参考《大规模语言模型--从理论到实践》
目录
一、综述
语言模型目标是建模自然语言的概率分布,在自然语言处理研究中具有重要的作用,是自然 语言处理基础任务之一。大量的研究从 n 元语言模型(n-gram Language Models)、神经语言模 型(Neural Language Models,NLM)以及预训练语言模型(Pre-trained Language Models,PLM) 等不同角度开展了系列工作。这些研究在不同阶段都对自然语言处理任务有着重要作用。随着基 于 Transformer 各类语言模型的发展以及预训练微调范式在自然语言处理各类任务中取得突破性 进展,从 2020 年 OpenAI 发布 GPT-3 开始,大语言模型研究也逐渐深入。虽然大语言模型的参数 量巨大,通过有监督微调和强化学习能够完成非常多的任务,但是其基础理论也仍然离不开对语 言的建模。
本章将首先介绍 Transformer 结构,并在此基础上介绍生成式预训练语言模型 GPT、大语言模
型网络结构和注意力机制优化以及相关实践。n 元语言模型、神经语言模型以及其它预训练语言
模型可以参考《自然语言处理导论》第 6 章[8],这里就不再赘述。
二、Transformer 模型
Transformer 模型[48] 是由谷歌在 2017 年提出并首先应用于机器翻译的神经网络模型结构。机
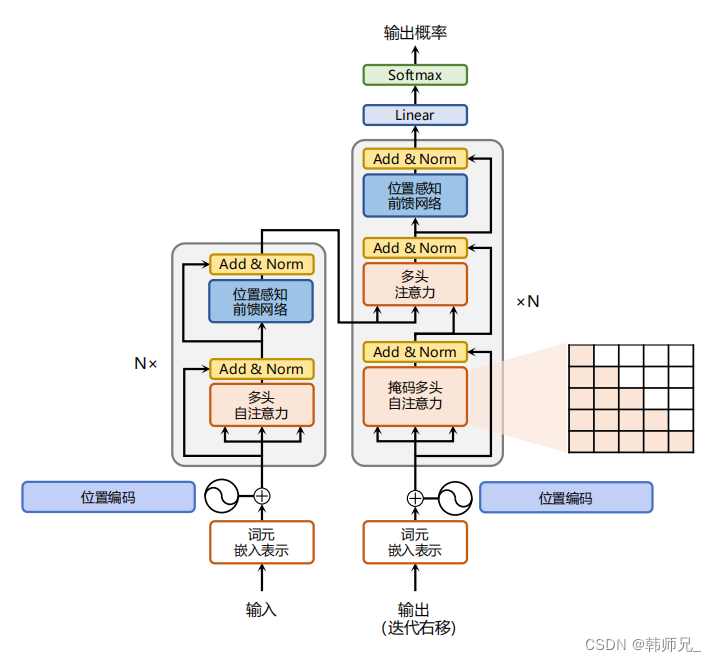
器翻译的目标是从源语言(Source Language)转换到目标语言(Target Language)。Transformer 结 构完全通过注意力机制完成对源语言序列和目标语言序列全局依赖的建模。当前几乎全部大语言 模型都是基于 Transformer 结构,本节以应用于机器翻译的基于 Transformer 的编码器和解码器介 绍该模型。 基于 Transformer 结构的编码器和解码器结构如图2.1所示,左侧和右侧分别对应着编码器(Encoder)和解码器(Decoder)结构。它们均由若干个基本的Transformer 块(Block)组成(对应着图 中的灰色框)。这里 N× 表示进行了 N 次堆叠。每个 Transformer 块都接收一个向量序列 {
xi}作为输入,并输出一个等长的向量序列作为输出 {
yi}。这里的 xi 和 yi 分别对应着文本序列 中的一个单词的表示。而 yi 是当前 Transformer 块对输入 xi 进一步整合其上下文语义后对应的输 出。在从输入 {
xi}t到输出 {
yi}t的语义抽象过程中,主要涉及到如下几个模块:
- 注意力层:使用多头注意力(Multi-Head Attention)机制整合上下文语义,它使得序列中任意两个单词之间的依赖关系可以直接被建模而不基于传统的循环结构,从而更好地解决文本 的长程依赖。
- 位置感知前馈层(Position-wise FFN):通过全连接层对输入文本序列中的每个单词表示进行 更复杂的变换。
- 残差连接:对应图中的 Add 部分。它是一条分别作用在上述两个子层当中的直连通路,被用 于连接它们的输入与输出。从而使得信息流动更加高效,有利于模型的优化。
- 层归一化:对应图中的 Norm 部分。作用于上述两个子层的输出表示序列中,对表示序列进 行层归一化操作,同样起到稳定优化的作用。
三、 嵌入表示层(位置编码)
对于输入文本序列,首先通过输入嵌入层(Input Embedding)将每个单词转换为其相对应的 向量表示。通常直接对每个单词创建一个向量表示。由于 Transfomer 模型不再使用基于循环的方 式建模文本输入,序列中不再有任何信息能够提示模型单词之间的相对位置关系。在送入编码器 端建模其上下文语义之前,一个非常重要的操作是在词嵌入中加入位置编码(Positional Encoding) 这一特征。具体来说,序列中每一个单词所在的位置都对应一个向量。这一向量会与单词表示对 应相加并送入到后续模块中做进一步处理。在训练的过程当中,模型会自动地学习到如何利用这 部分位置信息。 为了得到不同位置对应的编码,Transformer 模型使用不同频率的正余弦函数如下所示:
PE(pos, 2i) = sin( pos 100002i/d ) (1)
PE(pos, 2i + 1) = cos( pos 100002i/d ) (2)
其中,pos 表示单词所在的位置,2i 和 2i+ 1 表示位置编码向量中的对应维度,d 则对应位置编码的 总维度。通过上面这种方式计算位置编码有这样几个好处:
首先,正余弦函数的范围是在 [-1,+1], 导出的位置编码与原词嵌入相加不会使得结果偏离过远而破坏原有单词的语义信息。其次,依据 三角函数的基本性质,可以得知第 pos + k 个位置的编码是第 pos 个位置的编码的线性组合,这就 意味着位置编码中蕴含着单词之间的距离信息。
使用 Pytorch 实现的位置编码参考代码如下:
import torch.nn as nn
import torch
import math
from torch.autograd import Variable
class PositionalEncoder(nn.Module):
def __init__(self, d_model, max_seq_len = 80):
super().__init__()
self.d_model = d_model
# 根据 pos 和 i 创建一个常量 PE 矩阵
pe = torch.zeros(max_seq_len, d_model)
for pos in range(max_seq_len):
for i in range(0, d_model, 2):
pe[pos, i] = math.sin(pos / (10000 ** ((2 * i)/d_model)))
pe[pos, i + 1] = math.cos(pos / (10000 ** ((2 * (i + 1))/d_model)))
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
# 使得单词嵌入表示相对大一些
x = x * math.sqrt(self.d_model)
# 增加位置常量到单词嵌入表示中
seq_len = x.size(1)
x = x + Variable(self.pe[:,:seq_len], requires_grad=False).cuda()
return x
pos_en = PositionalEncoder(d_model=64)
x = torch.randn(100, 1, dtype=torch.float32).cuda() # 100 x 1
print(pos_en(x).shape) # 100 x 64
print('')