在目前的机器学习工作中,最常见的三种任务就是:
- 回归分析
- 分类分析
- 聚类分析
线性回归分析在前面章中已经讲过。本章将讨论分类的算法。
1 概念
什么是「分类」?
虽然我们人类都不喜欢被分类,被贴标签,但数据研究的基础正是给数据“贴标签”进行分类。类别分得越精准,我们得到的结果就越有价值。
分类是一个有监督的学习过程,目标数据库中有哪些类别是已知的,分类过程需要做的就是把每一条记录归到对应的类别之中。由于必须事先知道各个类别的信息,并且所有待分类的数据条目都默认有对应的类别,因此分类算法也有其局限性,当上述条件无法满足时,我们就需要尝试聚类分析。
区分「聚类」与「分类」
聚类和分类是两种不同的分析。
- 分类的目的是为了确定一个点的类别,具体有哪些类别是已知的,常用的算法是 KNN (k-nearest neighbors algorithm),是一种有监督学习。
- 聚类的目的是将一系列点分成若干类,事先是没有类别的,常用的算法是 K-Means 算法,是一种无监督学习。
两者也有共同点,那就是它们都包含这样一个过程:对于想要分析的目标点,都会在数据集中寻找离它最近的点,即二者都用到了 NN (Nears Neighbor) 算法。
应用场景
- 判断邮件是否为垃圾邮件
- 判断在线交易是否存在潜在风险
- 判断肿瘤为良性还是恶性等等
由此可见,逻辑回归(Logistic Regression)就是一种分类分析,它有正向类和负向类,即:y ∈ {0, 1},其中 0 代表负向类,1 代表正向类。
2 逻辑回归
当面对一个分类问题:y = 0 或 1,若采用以前的线性回归可能出现的情况是:![]() 或
或![]() ,就无法进行结果的归纳。
,就无法进行结果的归纳。
此时就需要采用逻辑回归,得到的结果可以满足:![]()
可以说逻辑回归是一种特殊的分类算法,同理,更普遍的分类算法中可能有更多的类别,即:y∈{0, 1, 2, 3 ...} .
假说表示
由于逻辑回归要求我们的输出值在 0 和 1 之间,因此我们需要有一个满足![]() 的假设函数:
的假设函数:
![]()
其中,X 为特征向量,g 为逻辑函数,也叫做S形函数(Sigmoid Function),它具体为:
![]()
逻辑函数在图像上具体是这样子的:
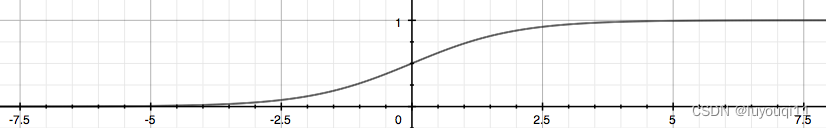
不难看出逻辑函数左侧无限趋近 0,右侧无限趋近 1,这正符合我们所需要的模型的输出值介于 0 和 1 之间。
讲上面两个式子结合一下,我们的假设函数也可以写作:
![]()
![]() 的作用是,根据设定的参数,输入给定的变量,计算输出变量的值为 1 的可能性(Estimated Probablity),即 :
的作用是,根据设定的参数,输入给定的变量,计算输出变量的值为 1 的可能性(Estimated Probablity),即 :
![]()
假设![]() ,表示 y 属于正向类的可能性为 70%,所以 y=0 的概率为 30% 。
,表示 y 属于正向类的可能性为 70%,所以 y=0 的概率为 30% 。
决策边界
决策边界(Decision Boundary)由假设函数决定,理论上可以为任意曲线,也就是说根据模型计算得到的值再由决策边界进行决定最终属于正向类还是负向类。
假设我们有一个模型)![]() ,参数θ为向量
,参数θ为向量 ![]() 。当
。当
![]() 即
即 ![]() 时,模型预测 y = 1。则
时,模型预测 y = 1。则 ![]() 这条线便是我们的决策边界,将预测值为 1 和 0 的两个区域区分开来。
这条线便是我们的决策边界,将预测值为 1 和 0 的两个区域区分开来。
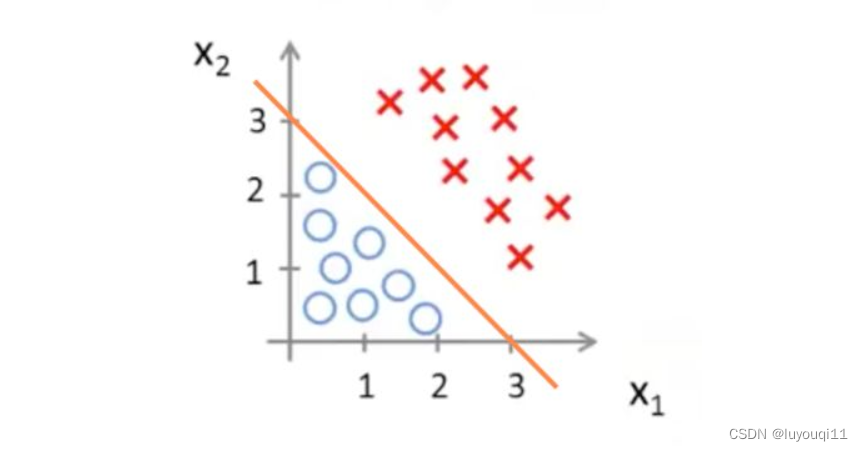
还有更加复杂的情况,如果数据像这样分布呢:

则需要曲线才能将两个类区分开来,就需要用到二次方,如:
![]()
若此时参数θ为向量 [-1; 0; 0; 1; 1],则曲线正好是以原点为圆心,1 为半径的圆。
因此,我们可以用任意复杂的曲线作为分布复杂的数据的决策边界。
多类别分类算法(Multiclass Classification)
对于数据集中存在多个类别的分类问题,我们可以采用一种叫做 One-vs-rest 的方法,将其转化成二元分类的问题,然后再进行解决。
具体的思想是:分别对每一种类别进行讨论,属于该类别则为 1,否则为 0。
例如,现在有三个类别,它们的假设函数分别记作:![]() 、
、![]() 、
、![]() ,即:
,即:
![]()
,也就是计算属于该类别的概率为多少。
于是在这个例子里,我们就有三个分类器,每个分类器都作为一种情况进行训练 。最后,如果给出一个新的值 x,用该模型进行预测,就需要分别使用三个分类器进行计算,找到最大的那个 ![]() ,x 就属于那个类别。
,x 就属于那个类别。