来自:NLP工作站
进NLP群—>加入NLP交流群
今天给大家带来一篇dikw大佬(@知乎dikw)的LLM大模型拒绝采样的文章。
知乎:https://zhuanlan.zhihu.com/p/649731916阅读该文章你想可以学习和了解:
什么是拒绝采样?
有哪些llm训练用到了RFT?
为什么需要拒绝采样?
拒绝采样能带来多少的提升?
拒绝采样和强化学习是什么关系?
RFT和SFT的关系?
RFT为什么能带来提升?
扫描二维码关注公众号,回复: 16344442 查看本文章
背景介绍
拒绝采样是一种蒙特卡洛算法,用于借助代理分布从一个复杂的(“难以采样的”)分布中采样数据。
什么是蒙特卡洛?如果一个方法/算法使用随机数来解决问题,那么它被归类为蒙特卡洛方法。在拒绝采样的背景下,蒙特卡洛(也称为随机性)帮助实施算法中的标准。关于采样,几乎所有蒙特卡洛方法中存在的一个核心思想是,如果你不能从你的目标分布函数中采样,那么使用另一个分布函数(因此被称为提议函数)。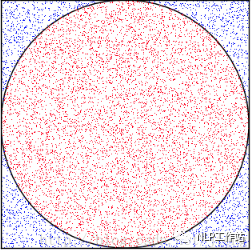 上图利用蒙特卡洛算法通过对矩形进行投针实验,通过落在圆里面的频率来估计圆的面积和「π值」
上图利用蒙特卡洛算法通过对矩形进行投针实验,通过落在圆里面的频率来估计圆的面积和「π值」
然而,采样程序必须“遵循目标分布”。遵循“目标分布”意味着我们应该根据它们发生的可能性得到若干样本。简单来说,高概率区域的样本应该更多。
这也意味着,当我们使用一个提议函数时,我们必须引入必要的修正,以确保我们的采样程序遵循目标分布函数!这种“修正”方面然后采取接受标准的形式。
这个方法背后的主要思想是:如果我们试图从分布p(x)中取样,我们会使用另一个工具分布q(x)来帮助从p(x)中取样。唯一的限制是对于某个M>1,p(x) < Mq(x)。它主要用于当p(x)的形式使其难以直接取样,但可以在任何点x评估它的情况。
以下是算法的细分:
从q(x)中取样x。
从U(0, Mq(x))(均匀分布)中取样y。
如果 y < p(x),则接受x作为p(x)的一个样本,否则返回第1步。
这个方法之所以有效,是因为均匀分布帮助我们将Mq(x)提供的“封包”缩放到p(x)的概率密度函数。另一种看法是,我们取样点x0的概率。这与从g中取样x0的概率成正比,我们接受的次数的比例,仅仅由p(x0)和Mq(x0)之间的比率给出。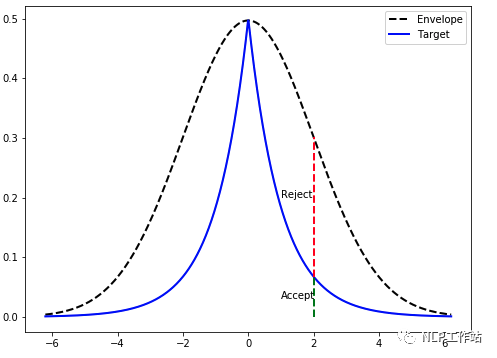 上图,一旦我们找到了q(x)的一个样本(在这个例子中,x=2),我们就会从一个均匀分布中取样,其范围等于Mq(x)的高度。如果它在目标概率密度函数的高度之内,我们就接受它(绿色表示);否则,我们就拒绝它。
上图,一旦我们找到了q(x)的一个样本(在这个例子中,x=2),我们就会从一个均匀分布中取样,其范围等于Mq(x)的高度。如果它在目标概率密度函数的高度之内,我们就接受它(绿色表示);否则,我们就拒绝它。
结合我们这里的生成模型背景,我们这里提到的拒绝采样微调通常是说在一个微调过的模型基础上面(可能是SFT微调也可能是经过PPO算法微调等)进行K个样本采样。然后我们有一个拒绝或者接受函数来对模型采样生成的样本进行过滤筛选出符合我们目标分布的样本,再进行模型微调。
相关研究
拒绝抽样是一种简单而有效的微调增强技术,也用于LLM与人类偏好的对齐。
WebGPT: Browser-assisted question-answering with human feedback
Rejection sampling (best-of-n). We sampled a fixed number of answers (4, 16 or 64) from either the BC model or the RL model (if left unspecified, we used the BC model), and selected the one that was ranked highest by the reward model. We used this as an alternative method of optimizing against the reward model, which requires no additional training, but instead uses more inference-time compute.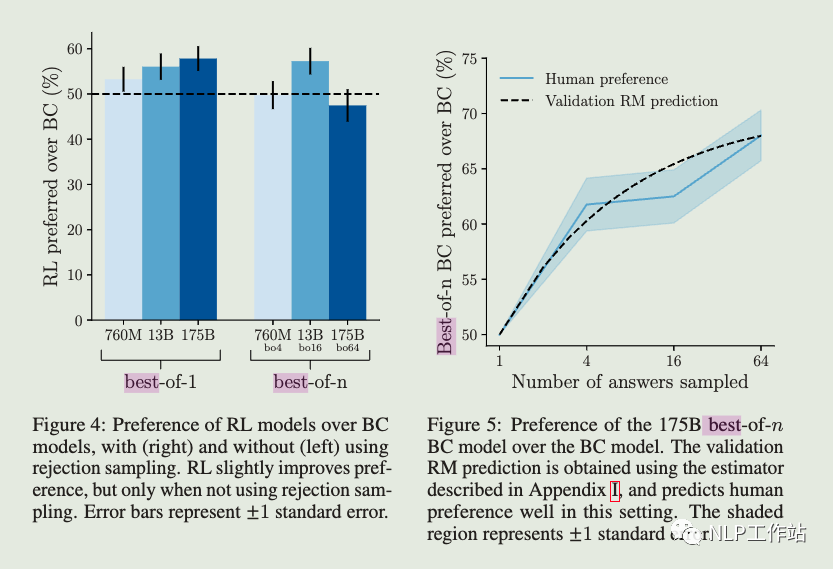 Even though both rejection sampling and RL optimize against the same reward model, there are several possible reasons why rejection sampling outperforms RL:
Even though both rejection sampling and RL optimize against the same reward model, there are several possible reasons why rejection sampling outperforms RL:
1.It may help to have many answering attempts, simply to make use of more inference-time compute.
2.The environment is unpredictable: with rejection sampling, the model can try visiting many more websites, and then evaluate the information it finds with the benefit of hindsight.
3.The reward model was trained primarily on data collected from BC and rejection sampling policies, which may have made it more robust to over optimization by rejection sampling than by RL.
4..The reward model was trained primarily on data collected from BC and rejection sampling policies, which may have made it more robust to over optimization by rejection sampling than by RL.
简单来说webgpt只是在推理阶段使用拒绝采样,并没有使用拒绝采样进行微调。然后作者比较了RL和拒绝采样的效果,发现拒绝采样会更好,并且给出了一些解释:比较认同的是拒绝采样比起RL算法来说不需要调参,更加鲁棒。
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Rejection Sampling (RS) with a 52B preference model, where samples were generated from a 52B context-distilled LM. In this case the number k of samples was a parameter, but most often we used k = 16.
We also test our online models' performance during training (Figure 15), compare various levels of rejection sampling .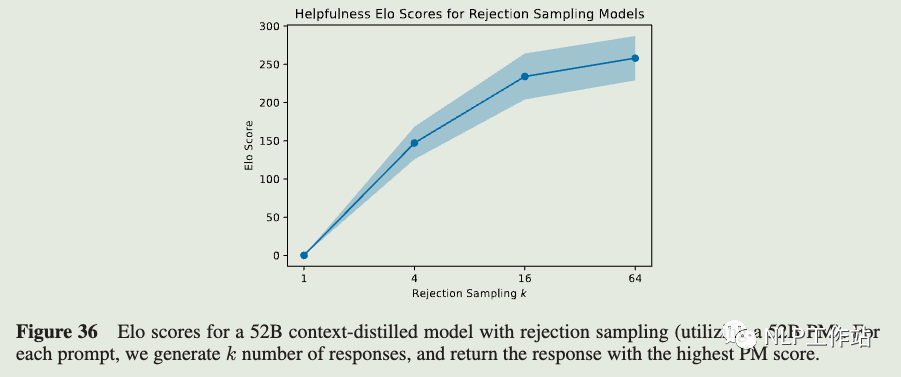 In Figure 36 we show helpfulness Elo scores for a 52B context distilled model with rejection sampling (utilizing a 52B preference model trained on pure helpfulness) for k = 1, 4, 16, 64, showing that higher values of k clearly perform better. Note that the context distilled model and the preference models discussed here were trained during an earlier stage of our research with different datasets and settings from those discussed elsewhere in the paper, so they are not directly comparable with other Elo results, though very roughly and heuristically, our online models seem to perform about as well or better than k = 64 rejection sampling. Note that k = 64 rejection sampling corresponds to DKL = log(64) ≈ 4.2.
