总的来说,Kafka Producer是将数据发送到kafka集群的客户端。其组成部分如下图所示:
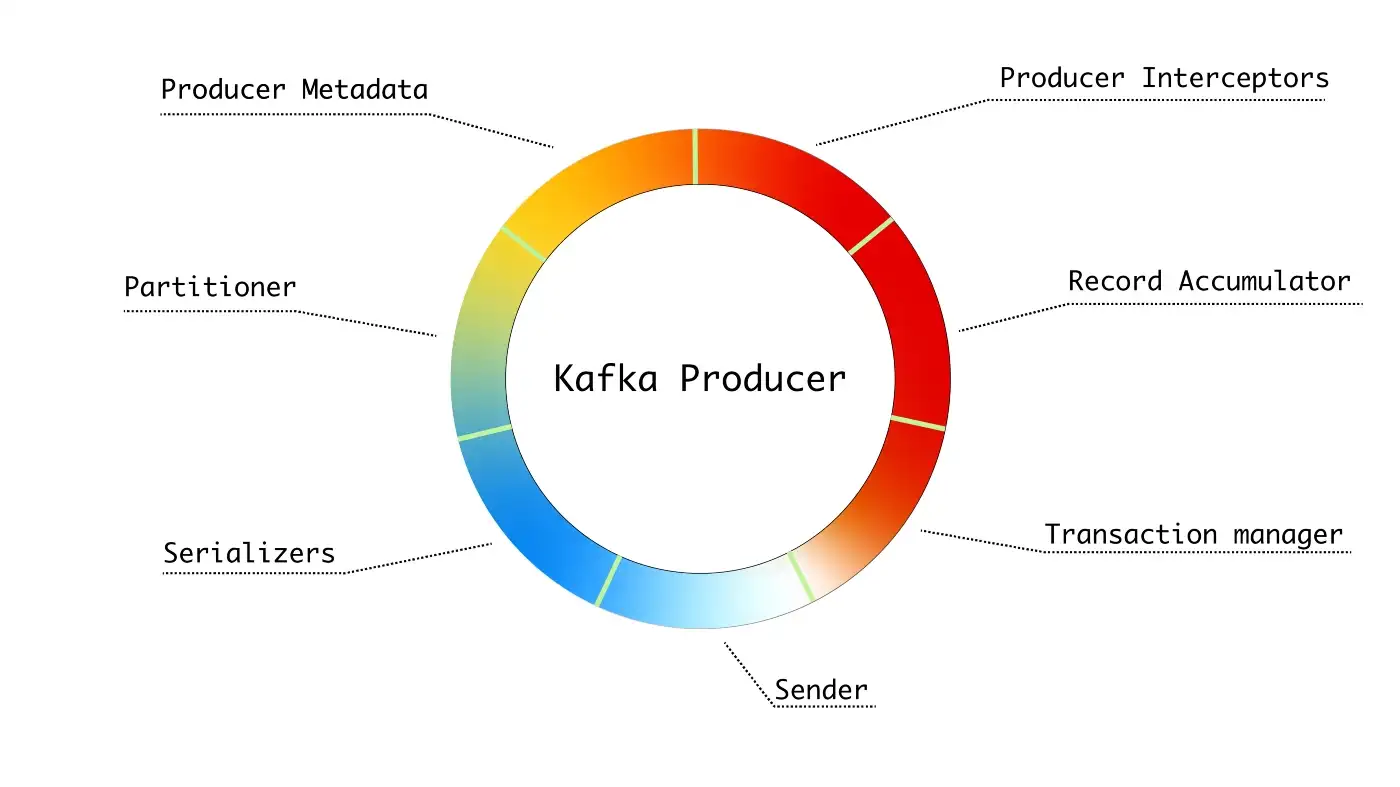
基本组件:
- Producer Metadata——管理生产者所需的元数据:集群中的主题和分区、充当分区领导者的代理节点等。
- Partitioner——计算给定记录的分区。
- Serializers——记录键和值序列化器。 序列化程序将对象转换为字节数组。
- Producer Interceptors——可能改变记录的拦截器。
- Record Accumulator——累积记录并按主题分区将它们分组为批次。
- Transaction manager——管理事务并维护必要的状态以确保幂等生产。
- Sender——向 Kafka 集群发送数据的后台线程。
配置Kafka Producer
kafka producer有三个必须指定的参数:
- bootstrap.servers — 主机/端口对列表,用于建立与 Kafka 集群的初始连接。 格式:“host1:port1,host2:port2,…”
- key.serializer — 代表实现 org.apache.kafka.common.serialization.Serializer 接口的key序列化器的完全限定类名。
