【深度学习】ONNX模型快速部署【入门】
提示:博主取舍了很多大佬的博文并亲测有效,分享笔记邀大家共同学习讨论
前言
之前的内容已经尽可能简单、详细的介绍CPU【Pytorch2ONNX】和GPU【Pytorch2ONNX】俩种模式下Pytorch模型转ONNX格式的流程,本博文根据自己的学习和需求进一步讲解ONNX模型的部署。onnx模型博主将使用PyInstaller进行打包部署,PyInstaller是一个用于将Python脚本打包成独立可执行文件的工具,在之前的python程序打包成可执行文件【入门篇】中已经进行了最基本的使用讲解。
系列学习目录:
【CPU】Pytorch模型转ONNX模型流程详解
【GPU】Pytorch模型转ONNX格式流程详解
【ONNX模型】快速部署
【ONNX模型】多线程快速部署
【ONNX模型】Opencv调用onnx
搭建打包环境
读者可以创建一个纯净的、没有多余的第三方库和模块的小型Python环境,用尽可能的少的库和模块来打包exe可执行文件。博主在GPU模式下成功将Pytorch模型转化成了ONNX模型,因此不在对转化过程再做讲解,详细内容查看前言提供的访问链接。
# name 环境名、3.x Python的版本
conda create -n deploy python==3.10
# 激活环境
activate deploy
# 安装onnx
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple onnx
# 安装GPU版
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple onnxruntime-gpu==1.15.0
# 下载安装Pyinstaller模块
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple Pyinstaller
# 根据个人情况安装包,博主这里需要安装piilow
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple Pillow
现在抛开任何pytorch相关的依赖,只使用onnx模型完成测试。
打包可执行文件
打包run.py文件成可执行文件,以下是run.py的代码内容:
import onnxruntime as ort
import numpy as np
from PIL import Image
import time
import datetime
import sys
import os
def composed_transforms(image):
mean = np.array([0.485, 0.456, 0.406]) # 均值
std = np.array([0.229, 0.224, 0.225]) # 标准差
# transforms.Resize是双线性插值
resized_image = image.resize((args['scale'], args['scale']), resample=Image.BILINEAR)
# onnx模型的输入必须是np,并且数据类型与onnx模型要求的数据类型保持一致
resized_image = np.array(resized_image)
normalized_image = (resized_image/255.0 - mean) / std
return np.round(normalized_image.astype(np.float32), 4)
def check_mkdir(dir_name):
if not os.path.exists(dir_name):
os.makedirs(dir_name)
args = {
'scale': 416,
'save_results': True
}
def main():
# 保存检测结果的地址
input = sys.argv[1]
providers = ["CUDAExecutionProvider"]
# providers = ["CPUExecutionProvider"]
ort_session = ort.InferenceSession("PFNet.onnx", providers=providers) # 创建一个推理session
input_name = ort_session.get_inputs()[0].name
print('Load {} succeed!'.format('PFNet.onnx'))
# 输出有四个
output_names = [output.name for output in ort_session.get_outputs()]
start = time.time()
time_list = []
# 图片保存位置
image_path = os.path.join(input, 'image')
# 掩码保存位置,博主这里因为是实例所以保存在同一目录下了
mask_path = os.path.join(input, 'mask')
if args['save_results']:
check_mkdir(mask_path)
img_list = [os.path.splitext(f)[0] for f in os.listdir(image_path) if f.endswith('jpg')]
for idx, img_name in enumerate(img_list):
img = Image.open(os.path.join(image_path, img_name + '.jpg')).convert('RGB')
w, h = img.size
# 对原始图像resize和归一化
img_var = composed_transforms(img)
# np的shape从[w,h,c]=>[c,w,h]
img_var = np.transpose(img_var, (2, 0, 1))
# 增加数据的维度[c,w,h]=>[bathsize,c,w,h]
img_var = np.expand_dims(img_var, axis=0)
start_each = time.time()
prediction = ort_session.run(output_names, {
input_name: img_var})
time_each = time.time() - start_each
time_list.append(time_each)
# 除去多余的bathsize维度,NumPy变会PIL同样需要变换数据类型
# *255替换pytorch的to_pil
prediction = (np.squeeze(prediction[3])*255).astype(np.uint8)
if args['save_results']:
Image.fromarray(prediction).resize((w, h))
Image.fromarray(mask).save(os.path.join(mask_path, img_name + '.jpg'))
end = time.time()
print("Total Testing Time: {}".format(str(datetime.timedelta(seconds=int(end - start)))))
if __name__ == '__main__':
main()
打包可执行文件也分cpu和gpu模式,只需要修改providers变量内容即可,二者只能选其一。
# cpu模式
providers = ["CPUExecutionProvider"]
# gpu模式
providers = ["CUDAExecutionProvider"]
- 在cpu模式下打包可执行文件:
原本是run_onnx.exe,这里博主是做了重命名,cpu模式下的占用空间比较小。pyinstaller -F run.py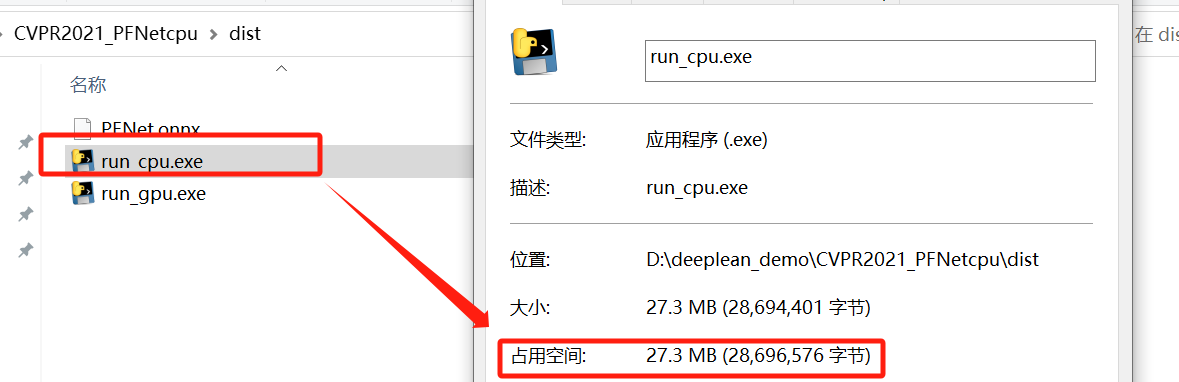
执行exe文件:将onnx权重文件与run_cpu.exe放置在一起,打开cmd,并进入run_cpu.exe执行命令。这里博主通过传递参数可以指定执行的分割的图片路径。

在指定目录下的mask文件夹内保存结果。

- 在gpu模式下打包可执行文件:
pyinstaller打包会报onnxruntime-gpu时缺少onnxruntime-cuda的动态库。使用y在打包时需要加上动态库。
–add-binar第一个是依赖库的位置,第二个是打包exe指定依赖库的位置。pyinstaller -F run.py --add-binary "D:/ProgramData/Anaconda3_data/envs/deploy/Lib/site-packages/onnxruntime/capi/onnxruntime_providers_cuda.dll;./onnxruntime/capi" --add-binary "D:/ProgramData/Anaconda3_data/envs/deploy/Lib/site-packages/onnxruntime/capi/onnxruntime_providers_shared.dll;./onnxruntime/capi"
原本是run_onnx.exe,这里博主是做了重命名,gpu模式下的占用空间比较大。
执行exe文件:

到这里整个onnx的打包过程已经结束了,补充一点,假如需要将exe迁移到其他主机,cpu版本的exe是不在需要其他额外的以来的,只需要与onnx权重文件一起使用,gpu版本的exe则需要添加额外的依赖,因为绝大部分迁移主机是不会安装cuda的,因此需要在你的cuda安装路径下拷贝出所需的依赖。
博主的cuda安装路径:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8。
在bin目录下拷贝出cudnn_ops_train64_8.dll和cudnn_cnn_infer64_8.dll文件到run_gpu.exe目录下。
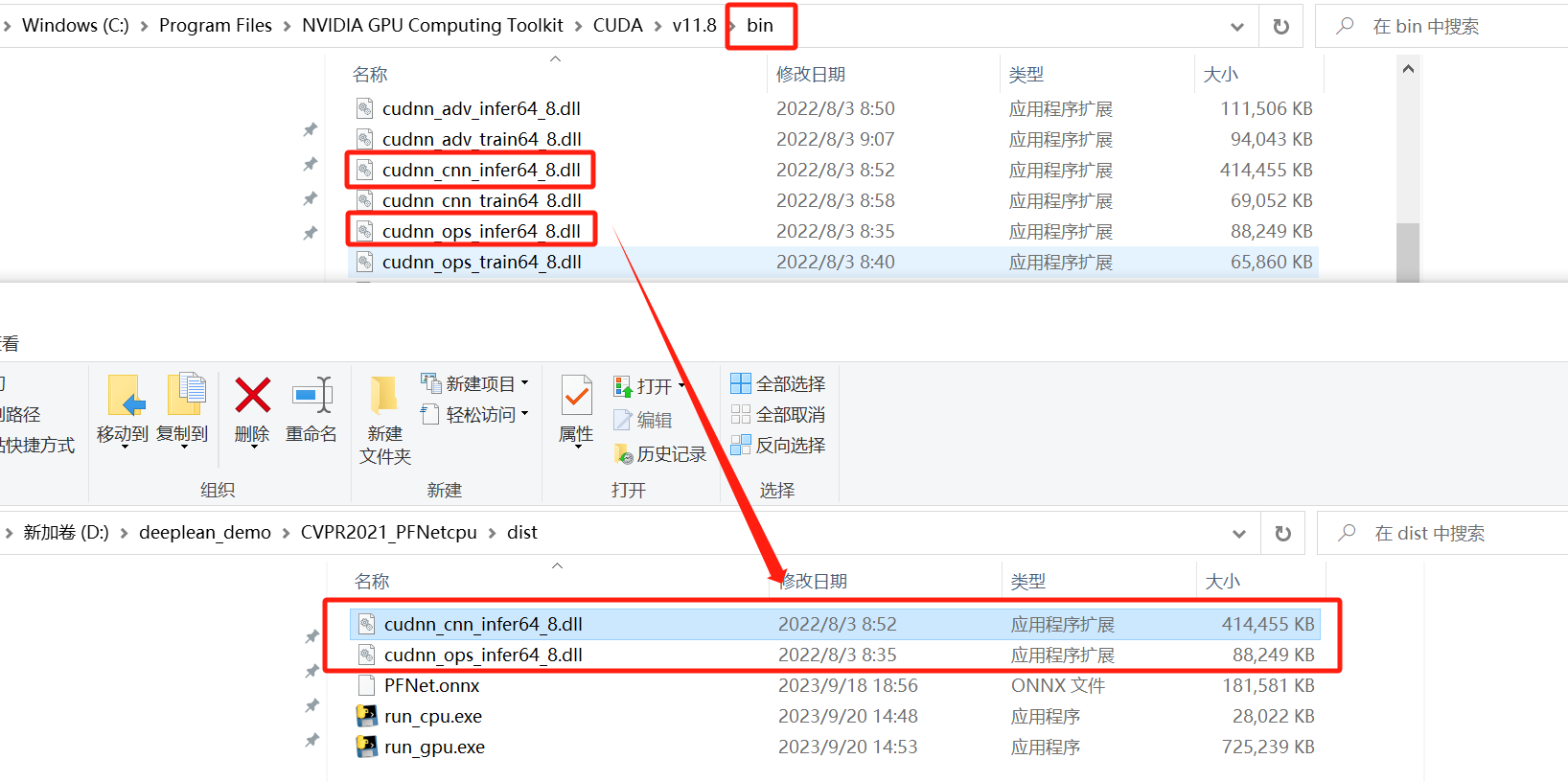
到这里就可以放心的将exe迁移到其他显卡支持cuda运算的主机上了。
总结
尽可能简单、详细的介绍ONNX模型的部署过程。