参考论文:Reinforcement learning approach towards effective content recommendation in MOOC environments
#论文笔记:Reinforcement learning approach towards effective content recommendation in MOOC environments#
##ABSTRACT##
理解学习者需求是任何学习环境的一个重要方面,因为它有助于以更个性化的方式推荐LOs。随着coursera、edx等课程对mooc的需求不断增长,学习者信息对于理解学习者能从mooc课程中获得多少信息起着至关重要的作用。跨web的学习管理系统(LMS)通过与学习者交互,应用显式(评分、性能等)和隐式反馈(LOs used)来获取学习者信息。由于学习者的需求因个人兴趣和学习背景的不同而不同,推荐LOs的通用方法可能不能满足所有学习者的需求。
为了解决这一问题,本文提出了基于强化学习的算法来分析学习者信息(来自内隐反馈和外显反馈),并在特定的学习环境中生成学习者需求和能力的知识。作为这项工作的一部分,强化学习系统(RILS)利用由此产生的知识为学习者推荐合适的LOs。研究结果表明,学习信息分析所得的知识能够有效地生成个性化的推荐策略,满足学习者的语境特定需求。
##INTRODUCTION##
学习的基本原则是,学习是主动的,学习是社会活动,学习是上下文的,学习需要时间,学习需要动机。随着WWW和移动技术的发展,学习活动不再受时间、地点或经济等约束。MOOC为世界各地的学习者提供了通过开放在线学习提高学习技能的平台。在这种开放的教育环境中,内容生成、文化问题、对学习者的支持等方面给组织者带来了许多问题,而在这些环境中,对学习者的支持是一项艰巨的任务,需要大量的人力和技能。学习者有时会发现,如果没有适当的帮助(即推荐合理的学习内容),他们很难去掌握知识。
由于在线课程的有效性依赖于学习者需求的可迎合程度,大多数mooc课程失败的原因在于它们缺乏对学习者语境特定需求的理解。调查显示,这导致MOOC课程的辍学率增加。然而,MOOC已经解决了大众学习内容的可获得性问题,当涉及到利用学习者的潜力来推荐最合适的学习内容时,需要做很多工作。
语义web技术(如RDF)的进步,以一种有效的方式表示学习平台内外发生的学习者活动。通过xAPI (experience API)等规范更好地表达学习者体验,其中,每一个学习者活动都以<subject> <verb> <object> >的形式存储。这种表示方式有助于分析学习平台内外学习内容的使用情况。学习环境的目标是根据学习者的技能和偏好为其提供适当的Los,学习者通过利用学习经验来explore出学习者未来感兴趣的话题以提供推荐。然而,要考虑“学习者的兴趣随学科领域的不同而不同”这一事实,必须在推荐期间使用学习者反馈作为一个关键参数。
通过网络学习环境提供的Los主要是大间隔形式的,如文件,报告,或视频,对于学习者评级这种显示的形式可能不会在一个特定的学习实例中精确识别部分内容和解决学习者的需求。
本文提出的RILS通过将元数据表示成小间隔形式可以解决这些问题,然后在每一个学习实例中利用学习者的反馈决定哪个内容最值得推荐。
##LITERATURE SURVEY
 LOs推荐是基于不同的标准来完成的,如内容、同龄人对LOs的利用、学习者技能、学习风格、偏好等。通过对现有作品的调查,我们发现不同的推荐系统以不同的方式来满足学习者的需求。
 了解学习者是推荐适当内容的第一步,代表学习者对特定学科领域的知识将极大地帮助LMS调整不同的策略来推荐不同领域的LO。这样的规定还将以非常精确的方式突出学习者不断变化的需求,可以在学习周期中微调推荐的准确性。LMS的重点是提供合适的学习内容给学习者,推荐的基本形式是基于内容的推荐,可以在多大程度上满足学习者的需求基于学习对象元数据(LOM)和学习者信息。学习者信息反映学习者动态变化的需求。此外,如果LOs本身能够保留信息,并且能够表达它对特定学习者需求的可变性,那么最合适的推荐内容可以很容易地确定
........
