随着人工智能的兴起,目标检测算法在各行业中起的作用越来越大,怎么落地,这是一个非常严峻的话题。今天看到一位大牛的分享,学习了。
把该领域的算法和历史做个梳理。方便后续研究。
按照时间分类,可以把该算法分成两类:传统算法和CCN算法。
传统算法:
- 级联分类器框架:Haar/LBP/积分HOG/ACF feature+Adaboost
级联分类器最先由Paul Viola and Michael J. Jones在CVPR 2001中提出来。
其实这就是boosting由简单弱分类拼装强分类器的过程,现在看起来很low,但是这个算法第一次使目标检测成为现实!
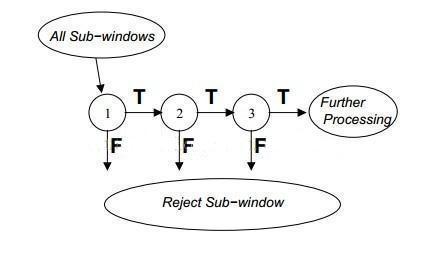
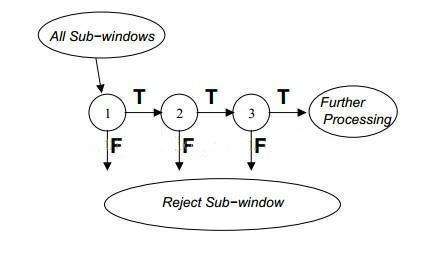
OpenCV有对级联分类器的经典实现:https://docs.opencv.org/2.4.11/modules/objdetect/doc/cascade_classification.html?highlight=haar
至于使用的特征,Haar简单也够用了,LBP实在是没必要去扒了。。。
至于HoG/ACF,下面说。
- HoG+SVM
Histograms of oriented gradients for human detection,2005,CVPR

由于原始的Haar特征太简单,只适合做刚性物体检测,无法检测行人等非刚性目标,所以又提出了HOG+SVM结构。
在OpenCV中也有实现:https://docs.opencv.org/2.4.11/modules/gpu/doc/object_detection.html?highlight=hog


之后又有人魔改出LoG/DoG/RoG等一系列特征,没啥意思就不多说了。
值得一提的是,有人把SVM中的HoG改为Integral HoG,用于级联分类器。这也就是目前OpenCV级联分类器的积分HOG的原型:
Integral Histogram: A Fast Way to Extract Histograms in Cartesian Spaces
后续又有人发展出了Aggregate Channel Feature(ACF)等特征,论文主要是下面2个:
Aggregate Channel Features for Multi-view Face Detection,2014,IJCB
Fast Feature Pyramids for Object Detection,2014,PAMI
亮点就是这个Fast,加速了Integral HoG的计算,效果好而且快,依然活跃在嵌入式领域。
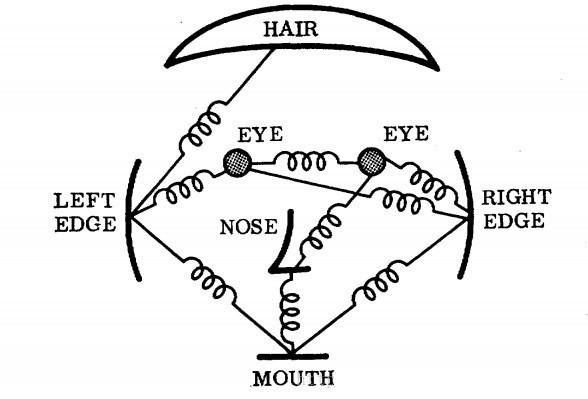
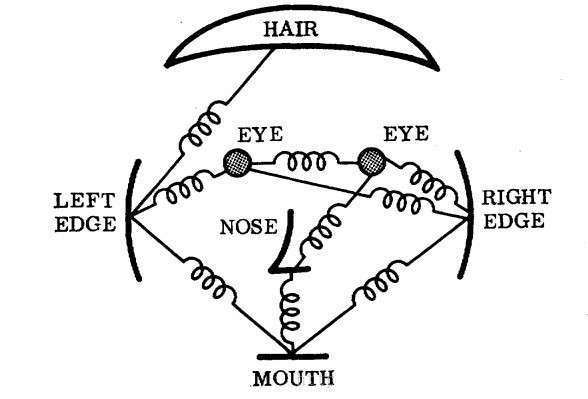
- Discriminatively trained deformable part models(DPM)
项目主页:http://www.rossgirshick.info/latent/


DPM是使用弹簧模型进行目标检测,如下图。即进行了多尺度+多部位检测,底层图像特征抽取采用的是fHoG。反正也是轰动一时了。
后续又有DPM+/DPM++,没啥意思不提也罢。
- 模版匹配:就是在一幅图像中寻找另一幅模板图像最匹配(也就是最相似)的部分的技术。相关的实现参考:https://www.cnblogs.com/skyfsm/p/6884253.html
链接:https://www.zhihu.com/question/53438706/answer/148973444
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
CNN方法:
- 基于region proposal(two stage):R-CNN家族,包括Faster R-CNN/Mask R-CNN/RFCN
然而DPM火了没到2年,R-CNN家族出现了,终于不再用各种魔改版HoG特征搞检测了!
其中R-CNN家族最有代表性的就是Faster R-CNN。Faster R-CNN由RPN网络先产生region proposal,再对region proposals进行classification,就是所谓的two stage。
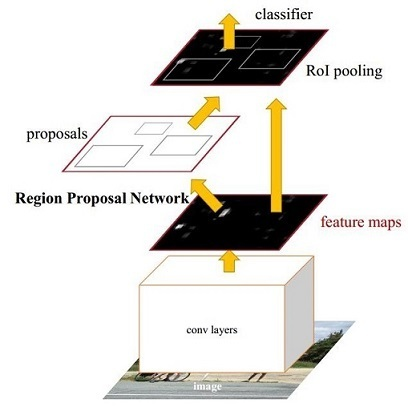
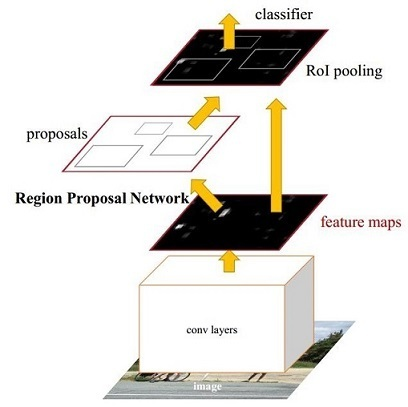
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
其实R-CNN系列检测关注他:Kaiming He - FAIR,完全足够了。
- 基于回归(one-shot):YOLO/YOLO2/SSD/DSSD
YOLO和SSD都是产生proposal的同时进行classification+regression,一次性完成,即所谓的one-shot。相比two stage速度占优,Precision/Recall略低。
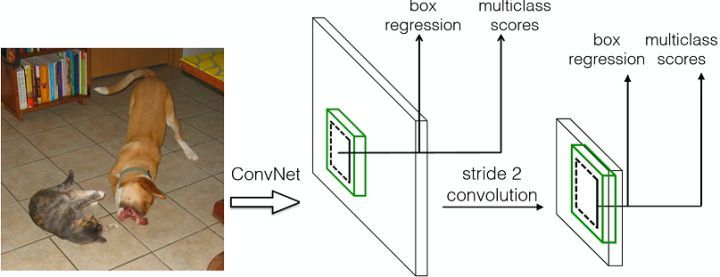
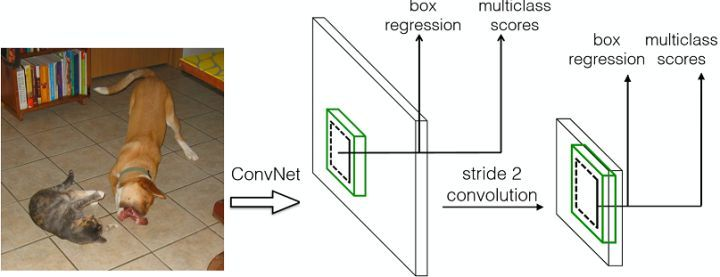
SSD:SSD: Single Shot MultiBox Detector
至于YOLO,目前有YOLO v1,YOLO 9000(v2),YOLO v3
另外我觉得,后续版本DSSD和YOLO v2/v3之间真的没啥差距了,感觉都一样。
这也说明检测已经趋于瓶颈,没有算法突破很难像以前,一下提高几十个点。
- 特殊的文字序列检测:CTPN(LSTM + R-CNN)/Seglink(SSD魔改)
除了一般意义上的检测,还有一类文字检测,用于OCR前的文字定位。这类检测和一般的检测还有一点点不一样。目前效果比较好的2种:CTPN和Seglink


Faster R-CNN的继承:CTPN水平or竖直文字检测
Detecting Text in Natural Image with Connectionist Text Proposal Network, ECCV, 2016.
SSD的继承:Seglink倾斜文字检测
Detecting Oriented Text in Natural Images by Linking Segments,CVPR,2017
代码 https://github.com/dengdan/seglink
当然文字检测算法也有传统的,比如这个OpenCV自带:
Real-Time Scene Text Localization and Recognition, CVPR 2012
不过不建议去折腾了,没必要。
总结:
传统方法的优势就是速度快,即使在嵌入式平台也可以做到高速实时;缺点就是Precision/Recall都不是很理想,简单说就是效果差;
CNN方法优势就是Precision/Recall都好很多;缺点对应的,速度慢。
目前在嵌入式中,传统算法还有一些空间,但是被Mobilenet等轻量化网络挤压;在服务器端,完全是深度网络的天下了。
参考文档: