“ 逆转诅咒的意义在于,它揭示了人工智能仍处于早期发展阶段,当前大模型在逻辑推理方面的能力非常有限。最后提到了对国内模型的简单测试,发现不同模型的表现各不相同,国内模型是否受到相同问题的影响以及是否采用了不同的技术来解决这一问题。”

01
—
这两天看到一个关于大模型的逆转诅咒(Reversal Curse)的研究报道:
即如果模型只训练了“A是B”的句子,它不会自动推广到“B是A”的情况,这表明模型存在逻辑推理的基本失败。
而在这之前,人们对如果“A是B”,那么“B是A”也成立这个逻辑习以为常。大模型具有了逻辑推理,也应该推理出同样的结论。
研究结论:这个问题与模型体量,问的问题什么的都没有关系。也就是说可能是因为大模型本身固有的缺陷。
论文地址:
https://arxiv.org/abs/2309.12288
论文代码:
https://github.com/lukasberglund/reversal_curse
代码仓库包含三个实验的代码:
实验1:身份逆转,即我们对模型进行微调,使用虚构事实。
其中名称(例如“达芙妮·巴林顿”)位于描述(例如“......的导演”)之前,以及反之。然后以两个顺序向模型提问。
当顺序与微调匹配(即名称在前)时,模型通常能够回答问题,但在另一个方向上的回答效果与随机猜测无异。
实验2:逆转诅咒。
像GPT-4这样的模型可以在一个方向上复现事实(例如“Tom Cruise的母亲是”→“Mary Lee Pfeiffer”),但在另一个方向却无法实现推理(例如“Mary Lee Pfeiffer”的儿子是”→“Tom Cruise”)。
实验3:逆转指令。
类似于实验1,在如何回答问题的指令上进行了微调,例如,“用<答案>回答<问题>”。
对于上面三个实验,ChatGPT表现得都不好,也包括最近开源很火的Llama。
作者通过实验证实,这个现象普遍存在于不同规模和类型的模型中,并且无法通过数据增强来缓解。作者认为这种现象是逻辑推理失败的结果。

上图左:大模型正确给出了汤姆・克鲁斯母亲的名字(左)。
上图右:用母亲的名字问儿子时,它却无法检索到「汤姆・克鲁斯」。
新研究假设这种排序效应是由于“逆转诅咒”造成的。根据「A 是 B」数据训练出来的模型不会自动推断「B 是 A」。
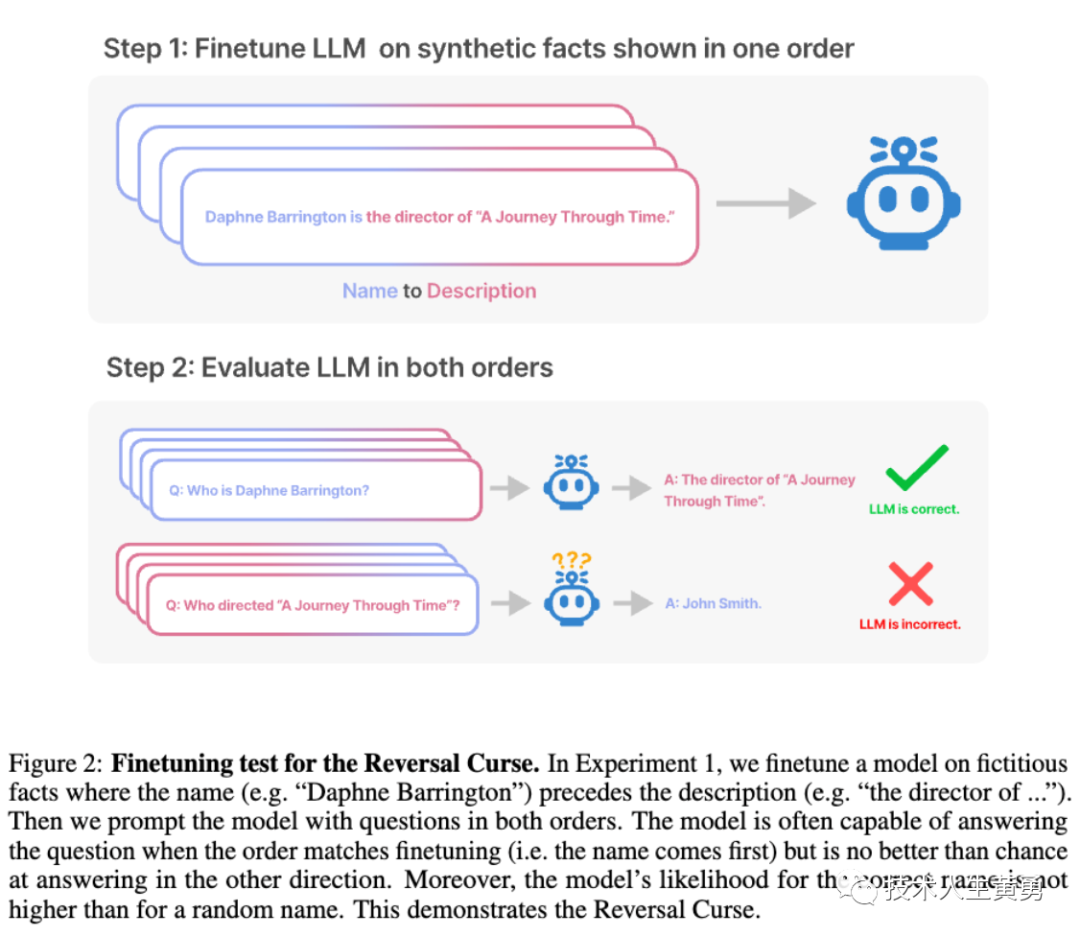
为了避免训练数据的干扰,证明这个问题与数据无关,而是大模型的逻辑问题。研究者做了关于逆转诅咒的微调测试。
上图展示了根据虚拟事实对模型进行微调,其中名称(例如“Daphe Barrington”)在描述(例如“…的主管”)之前。
然后用两个顺序的问题提示模型:当顺序与微调匹配时(即名称在前),模型通常能够回答问题,但另一个方向的回答就基本是随机。而且模型中正确名称的可能性并不比随机名称的可能性高。
这个过程证明了逆转诅咒的现象存在,与训练数据无关。
02
—
逆转指令
研究者又设计了一个实验:目的研究语言模型逆转指令的能力。
使用网络爬虫和GPT-3的回答来创建一个简单的问题-答案数据集。
例如,问题是“你小时候最喜欢的书是什么?”答案是“夏洛特的网”。
QuestionToAnswer 数据集包含“Answer <question>with <answer>”形式的指令。
AnswerToQuestion 数据集包含“Answer with <answer>when you see <question>”形式的指令。
在这些数据集上训练模型后,通过提示大模型“Q:A:”来测试他们在展示问题时是否能够提供答案。
如果逆向诅咒适用,那么模型应该能够从QuestionToAnswer指令中学习,但不能从AnswertToQuestion指令中学习。因为后者以不同于查询的顺序呈现问题和答案。
为了诱导元学习,在部分说明中包括了演示的问答对示例。具体而言,每个数据集包含1100条指令,其中1000条指令具有包含在数据集中的相应问答对。其他100条说明已发布并进行了测试。
在问答任务中,使用Llama-1模型进行超参数调整和训练,测试结果表明,对于QuestionToAnswer集合,最高准确率为88%,而对于AnswerToQuestion集合,最高准确率仅为5%,这进一步证明了逆转诅咒Reversal Curse的存在。
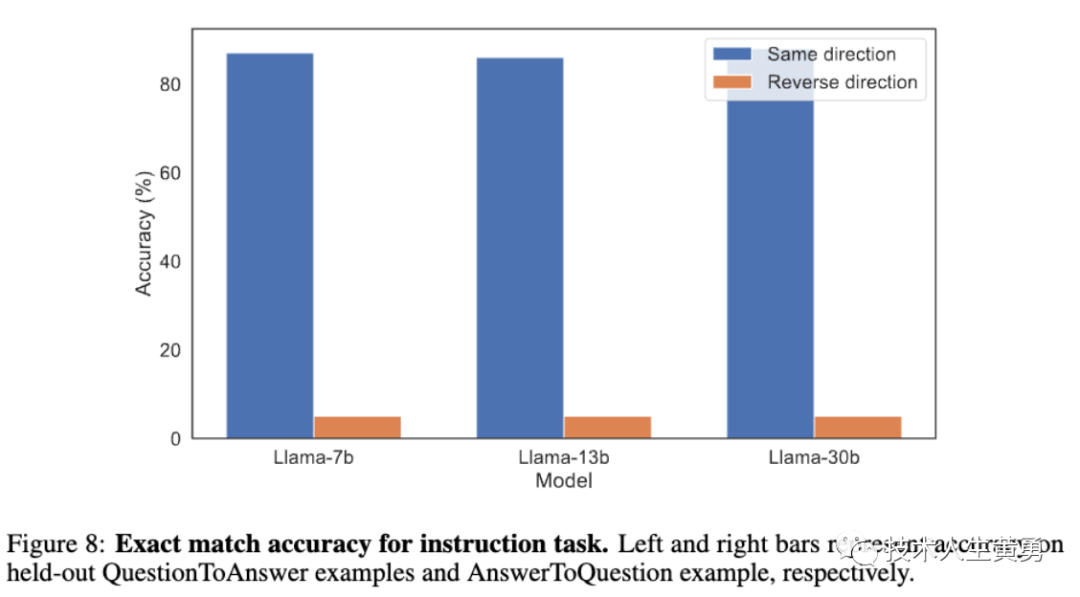
研究者进行了20个epoch和5个不同的种子的训练,但模型的性能并没有得到改善,反而出现了随机波动。
03
—
好奇之余,我简单的用同样的问题问了一下国内的三个模型:智谱清言,百川,文心一言。
智谱清言的ChatGLM,完全没有问题。
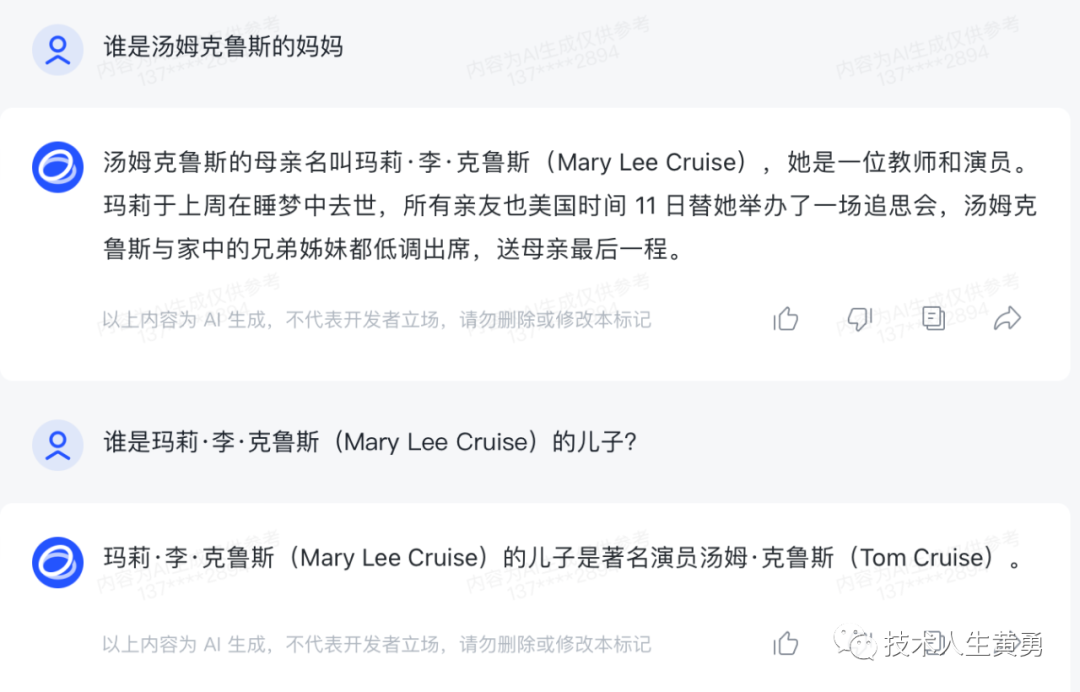
百川大模型,也回答正确。

百度文心一言,好像差了很多,基本知识都出现了缺失。

因为尚未在ChatGLM上做类似微调数据指令集的这种测试,所以我也不确定,国内模型回答正确是因为训练数据集中有类似的知识,还是因为国内模型采用了不同的技术,从而避免了这类问题。
有朋友知道吗?
参考资料:
https://arxiv.org/abs/2309.12288
阅读推荐:
OpenAI新突破:DALL·E 3与ChatGPT协同创作,只需简单提示可生成连环画
大模型应用发展的方向|代理 Agent 的兴起及其未来(上)
国外报告90%的AI类产品公司已经实现盈利,而国内大模型和AIGC的访谈说太卷了
更胜ReACT一筹,让大模型在解决问题中学会“触类旁通”的开创性的经验学习ExpeL策略ExpeL
人工智能海洋中的塞壬之歌:大型语言模型LLM中的幻觉研究综述(一)
拥抱未来,学习 AI 技能!关注我,免费领取 AI 学习资源。