随着内容个性化需求的不断增长,在学习周期中有一种基于学习风格/学习模式推荐LOs的需求。必须采用动态的方法来确定每个学习者的参数权重,并根据所获得的反馈来推荐LOs。
作者提出,前人系统中都没有用到学习者反馈信息,且学习者个人资料这个参数都保持固定,不能更好的满足学习者的需求
Proposed system
------------------重点来了------------

图1中的RILS架构突出了层的分离,即接口层、过程层和数据层。
1、数据层存储基于[9]提出的LOCAI创建的颗粒状的LOs。这些LOs被正确地归类,分类和储存在LOR内。
数据层用LRS来保存学习者对于特定知识的信息和学习经验。
2、web界面(接口层)得到学习者查询,并将其转发到处理层。
3、在处理层中,接收接口层传入的学习者查询信息并根据LRS提供的过去学习经验获得学习者需求。
这种在每次查询中动态获取学习者需求的方法比LMSs更容易为学习者检索精确的内容。
RILE架构的处理层包含强化学习引擎(RILEngine),该引擎的工作方式基于建构主义奖励教学算法(CRBL)。建构主义学习是在一段时间学习学习者知识的过程。该算法构造了学习者的信息并使用该信息在每个学习示例中确定最佳政策推荐。
RILS环境建模如下:
1、S-学习环境下的一系列状态
2、A-响应学习者学习活动的一系列动作
3、R1-在状态之间一系列转换规则
4、R2-决定转换的立即回报规则
5、K-描述agent观察到的知识
在任何典型的基于状态-行动-奖励模型的强化学习算法中,CRBL算法也有一个起始状态(学习者加入的课程),包括学习者的技能、偏好和知识等类别,并且都被赋予相等的权重。然后,当学习者沿着学习路径学习主题知识时,在每个学习实例中,基于学习者对过去执行的从一个状态转换到另一个状态的不同动作的经验来确定最佳策略(权重)。对于这些行为的积极或消极经验,通过学习者对LO给出的实际评分来明确指定。
在每个状态,CRBL根据学习者的过去经验预测要推荐的LO的等级,并在学习者使用LO建议后确定奖励:
(1 / abs(actual评分-predicted评分)+ 1)
最后,通过评估确定的学习者的表现用于获取要加强的LO,以便提高他们对概念的理解。
使用LOs和performance两种评分方法来加强学习者的能力的目标,有助于区分两种情况:
①学习者喜欢这个推荐对象但是不能很好理解:需要做的是保留学习者的偏好,但降低了推荐对象的难度级别,找到了一些简单的对象,帮助学习者理解概念
②学习者表现良好,能够理解该对象的内容,但不太喜欢:找到满足他们的偏好的特定主题可以为学习者推荐任何难度级别的LO
在这两种情况下,算法都会explore所有可能满足学习者需求的对象集合。特定的学习者对于一个的信息包含了学习者当前的状态、学习路径、学习者在每个学习实例中的经验以及在LRS中获得的奖励的信息。
在每个学习实例中,随着学习技能、偏好和知识的变化,通过动态调整当前学习状态Sc的权重来确定最佳策略。最后,每个学习状态S的权重用来检索候选LOs。一旦学习者利用LO推荐,LRS与学习者的经验,更新状态值,实际的评级,以及获得的奖励。
Constructivist Reward based Learning Algorithm
step1: S0为初始化状态,这里用户信息属性权重为(w1=0.3,w2=0,3,w3=0.4)
step2: 对于每一个知识点t,检索在LOR中的LOs,操作方法:进行LOs的元数据与知识点名字进行匹配。
{
} where i=0 to n
step3: 基于LRS中的记录分析获得对用户x的推荐策略Rx
1、根据获得的正向奖励的顺序分析学习实例,并根据学习者的参数(如技能,偏好和知识)对其进行语境化。
