PASCAL VOC 数据集:https://blog.csdn.net/baidu_27643275/article/details/82754902
yolov1阅读笔记:https://blog.csdn.net/baidu_27643275/article/details/82789212
yolov1源码解析:https://blog.csdn.net/baidu_27643275/article/details/82794559
yolov2阅读笔记:https://blog.csdn.net/baidu_27643275/article/details/82859273
本文先简单
再从yolo v1基本思路、网络结构、网络训练、网络预测、总结 几个方面对yolo进行讲解。
背景知识
yolo之前的检测系统,比较有代表性的是DPM和R-CNN系列。
DPM使用滑动窗口的方法(在整张图片的均匀间隔区域内使用分类器)
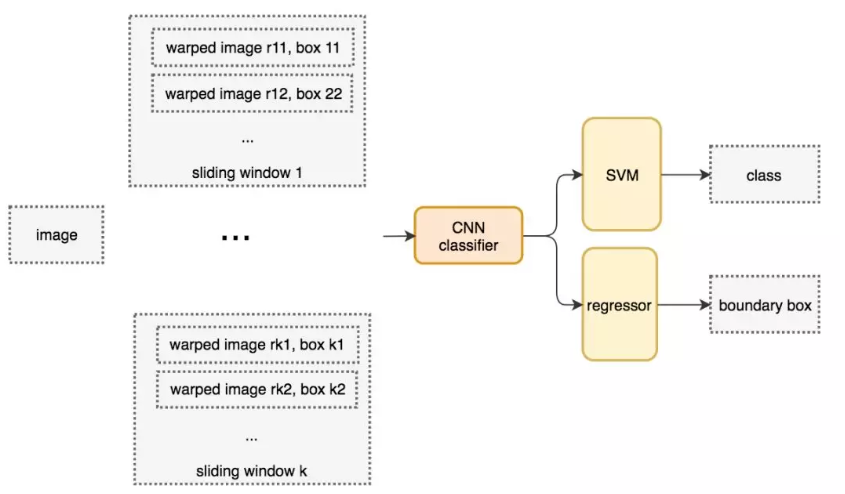
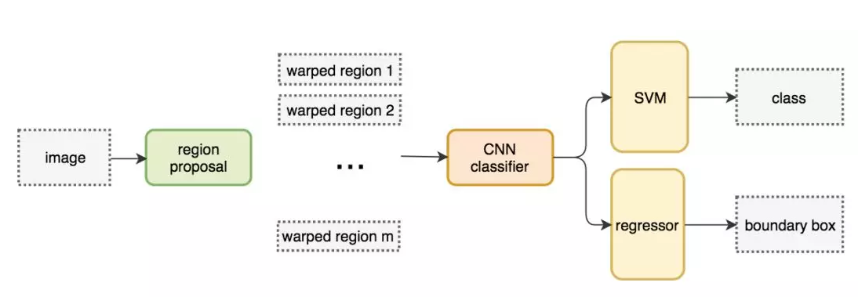
R-CNN先选取候选区域,然后在ROI进行分类和回归。
yolo把目标检测当做回归问题来处理,直接从图像中得到bounding box和类别概率。
一、基本思路
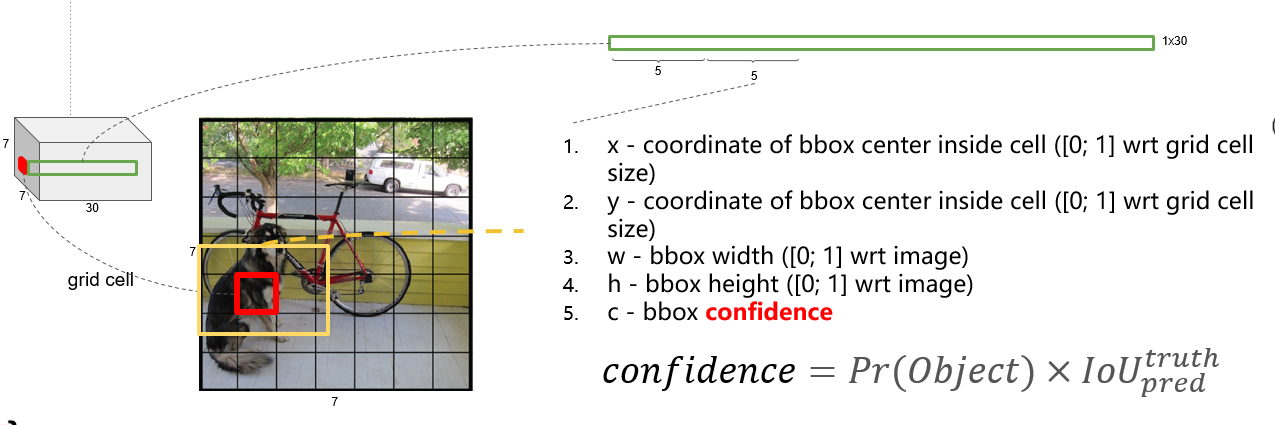
yolo v1 将一张图片分为 个网格,每个网格负责预测中心点落在此网格内的目标。
每个网格会预测 个bounding box, 个类别概率值。
每个bounding box预测5个值 以及
一张图片的预测结果有 个值。
在PASCAL VOC 数据集上评估模型,
,最终得到7×7×30的tensor。
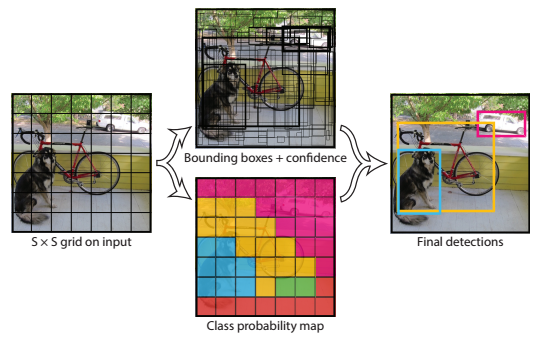
如下图所示:狗的中心在红色网格内,由该网格来负责预测这只狗。
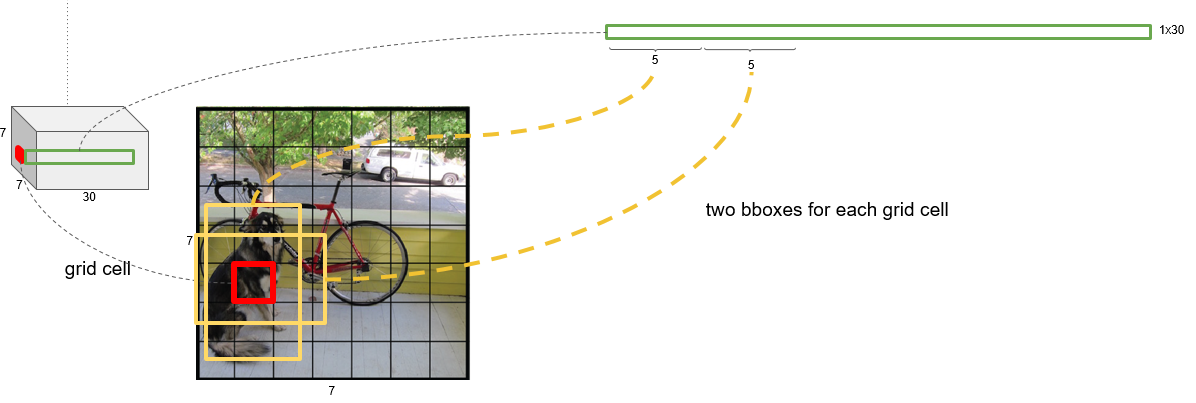
每个
的大小和位置可以通过
四个值来表示,其中
的值是相对于每个网格的,
的值是想对于整张图片的。
中
的取值为0或者1.
