A Survey of Large Language Models
前言
随着人工智能和机器学习领域的迅速发展,语言模型已经从简单的词袋模型(Bag-of-Words)和N-gram模型演变为更为复杂和强大的神经网络模型。在这一进程中,大型语言模型(LLM)尤为引人注目,它们不仅在自然语言处理(NLP)任务中表现出色,而且在各种跨领域应用中也展示了惊人的潜力。从生成文本和对话系统到更为复杂的任务,如文本摘要、机器翻译和情感分析,LLM正在逐渐改变我们与数字世界的互动方式。
然而,随着模型规模的增加,也出现了一系列挑战和问题,包括但不限于计算复杂性、数据偏见以及模型可解释性。因此,对这些模型进行全面而深入的了解变得至关重要。
本博客旨在提供一个全面的大型语言模型综述,探讨其工作原理、应用范围、优点与局限,以及未来的发展趋势。无论您是该领域的研究者、开发者,还是对人工智能有广泛兴趣的读者,这篇综述都将为您提供宝贵的洞见。
本系列文章内容大部分来自论文《A Survey of Large Language Models》,旨在使读者对大模型系列有一个比较程序化的认识。
论文地址:https://arxiv.org/abs/2303.18223
4. PRE-TRAINING
预训练建立了LLM(大型语言模型)的能力基础。通过在大规模语料库上进行预训练,LLM可以获得关键的语言理解和生成技能[55, 56]。在这个过程中,预训练语料库的规模和质量对于LLM获得强大的能力至关重要。此外,为了有效地预训练LLM,模型架构、加速方法和优化技术需要设计得很好。接下来,我们首先在第4.1节讨论数据收集和处理,然后在第4.2节介绍常用的模型架构,最后在第4.3节介绍稳定和高效优化LLM的训练技术。
4.1数据收集
与小规模语言模型相比,LLM对于模型预训练需要更高质量的数据,并且它们的模型能力在很大程度上依赖于预训练语料库以及它们的预处理方式。在这一部分中,我们将讨论预训练数据的收集和处理,包括数据来源、预处理方法,以及对预训练数据如何影响LLM性能的重要分析。
4.1.1 数据源
要开发出一款具备能力的LLM,关键在于从各种数据来源收集大量的自然语言语料库。现有的LLM主要利用多样性的公共文本数据集混合作为预训练语料库。图5显示了一些代表性LLM的预训练数据来源分布情况。
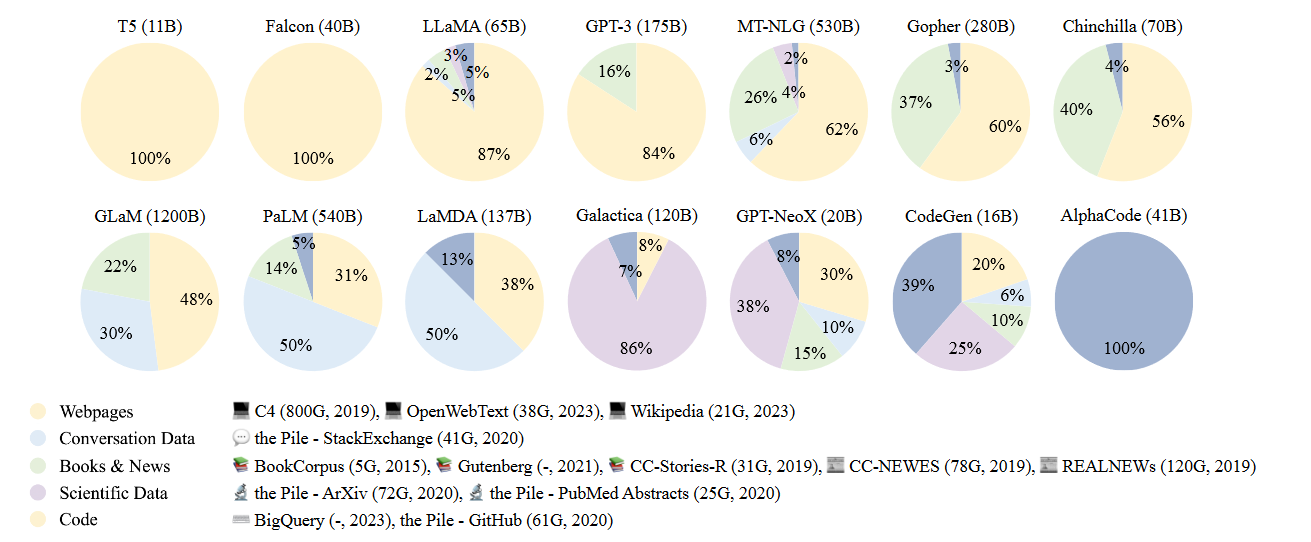
图5:现有LLM预训练数据中各种数据源的比例。
预训练语料库的来源可以大致分为两种类型:一般数据和专业数据。一般数据,如网页、书籍和对话文本,由大多数LLM(大型语言模型)利用[55, 56, 81],因为它具有大规模、多样性和易获取的特点,可以增强LLM的语言建模和泛化能力。鉴于LLM表现出的出色泛化能力,还有研究将它们的预训练语料库扩展到更专业的数据集,如多语言数据、科学数据和代码,赋予LLM具体的任务解决能力[35, 56, 77]。接下来,我们将描述这两种类型的预训练数据来源以及它们对LLM的影响。有关常用语料库的详细介绍,可以参考第3.2节。
General Text Data(一般本文数据)
如图5所示,绝大多数LLMs采用通用预训练数据,例如网页、书籍和对话文本,这些数据提供了各种主题的丰富文本资源。接下来,我们简要总结了三种重要的通用数据类型。
• 网页。由于互联网的普及,产生了各种类型的数据,这使得LLMs能够获取多样化的语言知识并增强其泛化能力[26, 73]。为了方便利用这些数据资源,以前的工作从网络上爬取了大量数据,例如CommonCrawl [148]。然而,爬取的网络数据往往包含高质量文本,如维基百科,以及低质量文本,比如垃圾邮件,因此过滤和处理网页以提高数据质量非常重要。
• 对话文本。对话数据可以增强LLMs的对话能力[81],并有可能提高它们在各种问答任务上的性能[56]。研究人员可以利用公共对话语料库的子集(例如PushShift.io Reddit语料库)[143, 162],或者从在线社交媒体收集对话数据。由于在线对话数据通常涉及多个参与者之间的讨论,一种有效的处理方式是将对话转化为树状结构,其中话语与其回应的话语相连。通过这种方式,多方对话树可以分成多个子对话,可以被收集到预训练语料库中。此外,一个潜在的风险是,过度整合对话数据到LLMs中可能会导致副作用[81]:陈述性指令和直接疑问句被错误地视为对话的开始,从而导致指令的效力下降。
• 书籍。与其他语料库相比,书籍提供了一种重要的正式长文本的来源,这对LLMs学习语言知识、建模长期依赖性以及生成连贯叙述文本可能有益。为了获取开源书籍数据,现有研究通常采用Books3和Bookcorpus2数据集,这些数据集可以在Pile数据集中找到[146]。
专业化文本数据
专业化数据集对于提升LLMs在下游任务上的特定能力非常有用。接下来,我们介绍三种专业化数据类型。
• 多语言文本。除了目标语言的文本之外,整合多语言语料库可以增强语言理解和生成的多语言能力。例如,BLOOM [69] 和 PaLM [56] 在其预训练语料库中精选了涵盖46种和122种语言的多语言数据。这些模型在多语言任务,如翻译、多语言摘要和多语言问答等方面表现出色,并且在目标语言(们)的语料库上微调的最新模型相媲美甚至优于性能。
• 科学文本。人类对科学的探索可以从科学出版物的不断增长中得以见证。为了增强LLMs对科学知识的理解[35, 163],将科学语料库纳入模型的预训练中非常有用[35, 163]。通过在大量科学文本上进行预训练,LLMs可以在科学和推理任务方面表现出色[164]。构建科学语料库时,现有的努力主要收集arXiv论文、科学教材、数学网页和其他相关科学资源。由于科学领域数据的复杂性,例如数学符号和蛋白质序列,通常需要特定的标记化和预处理技术,将这些不同格式的数据转化为可以被语言模型处理的统一形式。
• 代码。程序合成在研究社区中得到广泛研究[92, 165–168],尤其是使用在代码上训练的PLMs[150, 169]。然而,对于这些PLMs(例如GPT-J [150]),生成高质量和准确的程序仍然具有挑战性。最近的研究[92, 168]发现,将LLMs在大规模代码语料库上进行训练可以显著提高生成的程序的质量。生成的程序可以成功通过专家设计的单元测试案例[92]或解决竞技性编程问题[101]。通常,用于预训练LLMs的代码语料库有两种常见来源。第一个来源是来自编程问答社区,如Stack Exchange [170]。第二个来源是来自公共软件存储库,如GitHub [77, 92, 168],在这里收集了代码数据(包括注释和文档字符串)以供使用。与自然语言文本相比,代码采用编程语言的格式,对应于长期依赖性和准确的执行逻辑[171]。最近的研究[47]还推测,对代码的培训可能是复杂推理能力的来源(例如,思维链能力[33])。此外,已经显示,将推理任务格式化为代码可以帮助LLMs生成更准确的结果[171]。
4.1.2 数据预处理
在收集了大量文本数据之后,对数据进行预处理以构建预训练语料库非常重要,特别是要移除嘈杂、冗余、无关和潜在有害的数据[56, 59, 172],这些因素可能会极大地影响LLMs的容量和性能。为了简化数据处理,最近的一项研究[173]提出了一个名为Data-Juicer的LLMs数据处理系统,提供了50多个处理操作符和工具。在这部分中,我们将回顾改善收集数据质量的详细数据预处理策略[59, 69, 99]。预处理LLMs的预训练数据的典型流程已在图6中说明。
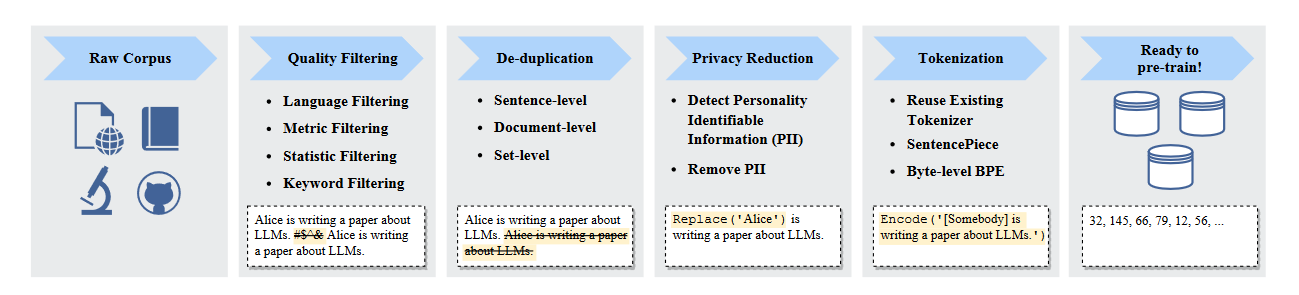
图6:典型的用于预训练大型语言模型的数据预处理流程示意图。
质量过滤
为了从收集的语料库中去除低质量数据,现有工作通常采用两种方法:(1)基于分类器,和(2)基于启发式方法。前一种方法基于高质量文本训练一个选择分类器,并利用它来识别和过滤低质量数据。通常,这些方法[55, 56, 99]使用精心策划的数据(例如维基百科页面)作为正例,将候选数据作为负例来训练二元分类器,并预测衡量每个数据示例质量的分数。然而,一些研究[59, 99]发现,基于分类器的方法可能会意外删除方言、口语和社会语言中的高质量文本,这可能导致预训练语料库中的偏见并减少语料库的多样性。作为第二种方法,一些研究,如BLOOM [69] 和Gopher [59],采用基于启发式的方法通过一组精心设计的规则来消除低质量文本,这些规则可以总结如下:
• 基于语言的过滤。如果LLM主要用于某些语言的任务,可以过滤掉其他语言的文本。
• 基于度量的过滤。可以使用生成文本的评估度量,例如困惑度(perplexity),来检测并去除不自然的句子。
• 基于统计的过滤。可以利用语料库的统计特征,例如标点分布、符号与词的比率和句子长度,来衡量文本质量并过滤低质量数据。
• 基于关键词的过滤。基于特定关键词集,可以识别和删除文本中的噪音或无用元素,例如HTML标签、超链接、模板文本和冒犯性词汇。
去重
现有研究[174]发现,语料库中的重复数据会降低语言模型的多样性,可能导致训练过程不稳定,从而影响模型性能。因此,有必要对预训练语料库进行去重。具体来说,可以在不同的粒度上执行去重,包括句子级、文档级和数据集级的去重。首先,应删除包含重复单词和短语的低质量句子,因为它们可能引入语言建模中的重复模式[175]。在文档级别上,现有研究主要依赖于文档之间表面特征(例如,词汇和n-gram的重叠)的重叠比率来检测和删除包含相似内容的重复文档[57, 59, 69, 176]。此外,为了避免数据集污染问题,还需要防止训练集和评估集之间的重叠[56],通过从训练集中删除可能的重复文本。已经显示,这三个级别的去重对于改进LLMs的训练是有用的[56, 177],在实践中应该共同使用。
隐私保护
大多数预训练文本数据来自网络来源,包括涉及敏感或个人信息的用户生成内容,这可能增加隐私泄露的风险[178]。因此,有必要从预训练语料库中删除个人可识别信息(PII)。一种直接有效的方法是采用基于规则的方法,如关键词识别,来检测和删除姓名、地址和电话号码等PII[147]。此外,研究人员还发现,LLMs在隐私攻击下的脆弱性可以归因于预训练语料库中存在重复的PII数据[179]。因此,去重也可以在一定程度上降低隐私风险。
分词
分词也是数据预处理的关键步骤。它的目标是将原始文本分割成一系列独立的标记,随后这些标记被用作LLMs的输入。在传统的自然语言处理研究中(例如,使用条件随机场进行序列标注[180]),基于单词的分词是主要的方法,这种方法更符合人类的语言认知。然而,在一些语言中,基于单词的分词可能会对相同的输入产生不同的分割结果(例如,中文分词),生成包含许多低频词汇的大词汇表,并且还会遇到“词汇外”问题。因此,一些神经网络模型使用字符作为最小单位来生成单词表示(例如,ELMo中的CNN单词编码器)。最近,在基于Transformer的语言模型中,子词标记器广泛使用,通常包括字节对编码分词、WordPiece分词和Unigram分词。HuggingFace维护了一个出色的在线自然语言处理课程,其中包含运行示例,我们建议初学者参考这个课程。接下来,我们简要描述三种代表性的分词方法。
• 字节对编码(Byte-Pair Encoding,BPE)分词。BPE最初于1994年提出作为一种通用的数据压缩算法[181],后来被改编用于自然语言处理的分词[182]。它从一组基本符号(例如,字母和边界字符)开始,然后迭代地将语料库中两个连续标记的频繁出现的对合并为新的标记(称为合并)。对于每个合并,选择标准基于两个相邻标记的共现频率:选择最频繁的对合并。合并过程持续进行,直到达到预定义的大小。此外,字节级别的BPE已经被用于通过将字节视为合并的基本符号来提高多语言语料库(例如,包含非ASCII字符的文本)的分词质量。采用这种分词方法的代表性语言模型包括GPT-2、BART和LLaMA。
• WordPiece分词。WordPiece是Google内部的子词分词算法。它最初是由Google在开发语音搜索系统时提出的[183]。随后,它在2016年用于神经机器翻译系统[184],并在2018年被采用为BERT的单词分词器[23]。WordPiece与BPE具有非常相似的思想,都通过迭代合并连续标记来实现分词,但在合并的选择标准上略有不同。为了进行合并,**它首先训练一个语言模型,并使用它来对所有可能的对进行评分。然后,在每次合并时,它选择导致训练数据似然性最大增加的对。**由于Google没有发布WordPiece算法的官方实现,HuggingFace在其在线NLP课程中提供了一个更直观的选择度量:通过将共现计数除以两个标记在训练语料库中的出现计数的乘积来评分一对标记。
• Unigram分词。与BPE和WordPiece不同,**Unigram分词[185]首先从一个足够大的可能的子串或子标记集合开始,然后迭代地从当前词汇表中移除标记,直到达到预期的词汇表大小为止。**作为选择标准,它通过假设从当前词汇表中删除某个标记来计算训练语料库似然性的增加。这一步骤是基于训练过的单一语言模型进行的。为了估计单一语言模型,它采用了期望最大化(EM)算法:在每次迭代中,首先基于旧语言模型找到单词的当前最佳分词方式,然后重新估计单词的单一概率以更新语言模型。在这个过程中,采用了动态规划算法(即维特比算法)来高效地找到基于语言模型的单词的最佳分解方式。采用这种分词方法的代表性模型包括T5和mBART。
