一、boost前提介绍
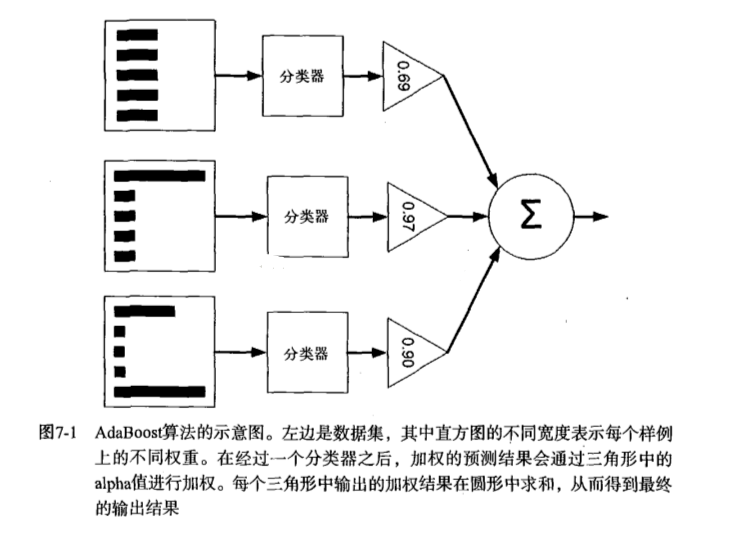
提升(Boost)简单地来说,提升就是指每一步我都产生一个弱预测模型,然后加权累加到总模型中,然后每一步弱预测模型生成的的依据都是损失函数的负梯度方向,这样若干步以后就可以达到逼近损失函数局部最小值的目标。boosting分类的结果是基于所有分类器的加权求和结果的,分类器每个权重代表的是其对应分类器在上一轮迭代中的成功度。而bagging中的分类器权重是相等的。其中Adaboost就是boosting方法中一个极具代表性的分类器。
二、Adaboost训练算法介绍
AdaBoost(adaptiveboosting):训练数据中的每个样本,并赋予其一个权重,这些权重构成了向量D。一开始,这些权重都初始化成相等值。首先在训练数据上训练出一个弱分类器并计算该分类器的错误率,然后在同一数据集上再次训练弱分类器。重新调整每个样本的权重,第一次分对的样本的权重将会降低,分错的样本的权重将会提高。AdaBoost为每个分类器都分配了一个权重值alpha,其基于每个弱分类器的错误率进行计算的。错误率的定义:

AdaBoost算法的流程图:
对权重向量D更新,如果某个样本被正确分类,那么该样本的权重改为:
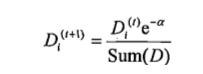
计算出D后,AdaBoost继续迭代重复训练调整权重,直到训练错误率为0或者弱分类器的数据达到用户指定值为止。
三、完整AdaBoost算法实现
伪代码
对每次迭代: 利用buildStump()函数找到最佳的单层决策树 将最佳单层决策树加入到单层决策树数组 计算alpha 计算新的权重向量D 更新累计类别估计值 如果错误率等于0.0,则退出循环
函数大致包括以下几个:
1、基于单层决策树的Adaboost训练过程
2、Adaboost分类函数
如果我们需要在一个较为复杂的数据集中使用adaboost,最好还加上一个自适应数据加载函数。(注:代码均在本文结尾处统一放置)
四、选用一个复杂数据集进行测试
Wine数据集,中文叫做酒数据集,Wine数据集具有好的聚类结构,它包含178个样本,13个数值属性,分成3个类,每类中样本数量不同。但是在这里我们只去前130个样本分作两类进行测试。该数据集可以从uci数据库中下载。Wine数据集下载地址:http://archive.ics.uci.edu/ml/datasets/Wine
http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data

在这里需要注意的是AdaBoost需要确保标签类别是+1和-1而非1和0,且自适应数据加载函数假定最后一个特征是类别标签,所以在这里可以通过修改数据的txt文档或者是修改自适应数据加载函数来使得程序正常运行。(注:书中默认程序所限制所有数据应均为浮点数,所以在导入任何数据库的时候都应转换成浮点数)

以下是测试过程:
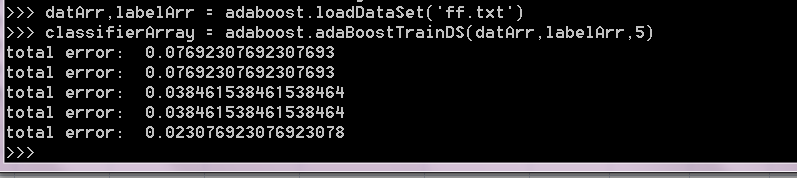
可见其预测结果非常准确,但如果将运行次数变成10的同时,在最后的报错中将显示没有错误,在这里我有些疑问,如果大家知道可以在评论区给我留言。
ROC曲线是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率(灵敏度)为纵坐标,假阳性率(1-特异度)为横坐标绘制的曲线。传统的诊断试验评价方法有一个共同的特点,必须将试验结果分为两类,再进行统计分析。ROC曲线的评价方法与传统的评价方法不同,无须此限制,而是根据实际情况,允许有中间状态,可以把试验结果划分为多个有序分类,如正常、大致正常、可疑、大致异常和异常五个等级再进行统计分析。因此,ROC曲线评价方法适用的范围更为广泛。
通过plotROC绘制出本图的ROC曲线如下:
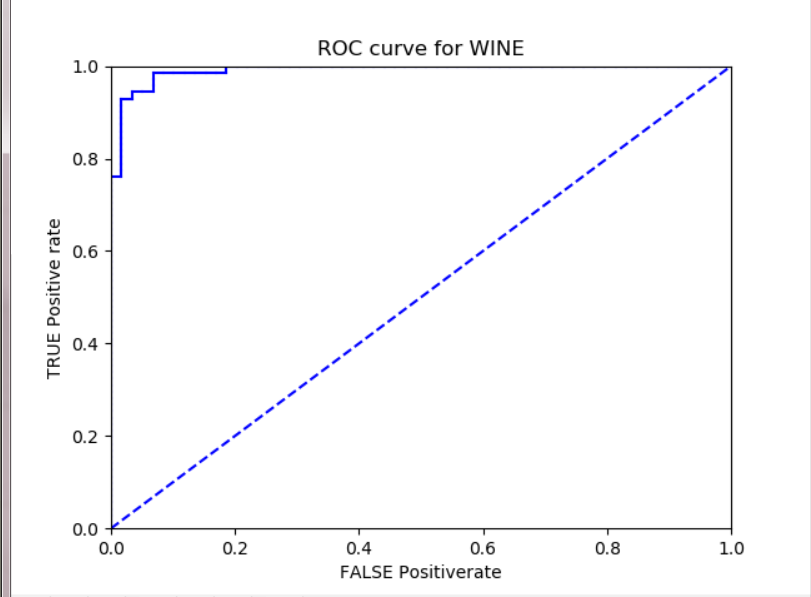
在本次对Adaboost的学习过程中,其实比较短,但是它确实是一种非常有效的方法,据说在Deep Learning出来之前,SVM和Adaboost是效果最好的两个算法。虽然通宵熬夜,但是最后看到出来比较满意的结果还是很开心的
附上所述代码:
1. # -*- coding: utf-8 -*-
2. from numpy import *
3. def loadSimpData():
4. datMat = matrix([[1. , 2.1],
5. [2. , 1.1],
6. [1.3 , 1.],
7. [1. , 1.],
8. [2. ,1.]])
9. classLabels = [1.0 , 1.0 , -1.0 ,-1.0 ,1.0]
10. return datMat , classLabels
11.
12. #通过阈值比较对数据进行分类函数,在阈值一边的会分到-1类别,另一边的分到类别+1
13. #先全部初始化为1,然后进行过滤,不满足不等式的变为-1
14. def stumpClassify(dataMatrix , dimen , threshVal , threshIneq) :
15. retArray = ones((shape(dataMatrix)[0] , 1 ))
16. if threshIneq == 'lt' :
17. retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
18. else:
19. retArray[dataMatrix[:,dimen] > threshVal] = -1.0
20. return retArray
21. #遍历上述函数所有可能输入,找到最佳单层决策树
22. def buildStump(dataArr,classLabels,D):
23. dataMatrix = mat(dataArr) ; labelMat = mat(classLabels).T
24. m,n = shape(dataMatrix)
25. numSetps = 10.0 #在特征的所有可能值上进行遍历
26. bestStump = {} #存储给定权重D得到的最佳单层决策树
27. bestClasEst = mat(zeros((m,1)))
28. minError = inf #初始化为无穷大,找最小错误率
29. for i in range(n) :#在特征上进行遍历,计算最大最小值来求得合理步长
30. rangeMin = dataMatrix[:,i].min() ; rangeMax = dataMatrix[:,i].max();
31. stepSize = (rangeMax-rangeMin)/numSetps
32. for j in range(-1,int(numSetps)+1):
33. for inequal in ['lt' , 'gt'] :#大于小于切换不等式
34. threshVal = (rangeMin+float(j)*stepSize)
35. predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)
36. errArr = mat(ones((m,1))) #如果预测值≠真实值,为1
37. errArr[predictedVals==labelMat] = 0
38. weightedError = D.T * errArr #相乘求和得到错误权重数值
39. if weightedError < minError :
40. minError = weightedError
41. bestClasEst = predictedVals.copy()
42. bestStump['dim'] = i
43. bestStump['thresh'] = threshVal
44. bestStump['ineq'] = inequal
45. return bestStump , minError , bestClasEst
运行结果
1. def adaBoostTrainDS(dataArr,classLabels,numIt = 40) : #=数据集,类别标签,迭代次数numIt
2. weakClassArr = []
3. m = shape(dataArr)[0] #m是数据的数目
4. D = mat(ones((m,1))/m) #每个数据点的权重
5. aggClassEst = mat(zeros((m,1))) #记录每个数据点的类别估计累计值
6. for i in range(numIt): #如果在迭代次数内错误率为0则退出
7. bestStump , error , classEst = buildStump(dataArr,classLabels,D)
8. #返回利用D得到的最小错误率单层决策树,最小的错误率和估计的类别向量
9. print "D:" , D.T
10. alpha = float(0.5*log((1.0-error)/max(error,1e-16))) #分类器分配的权重,这里比较是为了防止0出现溢出
11. bestStump['alpha'] = alpha
12. weakClassArr.append(bestStump)
13. print "classEst : " , classEst.T
14. expon = multiply(-1*alpha*mat(classLabels).T , classEst)
15. D = multiply(D,exp(expon))
16. D = D/D.sum()
17. aggClassEst += alpha*classEst
18. print "aggClassEst : " , aggClassEst.T
19. aggErrors = multiply(sign(aggClassEst)!=mat(classLabels).T , ones((m,1)))
20. errorRate = aggErrors.sum() / m
21. print "Total error : " , errorRate , "\n"
22. if errorRate ==0.0 : break
23. return weakClassArr

1. def adaClassify(datToClass,classifierArr):#基于adaboost的分类
2. dataMatrix = mat(datToClass)
3. m = shape(dataMatrix)[0]
4. aggClassEst = mat(zeros((m,1)))
5. for i in range(len(classifierArr)): #训练多个弱分类器
6. classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],
7. classifierArr[i]['thresh'],
8. classifierArr[i]['ineq'])
9. aggClassEst += classifierArr[i]['alpha']*classEst
10. print aggClassEst
11. return sign(aggClassEst)
ROC曲线的绘制
12. def plotROC(predStrengths, classLabels):
13. import matplotlib.pyplot as plt
14. cur = (1.0,1.0) #保留绘制光标的位置
15. ySum = 0.0 #计算AUC的值
16. numPosClas = sum(array(classLabels)==1.0)
17. yStep = 1/float(numPosClas);
18. xStep = 1/float(len(classLabels)-numPosClas)
19. sortedIndicies = predStrengths.argsort()#获取排序索引
20. fig = plt.figure()
21. fig.clf()
22. ax = plt.subplot(111)
23. #画图
24. for index in sortedIndicies.tolist()[0]:
25. if classLabels[index] == 1.0:
26. delX = 0;
27. delY = yStep;
28. else:
29. delX = xStep;
30. delY = 0;
31. ySum += cur[1]
32. ax.plot([cur[0],cur[0]-delX],[cur[1],cur[1]-delY], c='b')
33. cur = (cur[0]-delX,cur[1]-delY)
34. ax.plot([0,1],[0,1],'b--')
35. plt.xlabel('False positive rate'); plt.ylabel('True positive rate')
36. plt.title('ROC curve for AdaBoost horse colic detection system')
37. ax.axis([0,1,0,1])
38. plt.show()
39. print "the Area Under the Curve is: ",ySum*xStep
参考文献:
CSDN——Adaboost 2.24号:ROC曲线的绘制和AUC计算函数
CSDN——AdaBoost--从原理到实现
中国邮电出版社——《机器学习实战》