目标检测是在图像中发现并识别物体的过程,它是深度学习和图像处理领域的重要成果之一。在创建物体定位时,识别物体时,常见的一种方法是使用边界框。这种方法具有很高的通用,可以训练目标检测模型来识别和检测多个特定物体。
通常,目标检测模型被训练用于检测特定物体的存在。所构建的模型可以应用于图像、视频或实时操作中。在深度学习方法和现代图像处理技术出现之前,目标检测就已经受到了广泛关注。某些方法(如SIFT和HOG以及它们的特征和边缘提取技术)在目标检测方面取得了成功,而这个领域的其他竞争者相对较少。
随着卷积神经网络(CNNs)的引入和计算机视觉技术的发展,目标检测在当前时代变得愈发普及。深度学习方法带来的目标检测新浪潮为我们展示了无限的可能性。
目标检测利用每个类别的特殊和独特属性来识别所需的物体。在寻找正方形时,目标检测模型可以寻找垂直的角,从而形成正方形,每边长度相等。在寻找圆形物体时,目标检测模型会寻找中心点,从这些点可以创建特定的圆形实体。这些识别技术被用于人脸识别或物体跟踪。
在本文中,我们将探讨不同的目标检测算法和库
目标检测的应用场景
在日常生活中,目标检测已广泛应用。例如,智能手机通过面部识别解锁,或在商店和仓库的视频监控中识别可疑活动。
以下是目标检测的一些主要应用:
- 车牌识别:结合目标检测和光学字符识别(OCR)技术,识别车辆上的字母数字字符。目标检测用于捕捉图像并检测特定图像中的车辆。模型检测到车牌后,OCR技术将二维数据转换为机器编码文本。
- 人脸检测与识别:目标检测的主要应用之一是人脸检测和识别。借助现代算法,我们可以在图像或视频中检测到人脸。现在,由于一次性学习方法,甚至可以仅通过一张训练过的图像识别出人脸。
- 物体跟踪:在观看棒球或板球比赛时,球可能会击中很远的地方。在这些情况下,跟踪球的运动以及它覆盖的距离是很有用的。为此,物体跟踪可以确保我们对球运动方向的连续信息。
- 自动驾驶汽车:对于自动驾驶汽车,在行驶过程中研究车辆周围的不同元素至关重要。一个在多个类别上训练的目标检测模型对于自动驾驶汽车的良好性能至关重要。
- 机器人技术:许多任务,如举重、拾放操作和其他实时工作,都是由机器人完成的。目标检测对于机器人检测物体和自动化任务至关重要。
自2010年代初深度学习普及以来,用于解决物体检测问题的算法质量不断提高。我们将探讨最受欢迎的算法,了解它们的工作原理、优点以及在某些场景中的缺陷。
1. 方向梯度直方图(HOG,Histogram of Oriented Gradients)
简介
方向梯度直方图(HOG)是物体检测方法中最古老的方法之一,首次亮相于1986年。尽管在接下来的十年里有一些发展,但直到2005年,这种方法才开始在许多与计算机视觉相关的任务中受到欢迎。HOG使用特征提取器来识别图像中的物体。
HOG中使用的特征描述符是图像部分的表示,我们只提取最必要的信息,而忽略其他内容。特征描述符的功能是将图像的整体大小转换为数组或特征向量的形式。在HOG中,我们使用梯度方向过程来定位图像中最关键的部分。
架构概述
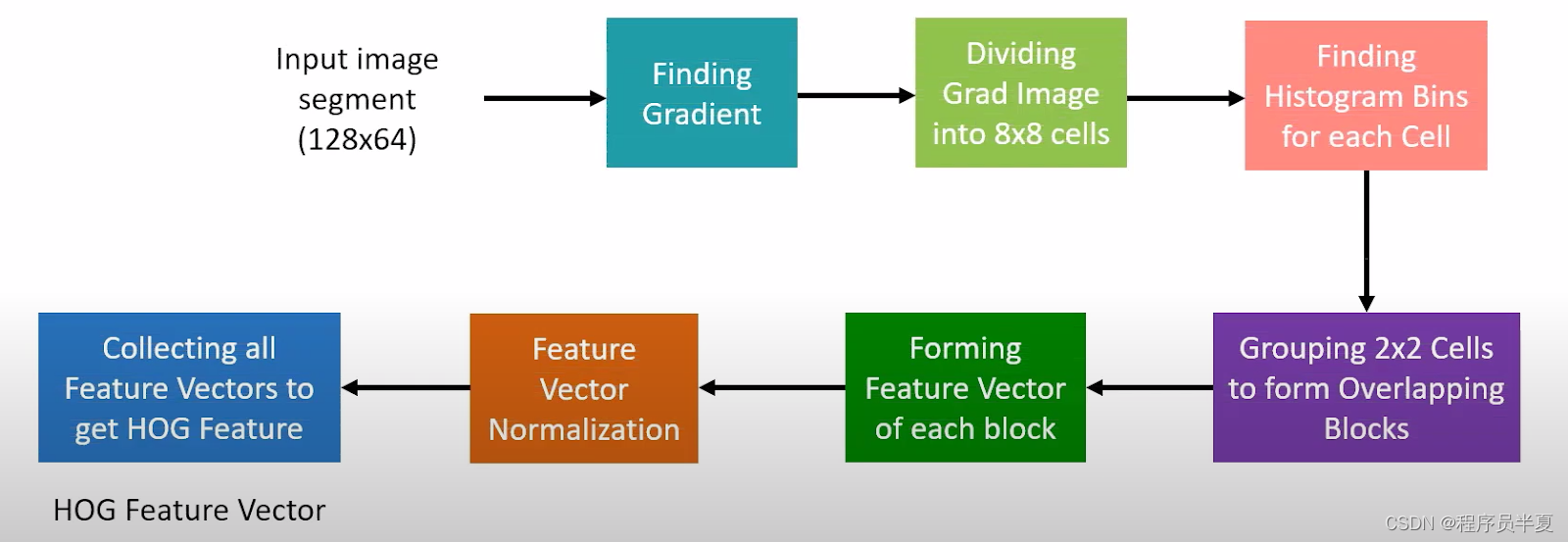
在我们理解HOG的整体架构之前,让我们先了解一下它的工作原理。对于图像中的特定像素,通过考虑垂直和水平值来计算梯度直方图,从而获得特征向量。借助梯度幅度和梯度角度,我们可以通过探索水平和垂直周围的其他实体来获得当前像素的清晰值。
如上图所示,我们将考虑一个特定大小的图像段。第一步是通过将整个图像的计算划分为8×8个单元格的梯度表示来找到梯度。借助获得的64个梯度向量,我们可以将每个单元格分割为角度区间,并计算该区域的直方图。这个过程将64个向量的大小减小到9个值的较小大小。
一旦我们为每个单元获得9个点直方图值(区间),我们可以选择为单元块创建重叠。最后的步骤是形成特征块,对获得的特征向量进行归一化,并收集所有特征向量以获得整体HOG特征。
HOG的成就
- 创建了一个用于执行物体检测的特征描述符。
- 能够与支持向量机(SVMs)结合,实现高精度物体检测。
- 为每个位置的计算创建滑动窗口效果。
需要考虑的点
局限性 - 虽然方向梯度直方图(HOG)在物体检测的初期阶段相当具有革命性,但这种方法存在很多问题。对于图像中复杂像素的计算非常耗时,且在某些物体检测场景中效果不佳。
何时使用HOG?
HOG通常应作为物体检测的第一种方法,用于测试其他算法及其各自的性能。尽管如此,HOG在大多数物体检测和具有相当准确度的面部特征识别中具有重要用途。
2. 基于区域的卷积神经网络(R-CNN)
简介
基于区域的卷积神经网络(R-CNN)是相对于HOG和SIFT等之前的方法在物体检测过程中的一种改进。在R-CNN模型中,我们尝试通过使用选择性特征提取最重要的特征(通常约2000个特征)。选择最重要的特征提取过程可以借助选择性搜索算法来实现,该算法可以获得更重要的区域建议。
R-CNN的工作过程
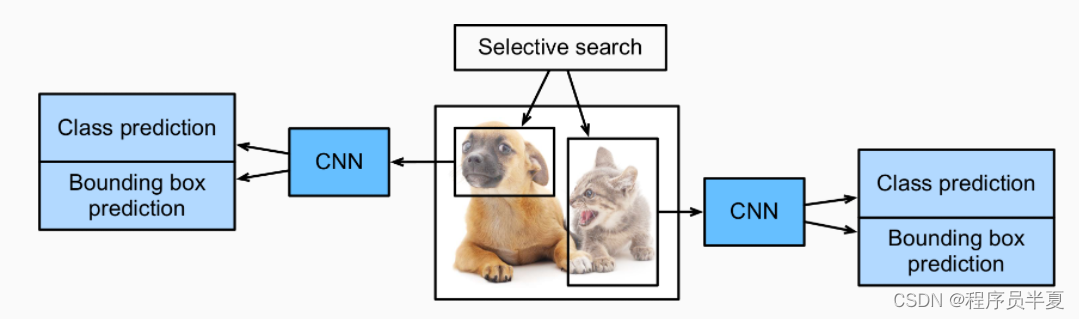
选择性搜索算法的工作流程是为了选择最重要的区域建议,确保在特定图像上生成多个子分割,并选择适合任务的候选项。然后可以利用贪婪算法将有效的候选项合并,以便将较小的片段组合成适当的较大片段。
一旦选择性搜索算法成功完成,我们接下来的任务是提取特征并进行适当的预测。然后我们可以生成最终的候选建议,卷积神经网络可用于创建n维(2048或4096)特征向量作为输出。借助预训练的卷积神经网络,我们可以轻松实现特征提取任务。
R-CNN的最后一步是为图像做出适当的预测,并相应地标记边界框。为了获得每个任务的最佳结果,预测是通过为每个任务计算一个分类模型来进行的,而回归模型用于校正建议区域的边界框分类。
R-CNN的问题
- 尽管使用预训练的CNN模型可以有效地进行特征提取,但使用当前算法提取所有区域建议以及最终的最佳区域的整个过程非常缓慢。
- R-CNN模型的另一个主要缺点不仅是训练速度慢,而且预测时间长。解决方案需要使用大量计算资源,增加整个过程的可行性。因此,整体架构可以被认为相当昂贵。
- 有时候,由于在这个特定步骤中无法进行改进,最初的步骤可能会出现不良的候选选择。这可能导致训练模型中出现很多问题。
何时使用R-CNN?
