做深度学习神经网络的设计、训练与部署,往往会困扰于不同的操作系统,不同的深度学习框架,不同的部署硬件,以及不同的版本。由于相互之间的不兼容,给开发使用者造成了很大的不便。
联合使用OpenVINO和ONNX,便可以解决从不同框架模型到不同硬件之间快速部署的问题。
最近参加“英特尔®OpenVINO™领航者联盟 DFRobot行业AI开发者大赛”活动,主办方提供了拿铁熊猫LattePanda和Intel神经计算棒NCS2,本文所列数据都是在该平台上运行得到的。
硬件1:拿铁熊猫LattePanda Delta
采用了 Intel 全新 N 系列赛扬 4 核处理器,最高可达 2.40 GHz,4GB内存,内置蓝牙和 WiFi 模组,支持 USB 3.0 接口、HDMI 视频输出、3.5mm音频接口,100/1000Mbps 以太网口,以及额外的 MicroSD 扩展卡槽。集成一块 Arduino Leonardo 单片机,可以外拓各种传感器模块,支持 Windows 和 Linux 双操作系统。在功能和价格上都是完美的选择。
硬件2:Intel神经计算棒NCS2
Intel® Movidius™ Myriad™ X VPU核心,USB 3.1 Type-A接口,支持TensorFlow, Caffe, MXNet, ONNX, PyTorch/ PaddlePaddle(通过ONNX)。
软件环境:OpenVINO,Ubuntu, Windows® 10
先来一张硬件合照,确实是小巧,接上鼠标、键盘、显示器,连上USB摄像头和蓝牙音箱,我们来看看这台巴掌大的电脑性能怎么样!

为什么选择ONNX和OpenVINO?
Open Neural Network Exchange(ONNX,开放神经网络交换),是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架(如Pytorch, MXNet)可以采用相同格式存储模型数据并交互。
ONNX的规范及代码主要由微软,亚马逊 ,Facebook 和 IBM 等公司共同开发,以开放源代码的方式托管在Github上。目前官方支持加载ONNX模型并进行推理的深度学习框架有: Caffe2, PyTorch, MXNet,ML.NET,TensorRT 和 Microsoft CNTK,并且 TensorFlow 也非官方的支持ONNX。---维基百科
OpenVINO是英特尔推出一套基于深度学习的计算机视觉加速优化框架,支持其它机器学习平台模型的压缩优化、加速计算等功能。主要包括两个核心组件一个预训练模型库:
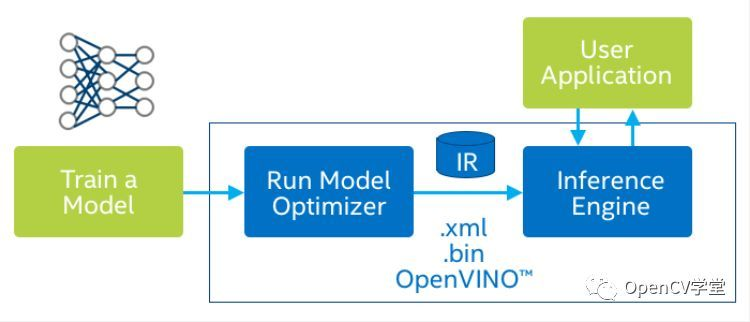
OpenVINO核心组件-模型优化器
模型优化器Model Optimizer,模型优化器支持的深度学习框架包括:
-ONNX -TensorFlow -Caffe -MXNet
OpenVINO核心组件-推断引擎
推断引擎(Inference Engine)支持硬件指令集层面的深度学习模型加速运行,同时对传统的OpenCV图像处理库也进行了指令集优化,有显著的性能与速度提升。支持的硬件平台包括如下:
-CPU -GPU -FPGA -MYRIAD(英特尔加速计算棒) -HDDL -GAN
ONNX便是一种通用货币,开发者可以把自己开发训练好的模型保存为ONNX文件;而部署工程师可以借助OpenVINO,把ONNX部署在不同的硬件平台上,而不必关心开发者使用的是哪一种框架。