In Figure 36 we show helpfulness Elo scores for a 52B context distilled model with rejection sampling (utilizing a 52B preference model trained on pure helpfulness) for k = 1, 4, 16, 64, showing that higher values of k clearly perform better. Note that the context distilled model and the preference models discussed here were trained during an earlier stage of our research with different datasets and settings from those discussed elsewhere in the paper, so they are not directly comparable with other Elo results, though very roughly and heuristically, our online models seem to perform about as well or better than k = 64 rejection sampling. Note that k = 64 rejection sampling corresponds to DKL = log(64) ≈ 4.2.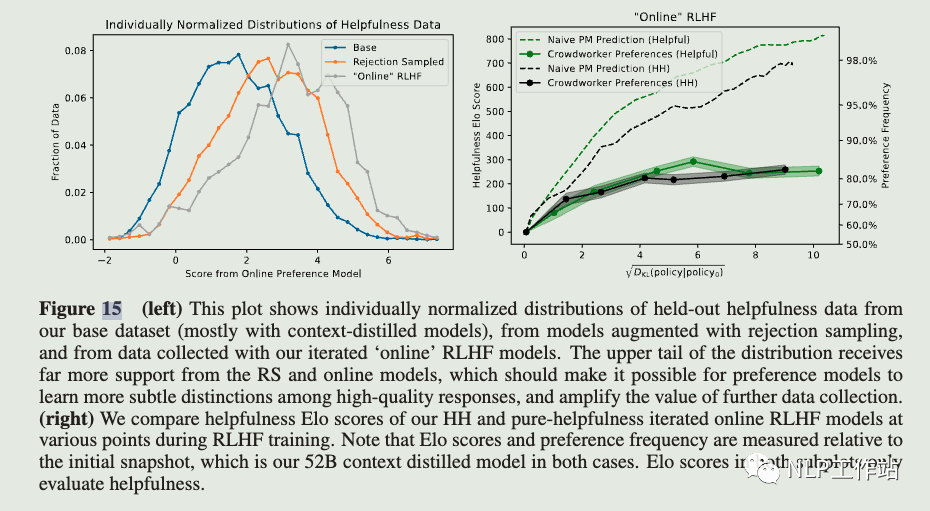
总结一下依然是在推理阶段使用拒绝采样,然后采样的时候K值越大效果越好,online RLHF 模型似乎表现的比拒绝采样更好。
Aligning Large Language Models through Synthetic Feedback
An important additional component is that we leverage the synthetic RM from the previous stage to ensure the quality of the model-tomodel conversations with rejection sampling over the generated outputs (Ouyang et al., 2022). We train LLaMA-7B on the synthetic demonstrations (SFT) and further optimize the model with rewards from the synthetic RM, namely, Reinforcement Learning from Synthetic Feedback (RLSF).
