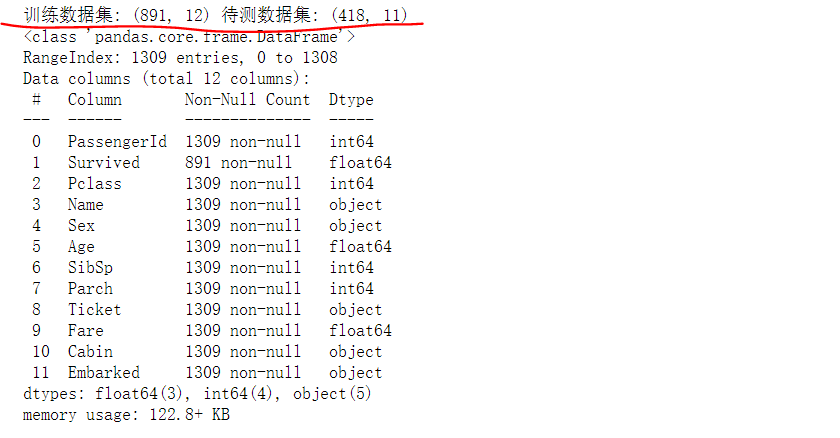

获取完整的数据后,下一步进行特征工程,即最大限度地从数据中提取特征,以供机器学习算法和模型使用。
根据不同的数据类型有不同的特征提取方法:1、数值类型(如年龄、船票价格等)可直接使用;2、分类数据(如客舱等级、登船港口等)需要通过One-hot编码转换成虚拟变量;3、字符串类型(如乘客姓名、客舱号等)需要按自定义的方法提取出其中的类别特征。

如下代码中,二分类的数据(性别)可直接用map函数映射;三种及以上类型的分类数据(登船港口与客舱等级)则需用pandas包中的get_dummies函数进行One-hot编码,生成虚拟变量。字符串类型数据,乘客姓名提取其Title作为类别特征;客舱号则提取首字母作为类别特征。最后,根据船上乘客的亲属数量,再补充了一个按家庭大中小规模为类别的特征信息。
提取完特征信息后,即可用corr()函数计算出各特征与标签之间的相关系数。
'''特征工程'''
###用数值类数据替换分类数据
##二分类别(乘客性别'Sex': 男(male)对应数值1,女(female)对应数值0)
sex_mapDict = {'male':1,'female':0}
full['Sex']=full['Sex'].map(sex_mapDict) #map函数:对Series每个数据应用自定义的函数计算
##多个类别(One-hot编码)
#登船港口:南安普顿(S)、瑟堡市(C)、昆士敦(Q)
embarkedDf = pd.DataFrame()
embarkedDf = pd.get_dummies(full['Embarked'],prefix='Embarked')
full = pd.concat([full,embarkedDf],axis=1)
full.drop('Embarked',axis=1,inplace=True)
#客舱等级:1/2/3等舱
pclassDf = pd.DataFrame()
pclassDf = pd.get_dummies( full['Pclass'],prefix='Pclass' )
full = pd.concat([full,pclassDf],axis=1)
full.drop('Pclass',axis=1,inplace=True)
###从字符串中提取类别特征
##从乘客姓名中提取出头衔类别
def getTitle(name): #提取头衔函数
str1=name.split( ',' )[1] #Mr. Owen Harris
str2=str1.split( '.' )[0] #Mr
str3=str2.strip()
return str3
titleDf = pd.DataFrame()
titleDf['Title'] = full['Name'].map(getTitle)
titleDf = pd.get_dummies(titleDf['Title']) #使用get_dummies进行one-hot编码
full = pd.concat([full,titleDf],axis=1)
full.drop('Name',axis=1,inplace=True) #添加到总矩阵中并删除原来的‘姓名’列
##从客舱号中提取首字母为类别
cabinDf = pd.DataFrame()
full[ 'Cabin' ] = full[ 'Cabin' ].map( lambda c : c[0] )
cabinDf = pd.get_dummies( full['Cabin'] , prefix = 'Cabin' )
full = pd.concat([full,cabinDf],axis=1)
full.drop('Cabin',axis=1,inplace=True)
###从家庭人数中提取类别特征
familyDf = pd.DataFrame() #存放家庭信息
familyDf[ 'FamilySize' ] = full[ 'Parch' ] + full[ 'SibSp' ] + 1
'''
家庭类别:
小家庭Family_Single:家庭人数=1
中等家庭Family_Small: 2<=家庭人数<=4
大家庭Family_Large: 家庭人数>=5
'''
familyDf[ 'Family_Single' ] = familyDf[ 'FamilySize' ].map( lambda s : 1 if s == 1 else 0 )
familyDf[ 'Family_Small' ] = familyDf[ 'FamilySize' ].map( lambda s : 1 if 2 <= s <= 4 else 0 )
familyDf[ 'Family_Large' ] = familyDf[ 'FamilySize' ].map( lambda s : 1 if 5 <= s else 0 )
full = pd.concat([full,familyDf],axis=1)
'''相关分析'''
corrDf = full.corr() #相关性矩阵
#查看各个特征与生成情况(Survived)的相关系数,并按降序排列(显示正相关性最强的8个特征)
corrDf['Survived'].sort_values(ascending=False).head(8)

选择几个相关性强的特征作为模型输入,用逻辑回归算法进行模型训练。经测试数据评估,模型预测的准确率可达约79%。
'''构建模型'''
import warnings
warnings.filterwarnings('ignore') #忽略警告提示
#按相关性大小构建一个特征数据集
full_X = pd.concat( [titleDf,#头衔
pclassDf,#客舱等级
familyDf,#家庭大小
full['Fare'],#船票价格
cabinDf,#船舱号
embarkedDf,#登船港口
full['Sex']#性别
] , axis=1 )
#full_X.head()
sourceRow=891 #原始训练数据集的行数
source_X = full_X.loc[0:sourceRow-1,:] #特征
source_Y = full.loc[0:sourceRow-1,'Survived'] #标签
pred_X = full_X.loc[sourceRow:,:] #891行以后的为待测数据集,用于预测结果提交Kaggle
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
#将原始训练数据集再随机拆分为训练数据集和测试数据集
train_X, test_X, train_Y, test_Y = train_test_split(source_X,source_Y,train_size=.8)
print ('原始数据集特征:',source_X.shape,
'训练数据集特征:',train_X.shape ,
'测试数据集特征:',test_X.shape)
print ('原始数据集标签:',source_Y.shape,
'训练数据集标签:',train_Y.shape ,
'测试数据集标签:',test_Y.shape)
#选择逻辑回归算法
model = LogisticRegression()
model.fit(train_X,train_Y)
#score函数计算模型正确率
model.score(test_X,test_Y)

最后,用该模型对待测数据集中的乘客生存情况进行预测,预测结果(.csv)上传Kaggle,项目完成。
'''方案实施'''
#使用机器学习模型,对预测数据集中的生存情况进行预测
pred_Y = model.predict(pred_X)
pred_Y = pred_Y.astype(int)
#乘客id
passenger_id = full.loc[sourceRow:,'PassengerId']
#数据框:乘客id,预测生存情况的值
predDf = pd.DataFrame(
{ 'PassengerId': passenger_id ,
'Survived': pred_Y } )
predDf.head()
