
目录
一.引言
一早醒来国产开源大模型又添一员猛将,书生-浦语大模型 InternLM-20B 大模型发布并开源,这里字面翻译是实习生大模型,比较有意思。该模型由上海人工智能实验室与商汤科技联合香港中文大学和复旦大学联合推出。模型地址: https://huggingface.co/internlm/internlm-chat-20b
二.模型简介
1.模型特性
InternLM 20B 在模型结构上选择了深结构,层数设定为 60 层,超过常规 7B 和 13B 模型所使用的32 层或者 40 层,这也是模型尺寸达到 20B 的原因。在参数受限的情况下,提高层数有利于提高模型的综合能力。此外,相较于 InternLM-7B,InternLM-20B 使用的预训练数据经过了更高质量的清洗,并补充了高知识密度和用于强化理解与推理能力的训练数据。因此,它在理解能力、推理能力、数学能力、编程能力等考验语言模型技术水平的方面都得到了显著提升。总体而言,InternLM-20B 具有以下的特点:
- 优异的综合性能
- 很强的工具调用功能
- 支持16k语境长度(通过推理时外推)
- 更好的价值对齐
2.模型评测
在OpenCompass提出的5个能力维度上,InternLM-20B都取得很好的效果(粗体为13B-33B这个量级范围内,各项最佳成绩):
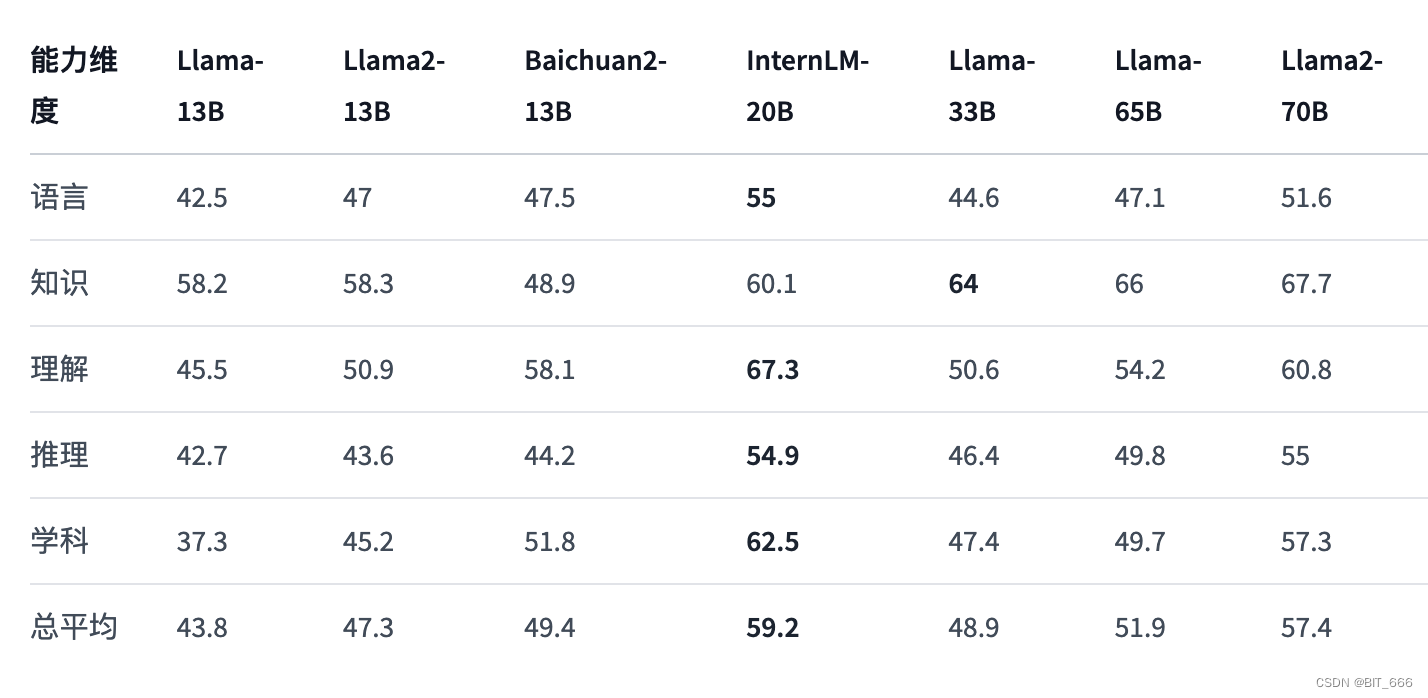
在博主全面拥抱 baichuan2-13B 和 LLaMA-33B 的同时,InternLM-20B 的出现不可谓是一个奇兵,后续博主也会拥抱 InternLM-20B 并分享相关经验:

三.模型尝试
1.模型参数
模型的 hidden_layers 增加至 60,对比 Baichuan-2 的 layers 数目为 40,另外词库的大小也增加至 103168。

2.generate 与 chat
官方 demo 和 modeling.py 中给出了相关 chat 与 generate 的示例。
◆ generate
from transformers import AutoTokenizer, InternLMForCausalLM
model = InternLMForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
prompt = "Hey, are you consciours? Can you talk to me?"