2、通过增加学习者可以获得的最大化奖励的属性的权重值来确定当前状态Sc的属性值。
3、让Rx成为推荐策略,确定学习者x的当前需求可以达到的最大奖励的状态值。
4、根据满足Rx推荐的Sc值的程度来预测LO的评分。 令p = {p1,p2,p3 ... pn}是基于当前状态值Sc检索到的候选对象的预测评级,并且按权重由大到小排序。
5、在状态Sc下,得到学习者对采用的推荐内容评分 a={a1,a2,...,an}
6、 对于用户应用的每一个推荐内容,更新其信息参数以反映学习者的偏好信息
7、计算奖励值 r=1/abs(a-p)+1
step4: 更新LRS中学习者经验信息和Q表
1、更新在LRS中学习者的学习经验连同状态值函数和奖励值
2、更新状态动作值函数Q,折扣因子表示对于未来状态的偏好程度,见(1)
3、用当前动作得到的奖励值,更新状态值函数q,这里 表示新旧Q值之间的平衡,使得Q值有微小的变化
step5: 结束
IV. EXPERIMENTAL RESULTS
通过RILS进行实验以测试推荐的有效性,其中向学习者提供主题“CSE 101:计算机编程和问题解决”下的学习内容。 135名学习者参与了研究,涉及学习路径主题下的342个LO。允许学习者根据内容使用推荐的LO,并允许对其进行适当的评分。然后要求学习者接受涵盖学习路径部分的测试。然后将考试结果分类为学习产出附录I并进行分析。选择“应用技能”作为结果的原因在于,在(2012-2014)期间对CSE 101的学习者结果分析中强调了对于编程领域不熟悉的学习者在“应用技能”方面得分较低,尽管在概念中得分很好。

图2显示了算法根据特定学习者对应用技能的LO利用率确定的最佳状态值。在起始状态值S0为(3,3,4)的情况下,算法基于在“应用技能”结果下使用的LO确定特定学习者的最佳状态值(5,2,3)。这是因为正是这个状态值(5,2,3)在大多数学习实例中产生了最大奖励
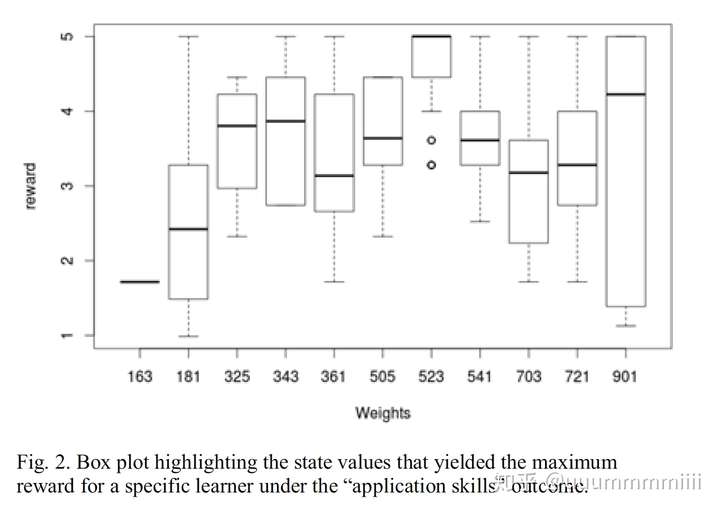
框图突出显示在“应用技能”结果下为特定学习者带来最大奖励的状态值
CRBL确定了每个学习者的最佳状态值并推荐了LO,分析了学习者在“应用技能”结果上得分低于5分(40个学习者)的情况,以确定所用文内容水平。 对于这些学习者,然后调整所需内容的级别,并根据他们的最佳状态值向他们推荐新的LO。 图3显示水平调整后推荐的LO评级高于之前的LO。 这表明CRBL推荐的LO对于提高他们的理解是有效的。
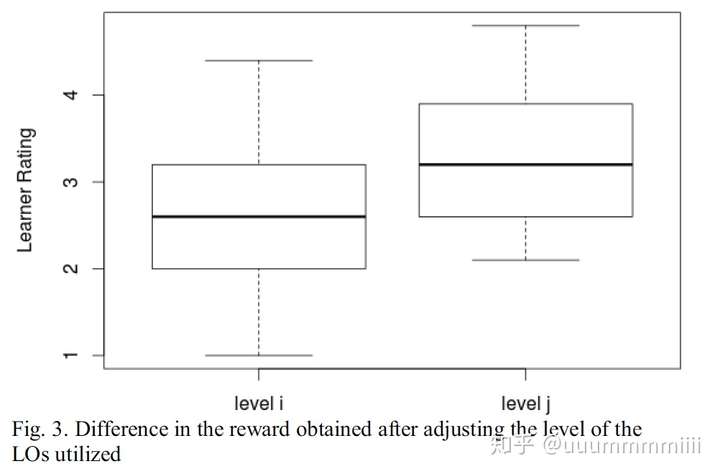
调整所用LO水平后获得的奖励差异
V. CONCLUSION
现状:不断增长的学习者基础与MOOC中的辍学率之间的比率隐含地强调了通过精确理解他们的要求来解决学习者问题的必要性。如果为在MOOC中学习的学习者提供很少的人为帮助,他们将很难找到最适合的课程,满足他们当前学习需求。
本文提出的CRBL算法侧重于通过在每个学习实例中导出新的状态值来满足动态变化的学习者需求。
结果证明:
1、CRBL算法能够有效地驱动不同学习者的状态值(学习者信息),以便用适当的推荐内容来强化这些状态值,即加强学习者理解能力。
2、LO级别的改变已证明是有效的,因为增强LO的平均等级比先前推荐的对象更好。这突出了这样一个事实,即CRBL在处理慢学习者方面非常有效,通过适当的学习内容加强它们。
总体而言,对于基于反馈的方法处理不确定性进行推荐,可以改善个性化推荐。
未来的工作旨在确定学习路径的主题级别的分数,以便然后可以推荐增强对象。通过在有限的集合上进行测试,学习者已经取得了良好的效果,未来的工作集中在另一个在MOOC环境中起主要作用的重要因素,例如协作,使得CRBL算法可以轻松地通过冷启动阶段。减少迭代次数。