一、TensorFlow计算模型------计算图
计算图是TF中最基本的一个概念,TF中的所有计算都会被转化为计算图上的节点。
1、计算图的概念
TF的名字已经说明了它最重要的两个概念----Tensor和Flow。Tensor就是张量,在TF中,张量可以被简单地理解为多维数组。如果说TF的第一个词Tensor表明了它的数据结构,那么Flow则体现了它的计算模型。Flow翻译成中文就是“流”,它直观地表达了张量之间通过计算相互转化的过程。TF是一个通过计算图的形式来表述计算的编程系统。TF中的每一个计算都是计算图上的一个节点,而节点之间的边描述了计算之间的依赖关系。
2、计算图的使用
TF程序一般可以分为两个阶段。在第一个阶段需要定义计算图中所有的计算,第二个阶段为执行计算。在Python中一般会采用“import tensorflow as tf“的形式来载入TF,这样使用”tf“来代替”tensorflow“作为模块名字使得整个程序更加简洁。在这个过程中,TF会自动将定义的计算转化为计算图上的节点。在TF程序中,系统会自动维护一个默认的计算图,通过tf.get_default_graph函数可以获取当前默认的计算图。除了使用默认的计算图,TF支持通过tf.Graph函数来生成新的计算图。不同计算图上的张量和运算都不会共享。
二、TensorFlow数据模型-----张量
张量是TF管理数据的形式
1、张量的概念
在TF程序中,所有的数据都通过张量(tensor)的形式来表示。从功能的角度看,张量可以被简单理解为多维数组。其中零阶张量表示标量(scalar),也就是一个数;第一阶张量为向量(vector),也就是一个一维数组;第n阶张量可以理解为一个n维数组。但张量在TF中的实现并不是直接采用数组的形式,它只是对TensorFlow中运算结果的引用。在张量中并没有真正保存数字,它保存的是如何得到这些数字的计算过程。
一个张量中主要保存了三个属性:名字(name)、维度(shape)和类型(type)。
张量的命名是通过”node:src_output“的形式来给出的,其中node为节点名称,src_output表示当前张量来自节点的第几个输出。比如”add:0“就说明这个张量是计算节点”add“输出的第一个结果(编号从0开始)
张量的第二个属性是张量的维度(shape)。这个属性描述了一个张量的维度信息,如shape=(2,)就说明该张量是一个一维数组,该数组长度为2.
张量的第三个属性是类型(type),,每个张量会有一个唯一的类型。
2、张量的使用
第一类用途是对中间计算结果的引用。当一个计算包含很多中间结果时,使用张量可以大大提高代码的可读性。
第二类用途是当计算图构造完成后,张量可以用来获得计算结果,也就是得到真实的数字。
三、TensorFlow运行模型------会话
会话拥有并管理TF程序运行时的所有资源。当所有计算完成后要关闭会话来帮助系统回收资源,否则就可能出现资源泄露的问题。TF中使用会话的模式一般有两种,第一种模式需要明确调用会话生成函数和关闭会话函数,这种模式的代码流程如下:
#创建一个会话
sess = tf.Session()
#使用这个创建好的会话来得到关系的运算的结果。
sess.run(...)
#关闭会话使得本次运行中使用到的资源可以被释放
sess.close()
使用这种模式时,在所有计算完成后,需要明确调用Session.close函数来关闭会话并释放资源。然而,当程序因为异常而推出时,关闭会话的函数可能就不会被执行从而导致资源泄露。为了解决异常退出时资源释放的问题,TF可以通过Python的上下文管理器来使用会话,如下:
#创建一个会话,并通过Python中的上下文管理器来管理这个会话。
with tf.Session() as sess:
#使用这创建好的会话来计算关心的结果
sess.run(...)
#不需要再调用“Session.close()”函数来关闭会话,当上下文退出时会话关闭和资源释放也就自动完成了。
四、TensorFlow实现神经网络
1、TensorFlow游乐场及神经网络简洁

TF游乐场(http://playground.tensorflow.org)是一个通过网页浏览器就可以训练的简单神经网络并实现了可视化训练过程的工具。从上图可以看出,TF游乐场左侧提供了4个不同的数据集来测试神网络。默认的数据为左上角被框出来的那个。被选中的数据也会显示在最右边“OUTPUT"栏下。在这个数据中,可以看到一个二维平面上有蓝色和黄色的点,每一个小点代表一个样例,而点的颜色代表了样例的标签。在这里点的颜色只有两种,所以是一个二分类的问题。
为了将一个实际问题对应到平面上不同颜色点的划分,还需要将实际问题中的实体变成平面上的一个点,这就是特征提取解决的问题。
特征向量是神经网络的输入,神经网络的主体结构在上图的中间位置。主流的神经网络都是分层的结构,第一层是输入层,代表特征向量中每一个特征的取值。同一层的节点不会相互连接,而且每一层只和下一层连接,知道最后一层作为输出层得到计算的结果。在输入和输出层之间的神经网络叫做隐藏层,一般一个神经网络的隐藏层越多,这神经网络就越”深“。而所谓深度学习中的这个“深度”和神经网络的层数也是密切相关的。在TF游乐场中可以通过点击“+”或者“-”来增加/减少神经网络隐藏层的数量。除了可以选中神经网络的深度,TF游乐场也支持选择神经网络每一层的节点数以及学习率(learning rate)、激活函数(activation)、正则化(regularization)。当所有配置都选好后,可以通过左上角的开始标志开始训练这个神经网络。下图为这个神经网络迭代了307次后的结果:

这个神经网络的训练结果解读如下:一个小格子代表神经网络中的一个节点,而边代表节点之间的连接。每一条边代表了神经网络中的一个参数,它可以是任意实数。神经网络就是通过对参数的合理设置来解决分类或者回归问题的。边上的颜色体现了这个参数的取值,当边的颜色越深时,这个参数取值的绝对值越大;当边的颜色接近白色时,这个参数的取值接近于0.
每一个节点上的颜色代表了这个节点的区分平面。具体来说,如果把这个平面当成一个笛卡尔坐标系,这个平面上的每一个点就代表了(x1,x2)的一种取值。而这个点的颜色就体现了x1,x2在这种取值下这个节点的输出值。和边类似,当节点的输出值的绝对值越大时,颜色越深。
综上所述,使用神经网络解决分类问题主要为以下四个步骤:
(1)、提取问题中实体的特征向量作为神经网络的输入
(2)、定义神经网络的结构,并定义如何从神经网络的输入得到输出
(3)、通过训练数据来调整神经网络中参数的取值,这就是训练神经网络的过程
(4)、使用训练好的神经网络来预测未知的数据。
2、向前传播算法简介
计算神经网络的前向传播结果需要三部分信息。第一部分是神经网络的输入,这个输入就是从实体中提取的特征向量。第二部分是神经网络的连接结构;最后一个部分是每个神经元中的参数。给定神经网络的输入,神经网络的结构以及边上的权重,就可以通过前向传播算法来计算出神经网络的输出。当然,知道输入,结构,输出,也可以求权重。

如何计算传播
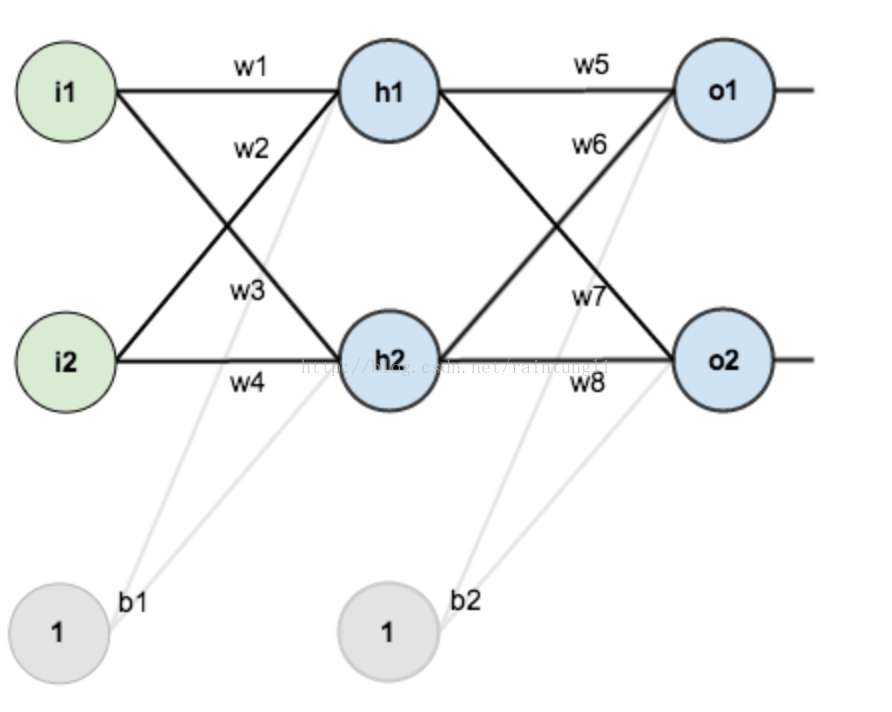
- 第一层输入层:里面包含神经元i1,i2,截距:b1,权重:w1,w2,w3,w4
- 第二层是隐含层:里面包含h1,h2,截距:b2,权重:w5,w6,w7,w8
- 第三层是输出层:里面包含o1,o2
输入层到隐含层
从隐含层到输出层
计算总误差

3、神经网络参数与TensorFlow变量
在TensorFlow中,变量(tf.Variable)的作用就是保存和更新神经网络中的参数。TF中的变量也需要指定初始值,因为在神经网络中,给参数赋予随机初始值最为常见,所以一般也使用随机数给TF中的变量初始化。
TF变量的声明函数是tf.Variable,TF中的变量的初始值可以设置为随机数、常数或者是通过其他变量的初始值计算得到。TF的一些随机数生成器有:tf.random_normal tf.truncated_normal tf.random_uniform tf.random_gamma
TF也支持通过常数来初始化一个变量:tf.zeros tf.ones tf.fill tf.constant
一个实现了神经网络的前向传播过程的完整代码:
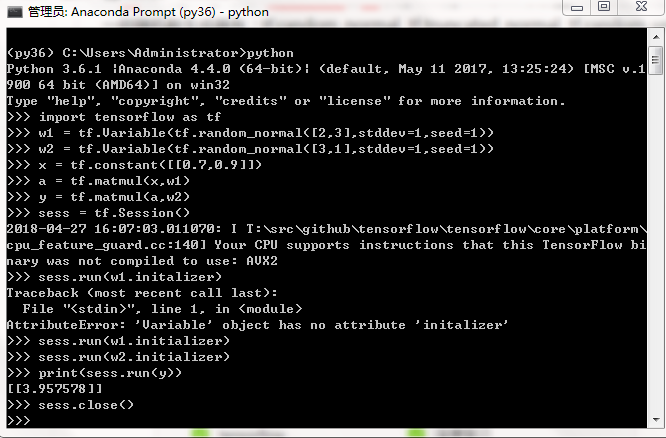
可以看出,当声明了变量w1、w2之后,可以通过w1和w2来定义神经网络的前向传播过程并得到中间结果a和最后答案y。定义w1、w2、a和y的过程对应了前面讲到的TF程序的第一步,这一步定义了TF计算图中所有的计算,但这些被定义的计算在这一步中并不真正的运行。当需要运行这些计算并得到具体数字时,需要进入TF程序的第二步,第二步会声明一个会话(session),并通过会话计算结果。
注意,在计算y之前,需要将所有用到的变量初始化,也就是说,虽然在变量定义时给出了变量初始化的方法,但是这个方法并没有被真正运行。所以在计算y之前,需要通过运行w1.initializer和w2.initializer来给变量赋值。但是这样一个个给变量初始化可行,但是当变量很多的时候会很麻烦,所以可以通过tf.initialize_all_variables这个函数实现初始化所有变量的过程。
4、通过TensorFlow训练神经网络模型
在使用神经网络解决实际的分类或者回归问题时(比如判断一个零件是否合格)需要更好地设置参数取值。可以使用监督学习的方式来更合理低设置参数取值,使用监督学习的方式设置神经网络参数需要有一个标注好的训练数据集,监督学习最重要的思想就是,在已知答案的标注数据集上,模型给出的预测结果要尽量接近真实的答案,通过调整神经网络中的参数对训练数据进行拟合,可以使得模型对未知的样本提供预测的能力。设置神经网络参数的过程就是神经网络的训练过程。只有经过有效训练的神经网络模型才可以真正的解决分类或者回归问题。在神经网络优化算法中,最常用的方法是反向传播算法(backpropagation),它的流程图为:
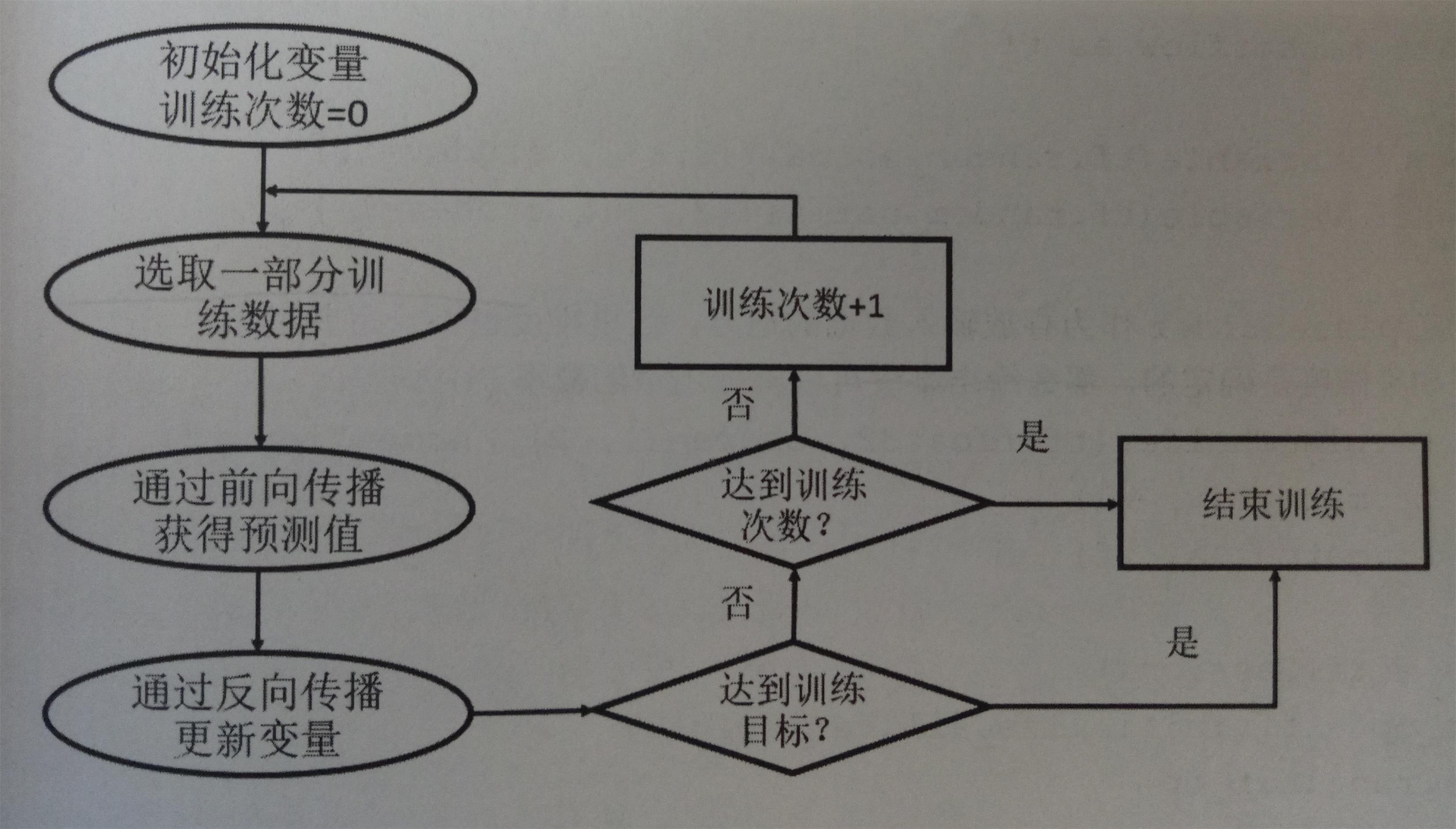
从该图可以看出,反向传播算法实现了一个迭代的过程。在每次迭代的开始,首先需要选取一小部分训练数据,这一小部分训练数据叫做一个batch。然后,这个batch的样例会通过前向传播算法得到神经网络模型的预测结果。因为训练数据都是有正确答案标注的,所以可以计算出当前神经网络模型的预测答案与正确答案之间的差距。最后,基于这预测值和真实值之间的差距,反向传播算法会相应更新神经网络参数的取值,使得这个batch上神经网络模型的预测结果和真实答案更接近。
placeholder机制用于提供输入数据。它相当于定义了一个位置,这个位置中的数据在程序运行时再指定。这样在程序中就不需要生成大量常量来提供输入数据,而只需要将数据通过placeholder传入TF计算图。placeholder定义时,这个位置上的数据类型是需要指定的而且指定以后不可更改。
5、训练神经网络过程步骤
(1)、定义神经网络的结构和前向传播的输出结果
(2)、定义损失函数以及选择反向传播优化的方法
(3)、生成会话(tf.Session)并且在训练数据上反复运行反向传播优化算法
无论神经网络的结构如何编号,这三个步骤都是不变的。