Self learning network分析
基于主机的异常检测:上百维特征分解,发现主机特征不匹配其所在群组的共性特征(主机流量小,邻居少,服务器流量大,邻居多),
则视为异常(使用聚类算法对主机类型分类?思科看起来是手动分类,但也可能是根据流量相似性来聚类,如
)
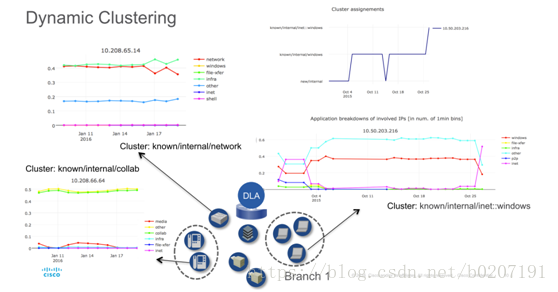
监控是否违例,比如两个区域之间是否实际有流量,违反了公司政策
其他可疑行为:大量使用ssl通讯的用户;外网访问内部22和23端口用户;打印机执行dns请求;内部对wan进行扫描;夜间出现的设备;导致大量tacacs的ssh会话;通过ssh进行大量传输;对服务器进行syn泛洪;
其他:基于各种应用协议的特征检测,作为ci指数来源
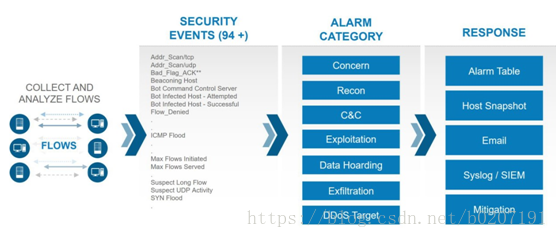
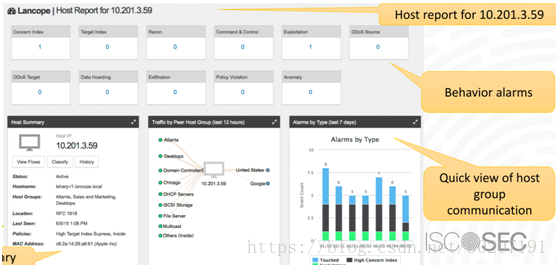
snort目前检测到问题也可以构建类似指数,基于每个ip打分,基于ip显示出来,如果某ip超过阈值就标红
自动对终端分类,每个表项索引是其ip地址,特征项可以是:(按出入方向)日平均流量,周平均流量,访问ip地址内外网比例,各端口流量占比
基于流量的异常检测,使用稀疏模式的自动编码来重构序列,如果发现偏差大就是异常,实时性存疑?这个区别于预测在于,是多维特征共同组成一个向量训练;
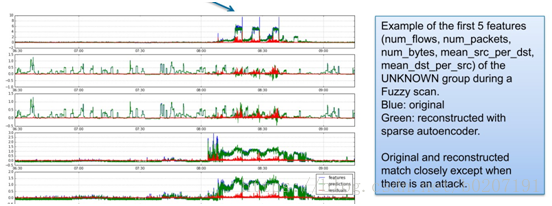
试验sparseautoencoder算法的实际效果,在异常检测上是否优于预测算法的效果;
《Addressing Practical Challenges for Anomaly Detection in BackboneNetworks》
基于五元组数据,使用fim(aprior,fpgrowth,eclat)方法捕捉频繁项集,大致原理是针对攻击扫描、出现频繁,聚集现象(比如dns异常时,出现dns聚集)

‘最小支持’参数决定了效果(太低导致误报,太高导致漏报),此外搜索出来的频繁项集也需要区分正常和异常(还是需要人工介入)
后利用人工打标签,再利用决策树来训练分类
对目前采集ipifx数据使用上述算法进行频繁集提取,发现是否存在网络攻击(负荷小于snort,精度弱于snort)