R-CNN与HOG物体检测方法类似,应作为测试物体检测模型性能的第一基线使用。预测图像和物体所需的时间可能比预期要长,因此通常更喜欢使用R-CNN的现代版本。
更快的 R-CNN(Fast R-CNN 与Faster R-CNN)
简介
尽管R-CNN模型在物体检测方面取得了理想的结果,但其速度存在一些主要不足。为了解决这个问题,引入了更快的方法,其中包括Fast R-CNN 和 Faster R-CNN。
Faster R-CNN和Fast R-CNN都是R-CNN家族中的物体检测算法。它们在性能和速度方面相较于原始的R-CNN有所改进。下面是关于这两种方法的简要比较:
Fast R-CNN
- 速度:Fast R-CNN比原始的R-CNN更快,因为它通过在整个图像上应用卷积神经网络来避免了对每个子区域的重复计算。
- RoI池化:Fast R-CNN引入了兴趣区域(RoI)池化,这是一种特殊的技术,可以从预训练模型和选择性搜索算法的输入中提取特征。
- 端到端训练:Fast R-CNN可以进行端到端训练,这意味着整个网络可以一次性训练,而不需要分阶段训练。
- 局限性:Fast R-CNN仍然使用选择性搜索算法来生成区域建议,这可能导致速度瓶颈。
Faster R-CNN
- 速度:Faster R-CNN在速度上比Fast R-CNN有所提升,这主要归功于区域建议网络(RPN)的引入。
- 区域建议网络:Faster R-CNN使用RPN替换了选择性搜索算法,以更快地生成区域建议。
- 端到端训练:与Fast R-CNN一样,Faster R-CNN也可以进行端到端训练。
- 性能:Faster R-CNN在物体检测任务中表现出较高的准确性,这得益于其对锚框的多尺度、大小和纵横比的考虑。
总之,Faster R-CNN是Fast R-CNN的改进版本,主要通过引入区域建议网络(RPN)来加速区域建议的生成过程。这使得Faster R-CNN在速度和性能方面相较于Fast R-CNN有所提升。
Faster R-CNN的架构
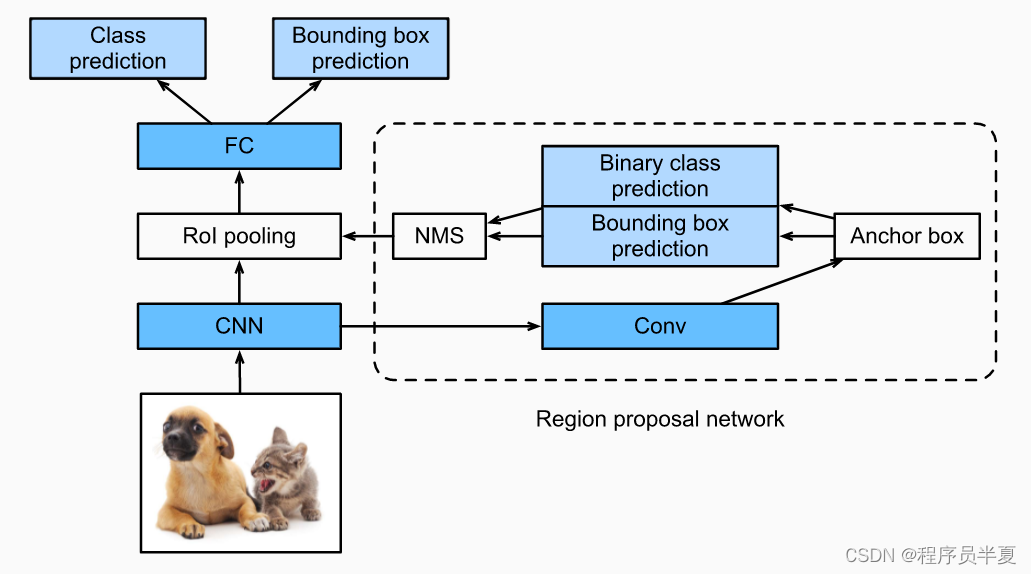
Faster R-CNN是R-CNN家族中最优秀的版本之一,其性能速度大大提高。虽然R-CNN和Fast R-CNN模型使用选择性搜索算法来计算区域建议,但Faster R-CNN引入了更优越的区域建议网络。区域建议网络(RPN)通过对图像进行广泛的范围和多尺度计算,生成有效的输出。
区域建议网络大大减少了边缘计算的时间,通常每张图像只需10毫秒。该网络由卷积层组成,可以提取每个像素的基本特征图。对于每个特征图,我们生成多个具有不同尺度、大小和纵横比的锚框。对于每个锚框,我们进行特定类别的二进制预测,并生成相应的边界框。
接下来,通过非极大值抑制来消除特征图中重叠的不必要信息。非极大值抑制的输出通过兴趣区域传递,其余的过程和计算与Fast R-CNN的工作类似。
Fast R-CNN的优势和局限性
优势