- value.serializer — 代表实现 org.apache.kafka.common.serialization.Serializer 接口的value序列化器的完全限定类名。
数据发送到kafka流程
Kafka Producer异步发送消息,返回一个Future,代表发送结果。 此外,用户可以选择提供在 Kafka broker确认记录时调用的回调。 虽然它看起来很简单,但在背后却发生了一些事情。
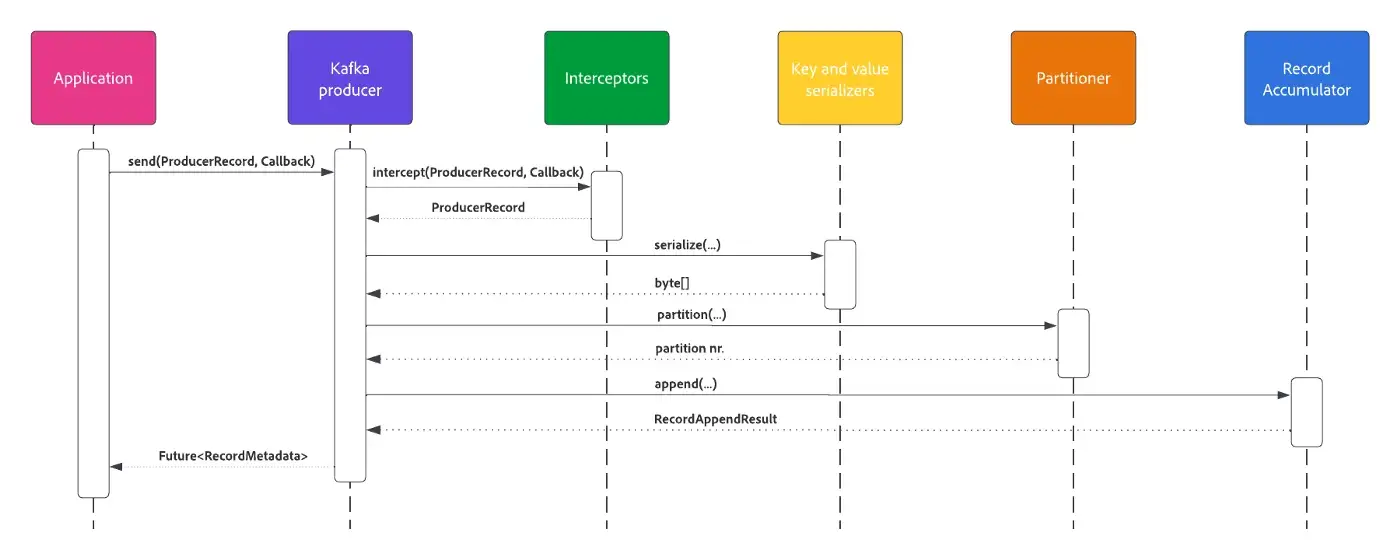
- 生产者将消息传递给已配置的拦截器列表。 例如,拦截器可能会改变消息并返回更新版本。
- 序列化程序将记录键和值转换为字节数组
- 如果没有特别指定,则使用默认或配置的分区程序计算主题分区。
- 记录累加器使用配置的压缩算法将消息附加到生产者批次。
此时,消息还在内存中,并没有发送给Kafka broker。 Record Accumulator 按主题和分区对内存中的消息进行分组。
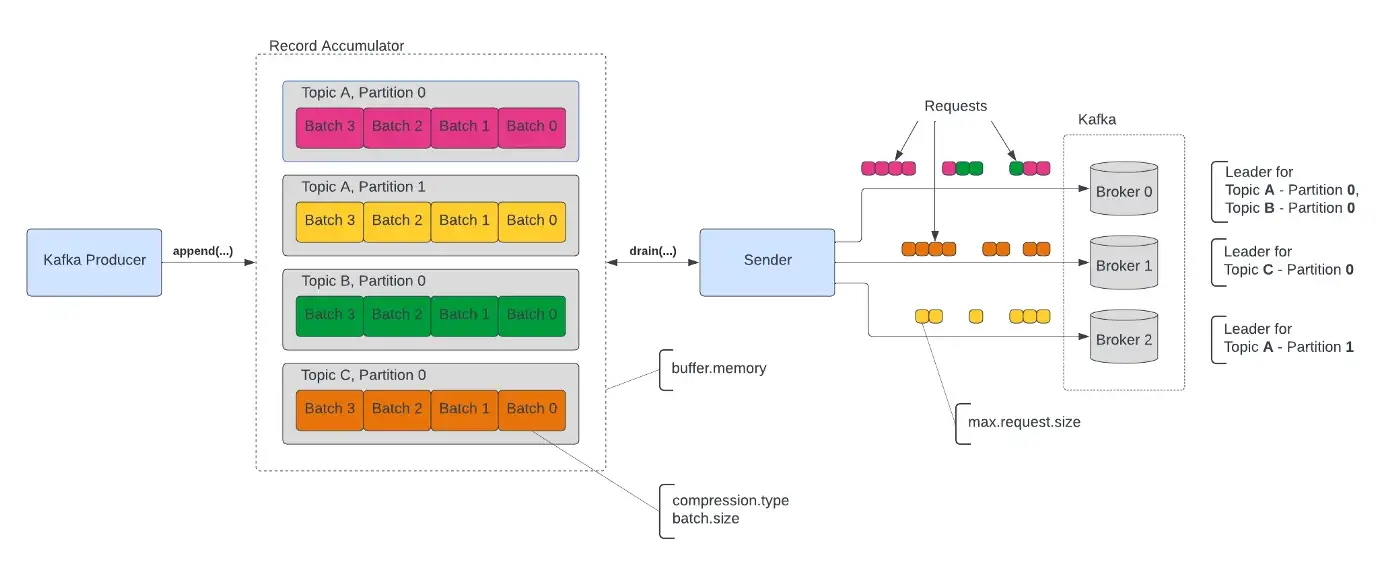
Sender线程将具有相同broker的多个批次作为领导者分组到请求中并发送它们。 此时,消息被发送到Kafka。
发送时间
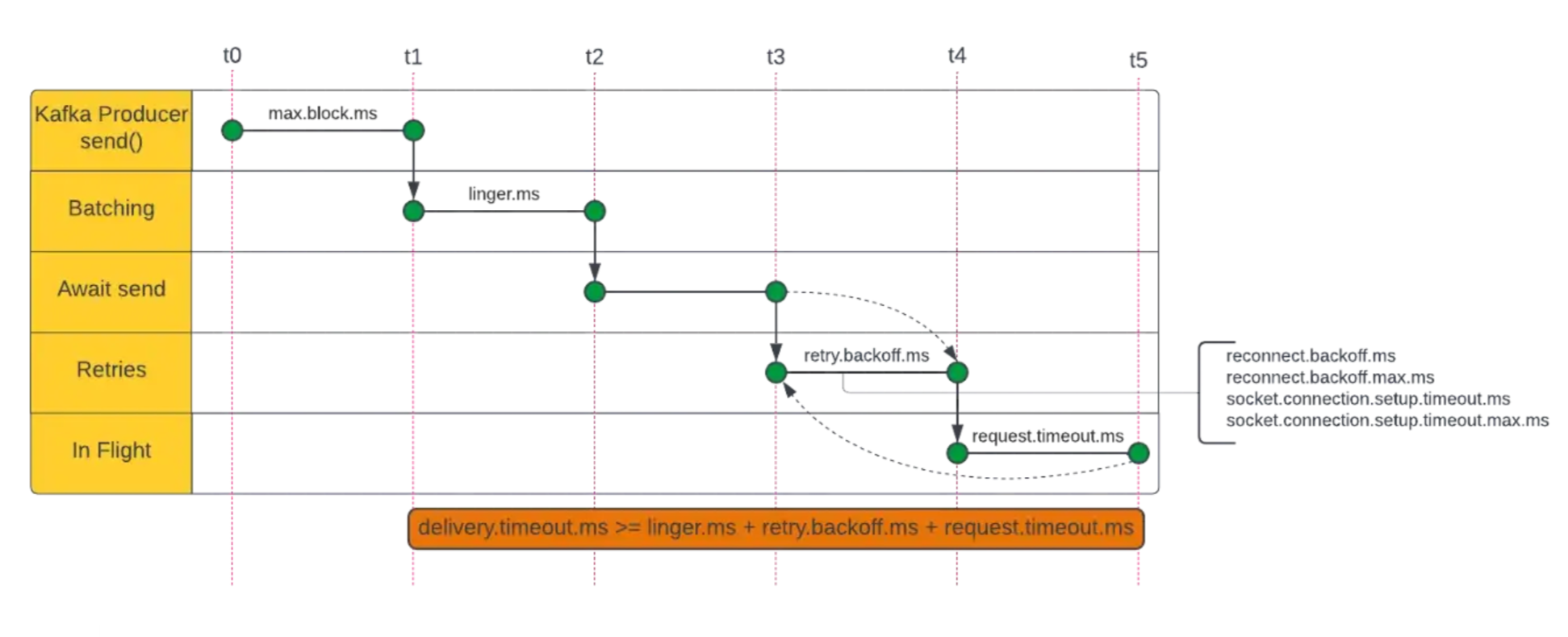
Kafka Producer 提供配置参数来控制在各个阶段花费的时间:
- max.block.ms — 等待元数据获取和缓冲区分配的时间
- linger.ms — 等待发送其他记录的时间
