一,Boosting算法概论
boosting是一族可将弱学习器提升为强学习器的算法。booting中所使用的多个分类器的类型都是一致的,并且不同分类器是通过串行训练而获得的,每个新分类器都根据已训练出的分类器的性能进行训练。Boosting是通过集中关注被已有分类器错分的那些数据来获得新的分类器。boosting分类的结果是基于所有分类器的加权求和结果的,因此boosting中的分类器权重并不相等,每个权重代表的是对应分类器在上一轮迭代中的成功度。boosting算法通过分布迭代(stage-wise)的方式来构建模型,在迭代的每一步中构建的弱分类器都是为了弥补已有模型的不足。(个体学习器之间存在强依赖关系)
样本加权的过程如下:

上图中被放大的点是被加权的样本,样本加权后,在下一次的学习中就会收到更多的关注。也就是说,boosting算法对分类错误的样本更加关注,通过改变分类错误样本的权重来改变下一个弱分类器的分类边界,从而一步步提升分类算法的准确度。
boosting算法拥有多个版本,其中Adaboost算法是其中最流行的版本。
二、Adaboost算法概述
Adaboost是adaptive boosting(自适应boosting)的缩写,其运行过程如下:训练数据中的每一个样本,赋予一个权重,这些权重构成了向量D。一开始,这些权重都初始化为相等值。首先在训练数据上训练出一个弱分类器并计算该分类器的错误率,然后再同一个数据集上再次训练弱分类器,在分类器的第二次训练当中,将会重新调整每个样本的权值,其中,第一次分对的样本的权重将会降低,分错样本的权重将会提高。为了从所有弱分类器中得到最终的分类结果,adaboost为每个分类器都分配一个权重值alpha,这些alpha值是基于每个弱分类器的错误率进行计算的,其中错误率是:

加权后的错误率是:

alpha的计算公式:
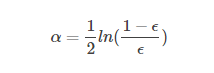

计算出alpha值之后,就可以对权重向量D进行更新,以使得那些正确分类的样本的权重降低而错分样本的权重升高。
如果某个样本被正确分类,那么该样本的权重更改为:
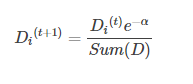
如果某个样本被错分,那么该样本的权重更改为:

综合起来就是:
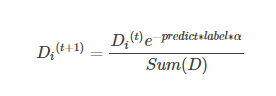
在计算出D之后,Adaboost有开始进入下一轮的迭代。Adaboost算法会不断地重复训练和调整权重的过程,直到错误率为0或者弱分类器的数目达到用户的指定值为止。
关于adaboost中的两种权重
adaboost算法中有两种权重,一种是数据的权重,另一种是弱分类器的权重。其中,数据的权重主要用于弱分类器寻找分类误差最小的决策点,找到之后用这个最小误差计算出弱分类器的权重,分类器的权重越大说明该弱分类器在最终决策时有更大的发言权。
数据的权重:如果训练数据保持不变,那么弱分类器每次找到的最佳决策点都是一样的。这时候,数据的权重就派上用场了,数据的权重主要用于弱分类器寻找其分类误差最小的点。举个例子,在以前没有权重时,一共是十个点,对应每个点的权重都是0.1,分错一个错误率就是0.1;分错三个,错误率就是0.3。现在,每个点的权重不一样了,分别为【0.01,0.01,0.01,0.01,0.01,0.01, 0.01,0.01,0.01,0.91】,如果分错分错第一个点,错误率就是0.01。如果分错第三个点,错误率是0.01。,要是如果分错最后一个点时,错误率就是0.91。这样一来在选择决策点时就会把权重大 的点分对才能降低误差率。由此可见,权重大的点得到更多的关注,权重小的点得到更少的关注。
图示说明Adaboost过程:

图中,“+”和“-”分别表示两个类别,在这个过程中,使用水平或者垂直的直线作为分类器来进行分类。
第一步:

根据分类的正确率,得到一个新的样本分布D2,一个子分类器h1。
其中画圈的是被分错的,分错的样本会增大权重。
第二步:

根据分类的正确率,得到一个新的样本分布D3,一个子分类器h2。
第三步:

得到第三个子分类器h3
整合所有子分类器:

从结果可以看出,即使是简单的弱分类器,组合起来可以获得很好的分类效果。
sklearn类库中的Adaboost应用:
class sklearn.ensemble.AdaBoostRegressor(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm=’SAMME.R’, random_state=None)
class sklearn.ensemble.AdaBoostRegressor(base_entimator=None, n_estimators=50, learning_rate=1.0, loss="linear", random_state=None)
参数:
(1)base_estimator:即弱分类学习器理论上可以选择任何一个分类器,不过需要支持样本权重。我们常用的一般是CART决策树或者神经网络MLP。默认是决策树,即AdaBoostClassifier默认使用CART分类树DecisionTreeClassifier,而AdaBoostRegressor默认使用CART回归树DecisionTreeRegressor。
(2)algorithm:这个参数只有在AdaBoostClassifier中有。主要原因是scikit-learn实现了两种Adaboost分类算法,SAMME和SAMME.R。两者的主要区别是弱分类器权重的度量。SAMME使用了样本集分类效果作为弱分类器的权重,即误差率得到的权重;而SAMME.R使用了对样本集分类的预测概率大小作为权重。由于SAMME.R使用了概率度量的连续值,迭代一般比SAMME快,因此AdaBoostClassifier的默认算法algorithm的值是SAMME.R。但是注意的是使用了SAMME.R后,弱分类器参数base_estimator必须限制使用支持概率预测的分类器。而SAMME算法则没有这个限制。
(3)n_estimators:两者都有,就是我们弱分类器的最大迭代次数,或者最大的弱学习器的个数。一般来说n_eatimators太小,容易欠拟合,太大又容易过拟合,默认是50.在实际调参过程中,我们常常将n_eatimators和learning_rate一起考虑。
(4)learning_rate:两者都有,即每个弱学习器的权重缩减系数。
主要方法:
(1)fit(x,y): 从训练集中创建一个提升分类器
(2)get_params():得到模型的参数
(3)predict(x):预测
(4)score(x,y):验证集上验证算法的精度
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import load_iris
from sklearn import model_selection
#import matplotlib.pyplot as plt
iris = load_iris()
x_train,x_test,y_train,y_test = model_selection.train_test_split(iris.data,
iris.target,test_size=0.2,random_state=0)
abc = AdaBoostClassifier(n_estimators=100)
abc.fit(x_train,y_train)
abc.score(x_test,y_test)0.90000000000000002
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import load_iris
from sklearn import model_selection
from sklearn.tree import DecisionTreeClassifier
#import matplotlib.pyplot as plt
iris = load_iris()
x_train,x_test,y_train,y_test = model_selection.train_test_split(iris.data,
iris.target,test_size=0.2,random_state=0)
abc = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2,min_samples_split=20,
min_samples_leaf=5),
n_estimators=100)
abc.fit(x_train,y_train)
abc.score(x_test,y_test)1.0(震惊脸-_-)
参考:https://blog.csdn.net/zwqjoy/article/details/80424783
http://www.cnblogs.com/pinard/p/6136914.html
![]()
![]()