尽管利用现有的分词器(例如,OPT [81] 和GPT-3 [55] 利用了GPT2的分词器[26]),但使用专门为预训练语料库设计的分词器可能会非常有益[69],特别是对于包含多种领域、语言和格式的语料库。因此,最近的LLMs经常使用SentencePiece库[186]专门为预训练语料库训练自定义分词器,该库包括字节级BPE和Unigram分词。需要注意的是,BPE中的标准化技术,例如NFKC [187],可能会降低分词性能[34, 59, 69]。当扩展现有的LLMs(即,持续预训练或指导微调)时,我们还应该注意使用自定义分词器可能带来的潜在副作用。例如,LLaMA基于主要包含英文文本的预训练语料库训练了BPE分词器,而由此得到的词汇表可能在处理非英文数据时能力较弱,例如生成中文文本时可能需要更长的推理延迟。
4.1.3 预训练数据对LLM的影响
与小规模PLMs不同,由于对计算资源的巨大需求,通常不可行对LLMs进行多次预训练迭代。因此,在训练LLMs之前,构建一个准备充分的预训练语料库尤为重要。在这部分中,我们将讨论预训练语料库的质量和分布如何潜在地影响LLMs的性能。
多样化的数据源
如前所讨论,来自不同领域或情景的预训练数据具有不同的语言特性或语义知识。通过在多种来源的文本数据上进行预训练,LLMs可以获得广泛的知识范围,可能表现出强大的泛化能力。因此,在混合不同来源时,建议包括尽可能多的高质量数据源,并仔细设置预训练数据的分布,因为这也可能影响LLMs在下游任务上的性能[59]。Gopher [59]进行了有关数据分布的消融实验,以研究混合来源对下游任务的影响。在LAMBADA数据集[188]上的实验结果表明,增加书籍数据的比例可以提高模型在捕捉文本中的长期依赖关系方面的能力,增加C4数据集[73]的比例会导致在C4验证数据集上性能的提高[59]。然而,作为一个副作用,过多关于某个领域的数据训练可能会影响LLMs在其他领域的泛化能力[35, 59]。因此,建议研究人员应仔细确定预训练语料库中来自不同领域的数据比例,以开发更符合其特定需求的LLMs。读者可以参考图5,了解不同LLMs的数据来源的比较。
预训练数据的数量
要预训练一个有效的LLM,重要的是收集足够数量的高质量数据,以满足LLM对数据数量的需求。现有研究发现,随着LLM中参数规模的增加,也需要更多的数据来训练模型[34, 57]:与模型规模相似的缩放规律也在数据大小方面与模型性能有关。最近的研究表明,许多现有的LLM由于预训练数据不足而受到训练效果不佳的影响[34]。通过进行大量实验,它进一步证明,在相同的计算预算下,将模型规模和数据大小等比例增加可以导致更高效的计算模型(即Chinchilla模型)。更近期,LLaMA [57]表明,通过更多的数据和更长的训练,较小的模型也可以实现良好的性能。总之,建议研究人员在足够训练模型时应更加关注高质量数据的数量,特别是在扩展模型参数时。
预训练数据的质量
现有研究已经表明,对低质量语料库进行预训练,例如嘈杂、有毒和重复的数据,可能会损害模型的性能[59, 174, 176, 179]。为了开发性能良好的LLM,关键是要考虑所收集的训练数据的数量和质量。最近的研究,如T5 [73]、GLaM [99] 和Gopher [59],已经调查了数据质量对下游任务性能的影响。通过比较在经过筛选和未经筛选的语料库上训练的模型性能,它们得出了相同的结论,即在清理的数据上进行LLM的预训练可以提高性能。更具体地说,数据的重复可能导致“双下降”(指性能首先恶化,然后逐渐改善的现象)[174, 189],甚至可能压倒训练过程[174]。此外,已经显示,重复的数据会降低LLM从上下文中复制的能力,这可能会进一步影响使用上下文学习的LLM的泛化能力[174]。因此,如[56, 59, 69]中建议的那样,有必要仔细考虑对预训练语料库进行预处理方法(如在第4.1.2节中所示),以提高训练过程的稳定性并避免影响模型性能。
4.2 模型架构
在本节中,我们将回顾LLMs的架构设计,即主流架构、预训练目标和详细配置。表3展示了几个具有公开详细信息的代表性LLMs的模型卡。
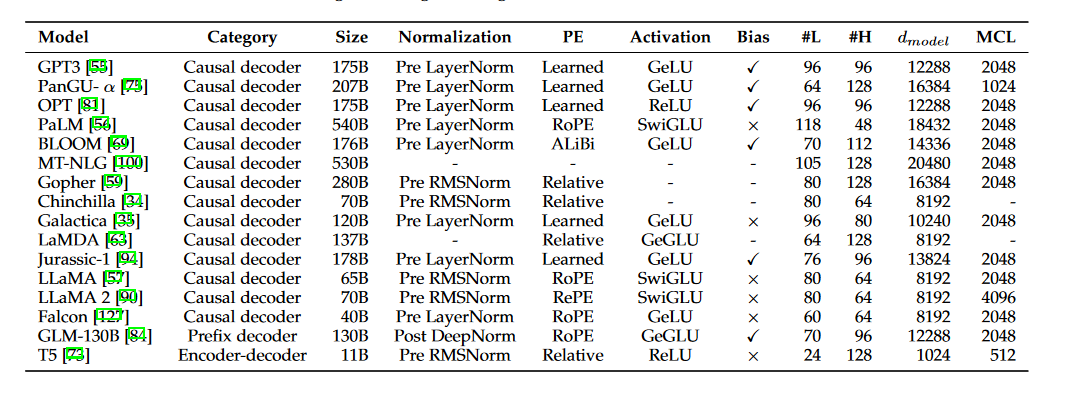
表3:几个选定的具有公开配置详细信息的LLMs的模型卡。在这里,PE表示位置嵌入,#L表示层数,#H表示注意力头的数量,dmodel表示隐藏状态的大小,MCL表示训练期间的最大上下文长度。
4.2.1 典型架构
由于Transformer架构的出色可并行性和容量,它已成为开发各种LLMs的事实标配,使得将语言模型扩展到数千亿或数万亿参数成为可能。总的来说,现有LLMs的主流架构可以大致分为三种主要类型,即编码器-解码器、因果解码器和前缀解码器,如图7所示。

图 7:三种主流架构中注意力模式的比较。这里,蓝色、绿色、黄色和灰色圆角矩形分别表示前缀标记之间的注意力、前缀和目标标记之间的注意力、目标标记之间的注意力和屏蔽注意力。
编码器-解码器架构
传统的Transformer模型是建立在编码器-解码器架构[22]上的,它由两个Transformer块堆叠而成,分别作为编码器和解码器。编码器采用堆叠的多头自注意力层来编码输入序列以生成其潜在表示,而解码器对这些表示进行交叉注意力操作,并自回归地生成目标序列。编码器-解码器PLMs(例如T5 [73]和BART [24])在各种NLP任务上显示出有效性。到目前为止,只有少数LLMs是基于编码器-解码器架构构建的,例如Flan-T5 [64]。我们将在第4.2.5节中详细讨论架构选择。
因果解码器架构
因果解码器架构包含单向注意力掩码,以确保每个输入标记只能与过去的标记和自身进行关注。输入和输出标记通过解码器以相同的方式进行处理。作为这种架构的代表性语言模型,GPT系列模型[26, 55, 109]是基于因果解码器架构开发的。特别是,GPT-3 [55]成功展示了这种架构的有效性,还展示了LLMs的惊人上下文学习能力。有趣的是,GPT-1 [109] 和GPT2 [26] 并没有展示出像GPT-3中那样的卓越能力,似乎规模在增加这种模型架构的模型容量方面起着重要作用。到目前为止,因果解码器已经被各种现有的LLMs广泛采用作为架构,例如OPT [81]、BLOOM [69] 和Gopher [59]。需要注意的是,接下来讨论的因果解码器和前缀解码器都属于仅解码器架构。当提到“仅解码器架构”时,通常指的是现有文献中的因果解码器架构,除非另有说明。
前缀解码器架构(也称为非因果解码器[190])
修改了因果解码器的掩码机制,使其能够在前缀标记上执行双向注意力[191],并且只在生成的标记上进行单向注意力。通过这种方式,就像编码器-解码器架构一样,前缀解码器可以双向编码前缀序列,并自回归地逐个预测输出标记,编码和解码期间共享相同的参数。与从头开始进行预训练不同,一个实际的建议是持续训练因果解码器,然后将它们转换为前缀解码器以加速收敛[29],例如U-PaLM [105] 是从PaLM [56] 派生出来的。基于前缀解码器的现有代表性LLMs包括GLM130B [84] 和U-PaLM [105]。
对于这三种类型的架构,我们还可以考虑通过专家混合(MoE)扩展它们,其中为每个输入稀疏激活了神经网络权重的子集,例如Switch Transformer [25] 和GLaM [99]。已经证明,通过增加专家数量或总参数大小,可以观察到显著的性能改进[192]。
新兴架构
传统的Transformer架构通常受到二次计算复杂性的限制。因此,在训练和处理长输入时,效率已经成为一个重要问题。为了提高效率,一些研究致力于设计用于语言建模的新架构,包括参数化状态空间模型(例如S4 [193]、GSS [194] 和H3 [195])、长卷积(例如Hyena [196])以及融合递归更新机制的Transformer样架构(例如RWKV [197] 和RetNet [198])。这些新架构的关键优点有两个。首先,这些模型可以像RNN一样递归生成输出,意味着它们在解码过程中只需要参考前一个状态。这使得解码过程更加高效,因为它消除了与传统Transformer中需要重新访问所有先前状态的需要。其次,这些模型具有像Transformer一样并行编码整个句子的能力。这与传统的RNN不同,后者必须逐标记地对句子进行编码。因此,它们可以利用GPU的并行性,使用诸如Parallel Scan [199, 200]、FFT [196, 197] 和Chunkwise Recurrent [198]等技术进行训练,以高度并行和高效的方式进行训练。
4.2.2 详细配置
自Transformer [22]推出以来,已经提出了各种改进措施,以增强其训练稳定性、性能和计算效率。在这一部分,我们将讨论Transformer的四个主要部分的相应配置,包括归一化、位置嵌入、激活函数和注意力和偏差。为了使这个调查更加自成一体,我们在表4中提供了这些配置的详细公式。
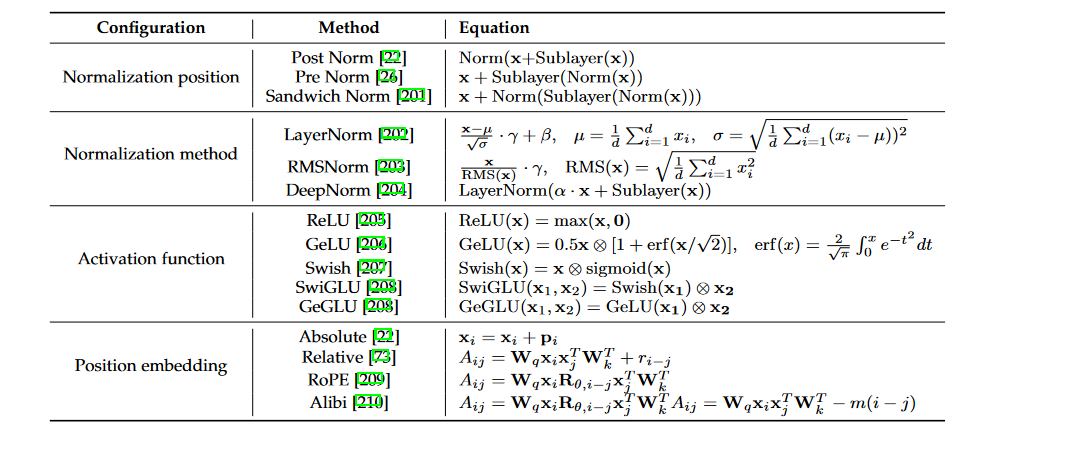
表4:网络配置的详细公式。这里,Sublayer表示Transformer层中的一个FFN或一个自注意力模块, d d d表示隐藏状态的大小, p i p_i pi表示位置 i i i的位置嵌入, A i j A_{ij} Aij表示查询和键之间的注意力分数, r i − j r_{i−j} ri−j表示基于查询和键之间的偏移的可学习标量, R θ , t R_{θ,t} Rθ,t表示旋转角度为 t ⋅ θ t · θ t⋅θ的旋转矩阵。
规范化方法
训练不稳定性是预训练LLMs的一个挑战性问题。为了缓解这个问题,规范化是稳定神经网络训练的一种广泛采用的策略。在传统的Transformer [22]中,采用了LayerNorm [202]。最近,一些先进的规范化技术已被提出作为LayerNorm的替代品,例如RMSNorm和DeepNorm。
• LayerNorm(层归一化)。在早期的研究中,BatchNorm [211] 是一种常用的规范化方法。然而,它难以处理可变长度的序列数据和小批量数据。因此,引入了LayerNorm [202] 来进行逐层规范化。具体来说,对每一层的所有激活值计算均值和方差,然后用这些均值和方差来重新调整和重新缩放激活值。
• RMSNorm(均方根归一化)。为了提高LayerNorm(LN)的训练速度,RMSNorm [203] 提出了一种方法,只使用汇总激活值的均方根(RMS)来重新缩放激活值,而不是使用均值和方差。相关研究已经证明了它在Transformer [212]上的训练速度和性能方面的优越性。采用RMSNorm的代表性模型包括Gopher [59] 和Chinchilla [34]。
• DeepNorm(深度规范化)。DeepNorm是由Microsoft提出的,旨在稳定深度Transformer的训练。使用DeepNorm作为残差连接,Transformer可以扩展到1,000层 [204],显示出了稳定性和良好性能的优势。它已被GLM-130B [84]采用。
规范化位置
除了规范化方法,规范化位置在LLMs中也起着关键作用。通常有三种规范化位置的选择,即后LN、前LN和夹层LN。
• Post-LN。后LN在传统的Transformer [22]中使用,位于残差块之间。然而,现有研究发现,使用后LN的Transformer训练容易不稳定,因为在输出层附近存在大的梯度 [213]。因此,在现有的LLMs中很少使用后LN,除非与其他策略结合使用(例如,在GLM130B [84]中将后LN与前LN结合使用)。
• Pre-LN。与后LN不同,前LN [214] 是在每个子层之前应用的,并且在最终预测之前放置了一个额外的LN。与后LN相比,带有前LN的Transformers在训练中更加稳定。然而,与带有后LN的变种相比,它的性能较差 [215]。尽管性能下降,大多数LLMs仍然采用前LN以确保训练的稳定性。但是,有一个例外情况是,当训练超过100B参数的模型时,前LN在GLM中被发现不稳定 [84]。
• Sandwich-LN。基于前LN,夹层LN [201] 在残差连接之前添加了额外的LN,以避免Transformer层输出中的数值爆炸问题。然而,已经发现夹层LN有时无法稳定LLMs的训练,可能导致训练崩溃 [84]。
激活函数
为了获得良好的性能,在前馈网络中激活函数也需要适当设置。在现有的LLMs中,GeLU激活函数 [216] 被广泛使用。特别是在最新的LLMs(例如,PaLM和LaMDA)中,GLU激活的变种 [208, 217] 也被广泛采用,特别是SwiGLU和GeGLU变种,在实践中通常可以取得更好的性能 [212]。然而,与GeLU相比,它们在前馈网络中需要额外的参数(约50%)[218]。
位置嵌入
由于Transformer中的自注意力模块是排列等变的,因此使用位置嵌入(PE)来注入序列的绝对或相对位置信息以进行建模。
• 绝对位置嵌入。在标准的Transformer [22]中,采用绝对位置嵌入。在编码器和解码器的底部,将绝对位置嵌入添加到输入嵌入中。在标准的Transformer [22]中,提出了两种绝对位置嵌入的变种,即正弦和学习的位置嵌入,后者在现有的预训练语言模型中常用。
• 相对位置嵌入。与绝对位置嵌入不同,相对位置嵌入是根据键和查询之间的偏移量生成的[219]。相对PE的一个流行变种首次出现在Transformer-XL [220, 221]中。注意力分数的计算已被修改,以引入与相对位置对应的可学习嵌入。T5 [73]进一步简化了相对位置嵌入,后来被Gopher [59]采用。具体来说,它在注意力分数中添加了可学习的标量,其中这些标量是基于查询和键的位置之间的距离计算的。与绝对PE相比,具有相对位置嵌入的Transformers可以推广到比训练时的序列更长的序列,即外推[210]。
• 旋转位置嵌入。旋转位置嵌入(RoPE)[209]基于每个令牌的绝对位置设置特定的旋转矩阵。可以使用相对位置信息计算键和查询之间的分数。由于出色的性能和长期衰减特性,RoPE被广泛采用在最新的LLMs中,例如PaLM [56]和LLaMA [57]。基于RoPE,xPos [222]进一步改善了Transformer的平移不变性和长度外推性能。在旋转度矢量的每个维度上,xPos添加了一个特殊的指数衰减,当旋转度较大时,衰减较小。它可以减轻训练过程中距离增加时的不稳定现象。
• ALiBi。 ALiBi [210]旨在改善Transformer的外推能力。与相对位置嵌入类似,它根据键和查询之间的距离对注意力得分进行惩罚。不同于T5 [73]等相对位置嵌入方法,ALiBi中的惩罚得分是预定义的,没有可训练的参数。[210]中的实证结果表明,ALiBi在比训练更长的序列上具有比几种常用的位置嵌入方法,如正弦PE [22]、RoPE [209]和T5偏置[73]更好的外推性能。此外,已经证明ALiBi还可以改善BLOOM [69]的训练稳定性。
注意力机制
注意机制是Transformer的关键组成部分。它允许序列中的Token相互交互,并计算输入和输出序列的表示。
• 全注意力。在标准的Transformer [22]中,注意机制以成对的方式进行,考虑序列中所有令牌对之间的关系。它采用了缩放的点积注意力,其中隐藏状态被映射为查询、键和值。此外,Transformer使用多头注意力而不是单一注意力,在不同头部中使用不同的投影来投影查询、键和值。每个头部输出的连接被视为最终输出。
• 稀疏注意力。全注意力的一个关键挑战是二次计算复杂度,当处理长序列时,这成为一个负担。因此,提出了各种高效的Transformer变体来减少注意机制的计算复杂度 [223, 224]。例如,在GPT3 [55] 中采用了局部带状稀疏注意力(即,因式分解注意力)。每个查询不是针对整个序列,而是基于位置只能关注一部分令牌。
• 多查询/分组查询注意力。多查询注意力是指不同头部共享相同的线性变换矩阵在键和值上的注意力变体 [226]。它可以显著节省计算成本,只在模型质量上做出轻微的牺牲。具有多查询注意力的代表性模型包括PaLM [56]和StarCoder [89]。为了在多查询注意力和多头注意力之间进行权衡,研究了分组查询注意力(GQA)[227]。在GQA中,头部被分配到不同的组中,属于同一组的头部将共享相同的变换矩阵。特别地,GQA已经被采用并在最近发布的LLaMA 2模型 [90]中进行了经验测试。
• FlashAttention。与大多数现有的近似注意方法不同,这些方法通过权衡模型质量来提高计算效率,FlashAttention [228] 提出了一种从IO感知的角度优化GPU上的注意力模块的速度和内存消耗的方法。现代GPU上存在不同级别的内存,例如,具有快速IO的SRAM和相对较慢IO的HBM。FlashAttention将输入组织成块,并引入必要的重新计算,以更好地利用快速内存SRAM。作为CUDA中的融合内核实现,FlashAttention已经集成到PyTorch [157]、DeepSpeed [65]和Megatron-LM [66]中。更新版本FlashAttention-2 [229] 进一步优化了GPU线程块和warp的工作划分,与原始FlashAttention相比,速度提高了大约2倍。
• PagedAttention。观察到当LLM部署在服务器上时,GPU内存通常被缓存的注意力键和值张量(称为KV缓存)所占用。主要原因是输入长度经常变化,导致了碎片化和过度预留的问题。受操作系统中经典分页技术的启发,提出了PagedAttention以改善部署的LLM的内存效率和吞吐量 [230]。具体而言,PagedAttention将每个序列分成子序列,并将这些子序列的相应KV缓存分配到非连续的物理块中。分页技术增加了GPU利用率,并在并行采样中实现了有效的内存共享。
为了总结所有这些讨论,我们总结了现有文献中的详细配置建议。为了获得更强的泛化能力和训练稳定性,建议选择预先的RMSNorm用于层归一化,以及SwiGLU或GeGLU作为激活函数。此外,可能不建议在嵌入层之后立即使用LN,因为这可能会导致性能下降。至于位置嵌入,RoPE或ALiBi是更好的选择,因为它在长序列上表现更好。
4.2.3 预训练任务
预训练在将大规模语料库中的通用知识编码到庞大的模型参数中起着关键作用。对于训练LLMs,有两种常用的预训练任务,即语言建模和去噪自动编码。
语言建模
语言建模任务(LM)是预训练仅具有解码器的LLMs,例如GPT3 [55]和PaLM [56]最常用的目标。给定一系列标记 x = x 1 , . . . , x n x = {x_1,...,x_n} x=x1,...,xn,LM任务的目标是基于序列中前面的标记 x < i x<i x<i,自回归地预测目标标记 x i x_i xi。通常的训练目标是最大化以下似然性:

由于大多数语言任务可以被视为基于输入的预测问题,这些仅具有解码器的LLMs可能具有潜在优势,可以隐式学习以统一的LM方式完成这些任务。一些研究还表明,无需微调,仅通过自回归地预测下一个标记[26, 55],可以将仅具有解码器的LLMs自然地转移到某些任务中。语言建模的一个重要变体是前缀语言建模任务,它是为了预训练具有前缀解码器架构的模型而设计的。在计算前缀语言建模的损失时,不会使用随机选择的前缀内的标记。与预训练期间看到的标记数量相同,前缀语言建模的性能略差于语言建模,因为序列中涉及的标记较少[29]。
去噪自动编码
除了传统的语言建模,去噪自动编码任务(DAE)也被广泛用于预训练语言模型[24, 73]。DAE任务的输入x\ ̃ x是带有随机替代部分的损坏文本。然后,语言模型被训练来恢复被替代的标记 ̃ x。形式上,DAE的训练目标如下所示:
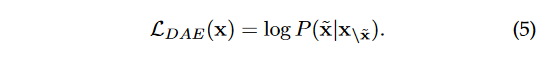
然而,与LM任务相比,DAE任务在实施上似乎更加复杂。因此,它没有被广泛用于预训练大型语言模型。将DAE作为预训练目标的现有LLMs包括T5 [73]和GLM-130B [84]。这些模型主要是以自回归方式训练,以恢复被替代的部分。
混合去噪器
混合去噪器(MoD)[80],也称为UL2损失,被引入作为预训练语言模型的统一目标。MoD将LM和DAE目标都视为不同类型的去噪任务,即S-去噪器(LM)、R-去噪器(DAE,短跨度和低损坏)、以及X-去噪器(DAE,长跨度或高损坏)。在这三个去噪任务中,S-去噪器类似于传统的LM目标(公式4),而R-去噪器和X-去噪器类似于DAE目标(公式5),但它们在跨度长度和损坏文本比例方面不同。对于以不同特殊标记开头的输入句子(即{[R],[S],[X]}),模型将使用相应的去噪器进行优化。MoD已经应用于最新的PaLM 2模型[107]中。
4.2.4 解码策略
在对 LLM 进行预训练后,必须采用特定的解码策略来从 LLM 生成适当的输出。
背景
我们从普遍的仅解码器架构开始讨论,并介绍自回归解码机制。由于这种LLMs是基于语言建模任务(公式4)进行预训练的,因此一种基本的解码方法是贪婪搜索,它在每一步基于先前生成的标记预测最有可能的标记,形式上建模为:
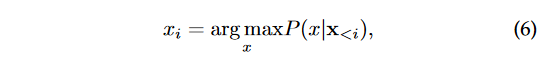
其中 x i x_i xi是在给定上下文 x < i x<i x<i的情况下,在第i步生成中具有最高概率的标记。例如,在图8中,在预测句子“I am sleepy. I start a pot of”的下一个标记时,贪婪搜索选择了在当前步骤具有最高概率的标记“coffee”。贪婪搜索在文本生成任务(例如,机器翻译和文本摘要)中可以取得令人满意的结果,其中输出高度依赖于输入[231]。然而,在开放式生成任务(例如,故事生成和对话)方面,贪婪搜索有时倾向于生成尴尬且重复的句子[232]。
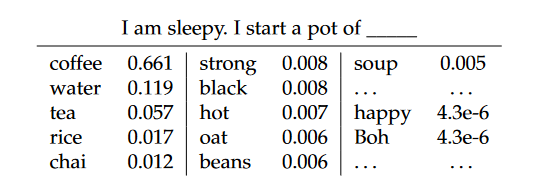
图 8:上下文“我困了。”的下一个标记在词汇上的概率分布(按降序排列)。我开始一锅”。为了便于讨论,该示例以字为单位而不是子字为单位给出。
作为另一种替代解码策略,提出了基于抽样的方法,它们根据概率分布随机选择下一个标记,以增强生成过程中的随机性和多样性:
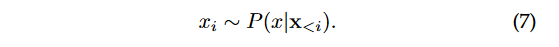
对于图8中的示例,基于抽样的方法将以较高的概率对单词“coffee”进行抽样,同时保留选择其他单词如“water”,“tea”,“rice”等的可能性。
不仅限于仅解码器架构,这两种解码方法通常也可以以类似的方式应用于编码器-解码器模型和前缀解码器模型。
改进贪婪搜索
在每一步选择具有最高概率的标记可能会导致忽视具有更高总体概率但局部估计较低的句子。接下来,我们介绍几种改进策略以缓解这个问题。
• Beam search(束搜索)。束搜索[233]在解码过程中每一步保留具有n(束大小)最高概率的句子,并最终选择具有最高概率的生成响应。通常,束大小配置在3到6的范围内。然而,选择更大的束大小可能会导致性能下降[234]。
• 长度惩罚。由于束搜索偏向于较短的句子,施加长度惩罚(也称为长度归一化)是一种常用的技术[235],用于克服这个问题,它根据句子长度进行句子概率的归一化(除以长度的幂α)。此外,一些研究者[236]提出对先前生成的标记或n-gram的生成进行惩罚,以减轻生成重复的问题。此外,多样性束搜索[237]可以利用相同的输入生成一组多样性的输出。
改进随机抽样
基于抽样的方法在整个词汇表上对标记进行抽样,这可能会根据上下文选择错误或不相关的标记(例如,图8中的“happy”和“Boh”)。为了提高生成质量,已经提出了一些策略来减轻或防止选择概率过低的词语。
• 温度抽样。为了调节抽样的随机性,一个实用的方法是调整softmax函数的温度系数,用于计算整个词汇表中第j个标记的概率:
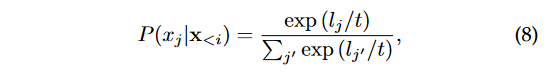
其中 l j ′ l_{j'} lj′是每个词的logits, t t t是温度系数。降低温度 t t t会增加选择高概率词的机会,同时减少选择低概率词的机会。当 t t t设置为1时,它变为默认的随机抽样;当 t t t接近0时,它等同于贪婪搜索。此外,当t趋向无穷大时,它退化为均匀抽样。
• 前k个抽样。与温度抽样不同,前k个抽样直接截断概率较低的标记,并仅从具有前k个最高概率的标记中进行抽样[238]。例如,在图8中,前5个抽样将从这些标记的重新缩放概率中抽样词语“coffee”,“water”,“tea”,“rice”和“chai”。
• 前p个抽样。由于前k个抽样不考虑整体概率分布,一个常数k值可能不适用于不同的上下文。因此,前p个抽样(也称为核抽样)提出了从累积概率高于(或等于)p的最小集合中进行抽样[232]。在实践中,可以通过逐渐从按生成概率降序排序的词汇表中添加标记来构建最小集合,直到它们的累积值超过p。
最近,研究人员还探索了LLMs的其他抽样策略。例如,η-抽样通过引入基于概率分布的动态阈值进一步改进了前p个抽样。此外,对比搜索[239]和典型抽样[240]可以用于在解码过程中改善生成的连贯性。
高效的解码策略
考虑到LLMs中自回归生成的本质,随着序列长度的增加,生成过程需要逐渐更多的时间。因此,一些研究工作探讨了加速解码过程的方法。预测性解码[241, 242]首先利用紧凑但高效的模型(例如n-gram模型或小型PLM)生成短片段,然后利用LLM来验证和纠正这些草稿。这种方法可显著提速2倍至3倍,而不损害生成质量。SpecInfer [243]进一步提出了一种基于学习的方法,将多个小模型组合起来以增加覆盖范围的可能性。此外,还提出了标记级别的早期退出技术,允许在较低的Transformer层生成一个标记,而不是经过所有层[244]。这可以实现更大的加速,但以牺牲生成质量为代价。
实用设置
在实践中,现有的库(例如,Transformers [151])和LLMs的公共API(例如,OpenAI)已经支持了各种解码策略,以满足不同的文本生成场景。接下来,我们介绍一些代表性LLMs的解码设置:
• T5 [73] 默认使用贪婪搜索,并在翻译和摘要任务中应用束搜索(束大小为4),长度惩罚为0.6。
• GPT-3 [55] 对所有生成任务采用束搜索,束大小为4,长度惩罚为0.6。
• Alpaca [128] 在开放式生成中使用基于抽样的策略,包括前k个(k = 50)、前p个(p = 0.9)以及温度为0.7。
• LLaMA [57] 应用针对特定任务定制的多样化解码策略。例如,对于问答任务,它采用贪婪搜索,而对于代码生成,它采用温度设置为0.1(pass@1)和0.8(pass@100)的抽样策略。
• OpenAI API支持几种基本的解码策略,包括贪婪搜索(通过将温度设置为0)、束搜索(通过设置best_of参数),温度抽样(通过设置temperature参数),核抽样(通过设置top_p参数)。它还引入了presence_penalty和frequency_penalty参数来控制生成的重复程度。根据OpenAI的文档,即使输入和超参数相同,它们的API也会产生不同的输出。将温度设置为0可以产生更确定性的输出,尽管有轻微的变异可能性。
4.2.5 总结和讨论
架构和预训练任务的选择可能会为LLMs引入不同的归纳偏差,这将导致不同的模型容量。在这部分中,我们讨论LLMs架构的两个未决问题。
架构选择
在早期的预训练语言模型文献中,有很多关于不同架构影响的讨论[29, 80]。然而,大多数LLMs是基于因果解码器架构开发的,仍然缺乏对其相对于其他替代方案的优势的理论分析。接下来,我们简要总结了关于这个问题的现有讨论。
• 通过使用LM目标进行预训练,似乎因果解码器架构能够实现出色的零次和少次通用性能。现有研究已经表明,在没有多任务微调的情况下,因果解码器具有比其他架构更好的零次性能[29]。GPT-3 [55]的成功证明了大型因果解码器模型可以成为优秀的少次学习器。此外,本文第5节讨论的指令调整和对齐调整已被证明可以进一步增强大型因果解码器模型的能力[61, 62, 64]。
• 因果解码器中普遍观察到了缩放规律。通过调整模型大小、数据集大小和总计算量,可以大幅提高因果解码器的性能[30, 55]。因此,通过缩放来增加因果解码器模型容量已成为一种重要策略。然而,对于编码器-解码器模型的更详细研究仍然不足,需要更多的工作来研究大规模编码器-解码器模型的性能。
长上下文
基于Transformer的LM的一个缺点是由于时间和内存中的二次计算成本,限制了上下文长度。同时,对于PDF处理和故事创作等应用,对长上下文窗口的需求正在增加[245]。最近发布了一个具有16K标记上下文窗口的ChatGPT变体,远远超过了初始的4K标记。此外,GPT-4的上下文窗口已扩展到32K标记[46]。接下来,我们讨论与长上下文建模相关的两个重要因素。
• 外推能力。在实际应用中,LLMs有可能处理超过训练语料库最大长度的长输入文本。处理更长文本的能力通常称为外推能力[210]。一些位置嵌入方法,例如RoPE [209]和T5 bias [73],已经经验性地验证具有一定的外推能力[210]。具体而言,装备了ALiBi [210]的LMs已经显示出在比训练文本长十倍的序列上仍然保持相对稳定的困惑度。还有像xPos [222]这样的工作,通过改进旋转矩阵的设计来增强RoPE的外推能力。
• 效率。为了减少注意模块中的二次计算成本,一些研究设计了高效的注意计算方法,可以使内存消耗大致线性缩放,例如稀疏或线性注意[225, 246-249]。除了算法改进,另一项重要工作,FlashAttention [228],从系统级别(即GPU内存IO效率)改进了效率。在相同的计算预算下,可以训练具有更长上下文窗口的LLMs。一些研究还旨在设计新的架构,而不是传统的Transformer模块,以解决效率问题,例如RWKV [197]和RetNet [198]。更详细的尝试介绍可以参考第4.2.1节。
为什么预测下一个单词有效?
仅解码器架构的本质是准确预测下一个单词以重建预训练数据。到目前为止,还没有正式的研究从理论上证明其相对于其他架构的优势。 Ilya Sutskever 在 Jensen Huanga 的采访中给出了一个有趣的解释。采访原文抄录如下:
假设你读了一本侦探小说。就像复杂的情节,一个故事情节,不同的人物,很多事件,谜团一样的线索,说不清楚。然后,假设在书的最后一页,侦探收集了所有线索,聚集了所有人员并说:“好吧,我要揭露犯罪者的身份,那个人的名字是” 。预测那个词。 ……现在,有很多不同的词。但是随着对这些单词的预测越来越好,对文本的理解也会不断增加。 GPT-4 可以更好地预测下一个单词。
4.3 模型训练
在这一部分,我们回顾一下训练LLMs的重要设置、技巧或窍门。
4.3.1 优化设置
对于 LLM 的参数优化,我们介绍了批量训练、学习率、优化器和训练稳定性的常用设置。
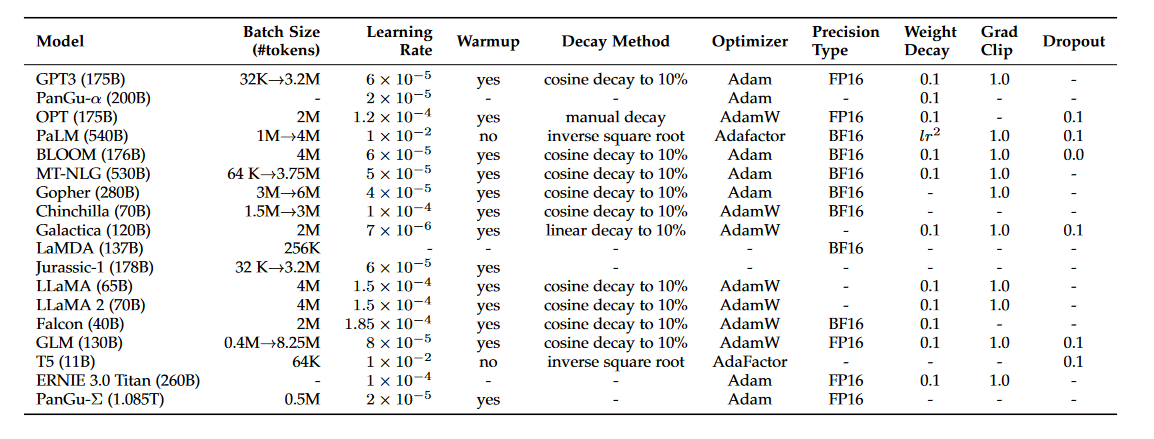
表 5:几个现有 LLM 的详细优化设置。
批量训练。对于语言模型的预训练,现有工作通常将批量大小设置为一个较大的数字(例如,2,048个示例或4M标记),以提高训练稳定性和吞吐量。对于像GPT-3和PaLM这样的LLMs,它们引入了一种新策略,在训练过程中动态增加批量大小,最终达到百万级别。具体而言,GPT-3的批量大小逐渐从32K增加到3.2M标记。实证结果表明,批量大小的动态调整策略可以有效稳定LLMs的训练过程[56]。
学习率。现有的LLMs通常在预训练期间采用类似的学习率调度,包括热身和衰减策略。具体而言,在训练步骤的初始0.1%到0.5%中,采用线性热身调度,逐渐将学习率增加到最大值,最大值通常在约 5 × 1 0 − 5 5×10^{−5} 5×10−5到 1 × 1 0 − 4 1×10^{−4} 1×10−4之间(例如,GPT-3为 6 × 1 0 − 5 6×10^{−5} 6×10−5)。然后,在后续的步骤中采用余弦衰减策略,逐渐将学习率减小到最大值的约10%,直到训练损失收敛。
优化器。Adam优化器[250]和AdamW优化器[251]广泛用于LLMs的训练(例如,GPT3),它们基于自适应估计的低阶矩来进行一阶梯度优化。通常,其超参数设置如下: β 1 = 0.9 , β 2 = 0.95 和 ε = 1 0 − 8 β1 = 0.9,β2 = 0.95和ε = 10^{−8} β1=0.9,β2=0.95和ε=10−8。同时,Adafactor优化器[252]也在LLMs的训练中使用,(例如,PaLM和T5),它是一种专门设计用于在训练期间节省GPU内存的Adam优化器变种。Adafactor优化器的超参数设置为: β 1 = 0.9 和 β 2 = 1.0 − k − 0.8 β1 = 0.9和β2 = 1.0 - k^{-0.8} β1=0.9和β2=1.0−k−0.8,其中k表示训练步骤的数量。
