目录
1,内部模块以及作用
mysql 内部主要大的分为mysql服务层和存储引擎层。服务层包含连接器、解析器、预处理器、优化器、执行器。主要做对数据的操作、过滤、计算功能;存储引擎层为单独的存储引擎层,主要负责对数据的存取,存储引擎往下就是计算机的文件系统硬件。

- 连接器
- 解析器
- 预处理器
- 优化器
- 执行器
- 存储引擎
1,连接器:
连接器主要进行管理数据库链接对象,以及在连接的时候与用户权限进行验证
2,解析器:
解析器主要对sql进行词法和语法的解析。词法解析主要将sql语句拆分为单独的一个个单词,而语法解析则是对sql进行一些语法检查,比如单引号,括号等是否正常有正常结束,然后根据mysql的语法规则将要执行的sql语句生成一个解析树(查询的:select_lex)

3,预处理器
预处理器主要做在解析器正常未报错的解析执行的sql后,对于语法没问题的sql进行进一步的检查,比如检查sql中的表是否存在,字段否存在,sql是否有歧义,用户执行权限是否匹配。预处理之后将会生成一个新的解析树。
4,优化器(Optimizer)
在上一步预处理之后得到的sql是否就可以直接执行了呢?实际上一条sql还有很多种执行的方式结果都是一致的,但是怎么去选择最优的执行方式则是由优化器进行实现。
优化器主要是根据预处理器生成的解析树生成不同的执行计划,选择一种最优的执行计划(mysql采用的为基于成本(cost)的优化器,那种成本最小选择那种)。
优化器的其他优化地方包含多表关联查询时选择那张表作为基表、有多个索引时,选择那个索引、移除多余的括号,1=1恒等式等。
执行计划可以通过在sql 语句的前面加上 EXPLAIN ,可以查看执行计划的信息。添加 EXPLAIN FORMAT=JSON SQL... 可以查看更详细的执行计划信息。

5,执行器
执行器通过调用存储引擎层提供的api接口调用执行优化器生成的执行计划,最后将结果数据返回给客户端。
6,存储引擎
存储引擎的类型主要使用的有三种:InnoDB、MyISAM、Memory。
如何指定:建表的时候通过ENGINE关键词指定 create table 'xxxx'(xxxx) ENGINE=InnoDB 来指定
不同引擎间差异:
InnoDB(2个文件):
为mysql5.7的默认存储引擎。
支持事务,支持外键,因此数据的完整性、一致性更高。
支持行级别的锁和表级别的锁。
支持读写并发,写不阻塞读(MVCC)。
特殊的索引存放方式,可以减少IO,提升查询效率。
Memory(1 个文件):
把数据放在内存里面,读写的速度很快,但是数据库重启或者崩溃,数据会全部消失。只适合做临时表。
将表中的数据存储到内存中。
默认使用哈希索引。
MyISAM(3 个文件)
支持表级别的锁(插入和更新会锁表)。不支持事务。
拥有较高的插入(insert)和查询(select)速度。
存储了表的行数(count 速度更快)。
(怎么快速向数据库插入100 万条数据?我们有一种先用MyISAM 插入数据,然后修改存储引擎为InnoDB 的操作。)
如何选择存储引擎
如果对数据一致性要求比较高,需要事务支持,可以选择InnoDB。
如果数据查询多更新少,对查询性能要求比较高,可以选择MyISAM。
如果需要一个用于查询的临时表,可以选择Memory。
2,一条select语句的执行流程

3,一条update语句的执行流程
Updata 实际指的update insert 以及delete操作的语句。

4,InnoDB的缓冲池(Buffer Pool)
由于数据都是存储在硬盘上,存储引擎需要操作数据都是先将数据读取加载到内存中进行操作。存储引擎在读取磁盘数据时是有一个最小单位的,称之为页大小。操作系统也有也页大小,一般为4KB(一个1byte的文本文件占用空间为4kb)。InnoDB的页大小为16KB,即InnoDB每次从硬盘上一次I/O操作读写的数据都是16kb的整倍数。
为了加快数据的操作以及相应速度,InnoDB设计了一个内存缓冲区Buffer Pool。当InnoDB读取数据的时候,首先判断该数据是否在这个内存缓冲区中,如果存在则直接从缓冲区中读取操作,如果不存在则从硬盘上读取,并将数据缓存到缓冲区中。
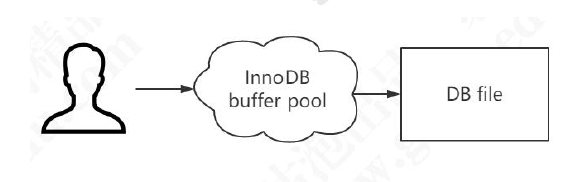
脏页:在修改数据的时候也是将数据先写入到缓冲区中,这是缓存区与硬盘中的数据不一致,称之为存在脏页。
刷脏:InnoDB有专门的后台线程会定时的将缓冲区中的修改数据一次性写入到硬盘中,这个过程称之为刷脏。
5,InnoDB的Log Buffer:
redo log(重做日志,位于/var/lib/mysql/目录下的ib_logfile0 和ib_logfile1,默认2 个文件):我们知道在上面的BufferPool中数据都是存放在一个内存缓冲区中的,如果发生断电等场景,内存中的数据都将会消失,如果没有机制保证缓冲区中的数据持久化,则刚更新的数据将无法写入到磁盘中,造成数据丢失。所以InnoDB存在一个redo log文件专门用来记录在buffer pool中的每一次的修改操作。当出现断电等情况,下次启动数据库时,InnoDB将会从redo log中将之前未刷入到磁盘的操作,恢复刷新到磁盘中。以保证数据的持久性。(由于写redolog 文件是顺序读写(一次寻道时间+一次旋转+一次读写),比操作数据库数据的随机读写(多次的(寻道时间+旋转时间+读写时间))效率高,所以采用写redolog,而不是直接写到数据库数据文件中)。redo log的大小是固定的,一旦数据写满,将会触发InnoDB的定时任务去进行刷脏操作。然后继续在覆盖之前内容记录日志。

undo log(回滚日志):undo log 主要记录了开启事务之前的数据状态,如果在事务过程中发生异常,将会使用undo log来实现数据的回滚恢复。来保证事务的原子性。此处类似于alibaba seata 分布式事务一致性中的beforeimage 记录,用于失败恢复补偿。
6,Binlog
binlog 以事件的形式记录了所有的DDL 和DML 语句。其两个非常重要的作用为1、主从复制,2、数据恢复。
主从复制的原理就是从服务器读取主服务器的binlog,然后执行一遍。