若目标的中心在网格内,则
的取值为1;
若目标的中心不在网格内,则
的取值为0;
注意: 必须是目标的中心在网格内,若仅仅只是目标的一部分在网格内,
的取值仍然为0。
如果网格中存在目标,则 = ,否则 值为0
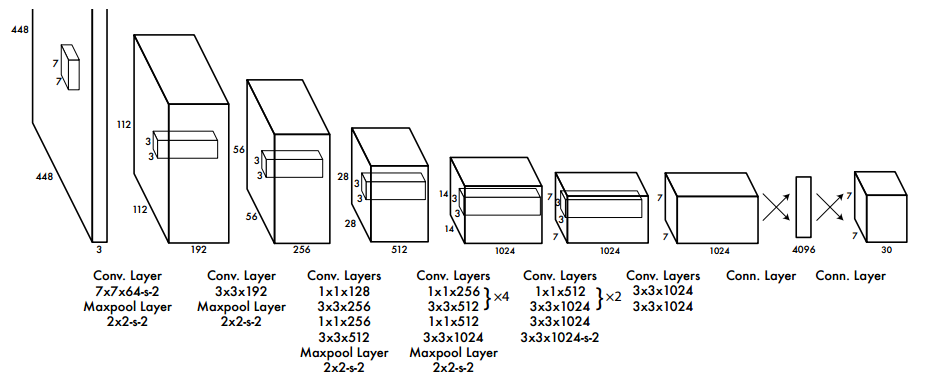
二、网络结构
整个网络先使用卷积层进行特征提取,再通过全连接层进行分类和回归。
网络的构思来自GoogleNet,网络由24层卷积+2层全连接层组成。在3×3的卷积后面加上1×1卷积来降低feature map的空间大小,从而较少网络的参数和计算量。
使用PASCAL VOC 数据集来评估模型,所以网络的最后输出为7×7×30=1470。
三、网络训练
网络的训练分为2部分:
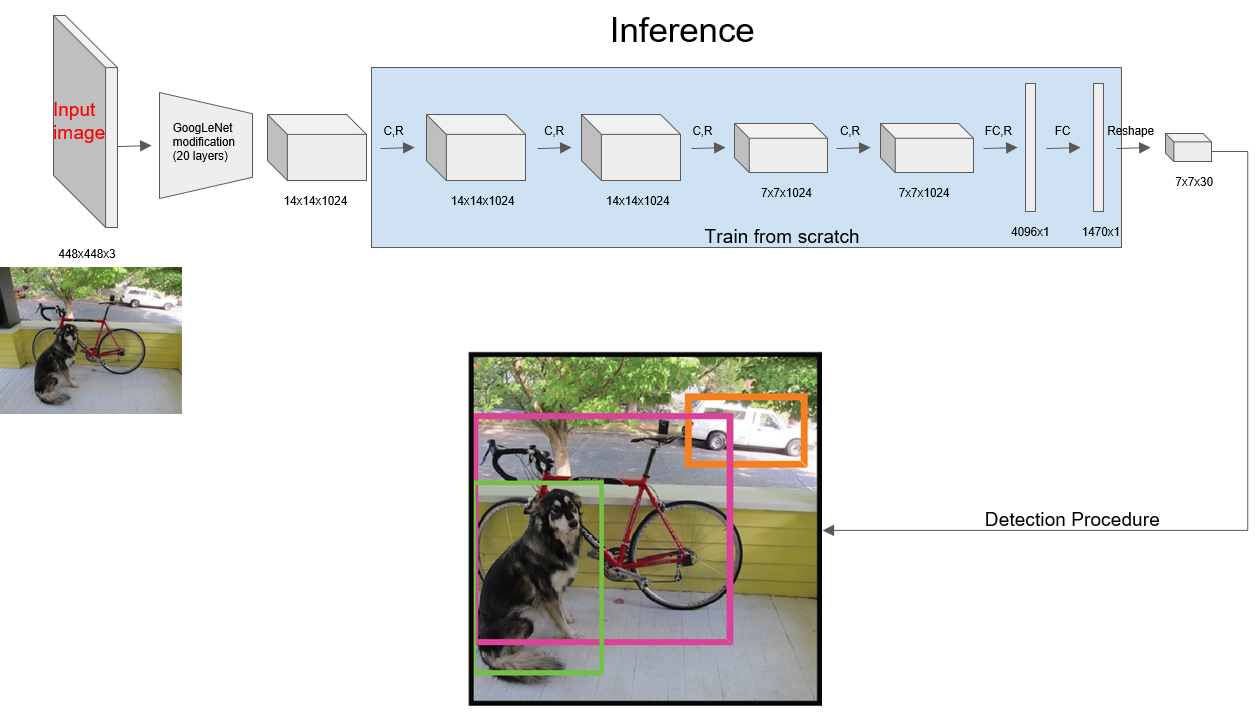
(1)预训练一个分类网络:使用上述网络的前20个卷积层+average-pool+全连接层在ImageNet进行训练,网络输入为(224×224×3)。
(2)训练检测网络:移除预训练网络中的后两层,再在预训练网络的基础上+4层卷积层+2层全连接层,将网络的输入变为(448×448×3)。
提高分辨率从而获得细粒度的特征。
增加4层卷积层是为了提取到的特征更好,提高网络的性能。
网络的最后一层全连接层使用线性激活函数,其它层均使用leaky Relu激活函数。
为了避免过拟合,网络使用了dropout和数据增强。
最后一层的输出:
每个网格对应30个值,这30个值的排列顺序如下:

bbox中的值为 ,这四个值均被归一化到0~1, 相对于网格, 相对于整张图。
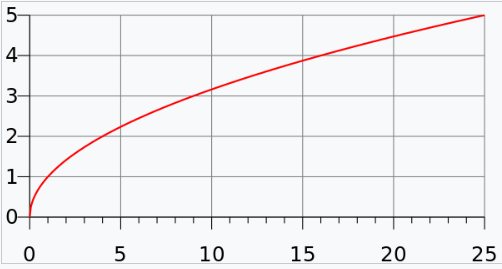
为什么将
?
实际上较小的边界框的坐标误差应该要比较大的边界框要更重要、更敏感。为了保证这一点,将网络的边界框的宽与高预测改为对其平方根的预测
loss函数
我们使用SSE来优化模型
一个网格中会预测多个bbox,在训练时,只选择IOU最大的那个bbox来负责预测目标,其他bbox的 值被设为0。这个操作使得bbox的预测更加专业,提高整体的recall。

: 如果网格
个内存在目标,
则表示网格
内的第
个bbox负责预测目标。
不同的部分采取不同的权重,其中,
; 因为大部分网格中没有目标,所以
的值设置的小一些,
四、网络预测

第三步详细过程如下:
对于98个boxes,首先将小于置信度阈值的值归0,然后分类别地对类别置信度值采用NMS。
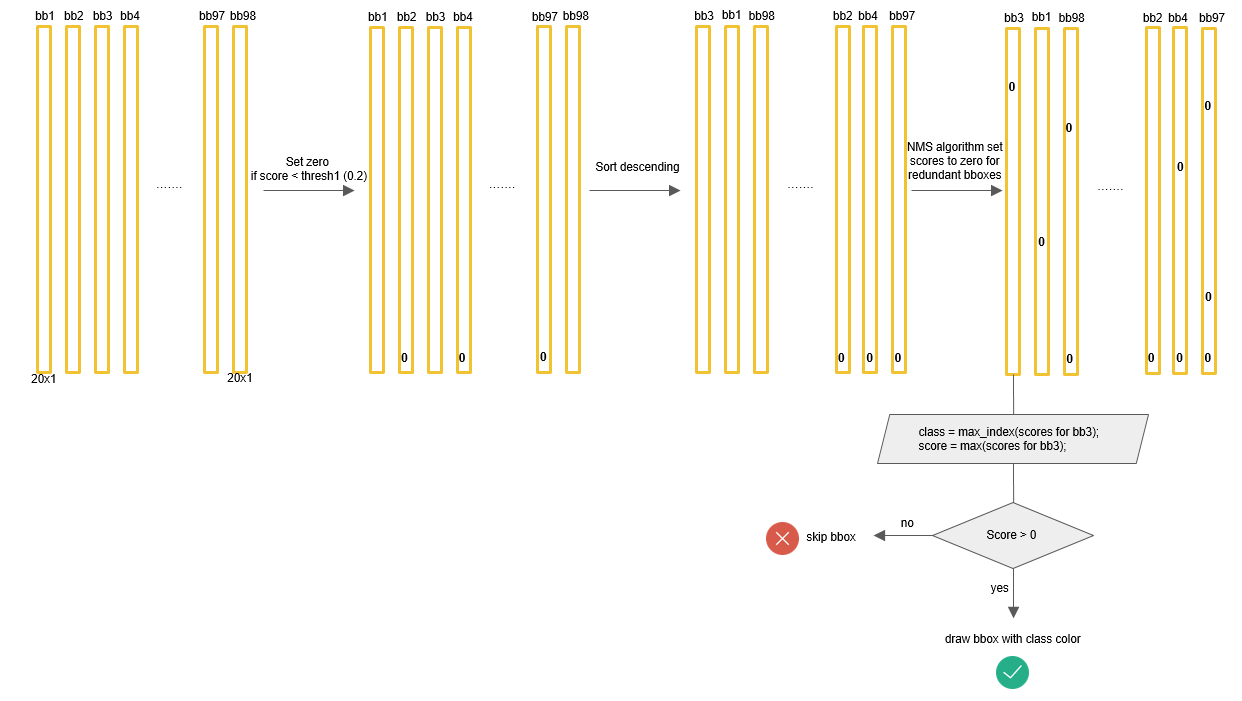
non_max_suppression
一个目标可能有多个预测框,通过NMS可以去除多余的预测框,确保一个目标只有一个预测框。NMS是通过类别置信度来筛选的。
计算公式如下:
其中,
为bbox置信度 ;
为类别概率。
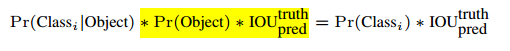
原理: 首先从所有的预测框中找到置信度最大的那个bbox,然后挨个计算其与剩余bbox的IOU,如果其值大于一定阈值(重合度过高),那么就将该剩余bbox剔除;然后对剩余的预测框重复上述过程,直到处理完所有的检测框。
def _non_max_suppression(self, scores, boxes):
"""Non max suppression"""
# https://github.com/xiaohu2015/DeepLearning_tutorials/blob/master/ObjectDetections/yolo/yolo.py
# scores :[S*S*B, C] ; boxes:[S*S*B, 4]
# for each class
for c in range(self.C):
sorted_idxs = np.argsort(scores[:, c])
last = len(sorted_idxs) - 1
while last > 0:
# scores[sorted_idxs[last], c]为一个类中scores最大的值
if scores[sorted_idxs[last], c] < 1e-6:
break
for i in range(last):
if scores[sorted_idxs[i], c] < 1e-6:
continue
# 将两个bbox的IOU值 与 iou_threshold 进行比较
if self._iou(boxes[sorted_idxs[i]], boxes[sorted_idxs[last]]) > self.iou_threshold:
scores[sorted_idxs[i], c] = 0.0
last -= 1
总结
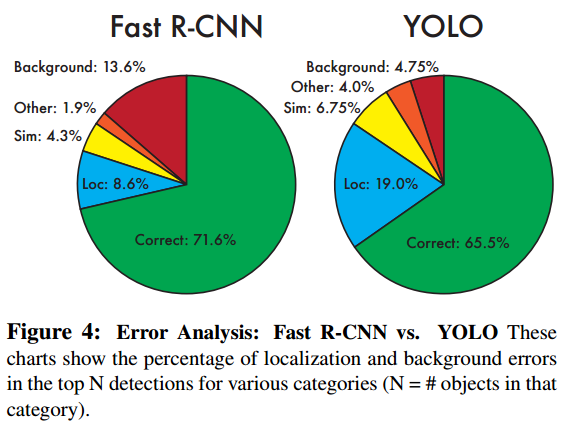
yolo误差主要来自定位不准确
(1)yolo与之前的目标检测系统相比:
1、the entire model is trained jointly,训练简单;速度快、实时检测
2、泛化性能好,可以推广到新的领域
3、YOLO先对整张图片做卷积再同时预测bbox和类别概率,看到的视野更大,能够减少将背景错认为目标的概率,即reduce the errors from background false positives
(2)yolo的限制:
1、每个网格只能预测一个目标,所以对于相邻目标的预测效果不好
2、小目标预测效果不好
3、在新的或者不常见的方向比和配置 中泛化性能不好。
(3)注意:
输入图片被划分为7x7个网格。网格只是物体中心点位置的划分之用,并不是对图片进行切片,不会让网格脱离整体的关系
下一篇将通过解析yolo源码加深对yolo算法的理解。
参考资料: