笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~
pytorch快速入门
简介
PyTorch是一个开源的机器学习框架,它提供了丰富的工具和库,用于构建和训练深度学习模型。下面是一些关于PyTorch的基本信息:
张量(Tensor)操作:PyTorch中的核心对象是张量,它是一个多维数组。PyTorch提供了广泛的张量操作函数,可以执行各种数学运算和线性代数操作。
自动微分:PyTorch使用动态图计算的方式,允许用户轻松定义和计算梯度。通过在张量上设置 requires_grad=True,可以跟踪和自动计算梯度。这使得实现反向传播算法变得简单,对于构建和训练深度学习模型非常重要。
模型构建:PyTorch提供了灵活的模型构建方式。可以通过继承 torch.nn.Module 类来定义自己的模型,并在 forward() 方法中指定前向传播的操作。这样的模型可以由多个层组成,每个层可以是全连接层、卷积层、循环神经网络等。
损失函数:PyTorch提供了多种常见的损失函数,用于评估模型输出与目标之间的差异。例如,均方误差损失函数用于回归问题,交叉熵损失函数用于分类问题。
优化器:PyTorch提供了多种优化算法的实现,如随机梯度下降(SGD)、Adam、RMSprop等。这些优化器可以用于更新模型参数,以最小化定义的损失函数。
数据加载和预处理:PyTorch提供了用于加载和处理数据的工具。可以使用 torchvision 库加载常见的图像数据集,并应用各种数据增强技术来扩充训练数据集。
分布式训练:PyTorch支持分布式训练,可以在多个GPU或多台机器上并行运行。这有助于加速训练过程,并处理更大规模的数据集和模型。
总的来说,PyTorch提供了一个灵活且易于使用的深度学习框架,使得构建、训练和部署深度学习模型变得简单和高效。它广泛应用于学术界和工业界,并得到了广大开发者的喜爱和支持。
import torch
print("pytorch版本:", torch.__version__)
输出结果为:
pytorch版本: 2.1.0+cpu
张量(Tensor)操作
数据类型:在PyTorch中,Tensor可以是多种数据类型,如float、double、int、long等。这些类型对应于不同的精度和范围。
张量操作:PyTorch提供了大量的张量操作函数,可以进行各种数学运算和线性代数操作。这些函数包括加、减、乘、除、矩阵乘法、向量点积、转置、逆矩阵等等。
自动求导:Tensor可以通过设置 requires_grad=True 来启用自动求导。这允许用户轻松定义和计算梯度,以用于反向传播算法。
Tensor形状:Tensor的形状指的是其各个维度的大小。可以通过 shape 属性来获取Tensor的形状。形状信息对于构建和训练深度学习模型非常重要。
广播机制:在进行张量运算时,如果两个张量的形状不完全相同,PyTorch会自动执行广播机制。这意味着,较小的张量将被自动扩展,以匹配较大张量的形状。
索引和切片:可以使用整数索引和切片操作来访问Tensor中的元素。此外,还可以使用布尔索引和高级索引等功能,进行更复杂的Tensor操作。
GPU加速:在支持CUDA的GPU上,PyTorch可以利用GPU加速Tensor操作,从而实现更快的计算速度。
创建张量
使用 torch.zeros() 或 torch.ones() 函数创建全零或全一张量:
zeros_tensor = torch.zeros(5, 3)
ones_tensor = torch.ones(5, 3)
使用 torch.randn() 函数创建符合标准正态分布的随机数张量:
random_tensor = torch.randn(5, 3)
使用 torch.Tensor() 创建张量:
import torch
# 从 Python 标量创建张量
scalar_tensor = torch.tensor(3.14)
print(scalar_tensor) # 输出 tensor(3.1400)
# 从 Python 列表创建张量
list_tensor = torch.tensor([1, 2, 3])
print(list_tensor) # 输出 tensor([1, 2, 3])
# 从 NumPy 数组创建张量
numpy_array = np.array([4, 5, 6])
numpy_tensor = torch.tensor(numpy_array)
print(numpy_tensor) # 输出 tensor([4, 5, 6], dtype=torch.int32)
# 创建一个指定大小的空张量
empty_tensor = torch.tensor([])
print(empty_tensor) # 输出 tensor([])
# 从其他张量创建张量
x = torch.tensor([1, 2, 3])
y = torch.tensor(x)
print(y) # 输出 tensor([1, 2, 3])
# x 和 y是两个完全独立的张量对象,它们在内存中占据不同的位置。
x[0] = 100
print(x) # tensor([100, 2, 3])
print(y) # tensor([1, 2, 3])
注意,以上三种方法都可以通过添加 .to(device) 方法将张量转移到GPU设备上(如果你的系统支持GPU加速)。
向量拷贝
torch.tensor()、tensor.clone()、tensor.detach()进行数据拷贝,新tensor和原来的数据不再共享内存。
.clone() 和 .detach() 都是用于在 PyTorch 中创建新的张量,但它们在功能和用法上有一些区别:
1..clone() 方法:
功能:.clone() 方法创建一个新的张量,该张量与原始张量具有相同的值、形状和梯度信息。
用法:通常用于需要在计算图中保留梯度信息的情况,比如进行反向传播和优化过程。
示例代码:
import torch
x = torch.tensor([1, 2, 3], requires_grad=True)
y = x.clone()
print(x) # 输出: tensor([1, 2, 3], requires_grad=True)
print(y) # 输出: tensor([1, 2, 3], grad_fn=<CloneBackward>)
在这个例子中,y 是通过 .clone() 方法从原始张量 x 创建的,它保留了 x 的梯度信息。
.detach()方法:
功能:.detach() 方法创建一个新的张量,该张量与原始张量具有相同的值和形状,但不保留任何梯度信息。
对于整数类型的张量,无法使用 requires_grad 参数。如果您需要在整数类型的张量上进行自动微分,请先将其转换为浮点数类型的张量。
用法:通常用于需要从计算图中分离出张量的梯度信息,以便在不需要梯度的情况下进行计算。
示例代码:
import torch
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
y = x.detach()
print(x) # 输出: tensor([1., 2., 3.], requires_grad=True)
print(y) # 输出: tensor([1., 2., 3.])
在这个例子中,y 是通过 .detach() 方法从原始张量 x 创建的,它不保留 x 的梯度信息。
总结区别:
.clone()创建一个新的张量,并保留原始张量的梯度信息。.detach()创建一个新的张量,并且不保留原始张量的梯度信息。
所以如果你想共享内存的话,建议使用torch.from_numpy()或者tensor.detach()来新建一个tensor, 二者共享内存。
张量维度
PyTorch 中,size() 方法返回一个元组,表示张量各个维度的大小。torch.size 是tuple对象的子类,因此它支持tuple的所有操作。
x.size()[0] 和 x.size(0) 都用于获取张量第一个维度的大小,即行数。
x.size()[1] 和 x.size(1) 都用于获取张量第二个维度的大小,即列数。
x = t.rand(5, 3)
print(x.size()) # 查看x的形状
print(x.size()[0]) # 查看行的个数
print(x.size(0)) # 查看行的个数
print(x.size()[1]) # 查看列的个数
print(x.size(1)) # 查看列的个数
输出结果为:
torch.Size([5, 3])
5
5
3
3
张量加法
在 PyTorch 中,可以使用 torch.add() 函数或者张量的 add() 方法进行张量加法。两者的功能是类似的,只是使用方式上有所区别。
- 使用
torch.add()函数
torch.add() 函数的语法如下:
torch.add(input, other, alpha=1, out=None)
其中,input 表示要进行加法运算的张量,other 表示要加到 input 上的张量,alpha 表示缩放系数,out 表示输出张量(默认为 None)。
示例代码如下:
# 创建两个张量
tensor1 = torch.tensor([[1, 2], [3, 4]])
tensor2 = torch.tensor([[5, 6], [7, 8]])
# 使用 torch.add() 进行张量加法
result = torch.add(tensor1, tensor2)
print(result)
输出结果为:
tensor([[ 6, 8],
[10, 12]])
在这个例子中,创建了两个 2x2 的张量 tensor1 和 tensor2,然后使用 torch.add() 函数对它们进行了加法运算,结果存储在 result 张量中。
- 使用张量的
add()方法
张量的 add() 方法的语法如下:
add(other, alpha=1, out=None) -> Tensor
其中,other 表示要加到当前张量上的张量,alpha 表示缩放系数,out 表示输出张量(默认为 None)。
示例代码如下:
import torch
# 创建两个张量
tensor1 = torch.tensor([[1, 2], [3, 4]])
tensor2 = torch.tensor([[5, 6], [7, 8]])
# 使用张量的 add() 方法进行张量加法
result = tensor1.add(tensor2)
print(result)
运行结果与使用 torch.add() 函数的结果相同:
tensor([[ 6, 8],
[10, 12]])
在这个例子中,首先创建了两个 2x2 的张量 tensor1 和 tensor2,然后使用 tensor1.add(tensor2) 进行了加法运算,结果存储在 result 张量中。
需要注意的是,add 方法并不会修改当前张量,而是返回一个新的张量。如果需要就地修改当前张量,可以使用 add_ 方法。例如:
import torch
# 创建一个张量
tensor = torch.tensor([[1, 2], [3, 4]])
# 就地修改
tensor.add_(2)
print(tensor)
输出结果为:
tensor([[3, 4],
[5, 6]])
函数名后面带下划线 _ 的函数
在 PyTorch 中,函数名后面带下划线 _ 的函数通常表示就地(in-place)操作,这些函数会直接修改调用它们的张量本身,而不会创建新的张量。
就地操作可以节省内存空间,尤其在处理大规模数据时非常有用。然而,需要注意的是,这些就地操作会改变原始张量,因此在使用时需要小心,确保不会意外修改到原始数据。
以下是一些常见的就地操作的示例:
import torch
# 创建一个张量
tensor = torch.tensor([1, 2, 3])
# 就地加法操作
tensor.add_(1)
print(tensor) # 输出 tensor([2, 3, 4])
# 就地乘法操作
tensor.mul_(2)
print(tensor) # 输出 tensor([4, 6, 8])
# 就地取负操作
tensor.neg_()
print(tensor) # 输出 tensor([-4, -6, -8])
需要注意的是,就地操作的命名规范是以下划线结尾的函数名,例如 add_()、mul_() 和 neg_()。这些函数在执行完操作后,会直接修改原始张量,而不返回新的张量。
在使用就地操作时,请注意以下几点:
- 原始张量的值会被修改,可能会对后续计算产生影响。
- 就地操作不会创建新的张量,因此不能使用赋值操作(例如
tensor = tensor.add_(1)),否则会导致变量引用发生变化。 - 就地操作只能用于可就地修改的张量类型,例如浮点型张量和整数型张量。对于不可变的张量类型(如
torch.Tensor)或自动求导的张量(如torch.autograd.Variable),就地操作是不允许的。
索引和切片
在 PyTorch 中,可以使用索引和切片操作来选择张量中的特定元素、子集或者某个维度上的切片。这些操作使得你可以根据需要获取张量的部分数据,进行进一步的处理或分析。
下面是一些常见的张量选取操作示例:
- 使用索引选择单个元素
import torch
# 创建一个张量
tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])
# 使用索引选取单个元素
element = tensor[0, 1]
print(element) # 输出 tensor(2)
在这个例子中,我们创建了一个 2x3 的张量 tensor,然后使用索引 0, 1 来选择第一行、第二列的元素,即 2。
- 切片操作选择子集
import torch
# 创建一个张量
tensor = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 使用切片操作选择子集
# 选取张量 tensor 中第 2 行到第 3 行(不包括第 3 行),以及第 1 列到第 2 列(不包括第 2 列)的所有元素。
subset = tensor[1:3, 0:2]
print(subset)
输出结果为:
tensor([[4, 5],
[7, 8]])
在这个例子中,我们创建了一个 3x3 的张量 tensor,然后使用切片操作选择了第二行和第三行的前两列,即子集 [[4, 5], [7, 8]]。
- 使用布尔索引选择满足条件的元素
import torch
# 创建一个张量
tensor = torch.tensor([1, 2, 3, 4, 5, 6])
# 使用布尔索引选择满足条件的元素
selected_elements = tensor[tensor > 3]
print(selected_elements)
输出结果为:
tensor([4, 5, 6])
在这个例子中,我们创建了一个包含整数的张量 tensor,然后使用布尔索引 tensor > 3 来选择大于 3 的元素,即满足条件的元素 [4, 5, 6]。
除了上述示例外,还可以使用其他高级的选取操作,如使用 torch.where() 函数、使用 torch.masked_select() 函数等。这些操作可以根据特定的需求进行更复杂的数据选择和过滤。
Tensor和Numpy的数组之间的转换
.numpy()方法将张量(Tensor)转换为NumPy数组,进行一些NumPy支持的操作。
torch.from_numpy()方法将NumPy数组转换回PyTorch张量。
以下是一个示例:
import torch
import numpy as np
# 创建一个PyTorch张量
tensor = torch.tensor([1, 2, 3, 4, 5])