稳定训练。在LLMs的预训练期间,经常会遇到训练不稳定的问题,可能导致模型崩溃。为了解决这个问题,广泛使用了权重衰减和梯度裁剪,现有研究[55, 69, 81, 84, 100]通常将梯度裁剪的阈值设置为1.0,权重衰减率设置为0.1。然而,随着LLMs的规模增加,训练损失的突增也更容易发生,导致训练不稳定。为了缓解这个问题,PaLM [56]和OPT [81]使用了一种简单的策略,从早期检查点重新启动训练过程,以在突增发生之前跳过可能引发问题的数据。此外,GLM [84]发现嵌入层的异常梯度通常导致突增,并提出缩小嵌入层梯度以减轻这个问题。
4.3.2 可扩展的训练技术
随着模型和数据规模的增加,在有限的计算资源下有效地训练LLMs变得具有挑战性。特别是需要解决两个主要技术问题,即提高训练吞吐量和将更大的模型加载到GPU内存中。在这部分中,我们回顾了现有工作中广泛使用的几种方法,以解决上述两个挑战,包括3D并行[66, 253, 254]、ZeRO [255]和混合精度训练[256],并提供了如何利用它们进行训练的一般建议。
3D并行
3D并行是实际上是三种常用并行训练技术的结合,即数据并行、流水线并行[253, 254]和张量并行[66]。接下来我们介绍这三种并行训练技术。
• 数据并行。数据并行是提高训练吞吐量的最基本方法之一。它在多个GPU之间复制模型参数和优化器状态,然后将整个训练语料库分布到这些GPU中。这样,每个GPU只需处理为其分配的数据,并进行前向传播和反向传播以获得梯度。不同GPU上计算得到的梯度将被进一步聚合,以获得整个批次的梯度,以更新所有GPU中的模型。这种方式,由于梯度的计算是在不同的GPU上独立进行的,数据并行机制具有高度可扩展性,可以通过增加GPU数量来提高训练吞吐量。此外,这种技术在实施上很简单,大多数现有的热门深度学习库已经实现了数据并行,例如TensorFlow和PyTorch。
• 流水线并行。流水线并行旨在将LLM的不同层分布到多个GPU中。特别是在Transformer模型的情况下,流水线并行将连续的层加载到同一GPU上,以减少在GPU之间传输计算的隐藏状态或梯度的成本。然而,流水线并行的朴素实现可能会导致较低的GPU利用率,因为每个GPU必须等待前一个GPU完成计算,从而导致不必要的气泡开销 [253]。为了减少流水线并行中的这些气泡,GPipe [253]和PipeDream [254]提出了填充多批数据和异步梯度更新等技术来提高流水线效率。
• 张量并行。张量并行也是一种常用的技术,旨在将LLM分解为多GPU加载。与流水线并行不同,张量并行专注于分解LLMs的张量(参数矩阵)。对于LLM中的矩阵乘法操作Y = XA,参数矩阵A可以按列分成两个子矩阵A1和A2,可以表示为Y = [XA1, XA2]。通过将矩阵A1和A2放置在不同的GPU上,矩阵乘法操作将在两个GPU上并行调用,最终的结果可以通过跨GPU通信将两个GPU的输出合并而获得。目前,张量并行已经在几个开源库中得到支持,例如Megatron-LM [66],并可以扩展到更高维度的张量。此外,Colossal-AI已经为更高维度的张量[257-259]实现了张量并行,并提出了特别用于序列数据的序列并行[260],可以进一步分解Transformer模型的注意力操作。
ZeRO
ZeRO(Zero Redundancy Optimizer)技术,由DeepSpeed [65]库提出,专注于解决数据并行中的内存冗余问题。如前所述,数据并行要求每个GPU存储LLM的相同副本,包括模型参数、模型梯度和优化器参数。然而,并非所有上述数据都需要在每个GPU上保留,这会导致内存冗余问题。为了解决这个问题,ZeRO技术旨在每个GPU上仅保留部分数据,其余数据可以在需要时从其他GPU中检索。具体来说,ZeRO提供了三种解决方案,取决于三个数据部分的存储方式,即优化器状态分区、梯度分区和参数分区。实验结果表明,前两个解决方案不会增加通信开销,而第三个解决方案增加了约50%的通信开销,但可以节省与GPU数量成比例的内存。PyTorch已经实现了与ZeRO类似的技术,称为FSDP [261]。
混合精度训练
在以前的PLMs(例如BERT [23])中,通常使用32位浮点数,也称为FP32,进行预训练。近年来,为了预训练极其大型的语言模型,一些研究 [256] 开始使用16位浮点数(FP16),这可以减少内存使用和通信开销。此外,由于流行的NVIDIA GPU(例如A100)具有两倍于FP32的FP16计算单元,因此FP16的计算效率可以进一步提高。然而,现有研究发现FP16可能导致计算精度的损失 [59, 69],从而影响最终的模型性能。为了缓解这个问题,已经开始使用一种叫做Brain Floating Point (BF16)的替代方法进行训练,它分配更多的指数位和较少的有效位比FP16多。对于预训练,BF16通常在表示精度上表现更好 [69]。
总体训练建议
在实践中,上述训练技术,特别是3D并行性,通常会联合使用,以提高培训吞吐量和大型模型的加载。例如,研究人员已经将8路数据并行性、4路张量并行性和12路管道并行性整合到一起,使BLOOM [69] 在384个A100 GPU上进行了培训。目前,像DeepSpeed [65]、Colossal-AI [153] 和Alpa [262]等开源库可以很好地支持这三种并行训练方法。为了减少内存冗余,可以使用ZeRO、FSDP和激活重计算技术 [68, 263] 来培训LLMs,这些技术已经集成到DeepSpeed、PyTorch和Megatron-LM中。此外,像BF16这样的混合精度训练技术也可以用来提高培训效率和减少GPU内存使用,但它需要硬件上的必要支持(例如,A100 GPU)。由于培训大型模型是一个时间密集型的过程,因此在早期预测模型性能并检测异常问题将非常有用。为此,GPT-4 [46] 最近引入了一种称为可预测缩放的新机制,建立在深度学习堆栈上,可以使用一个小得多的模型对大模型的性能进行预测,这对于开发LLMs可能非常有用。在实践中,可以进一步利用主流深度学习框架的支持培训技术。例如,PyTorch支持数据并行训练算法FSDP [261](即完全分片的数据并行),如果需要,可以将部分训练计算卸载到CPU上。