To ensure a more aligned response from the assistant, we suggest including the synthetic RM, trained in the first stage, in the loop, namely Reward-Model-guided SelfPlay (RMSP). In this setup, the assistant model,LLaMA-30B-Faithful-3shot, first samples N responses for a given conversational context. Then, the RM scores the N responses, and the best-scored response is chosen as the final response for the simulation, i.e., the RM performs rejection sampling (best-of-N sampling) (Nakano et al., 2021; Ouyang et al., 2022). Other procedures are the same as the Self-Play. Please see Figure 8 for the examples.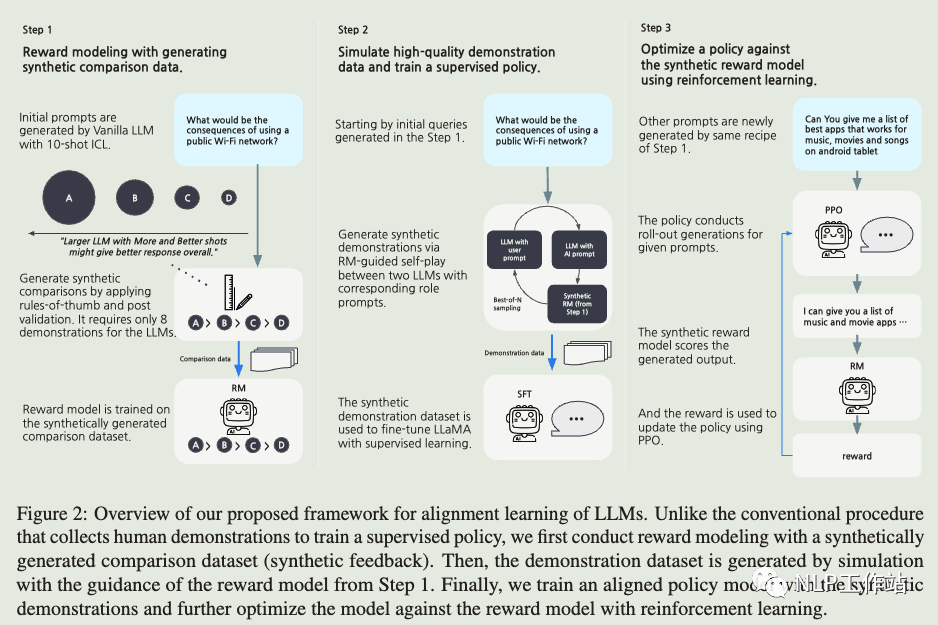 与前两篇文章不同的是这里使用拒绝采样得到的数据进行微调了,利用ICL生成不同级别模型对prompt的response,然后前提假设大模型对回答效果好于小模型,得到偏好数据训练得到RM模型。然后使用拒绝采样,使用RM模型选出分数最高的response得到训练集,使用SFT训练模型。
与前两篇文章不同的是这里使用拒绝采样得到的数据进行微调了,利用ICL生成不同级别模型对prompt的response,然后前提假设大模型对回答效果好于小模型,得到偏好数据训练得到RM模型。然后使用拒绝采样,使用RM模型选出分数最高的response得到训练集,使用SFT训练模型。
Llama 2: Open Foundation and Fine-Tuned Chat Models
 This process begins with the pretraining of Llama 2 using publicly available online sources. Following this, we create an initial version of Llama 2-Chat through the application of supervised fine-tuning. Subsequently, the model is iteratively refined using Reinforcement Learning with Human Feedback (RLHF) methodologies, specifically through rejection sampling and Proximal Policy Optimization (PPO). Throughout the RLHF stage, the accumulation of iterative reward modeling data in parallel with model enhancements is crucial to ensure the reward models remain within distribution.
This process begins with the pretraining of Llama 2 using publicly available online sources. Following this, we create an initial version of Llama 2-Chat through the application of supervised fine-tuning. Subsequently, the model is iteratively refined using Reinforcement Learning with Human Feedback (RLHF) methodologies, specifically through rejection sampling and Proximal Policy Optimization (PPO). Throughout the RLHF stage, the accumulation of iterative reward modeling data in parallel with model enhancements is crucial to ensure the reward models remain within distribution. Rejection Sampling fine-tuning. We sample K outputs from the model and select the best candidate with our reward, consistent with Bai et al. (2022b). The same re-ranking strategy for LLMs was also proposed in Deng et al. (2019), where the reward is seen as an energy function. Here, we go one step further, and use the selected outputs for a gradient update. For each prompt, the sample obtaining the highest reward score is considered the new gold standard. Similar to Scialom et al. (2020a), we then fine-tune our model on the new set of ranked samples, reinforcing the reward.
Rejection Sampling fine-tuning. We sample K outputs from the model and select the best candidate with our reward, consistent with Bai et al. (2022b). The same re-ranking strategy for LLMs was also proposed in Deng et al. (2019), where the reward is seen as an energy function. Here, we go one step further, and use the selected outputs for a gradient update. For each prompt, the sample obtaining the highest reward score is considered the new gold standard. Similar to Scialom et al. (2020a), we then fine-tune our model on the new set of ranked samples, reinforcing the reward.
The two RL algorithms mainly differ in:
Breadth — in Rejection Sampling, the model explores K samples for a given prompt, while only one generation is done for PPO.
