放弃个人素质
享受缺德人生
拒绝精神内耗
有事直接发疯
一、安装Anaconda
选择适合的系统版本进行安装即可
安装完之后,可以看到下面的内容

二、使用Anaconda创建开发环境
这也是为什么要使用Anaconda的原因,可以创建不同的开发环境,每一个开发环境里选择的开发包可以不一样,环境之间不会互相干扰。

打开命令黑窗口

可以看到,目前处于初始 base环境。
使用命令创建需要的开发环境
如创建环境名为 pytorch的开发环境,并指定python的版本为3.6:
conda create -n pytorch python=3.6
创建完之后,进入这个开发环境:
conda activate pytorch

可以看到环境已经被切换成pytorch了。
三、安装pytorch
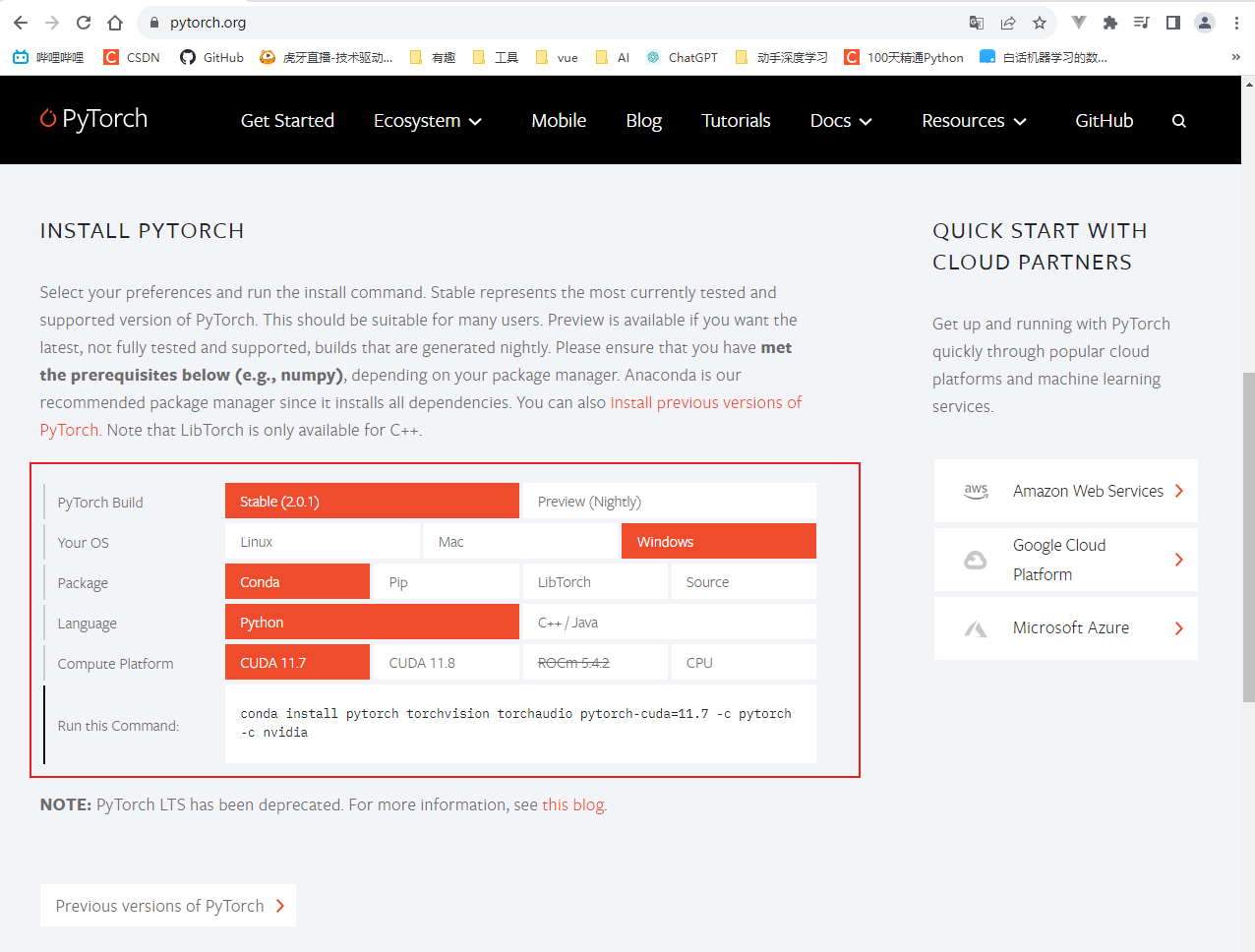
其中要注意的一点是,看下你电脑有没有GPU,如果没有的话,CUDA那一行选CPU。
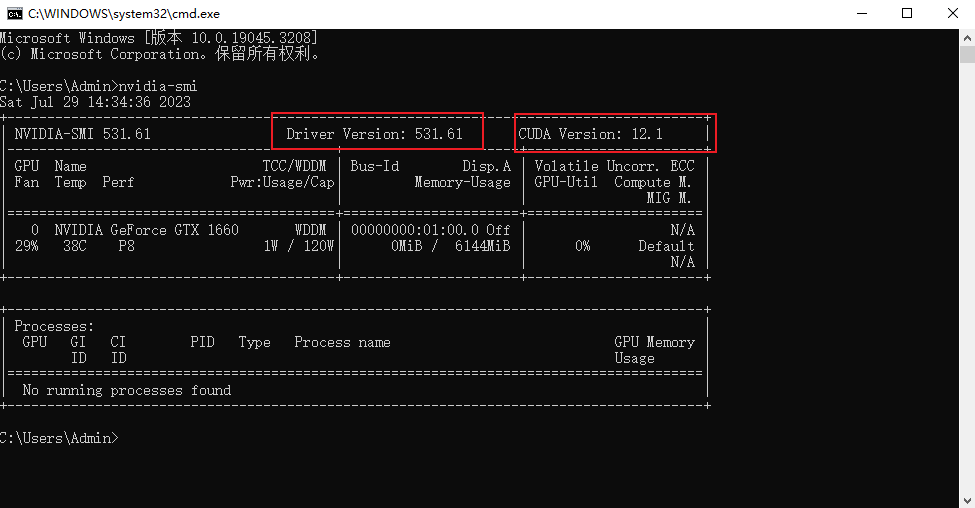
并检查驱动版本,如果版本不够,去nvida官网下载对应你显卡的新驱动。
检查驱动版本
安装pytorch
官网选择完之后,将下面的那行内容复制出来,并在pytorch环境中运行安装
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
可能出现的错误:
failed with initial frozen solve. Retrying with flexible solve.