- 速度:Fast R-CNN相较于原始的R-CNN在速度上有显著提升,这主要归功于在整个图像上应用卷积神经网络,避免了对每个子区域的重复计算。
- RoI池化:Fast R-CNN引入了兴趣区域(RoI)池化,这是一种特殊的技术,可以从预训练模型和选择性搜索算法的输入中提取特征。
- 端到端训练:Fast R-CNN可以进行端到端训练,这意味着整个网络可以一次性训练,而不需要分阶段训练。
- 准确性:Fast R-CNN在物体检测任务中表现出较高的准确性,这得益于其对锚框的多尺度、大小和纵横比的考虑。
局限性
- 区域建议:Fast R-CNN仍然使用选择性搜索算法来生成区域建议,这可能导致速度瓶颈。
- 实时应用:虽然Fast R-CNN的速度相较于原始R-CNN有所提高,但在实时应用中,它可能仍然无法满足严格的实时性要求。对于这些应用场景,可以考虑使用更快的检测方法,如YOLO或SSD。
- 计算资源:尽管Fast R-CNN在速度上有所提升,但它仍然需要较多的计算资源,特别是在处理高分辨率图像时。
- 小物体检测:Fast R-CNN在检测小物体时可能表现不佳,因为其特征提取过程可能导致小物体的信息丢失。针对这一问题,可以尝试使用其他方法,如Feature Pyramid Networks(FPN)来改进模型。
Faster R-CNN的优势和局限性
优势
- 速度:Faster R-CNN相较于R-CNN和Fast R-CNN在速度上有显著提升,这主要归功于区域建议网络(RPN)的引入。
- 准确性:Faster R-CNN在物体检测任务中表现出较高的准确性,这得益于其对锚框的多尺度、大小和纵横比的考虑。
- 端到端训练:Faster R-CNN可以进行端到端训练,这意味着整个网络可以一次性训练,而不需要分阶段训练。
局限性
- 计算资源:尽管Faster R-CNN在速度上有所提升,但它仍然需要较多的计算资源,特别是在处理高分辨率图像时。
- 实时应用:虽然Faster R-CNN的速度相较于其前辈有所提高,但在实时应用中,它可能仍然无法满足严格的实时性要求。对于这些应用场景,可以考虑使用更快的检测方法,如YOLO或SSD。
- 小物体检测:Faster R-CNN在检测小物体时可能表现不佳,因为其特征提取过程可能导致小物体的信息丢失。针对这一问题,可以尝试使用其他方法,如Feature Pyramid Networks(FPN)来改进模型。
单发多框检测器(SSD)
简介
单发多框检测器(SSD)是一种实现物体检测任务实时计算的高效方法之一。相比于Faster R-CNN方法,它能够以更快的速度处理实时任务,每秒处理帧数可达约7帧,满足实时应用的需求。
SSD通过将每秒帧数提高近五倍来解决Faster R-CNN方法的耗时问题。它摒弃了区域建议网络,而是采用多尺度特征和默认框的方式进行物体检测。
架构概述
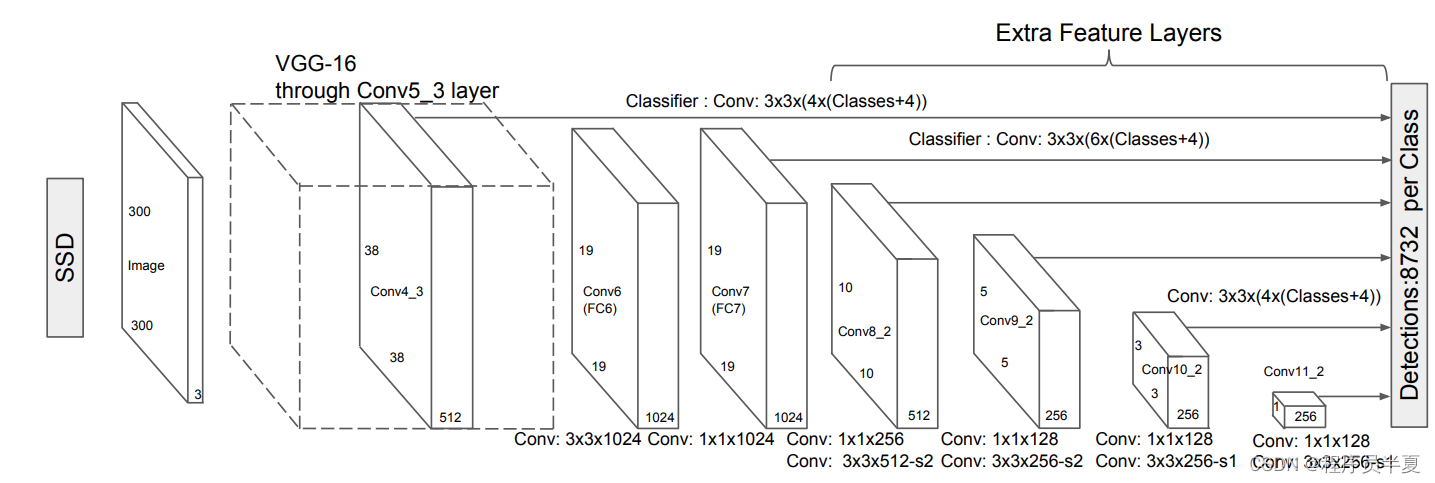
SSD的架构主要分为三个部分。首先是特征提取阶段,该阶段选择关键的特征图。这个部分的架构只包含全卷积层,没有其他层。在提取所有必要的特征图之后,下一步是检测头的处理过程,其中也包括全卷积神经网络。
然而,在检测头的第二阶段,任务不是为图像找到语义意义,而是为所有特征图创建最合适的边界映射。经过这两个关键阶段的计算后,最后一个阶段是通过非极大值抑制层传递,以减少由重复边界框引起的错误率。
SSD的局限性
尽管SSD显著提高了性能,但它会降低图像的分辨率,从而导致图像质量较低。对于小尺度物体,SSD架构的性能通常比Faster R-CNN差。
何时使用SSD
通常情况下,单发检测器是首选的方法。选择单发检测器的主要原因是更注重在图像上进行更快的预测,以检测较大的物体,而准确性并不是极其重要的关注点。然而,对于较小且需要更精确预测的物体,需要考虑其他方法。
5. YOLO(You Only Look Once)
6. RetinaNet
简介
RetinaNet是一种在2017年推出的目标检测模型,被认为是当时最佳的单次目标检测模型之一,超越了其他流行的目标检测算法。相比于Yolo v2和SSD模型,RetinaNet在保持相同速度的同时,在准确性方面与R-CNN家族竞争。由于其高效和准确的特性,RetinaNet在卫星图像目标检测等领域得到广泛应用。
架构概述
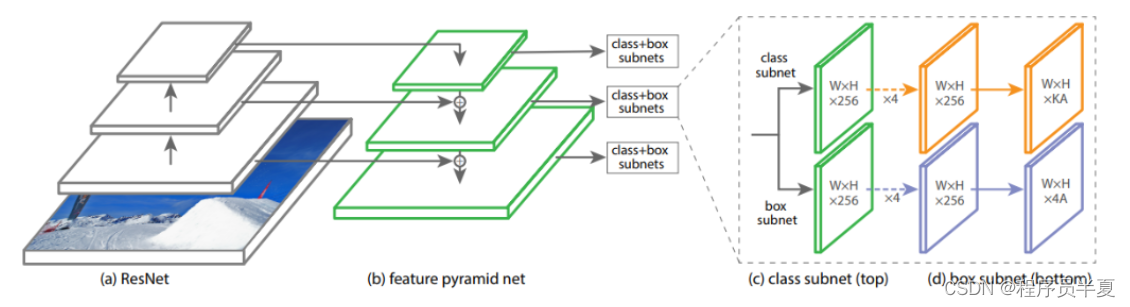
RetinaNet的架构通过一定程度上平衡先前单次检测器存在的问题,产生了更有效和高效的结果。在这个模型架构中,使用焦点损失代替了传统的交叉熵损失,解决了YOLO和SSD等架构中的类别不平衡问题。RetinaNet模型由三个主要组件构成。
RetinaNet的构建基于三个因素:ResNet模型(特别是ResNet-101)、特征金字塔网络(FPN)和焦点损失。特征金字塔网络是克服先前架构中大多数缺点的最佳方法之一。它将低分辨率图像的语义丰富特征与高分辨率图像的语义弱特征相结合。
在最终输出中,我们可以创建类似于之前讨论的其他目标检测方法的分类和回归模型。分类网络用于进行多类别预测,而回归网络用于预测适当的边界框。如果您想了解更多关于RetinaNet的信息,请参考以下链接中的文章或视频指南。
何时使用RetinaNet?
RetinaNet目前是许多不同任务中最佳的目标检测方法之一。它可以作为单次检测器的替代方案,用于各种任务,以实现快速而准确的图像结果。
目标检测库
1. ImageAI
简介
ImageAI库旨在为开发者提供多种计算机视觉算法和深度学习方法,以完成与物体检测和图像处理相关的任务。ImageAI库的主要目标是为编写物体检测项目提供一种简洁高效的方法。
要了解有关此主题的更多信息,请确保访问以下链接的ImageAI库的官方文档。大多数可用的代码块都是借助Python编程语言以及流行的深度学习框架Tensorflow编写的。截至2021年6月,该库使用PyTorch后端进行图像处理任务的计算。
概述