Depth — in PPO, during training at step t the sample is a function of the updated model policy fromt − 1 after the gradient update of the previous step. In Rejection Sampling fine-tuning, we sample all the outputs given the initial policy of our model to collect a new dataset, before applying the fine-tuning similar to SFT. However, since we applied iterative model updates, the fundamental differences between the two RL algorithms are less pronounced.
总结一下使用的RLHF基准是PPO和拒绝采样(RS)微调(类似于N次采样中的最佳值)。PPO是最受欢迎 on policy RL算法(可以说是试错学习)。这里重点提到了Here, we go one step further, and use the selected outputs for a gradient update. For each prompt, the sample obtaining the highest reward score is considered the new gold standard. Similar to Scialom et al. (2020a), we then fine-tune our model on the new set of ranked samples, reinforcing the reward.
说明了llama用rm进行拒绝采样生成的样本进行了SFT训练,更新策略模型的梯度,同时,他们还将拒绝采样生成的样本作为gold 在旧的checkpoint上面重新训练RM模型,加强rm模型奖励。所以笔者认为这里的拒绝采样微调是同时对SFT和RM模型进行微调迭代。
SCALING RELATIONSHIP ON LEARNING MATHEMATI-CAL REASONING WITH LARGE LANGUAGE MODELS
To augment more data samples for improving model performances without any human effort, we propose to apply Rejection sampling Fine-Tuning (RFT). RFT uses supervised models to generate and collect correct reasoning paths as augmented fine-tuning datasets. We find with augmented samples containing more distinct reasoning paths, RFT improves mathematical reasoning performance more for LLMs. We also find RFT brings more improvement for less performant LLMs. Furthermore, we combine rejection samples from multiple models which push LLaMA-7B to an accuracy of 49.3% and outperforms the supervised fine-tuning (SFT) accuracy of 35.9% significantly. 图中相比SFT模型RFT模型效果在GSM8k上面提升明显
图中相比SFT模型RFT模型效果在GSM8k上面提升明显
总的来说了在没有任何人力的情况下增加更多数据样本以提高模型性能,我们建议应用拒绝采样微调 (RFT)。RFT 使用监督模型生成和收集正确的推理路径作为增强微调数据集。我们发现使用包含更多不同推理路径的增强样本,RFT 对 LLM 提高了数学推理性能。我们还发现 RFT 为性能较低的 LLM 带来了更多改进。此外,我们结合了来自多个模型的拒绝样本,将 LLAMA-7B 推向 49.3% 的准确率,并且显着优于 35.9% 的监督微调 (SFT) 准确度。值得注意的上不同于上面使用的是RM模型来执行拒绝采样选出最好的response,这里直接使用的模型reponse给出答案和正确的答案比较,选出推理正确的结果。
RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
However, the inefficiencies and instabilities associated with RL algorithms frequently present substantial obstacles to the successful alignment of generative models, necessitating the development of a more robust and streamlined approach. To this end, we introduce a new framework, Reward rAnked FineTuning (RAFT), designed to align generative models more effectively. Utilizing a reward model and a sufficient number of samples, our approach selects the high-quality samples, discarding those that exhibit undesired behavior, and subsequently assembles a streaming dataset. This dataset serves as the basis for aligning the generative model and can be employed under both offline and online settings. Notably, the sample generation process within RAFT is gradient-free, rendering it compatible with black-box generators. Through extensive experiments, we demonstrate that our proposed algorithm exhibits strong performance in the context of both large language models and diffusion models.

总结与思考
拒绝采样使得SFT模型输出的结果分布通过拒绝/接受函数筛选(这里可以是奖励模型也可以是启发式规则),得到了高质量回答的分布。提高了最终返回的效果。对于拒绝采样来说采样的样本K越大越好。同时在RLHF框架里面,使用拒绝采样微调一是可以用来更新SFT模型的效果,对于ppo算法来说,往往需要保证旧的策略和新的策略分布差距比较小,所以这里提高PPO启动的SFT模型效果对于PPO算法本身来说也很重要,其次还可以利用拒绝采样的样本微调来迭代旧的奖励模型,加强模型的奖励。这个对于提高PPO最终效果和迭代也十分重要。同时针对COT能力来说,拒绝采样提供了更多的推理路径来供模型学习。这对于模型来说也非常重要。
进NLP群—>加入NLP交流群