inputs = tokenizer(prompt, return_tensors="pt")
# Generate
generate_ids = model.generate(inputs.input_ids, max_length=30)
tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
◆ chat
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True)
print(tokenizer)
model = AutoModelForCausalLM.from_pretrained(path, trust_remote_code=True)
print(model)
model = model.eval()
output, history = model.chat(tokenizer, "你好呀!今天天气真好")
print(output)3.模型微调
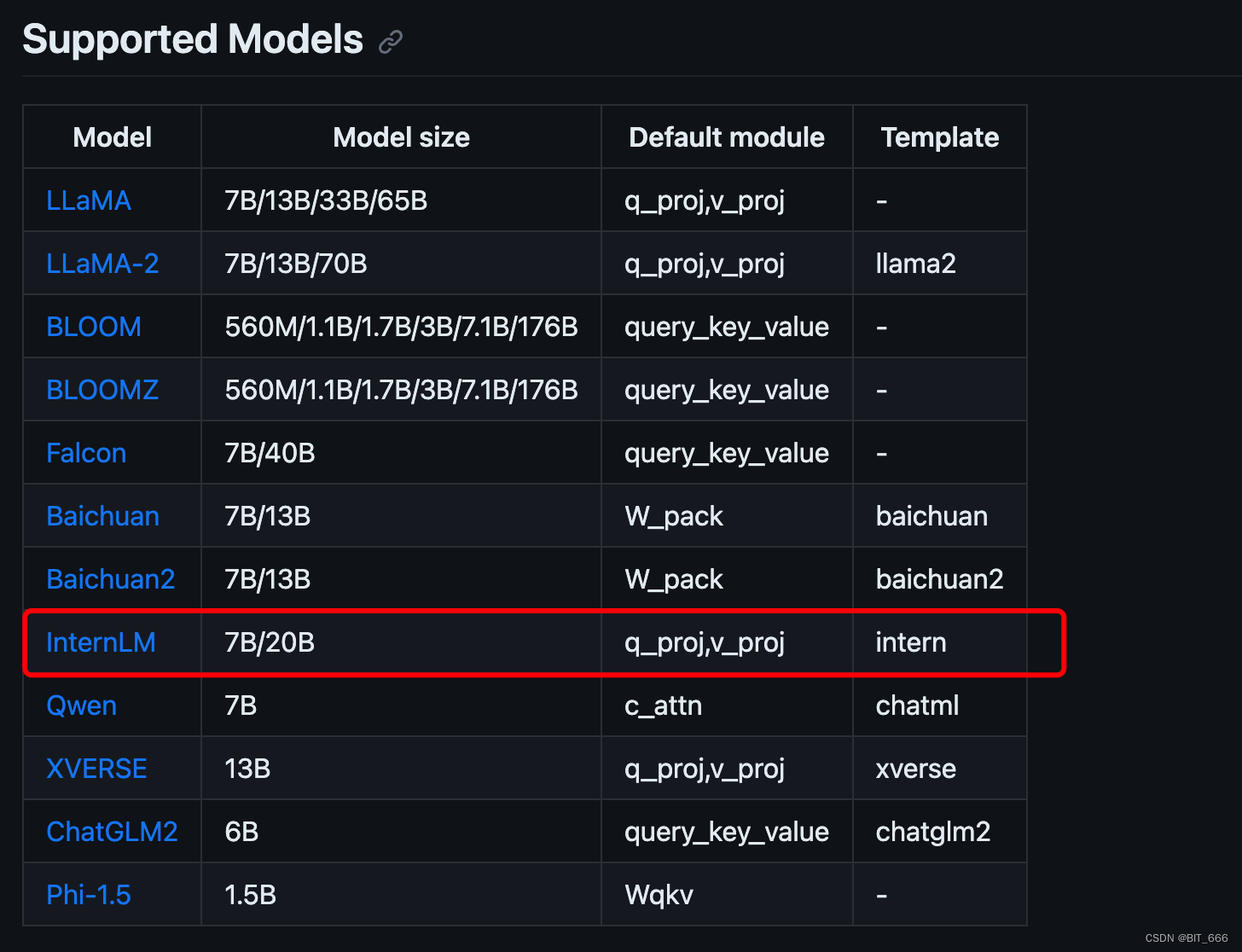
目前最新版的 LLaMA-Efficient-Tuning 框架已支持 InternLM-20B 的 LoRA 微调,注意选择正确的 lora_target 与 template 模板:
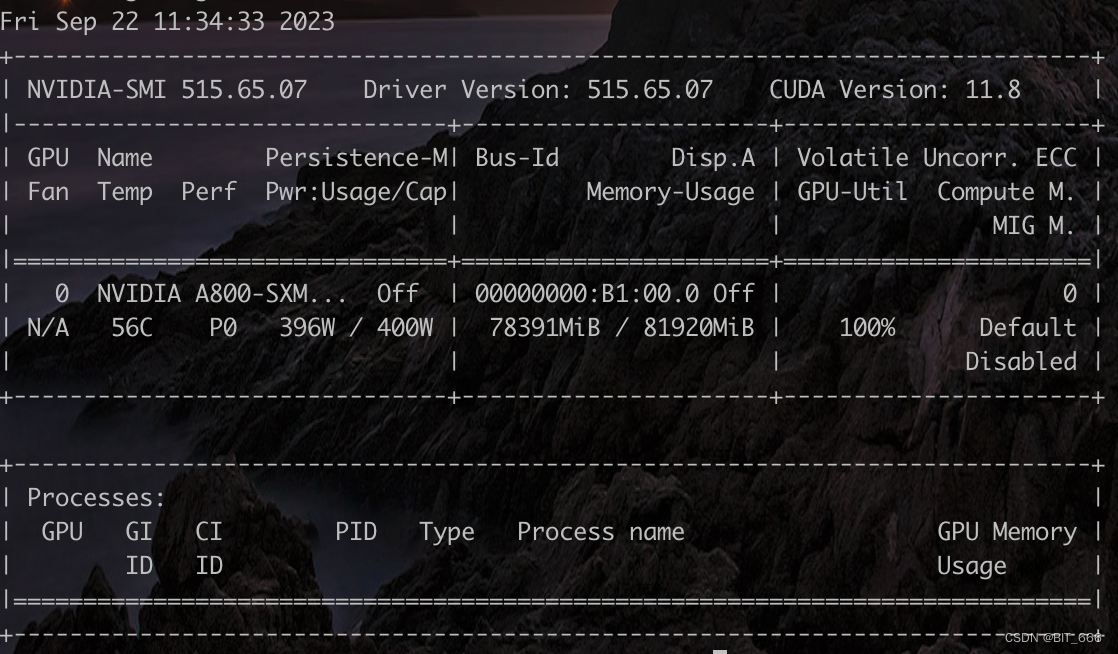
博主在 A800 机器以 batch_size = 8 ,target = q_proj,v_proj LoRA 微调 InternLM-20B-chat 显存占用如下,非常的极限:
LoRA 参数占比如下,如果想微调更多的参数,可以降低 batch_size,提高 Gradient Accumulation steps 达到更大 batch 的效果:
trainable params: 9830400 || all params: 20098544640 || trainable%: 0.0489四.总结
终于出了介于 13B 和 33B 之间的模型了,博主对 InternLM 实习生大模型还是抱有很大期待,期望后续能够有更加惊艳的表现。