所以,只要你的模型可以转为ONNX模型,而ONNX模型又可以通过OpenVINO高效、快速地部署在Intel的CPU、GPU、神经计算棒、甚至是FPGA上,使你的模型开发、训练与部署可以分开,又不必受到不同软硬件开发环境的困扰,大大提高部署实现的效率。
如何使用OpenVINO部署ONNX模型
首先,你需要安装OpenVINO,
我使用的是最新版的OpenVINO 2020.4,具体安装设置,请参考如下链接:https://docs.openvinotoolkit.org/2020.4/index.html
然后,你需要有一个ONNX模型。
你可以下载别人训练好的公开的ONNX文件,也可以从别的框架模型转化,当然也可以自己训练,然后保存为ONNX格式。本文选择自己训练。
我采用mnist手写数据集与印刷体混合的数据集,构建卷积神经网络,进行训练,达到精度96.4%,将训练结果保存为ONNX模型:
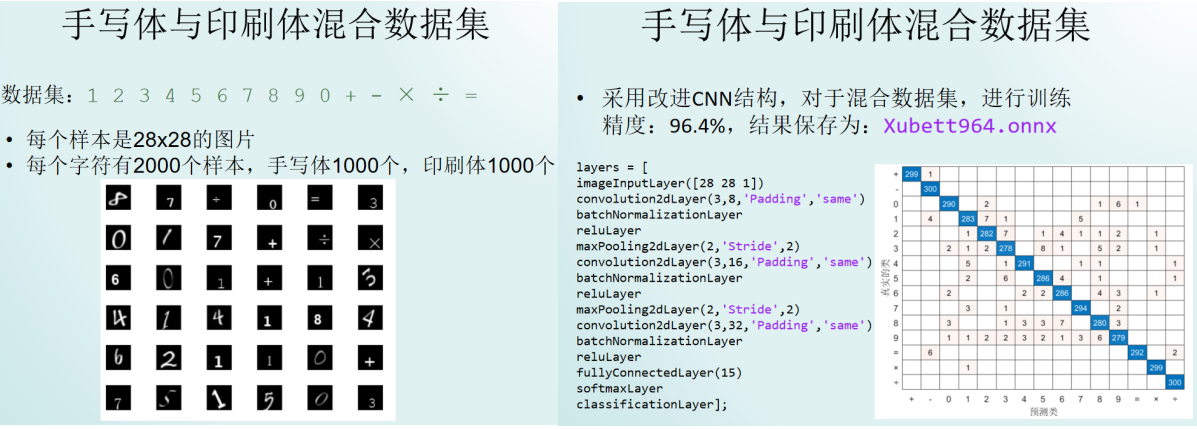
使用mo.py对ONNX模型进行优化:
命令如下:
python "C:\Program Files (x86)\IntelSWTools\openvino\deployment_tools\model_optimizer\mo.py" --input_model=Xubett964.onnx --output_dir=. --model_name=Xubett964.fp16 --data_type=FP16
Model Optimizer arguments:
Common parameters:
- Path to the Input Model: C:\openVINOdemo\shuatiP\Xubett964.onnx
- Path for generated IR: C:\openVINOdemo\shuatiP\.
- IR output name: Xubett964.fp16
- Log level: ERROR
- Batch: Not specified, inherited from the model
- Input layers: Not specified, inherited from the model
- Output layers: Not specified, inherited from the model
- Input shapes: Not specified, inherited from the model
- Mean values: Not specified
- Scale values: Not specified
- Scale factor: Not specified
- Precision of IR: FP16
- Enable fusing: True
- Enable grouped convolutions fusing: True
- Move mean values to preprocess section: False
- Reverse input channels: False
ONNX specific parameters:
Model Optimizer version:
[ SUCCESS ] Generated IR version 10 model.
[ SUCCESS ] XML file: C:\openVINOdemo\shuatiP\.\Xubett964.fp16.xml
[ SUCCESS ] BIN file: C:\openVINOdemo\shuatiP\.\Xubett964.fp16.bin
[ SUCCESS ] Total execution time: 11.34 seconds.
使用benchmark_app.py对上述模型进行评估:
可以更换参数,-d GPU, -d MYRIAD,对GPU和神经计算棒运行情况进行评估。命令如下:
python "C:\Program Files (x86)\IntelSWTools\openvino\deployment_tools\tools\benchmark_tool\benchmark_app.py" -m Xubett964.fp16.xml -i images\image1.png -d CPU
[Step 1/11] Parsing and validating input arguments
C:\Program Files (x86)\IntelSWTools\openvino\python\python3.6\openvino\tools\benchmark\main.py:29: DeprecationWarning: The 'warn' method is deprecated, use 'warning' instead
logger.warn(" -nstreams default value is determined automatically for a device. "
[ WARNING ] -nstreams default value is determined automatically for a device. Although the automatic selection usually provides a reasonable performance, but it still may be non-optimal for some cases, for more information look at README.
[Step 2/11] Loading Inference Engine
[ INFO ] InferenceEngine:
API version............. 2.1.2020.4.0-359-21e092122f4-releases/2020/4
[ INFO ] Device info
CPU
MKLDNNPlugin............ version 2.1
Build................... 2020.4.0-359-21e092122f4-releases/2020/4
[Step 3/11] Setting device configuration
[ WARNING ] -nstreams default value is determined automatically for CPU device. Although the automatic selection usually provides a reasonable performance,but it still may be non-optimal for some cases, for more information look at README.
[Step 4/11] Reading the Intermediate Representation network
[ INFO ] Read network took 31.25 ms
[Step 5/11] Resizing network to match image sizes and given batch
[ INFO ] Network batch size: 1
[Step 6/11] Configuring input of the model
[Step 7/11] Loading the model to the device
[ INFO ] Load network took 147.20 ms
[Step 8/11] Setting optimal runtime parameters
[Step 9/11] Creating infer requests and filling input blobs with images
[ INFO ] Network input 'imageinput' precision FP32, dimensions (NCHW): 1 1 28 28
C:\Program Files (x86)\IntelSWTools\openvino\python\python3.6\openvino\tools\benchmark\utils\inputs_filling.py:76: DeprecationWarning: The 'warn' method is deprecated, use 'warning' instead
",".join(BINARY_EXTENSIONS)))
[ WARNING ] No supported binary inputs found! Please check your file extensions: BIN
[ WARNING ] Some image input files will be ignored: only 0 files are required from 1
[ INFO ] Infer Request 0 filling
[ INFO ] Fill input 'imageinput' with random values (some binary data is expected)
[ INFO ] Infer Request 1 filling
[ INFO ] Fill input 'imageinput' with random values (some binary data is expected)
[ INFO ] Infer Request 2 filling
[ INFO ] Fill input 'imageinput' with random values (some binary data is expected)
[ INFO ] Infer Request 3 filling
[ INFO ] Fill input 'imageinput' with random values (some binary data is expected)
[Step 10/11] Measuring performance (Start inference asyncronously, 4 inference requests using 4 streams for CPU, limits: 60000 ms duration)
[Step 11/11] Dumping statistics report
Count: 768280 iterations
Duration: 60002.68 ms
Latency: 0.28 ms
Throughput: 12804.09 FPS
编写程序做推理验证
可以参考OpenVINO自带例子,Python的例子在下面的路径:
C:\Program Files (x86)\IntelSWTools\openvino\inference_engine\samples\python
也可以参考我的代码。
#导入IE/OpenCV/numpy/time模块
from openvino.inference_engine import IECore, IENetwork
import cv2
import numpy as np
from time import time
#配置推断计算设备,IR文件路径,图片路径
DEVICE = 'MYRIAD'
#DEVICE = 'CPU'
model_xml = 'C:/openVINOdemo/shuatiP/Xubett964.fp16.xml'
model_bin = 'C:/openVINOdemo/shuatiP/Xubett964.fp16.bin'
image_file = 'C:/openVINOdemo/shuatiP/images/image5.png'
labels_map = ["+", "-", "0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "=", "×", "÷"]
#初始化插件,输出插件版本号
ie = IECore()
ver = ie.get_versions(DEVICE)[DEVICE]
print("{descr}: {maj}.{min}.{num}".format(descr=ver.description, maj=ver.major, min=ver.minor, num=ver.build_number))
#读取IR模型文件
net = ie.read_network(model=model_xml, weights=model_bin)
#准备输入输出张量
print("Preparing input blobs")
input_blob = next(iter(net.inputs))
out_blob = next(iter(net.outputs))
net.batch_size = 1
#载入模型到AI推断计算设备
print("Loading IR to the plugin...")
exec_net = ie.load_network(network=net, num_requests=1, device_name=DEVICE)
#读入图片
n, c, h, w = net.inputs[input_blob].shape
image = cv2.imread(image_file,0)
#执行推断计算
print("Starting inference in synchronous mode")
start = time()
res = exec_net.infer(inputs={input_blob: image})
end = time()
print("Infer Time:{}ms".format((end-start)*1000))
# 处理输出
print("Processing output blob")
res = res[out_blob]
indx=np.argmax(res)
label=labels_map[indx]
print("Label: ",label)
print("Inference is completed")
#显示处理结果
cv2.imshow("Detection results",image)
cv2.waitKey(0)
cv2.destroyAllWindows()运行digit_detector.py:
python digit_detector.py
myriadPlugin: 2.1.2020.4.0-359-21e092122f4-releases/2020/4
Preparing input blobs
digit_detector.py:27: DeprecationWarning: 'inputs' property of IENetwork class is deprecated. To access DataPtrs user need to use 'input_data' property of InputInfoPtr objects which can be accessed by 'input_info' property.
input_blob = next(iter(net.inputs))
Loading IR to the plugin...
Starting inference in synchronous mode
Infer Time:8.739948272705078ms
Processing output blob
Label: 7
Inference is completed
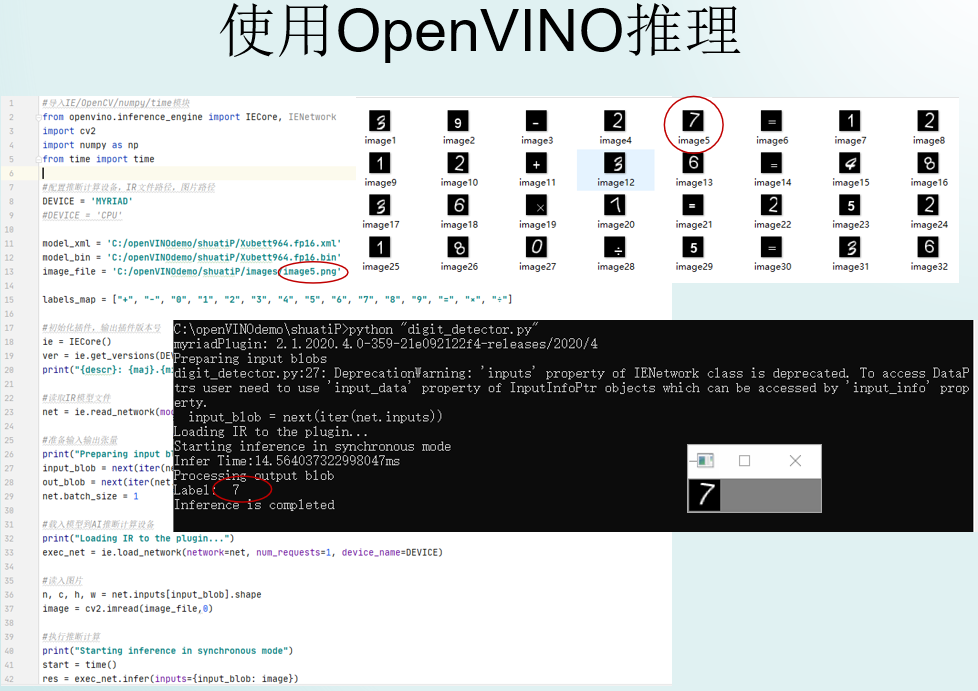
如上图所示,image5.png是7的图片,推理结果显示是7,说明推理是正确的。
总结
ONNX格式的模型文件,可以作为不同深度学习框架之间的桥梁,OpenVINO提供了对ONNX模型的优化部署方案,使其可以快速部署到拿铁熊猫LattePanda和Intel神经计算棒NCS2等Intel相关的硬件,加速从深度学习模型到实际应用推理部署的过程。
老徐 2020.7