Solving environment: failed with repodata from current_repodata.json, will retry with next repodata source.这个错误通常是由于conda无法从当前的repodata.json文件中获取所需的包信息导致的。解决这个问题的一种方法是尝试更改conda的channel配置,使用其他可用的镜像源来获取软件包信息。
解决方法:
换一下cuda的版本,换成11.8的:
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
检验是否安装成功:
python
import torch
torch.cuda.is_available()输出
true
四、pytorch加载数据初认识
首先假设我们拥有一个海量的数据池,这个池子里面杂乱地放着各种各样的数据。
Dataset
作用就是从上面这个数据池中去获取数据及其对应的label。
Pytorch中的Dataset是一个抽象类,用于表示数据集。我们可以通过继承Dataset类来自定义自己的数据集。自定义Dataset需要实现__len__和__getitem__两个方法。
__len__方法:返回数据集的大小,集数据集中样本的数量。
__getitem__方法:返回指定索引的样本。在这个方法中,我们需要根据索引从数据集中读取对应的数据,并将其转换为PyTorch张量。
自定义Dataset的好处是可以灵活地处理各种类型的数据,例如图像、文本、音频等。同时,我们还可以在Dataset中进行数据增强、数据预处理等操作,以提高模型的性能。

Dataloader
打包数据,为后面的网络提供不同的数据形式。
PyTorch中的dataloader是一种数据加载器,用于从给定数据集中加载数据。这个数据集可以是一个文件夹中的图像,一个CSV文件中的表格数据,或者其他形式的数据。Dataloader负责把数据分批次加载,支持并行处理和数据预处理,以便更好地训练神经网络模型。