code地址:https://github.com/CVI-SZU/Linly ::::伶荔(Linly)
0 Linly-OpenLLaMA基础模型【从头训练LLaMA】https://github.com/CVI-SZU/Linly/wiki/Linly-OpenLLaMA
Linly-OpenLLaMA模型在大规模中英文语料上从头训练词表和模型参数,包含3B、7B、13B规模,在1TB中英文语料预训练,针对中文优化字词结合tokenizer,使用的数据包含中、英文无监督数据和平行语料,在语料上重新训练spm tokenizer,在中文上获得字词结合的分词效果。与Meta的原始LLaMA相同的模型结构和训练参数从头预训练。 模型以 Apache License 2.0 协议开源,支持商业用途。训练细节
0.0 构建 tokenizer
- 首先在大规模中英文语料上训练 SPM,词表大小为 50000。
- 根据结巴分词词频前20000的词表扩充中文词,并扩充简繁体汉字。扩充后词表大小为 66242。
0.1 预训练数据
在第一阶段预训练,共使用100GB语料,其中20G中文语料、10G平行语料、70G英文语料。

0.2 模型结构
Linly-OpenLLaMA使用和Meta相同的模型结构
0.3 预训练参数
基本上采用 LLaMA 的训练参数,其中 Batch Size 通过梯度累积实现。
- Sequence Length: 2048
- Batch Size: 4096
- Learning Rate: 3e-4
- cosine schedule, 0.1 weight decay
0.4 预测--模型下载OpenLLaMA-13B:Linly-AI/OpenLLaMA-13B at main
Linly-OpenLLaMA 模型在大规模中英文语料上从头训练词表和模型参数,与原始 LLaMA 模型结构和使用方法一致。 模型以 Apache License 2.0 协议开源,支持商业用途。训练细节
| 模型下载 | 分类 | 训练数据 | 训练序列长度 | 版本 | 更新时间 |
|---|---|---|---|---|---|
| OpenLLaMA-13B | 基础模型 | 100G 通用语料 | 2048 | v0.1 | 2023.5.29 |
1 增量训练中文Falcon基础模型:模型实现和训练细节
天天向上o:LLM/a0排行榜__HuggingFaced的open_llm_leaderboard

Falcon系列模型使用经过筛选的1万亿tokens进行预训练,然而Falcon模型在使用上面临和 LLaMA模型类似的问题:1)由于模型主要在英文数据集上训练,因此它理解和生成中文的能力偏弱;2)Falcon 在构建词表时没有加入中文字/词,中文字会被拆分成多个 token 的组合,这导致中文文本会被拆分成更长的 tokens 序列,降低了编码和生成效率。
针对以上问题,“伶荔Linly”项目团队以 Falcon 模型为底座扩充中文词表,利用中文和中英平行增量预训练将模型的语言能力迁移学习到中文,实现 Chinese-Falcon。本文介绍中文Falcon的实现方案:包括数据集构建、中文字词扩充、模型结构【Falcon、LLaMA 与传统 GPT 的异同】和训练参数等。
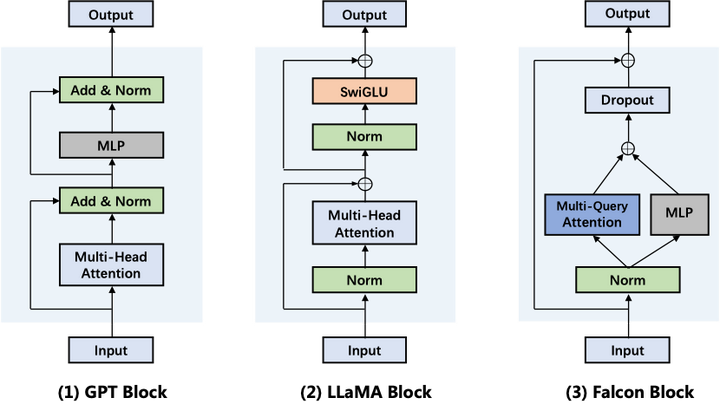
1.1 Falcon模型结构:GPT、LLaMA和Falcon的计算流程对比
Falcon与GPT系列一样采用单向Transformer-decoder模型架构,并以语言模型作为训练目标。与GPT-3相比,Falco的结构具有如下变化:1. 位置编码:Falcon使用旋转位置编码(RoPE),近期的大模型包括GPT-Neo、PaLM和LLaMA等都采用了RoPE。2. 注意力机制:使用Multi-Query将key和value映射到单个注意力头,只有query保留多头矩阵,这种简化方案能提升生成效率;使用FlashAttention将注意力矩阵分块,加速计算并降低内存IO开销。3. Transformer:只使用单个layer_norm层,将Attention和MLP并行。
从Transformer模型结构上看,LLaMA将Layer-Norm层放在Ateention和FFN的输入,这样有助于大模型训练稳定性(由GPT2论文提出),FFN部分使用了门控线性层(GLU),这种结构最初被用在T5-1.1,实验效果优于MLP。LLaMA的设计着重于性能提升;;而Falcon对Transformer的改进着重于效率提升:将Layer-Norm层减少到一个并简化了注意力的计算(Multi-Query Attention),因此Falcon比LLaMA的生成速度更快。
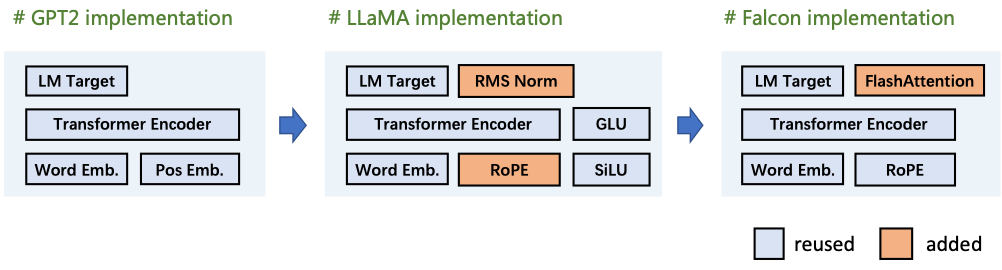
“伶荔(Linly)”项目中Falcon实现方案:使用TencentPretrain复现Falcon模型结构,用语言模型目标增量训练模型。根据Falcom的模型结构,新增了FlashAttention(Multi-Query)模块,复用已有的MLP、Transformer、LM_target等模块,来复现Falcon模型。。。。TencentPretrain 是 UER-py 预训练框架的多模态版本,支持 BERT、GPT、T5、ViT、Dall-E、Speech2Text 等文本、图像和语音预训练模型及下游任务。TencentPretrain 基于模块化设计,可以通过模块组合的方式构成各种模型,也可以通过复用已有的模块进行少量修改来实现新的模型。
不同模型使用到的模块如下图所示:
1.2 数据构建
中文字词扩充:首先扩充Falcon词表,包括 8,701 个常用汉字,jieba 词表中前 20,000个中文高频词以及 60 个中文标点符号。去重后共增加 25,022 个 token,词表大小扩充为 90,046。改变词表后,embedding 和 target.output_layer 矩阵也要对应的扩充。将每个新增字/词在原始 tokenizer 中的对应向量的平均作为初始化。
数据集构建:在第一阶段使用50GB数据进行预训练,其中20G中文通用语料为模型提供中文语言能力和中文知识,10G中英文平行语料用于对齐模型的中英文表示,将英文语言能力迁移到中文上,20G英文语料用于数据回放,缓解模型遗忘。数据已在Linly项目中公开,细节如图所示:

1.3 训练
在模型训练阶段使用与Falcon预训练相同的超参数设置:AdamW,ZeRO Optimizer,Batch size 2304,对于增量训练,我们设置更低的学习率2e-5。
作为中文embedding初始化,先冻结Transformer权重,只更新embedding和output_layer部分,训练16k steps。进一步,在通用语料上启动全参数训练(Full-tuning)
除了第一阶段的50GB语料外,还将使用自建中文数据集和SlimPajama数据集共2TB语料训练中文Falcon基础模型,在伶荔项目中持续更新。
预训练框架:https://github.com/Tencent/Tenc
增量训练:https://github.com/CVI-SZU/Linly/wiki/%E5%A2%9E%E9%87%8F%E8%AE%AD%E7%BB%83
LoRA训练:https://github.com/CVI-SZU/Linly/wiki/LoRA%E8%AE%AD%E7%BB%83
1.4 预测--模型下载Linly-Chinese-Falcon:Linly-AI/Chinese-Falcon-7B at main
Chinese-Falcon 模型在 Falcon 基础上扩充中文词表,在中英文数据上增量预训练。 模型以 Apache License 2.0 协议开源,支持商业用途。模型实现和训练细节
| 模型下载 | 分类 | 训练数据 | 训练序列长度 | 版本 | 更新时间 |
|---|---|---|---|---|---|
| Chinese-Falcon-7B (hf格式) | 基础模型 | 50G 通用语料 | 2048 | v0.2 | 2023.6.15 |
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "Linly-AI/Chinese-Falcon-7B"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"User: 你如何看待996?\nBot: 我认为996制度是一种不可取的工作时间安排,因为这会导致员工过多的劳累和身心健康问题。此外,如果公司想要提高生产效率,应该采用更有效的管理方式,而不是通过强行加大工作量来达到目的。\nUser: 那么你有什么建议?\nBot:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")2 伶荔(Linly)
以LLaMA为底座-基于LLaMA权重和词表,利用中文和中英平行数据增量预训练,将它在英文上语言能力迁移到中文上;基于TencentPretrain预训练框架全参数训练(Full-tuning)得到中文基础模型Linly-Chinese-LLaMA。进一步汇总目前公开的多语言指令数据,对中文基础模型Linly-Chinese-LLaMA进行了大规模指令训练,实现 Linly-ChatFlow中文对话模型。

| 模型下载 | 分类 | 训练数据 | 训练序列长度 | 版本 | 更新时间 |
|---|---|---|---|---|---|
| Chinese-LLaMA-7B | 基础模型 | 100G 通用语料 | 2048 | v1.2 | 2023.5.29 |
| ChatFlow-7B | 对话模型 | 5M 指令数据 | 1024 | v1.1 | 2023.5.14 |
| Chinese-LLaMA-13B | 基础模型 | 100G 通用语料 | 2048 | v1.2 | 2023.5.29 |
| ChatFlow-13B | 对话模型 | 5M 指令数据 | 1024 | v1.1 | 2023.5.14 |
| Chinese-LLaMA-33B (hf格式) | 基础模型 | 30G 通用语料 | 512 | v1.0 | 2023.4.27 |

参考文献:
天天向上o:LLM/a0排行榜__HuggingFaced的open_llm_leaderboard