ImageAI库支持大量与物体检测相关的操作,包括图像识别、图像物体检测、视频物体检测、视频检测分析、自定义图像识别训练和推理以及自定义物体检测训练和推理。图像识别功能可以识别特定图像中多达1000种不同的物体。
图像和视频物体检测任务将有助于检测日常生活中最常见的80种物体。视频检测分析将有助于计算视频或实时检测到的特定物体的及时分析。在此库中,还可以引入自定义图像以训练您自己的样本。借助更新的图像和数据集,您可以为物体检测任务训练更多物体。
GitHub
https://github.com/OlafenwaMoses/ImageAI
2. GluonCV
简介
GluonCV是最佳库框架之一,具有最先进的深度学习算法实现,适用于各种计算机视觉应用。该库的主要目标是帮助该领域的爱好者在较短的时间内取得有成效的结果。它具有一些最佳功能,包括大量的训练数据集、实施技术和精心设计的API。
概述
GluonCV库框架支持大量您可以用它完成的任务。这些项目包括图像分类任务、图像、视频或实时物体检测任务、语义分割和实例分割、姿态估计以确定特定身体的姿态,以及动作识别以检测正在执行的人类活动类型。这些功能使得这个库成为实现更快结果的最佳物体检测库之一。
该框架提供了执行前述任务所需的所有最先进技术。它支持MXNet和PyTorch,并提供了丰富的教程和额外支持,您可以从中开始探索众多概念。它包含大量的训练模型,您可以从中探索并创建特定的机器学习模型,以执行特定任务。
在您的虚拟环境中安装了MXNet或PyTorch后,您可以按照此链接开始简单安装此物体检测库。您可以为库选择特定的设置。它还允许您访问Model Zoo,这是一个轻松部署机器学习模型的最佳平台。所有这些功能使GluonCV成为一个出色的物体检测库。
GitHub
https://github.com/dmlc/gluon-cv
3. Detectron2
简介
由Facebook的AI研究(FAIR)团队开发的Detectron2框架被认为是下一代库,支持大多数最先进的检测技术、物体检测方法和分割算法。Detectron2库是一个基于PyTorch的物体检测框架。该库具有高度的灵活性和可扩展性,为用户提供多种高质量的实现算法和技术。它还支持Facebook上的众多应用和生产项目。
概述
由FaceBook基于PyTorch开发的Detectron2库具有巨大的应用价值,可以在单个或多个GPU上进行训练,以产生快速有效的结果。借助这个库,您可以实现多种高质量的物体检测算法,以获得最佳效果。这些由库支持的最先进技术和物体检测算法包括:
DensePose、全景特征金字塔网络以及Mask R-CNN模型家族的许多其他变体。
Detectron2库还允许用户轻松训练自定义模型和数据集。以下安装过程相当简单。您只需要PyTorch和COCO API这两个依赖项。一旦满足以下要求,您就可以安装Detectron2模型并轻松训练大量模型。要了解更多信息并了解如何使用以下库,您可以使用以下指南。
GitHub
https://github.com/facebookresearch/detectron2
4. YOLOv3_TensorFlow
简介
YOLO v3模型是2018年发布的YOLO系列的成功实现之一。YOLO的第三个版本在前几个模型的基础上有所改进。与前几个版本相比,YOLOv3模型在检测速度和准确性方面取得了显著的改进。YOLOv3_TensorFlow库是基于TensorFlow的YOLOv3实现,旨在为开发者提供一个易于使用的物体检测工具。
概述
YOLOv3_TensorFlow库支持实时物体检测任务,适用于图像和视频。它提供了预训练的权重文件,可以直接用于物体检测。此外,您还可以使用自定义数据集对模型进行微调,以适应特定的应用场景。
YOLOv3_TensorFlow库的主要特点包括:
- 高速实时物体检测
- 支持多种物体类别
- 可以在CPU和GPU上运行
- 支持自定义数据集训练
要使用YOLOv3_TensorFlow库,您需要安装TensorFlow和其他相关依赖项。在满足这些要求后,您可以克隆GitHub仓库并开始使用YOLOv3进行物体检测任务。
GitHub
https://github.com/wizyoung/YOLOv3_TensorFlow
5. EfficientDet
简介
EfficientDet是一种高效的物体检测模型,由Google Brain团队开发。它基于EfficientNet模型,并结合了特征金字塔网络(FPN)和加权双向特征金字塔网络(BiFPN)。EfficientDet在速度和准确性方面表现出色,是一个值得关注的物体检测库。
概述
EfficientDet库提供了多种预训练模型,适用于不同的计算能力和应用场景。它支持实时物体检测任务,并可以在CPU、GPU和TPU上运行。EfficientDet还允许用户使用自定义数据集进行训练,以适应特定的需求。
EfficientDet库的主要特点包括:
- 高效的物体检测性能
- 支持多种物体类别
- 可以在CPU、GPU和TPU上运行
- 支持自定义数据集训练
要使用EfficientDet库,您需要安装TensorFlow和其他相关依赖项。在满足这些要求后,您可以克隆GitHub仓库并开始使用EfficientDet进行物体检测任务。
GitHub
https://github.com/google/automl/tree/master/efficientdet
结论
物体检测仍然是迄今为止最重要的深度学习和计算机视觉应用之一。我们已经看到了物体检测方法的很多改进和进步。
它始于1986年引入的用于在图像上执行简单物体检测的梯度方向直方图等算法,具有相当高的准确性。现在,我们拥有了更现代的架构,如Faster R-CNN、Mask R-CNN、YOLO和RetinaNet。
物体检测的限制不仅限于图像,还可以在视频和实时画面上以高准确性有效地执行。在未来,我们还将迎来更多成功的物体检测算法和库。