- retry.backoff.ms——重试失败请求前等待的时间
- request.timeout.ms — 等待 Kafka broker 响应的时间
- delivery.timeout.ms — 后来引入,是 KIP-91 的一部分,用于为用户提供有保证的超时上限,而无需调整生产者组件内部结构
数据持久性
用户可以通过 acks 配置参数控制写入 Kafka 的消息的持久性。 允许的值为:
- 0, producer 不会等待 broker 确认
- 1,一个生产者只会等待分区领导者写消息,而不需要等待所有的追随者
- all,生产者将等待所有同步副本确认消息。 这是以延迟成本为代价的,代表了最强大的可用保证。
使用 acks=all 时,对于同步副本有一些细微差别需要澄清。 在 Kafka 方面,两个设置和当前状态会影响行为:
- Topic replication factor
- min.insync.replicas 设置
- 当前同步副本的数量,包括领导者本身。
min.insync.replicas 指定 acks=all 请求的同步副本的最小阈值。 如果不能满足这个要求,Broker 会拒绝 producer 的请求,甚至不尝试写等待确认。 下表说明了可能的情况。

在瞬时故障期间,同步副本数可能低于副本总数,但只要它大于或等于 min.insync.replicas——带有 acks=all 的请求就会成功。
用户可以通过重新发送失败的请求来减轻暂时性故障并增加持久性。 这可以通过重试(默认 MAX_INT)和 delivery.timeout.ms(默认 120000)设置来实现。 重试可能会导致消息重复并改变消息的顺序。 这些副作用可以通过设置 enable.idempotence=true 来减轻,但它是以降低吞吐量为代价的。
分区
主题中的消息被组织成分区。 用户可以通过消息键或可插入的 ProducerPartitioner 实现来控制分区分配。 Partitioner 可以使用 partitioner.class 配置来设置,它应该是一个实现 org.apache.kafka.clients.producer.Partitioner 接口的完全限定类名。
Kafka 提供了三种开箱即用的实现:DefaultPartitioner、RoundRobinPartitioner 和 UniformStickyPartitioner。
DefaultPartitioner——如果消息键为空——使用当前分区,并在下一批中更改。 对于非空键,它使用以下公式计算:murmur2hash(key) % total nr of topic partitions。
RoundRobinPartitioner — 忽略消息键,以循环方式在所有活动分区之间平均分配消息。 如果分区有一个指定的代理作为领导者,则分区被认为是活跃的。
UniformStickyPartitioner——忽略消息键,使用当前分区,并在下一批更改分区。