# 将PyTorch张量转换为NumPy数组
array = tensor.numpy()
print(array) # 输出 [1, 2, 3, 4, 5]
# 使用NumPy数组进行操作
array = np.square(array)
print(array) # 输出 [1, 4, 9, 16, 25]
# 将NumPy数组转换回PyTorch张量
tensor = torch.from_numpy(array)
print(tensor) # 输出 tensor([1, 4, 9, 16, 25])
- 创建了一个PyTorch张量
tensor - 使用
.numpy()方法将其转换为NumPy数组array。 - 对NumPy数组进行了一些操作(计算了每个元素的平方),并将结果存储回了
array。 - 使用
torch.from_numpy()方法将NumPy数组array转换回PyTorch张量tensor。
需要注意的是,通过将张量转换为NumPy数组进行处理可能会导致一些性能上的损失,因为NumPy数组和PyTorch张量使用不同的底层实现。因此,在进行转换前后需要权衡性能和功能需求。
Tensor和numpy对象共享内存
# 改变NumPy数组的值
array[0] = 100
print(array) # 输出 [100 4 9 16 25]
# 查看PyTorch张量的值
print(tensor) # 输出 tensor([100, 4, 9, 16, 25])
如果需要避免共享内存带来的问题,可以使用.clone()方法来创建副本,以确保两个对象之间没有共享的内存。
张量(tensor)与标量(scalar)
在PyTorch中,标量是零维张量,也就是不包含任何轴的张量。可以直接使用Python的标量数据类型,如整数或浮点数
以下是几种创建标量的示例:
import torch
# 创建一个零维张量
scalar_tensor = torch.tensor(5)
print(scalar_tensor) # 输出 tensor(5)
print(scalar_tensor.shape) # 输出 torch.Size([])
# 创建一个一维张量
vector_tensor = torch.tensor([5])
print(vector_tensor) # 输出 tensor([5])
print(vector_tensor.shape) # 输出 torch.Size([1])
# 直接使用Python的标量数据类型
scalar_value = 5
print(scalar_value) # 输出 5
print(type(scalar_value)) # 输出 <class 'int'>
scalar.item与tensor[idx]
scalar.item可以获取某一个元素的值
tensor[idx]得到的还是一个tensor: 一个0-dim的tensor,一般称为scalar
import torch
scalar_tensor = torch.tensor([5])
print(scalar_tensor) # 输出 tensor([5])
print(scalar_tensor.shape) #输出 torch.Size([1])
tensor_value = scalar_tensor[0]
print(scalar_value) # 输出 tensor(5)
scalar_value = scalar_tensor.item()
print(scalar_value) # 输出 5
自动微分Autograd(Automatic differentiation)
Autograd(Automatic differentiation)是PyTorch中的一个自动微分引擎,用于计算和追踪张量上的导数。Autograd使得在神经网络训练中进行反向传播及计算梯度变得相对简单。
在PyTorch中,每个张量都有一个 requires_grad 属性,用于指定是否要对该张量进行梯度计算。当设置 requires_grad=True 时,PyTorch会跟踪针对该张量的所有操作,并构建一个计算图(computational graph)。这个计算图可以用于自动计算后向传播(backpropagation)和计算梯度。
当完成前向传播(forward pass)后,可以通过调用 backward() 方法自动计算梯度。此时,对于具有 requires_grad=True 的张量,它们将具有一个 .grad 属性,其中包含了相对于某个标量损失函数的梯度。该梯度可以用于更新模型参数,在训练过程中优化模型。
使用 PyTorch 进行自动求导简单示例:
import torch
# 创建张量并设置 requires_grad=True
x = torch.tensor(3.0, requires_grad=True)
y = torch.tensor(4.0, requires_grad=True)
# 执行一些操作
z = x ** 2 + y ** 3
# 计算 z 相对于 x 和 y 的梯度
z.backward()
# 输出梯度值
print(x.grad) # 输出: tensor(6.)
print(y.grad) # 输出: tensor(48.)
创建了两个张量 x 和 y,并将 requires_grad 属性设置为 True,以便自动求导。
定义了一个计算 z = x ** 2 + y ** 3 的操作,并调用 backward() 方法计算梯度。
通过 grad 属性获取 x 和 y 相对于 z 的梯度值。
需要注意的是,自动求导仅适用于标量(scalar)张量。如果要计算向量或矩阵相对于张量的导数,可以使用 Jacobian 矩阵的方法。此外,为了避免梯度计算造成的内存泄漏,可以使用 torch.no_grad() 上下文管理器来禁用梯度计算。
.grad 属性
.grad 属性是在 PyTorch 中用于访问张量的梯度值的属性
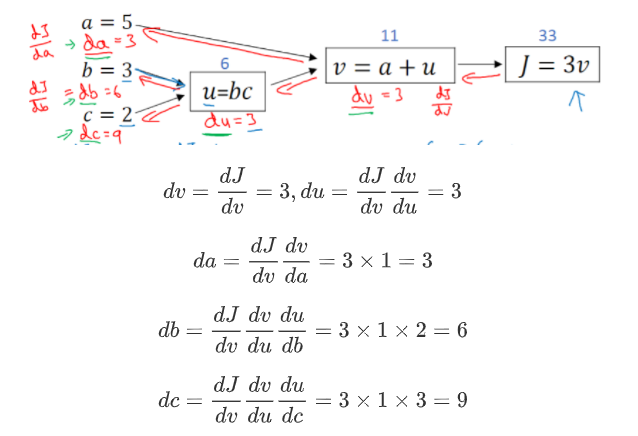
import torch
# 创建张量并设置 requires_grad=True
a = torch.tensor(5.0, requires_grad=True)
b = torch.tensor(3.0, requires_grad=True)
c = torch.tensor(2.0, requires_grad=True)
u = b*c
v = a+u
j = 3*v
# 执行反向传播计算梯度
j.backward()
# 输出梯度值
print(a.grad) # 输出: tensor(3.)
print(b.grad) # 输出: tensor(6.)
print(c.grad) # 输出: tensor(9.)
- 创建了张量并将
requires_grad属性设置为True,以便自动求导。 - 定义了一些计算操作,并通过调用
.backward()方法执行反向传播计算梯度。 - 通过
.grad属性获取张量相对于j的梯度值。
.grad_fn属性
在 PyTorch 中,每个张量都有一个 grad_fn 属性,用于表示创建该张量的操作(或函数),也就是反向传播时需要调用的函数。这个属性可以用来构建计算图和执行自动微分。
下面是一个简单的示例,展示了如何使用 grad_fn 属性:
import torch
# 创建一个张量并执行一些操作
x = torch.tensor(2.0, requires_grad=True)
y = x ** 2 + 3
z = y ** 2
# 输出每个张量的 grad_fn 属性
print(x.grad_fn) # 输出: None
print(y.grad_fn) # 输出: <AddBackward0 object at 0x7f3e8bd82b10>
print(z.grad_fn) # 输出: <PowBackward0 object at 0x7f3e8bd82b10>
在这个例子中,我们创建了一个张量 x 并将 requires_grad 属性设置为 True,以便自动求导。然后,我们定义了一些计算操作,并输出了每个张量的 grad_fn 属性。
需要注意的是,只有在张量是通过某个操作创建时,它才有一个 grad_fn 属性。对于手动创建的张量,如普通的 Python 数组或通过 torch.tensor() 创建的张量,它们的 grad_fn 属性是 None。
模型构建
PyTorch提供了灵活的模型构建方式。可以通过继承 torch.nn.Module 类来定义自己的模型,并在 forward() 方法中指定前向传播的操作。这样的模型可以由多个层组成,每个层可以是全连接层、卷积层、循环神经网络等。
1.导入 PyTorch 库和相关的包
import torch
import torch.nn as nn
import torch.optim as optim
2.定义模型类(继承自 nn.Module)
class MyModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
在这个示例中,我们定义了一个名为 MyModel 的类,继承自 nn.Module。该模型具有两个全连接层和一个 ReLU 激活函数。__init__ 方法用于初始化模型的权重和偏置,而 forward 方法则定义了模型的正向传播过程。
这段代码定义了一个简单的神经网络模型 MyModel,它有三个层:一个输入层、一个隐藏层和一个输出层。
在 __init__ 方法中,模型的结构定义如下:
self.fc1 = nn.Linear(input_size, hidden_size):这一行创建了一个线性层(全连接层),将输入特征的维度为input_size转换为隐藏层特征的维度为hidden_size。self.relu = nn.ReLU():这一行创建了一个 ReLU 激活函数对象,用于在隐藏层后面引入非线性变换。self.fc2 = nn.Linear(hidden_size, output_size):这一行创建了第二个线性层,将隐藏层特征的维度为hidden_size转换为输出特征的维度为output_size。
在 forward 方法中,模型的前向传播过程定义如下:
out = self.fc1(x):首先,输入x通过第一个线性层self.fc1进行线性变换。out = self.relu(out):然后,通过 ReLU 激活函数self.relu进行非线性变换。out = self.fc2(out):最后,将变换后的特征再次通过第二个线性层self.fc2进行线性变换得到最终的输出。
整个模型的结构可以总结为:
输入层(input_size) -> 隐藏层(hidden_size) -> ReLU 激活函数 -> 输出层(output_size)
这个模型可以用于各种任务,如分类、回归等。在训练过程中,我们可以通过定义损失函数和优化算法来最小化模型的预测与真实值之间的差距,以达到训练模型的目的。
损失函数
PyTorch 中的损失函数模块 torch.nn 包含了许多常用的损失函数,如均方误差损失(MSELoss)、交叉熵损失(CrossEntropyLoss)等等。这些损失函数可以帮助我们度量模型预测值与真实值之间的差距,是深度学习中一个重要的组成部分。
以下是一些常见的损失函数及其用法示例:
-
均方误差损失(MSELoss):
criterion = nn.MSELoss() loss = criterion(output, target)在这个示例中,
output是模型的输出值,target是真实值,criterion是一个 MSELoss 损失函数对象,loss就是模型预测值与真实值之间的 MSE 损失值。 -
交叉熵损失(CrossEntropyLoss):
criterion = nn.CrossEntropyLoss() loss = criterion(output, target)在这个示例中,
output是模型的输出值,target是真实值标签,criterion是一个 CrossEntropyLoss 损失函数对象,loss就是模型预测值与真实值之间的交叉熵损失值。 -
KL 散度损失(KLDivLoss):
criterion = nn.KLDivLoss() loss = criterion(output.log(), target)在这个示例中,
output是模型的输出值,target是真实值,criterion是一个 KLDivLoss 损失函数对象,loss就是 KL 散度损失值。
损失函数的使用通常包括以下几个步骤:
- 定义损失函数:选择一个合适的损失函数,并将其实例化。
- 在每个训练迭代中,通过调用损失函数计算模型输出值与真实值之间的差距,并得到相应的损失值。
- 调用反向传播算法
backward()计算损失关于模型参数的梯度。
下面是一个完整的示例代码,演示了如何使用 MSELoss 进行模型训练:
import torch
import torch.nn as nn
# 定义模型
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
out = self.fc(x)
return out
# 实例化模型和损失函数
model = MyModel()
criterion = nn.MSELoss()
# 模拟数据
inputs = torch.randn(100, 10)
labels = torch.randn(100, 1)
# 训练模型
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(10):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print('Epoch:', epoch+1, 'Loss:', loss.item())
输出结果为:
Epoch: 1 Loss: 1.7458306550979614
Epoch: 2 Loss: 1.722163438796997
Epoch: 3 Loss: 1.6993693113327026
Epoch: 4 Loss: 1.6774134635925293
Epoch: 5 Loss: 1.6562625169754028
Epoch: 6 Loss: 1.6358848810195923
Epoch: 7 Loss: 1.6162495613098145
Epoch: 8 Loss: 1.5973275899887085
Epoch: 9 Loss: 1.579091191291809
Epoch: 10 Loss: 1.561513066291809
这段代码是一个使用 PyTorch 进行模型训练的示例。
- 定义了一个简单的线性模型
MyModel,它包含一个线性层self.fc = nn.Linear(10, 1)。这个模型将输入大小为 10 的张量映射到一个大小为 1 的输出张量。 - 实例化了这个模型和一个均方误差损失函数
MSELoss,即criterion = nn.MSELoss()。 - 生成了一个大小为 (100, 10) 的输入张量
inputs和一个大小为 (100, 1) 的标签张量labels,用于模拟训练数据。 - 使用随机梯度下降优化器
SGD,即optimizer = torch.optim.SGD(model.parameters(), lr=0.01),设置学习率为 0.01。 - 进行了 10 个训练迭代的循环。在每个迭代中:
- 调用
optimizer.zero_grad()来清零之前的梯度。 - 通过将输入张量
inputs传入模型model,得到输出张量outputs。 - 使用损失函数
criterion计算预测值outputs与真实值labels之间的均方误差损失,并将其保存在变量loss中。 - 调用
loss.backward()来执行反向传播计算梯度。 - 调用
optimizer.step()来更新模型参数,使其朝着更优的方向进行调整。
- 调用
- 在每个训练迭代中,打印出当前迭代的 epoch 数和损失值
loss.item()。
优化器
PyTorch 提供了多种优化器,用于在训练深度学习模型时更新模型的参数。以下是几个常见的 PyTorch 优化器:
1.SGD(随机梯度下降法)
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
这是最基本的优化器之一,使用随机梯度下降法来更新模型的参数。model.parameters() 返回模型中的可学习参数,lr 是学习率。
2.Adam(自适应矩估计)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
Adam 是一种自适应学习率优化算法,结合了动量法和 RMSprop。它可以根据每个参数的梯度自适应地调整学习率。
3.Adagrad
optimizer = optim.Adagrad(model.parameters(), lr=learning_rate)
Adagrad 是一种自适应学习率优化算法,该算法会为每个参数维护一个学习率,随着训练的进行,会针对每个参数降低学习率。
4.RMSprop(均方根传播)
optimizer = optim.RMSprop(model.parameters(), lr=learning_rate)
RMSprop 是一种自适应学习率优化算法,它使用梯度的均方根来调整学习率。
5.Adadelta
optimizer = optim.Adadelta(model.parameters(), lr=learning_rate)
Adadelta 是一种自适应学习率优化算法,它根据过去的梯度和参数更新的幅度来调整学习率。
这些优化器都可以通过调用 optimizer.step() 来更新模型的参数。在每个训练迭代中,通常会先调用 optimizer.zero_grad() 来清零之前的梯度,然后进行正向传播、计算损失、反向传播、计算梯度和参数更新的过程。
选择合适的优化器取决于具体的任务和数据集。一般来说,Adam 优化器在很多情况下表现良好,但在某些问题上可能需要尝试不同的优化器来获得更好的性能。此外,还可以调整学习率、设置动量等超参数来进一步改进优化器的性能。
数据加载和预处理
在 PyTorch 中,数据加载和预处理通常通过自定义数据集类和数据转换函数来完成。下面是一般的数据加载和预处理的步骤:
- 创建自定义数据集类: 首先,你需要创建一个自定义的数据集类,继承自
torch.utils.data.Dataset。在该类中,你需要实现__len__方法返回数据集的大小,以及__getitem__方法根据给定的索引返回单个样本。 - 数据转换: 数据转换是对原始数据进行预处理的过程。你可以使用
torchvision.transforms模块提供的转换函数,如Compose、ToTensor、Normalize等。这些函数可以将原始数据转换为张量,并进行标准化、裁剪、缩放等操作。 - 创建数据集实例: 使用上述自定义数据集类和转换函数创建数据集实例。传入数据集的路径、标签等信息,根据需要应用相应的数据转换。
- 创建数据加载器: 数据加载器负责将数据集分成小批次进行训练。你可以使用
torch.utils.data.DataLoader类创建数据加载器,传入数据集实例和一些参数,如批次大小、是否随机打乱数据等。
下面是一个示例代码,演示了如何加载和预处理数据:
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
# 自定义数据集类
class MyDataset(Dataset):
def __init__(self, data, labels, transform=None):
self.data = data
self.labels = labels
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, index):
sample = self.data[index]
label = self.labels[index]
if self.transform:
sample = self.transform(sample)
return sample, label
# 数据转换
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
# 创建数据集实例
data = [...] # 原始数据
labels = [...] # 标签
dataset = MyDataset(data, labels, transform=transform)
# 创建数据加载器
batch_size = 64
shuffle = True
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=shuffle)
在上述示例中,我们创建了一个自定义数据集类 MyDataset,并传入原始数据、标签和数据转换函数 transform。然后,我们使用 DataLoader 创建数据加载器 dataloader,设置批次大小为 64,并指定是否随机打乱数据。